
Codex 自动化任务怎么设计?按目标、权限和复核点拆分的教程
Codex 自动化任务怎么设计?按目标、权限和复核点拆分的教程,适合希望把日报整理、日志归纳和代码检查交给代理执行的开发者。这篇文章只讲通用接入方法、检查顺序和排错思路,不比较平台优劣,也不把任何站点写成注册或购买引导。你可以把它当成一份上线前自检清单,先确认配置边界,再做最小请求,最后再放进真实工作流。
一、这个关键词对应的真实使用场景是什么
Codex 常见的真实场景,不是“演示一次调用就结束”,而是要把模型能力稳定地放进现有工程里,例如把 把重复性的项目检查、变更汇总和修复建议流程化。只要链路里有一个环节没有对齐,问题就会在请求放大后集中暴露出来。
先确认你要解决的是接入问题,不是业务逻辑问题
如果最小请求还没有跑通,就不要先怀疑业务代码。优先确认密钥、接口入口、模型名、超时和网络环境,再去看业务层输入是否合理。
接入类问题最怕“多个变量一起改”
一次同时修改 SDK、Base URL、模型名和环境变量,排错会很慢。更稳的做法是一次只改一项,每改完就跑一次固定测试请求。
二、开始前必须确认的 4 个配置项
配置项 1:密钥放在哪里读取
最常见的写法是把密钥放到环境变量里,变量名必须和工具要求完全一致。例如:
export OPENAI_API_KEY=your-secret-key如果你在 Windows、IDE 内置终端、WSL 或 CI 里运行,同名变量未必共用。看到 401 时,先确认当前进程到底有没有读到值。
配置项 2:Base URL 和控制台网址不是一回事
很多人复制浏览器地址栏的网址去当接口入口,这通常会得到 404 或权限错误。真正的接口入口应该来自文档或工具配置说明,而不是来自账户后台页面。
配置项 3:模型名是否和当前调用能力匹配
模型名不仅决定输出能力,也决定是否支持图像、工具调用、结构化输出或长上下文。建议先用一个明确的占位值,再替换为当前控制台里可见的模型名,例如:
model=codex-mini-latest配置项 4:日志里要能看到失败原因
不要只打印“请求失败”。至少把状态码、错误体、请求耗时和调用批次号记录下来,否则线上问题出现后很难追到是哪一次配置变更引起的。
三、推荐的最小接入顺序
第一步:先跑版本和环境检查
无论你用命令行工具还是 SDK,先确认程序能正常启动,再检查变量是否存在。不要在工具本身还无法运行时就去怀疑模型服务。
第二步:只发一个最小请求
最小请求应该简单到足以隔离问题,例如只要求返回一句固定文本:
{
"model": "codex-mini-latest",
"input": "请只回复:连接正常"
}只要这个请求稳定返回,你才能证明最基础的请求链路是通的。
第三步:再加工具、文件或更长上下文
最小请求通过后,再把代码仓库、MCP 工具、批处理输入、图像生成提示词或自动化步骤逐层加上去。这样一旦失败,你就知道是新增的哪一层出了问题。
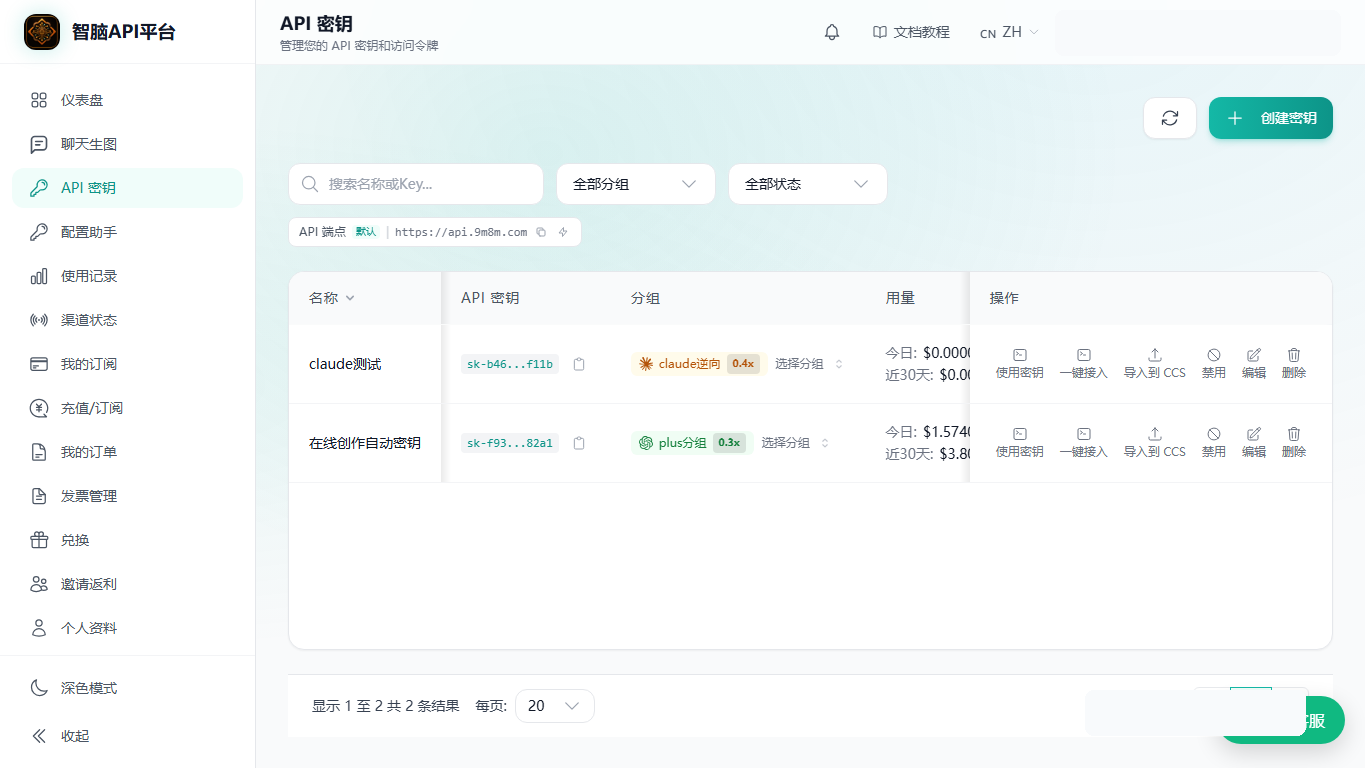
图 1:先确认密钥、分组、接口入口和状态信息,再进入正式调试。
四、正文结构应该怎么组织才方便排错
H2 用来切分阶段,H3 用来切分动作
教程类文章最怕结构松散。实践里可以把 H2 写成“准备配置、最小请求、错误排查、自动化扩展、发布前自检”,再用 H3 写清楚每个动作要检查什么。
代码块要短,优先展示关键字段
不要上来贴一大段完整项目代码。排错时真正关键的是环境变量名、Base URL、模型名、请求体和错误体,而不是几十行和主题无关的封装层。
链接只保留一条真正有复查价值的参考
教程里只需要保留一条能帮助复查字段含义和配置位置的参考链接即可: 教程文档参考:[参考文档](https://my.feishu.cn/wiki/NIgLwuuj1ibzJIkLGM0cgVNinzg)
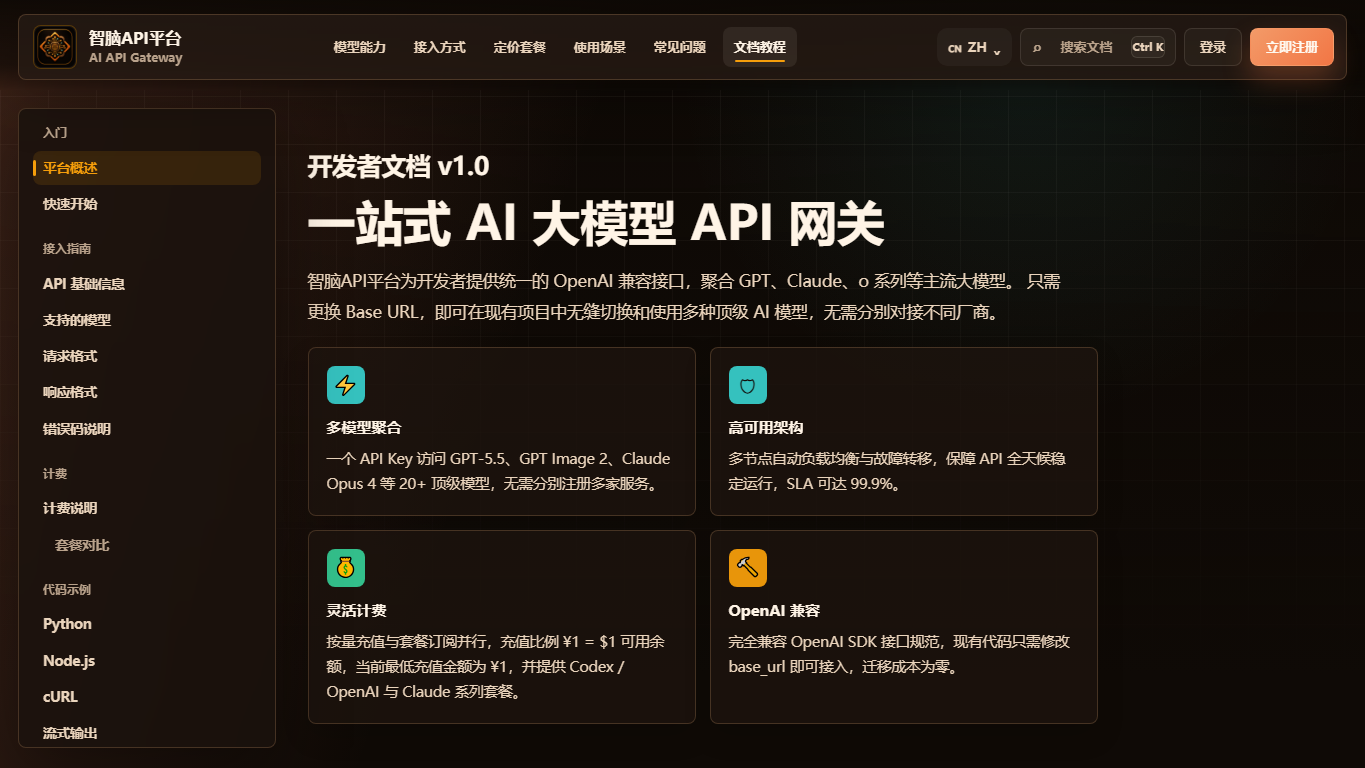
图 2:当文档页与代码配置页不一致时,应以当前可用字段和调用结果为准。
五、常见错误该按什么顺序查
401:先看密钥是否真的被当前进程读取
401 多数不是模型问题,而是密钥为空、复制不完整、变量名写错或运行环境没有重新加载变量。先在当前终端打印变量是否存在,再继续往下看。
403:再看权限、分组或能力范围
403 往往表示密钥本身有效,但没有目标模型或目标能力的权限。例如图像接口、工具调用或某类代理能力未开放时,就会在这里暴露出来。
404:最后看 Base URL 和路径拼接
404 经常来自路径写重、版本号重复或把网页路径当成接口路径。特别是在切换 OpenAI-compatible 服务时,这类错误最常见。
429 和超时:不要直接无限重试
看到 429 或超时,先缩小输入范围,再引入指数退避和最大重试次数。批处理里建议把失败请求落盘,这样单次失败不会拖垮整批任务。
const retryable = new Set([408, 409, 429, 500, 502, 503, 504]);六、把它接入自动化之前,还要多做一步
给任务设置边界条件
自动化里要明确输入目录、单次最大文件数、最大执行时间和失败后的停止条件。没有边界的代理任务,往往不是“更智能”,而是“更难复盘”。
给结果设置人工复核点
如果输出要进入代码库、知识库或线上系统,就要明确哪些步骤必须人工确认,例如修改生产配置、替换密钥、批量删除文件或对外发布。
给发布结果保留审计记录
至少保留标题、摘要、结构计数、参考链接、配图来源和发布结果。这样下一次复跑时,你能快速判断是内容问题、图片问题,还是平台状态问题。
checks:
title: true
h2: true
h3: true
reference_link: true
images: true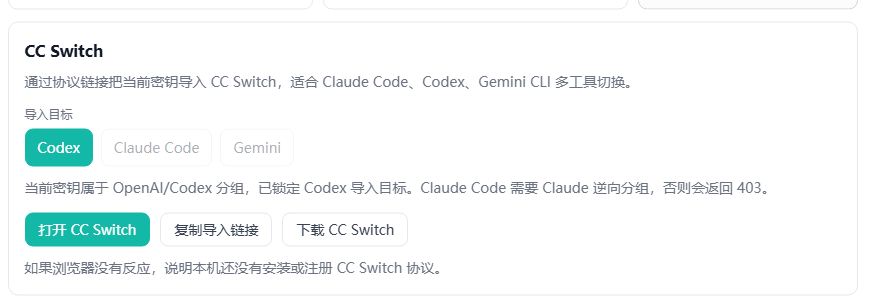
图 3:自动化任务上线前,应先确认工具入口、权限范围和回滚手段。
七、发布前自检清单
标题是否对应搜索词
标题最好能直接覆盖搜索关键词,但不要堆叠多个同义词。用户搜什么,就回答什么;多出来的扩展放在正文里。
H2 和 H3 是否真的有分工
如果 H2 只是换个说法重复标题,H3 只是随意拆句,读者找不到检查顺序。结构清晰,平台审核和后续复用都更稳定。
链接和配图是否能在公开页加载
编辑器里能看到图片,不代表公开页一定能看到。发布后应再次检查图片尺寸、是否失效、是否被平台替换,以及参考链接能否正常打开。
正文是否保留中立语气
教程只需要说明“怎么做”和“为什么这样排查”,不需要写夸张表述、平台优越感或引导动作。中立表达更适合长期复用。
总结
Codex 自动化任务怎么设计?按目标、权限和复核点拆分的教程 的核心,不在于记住某个平台的口号,而在于建立一条稳定的排查顺序:先确认密钥和入口,再用最小请求验证链路,然后逐层增加真实任务,最后为自动化和发布补齐日志、复核点和回滚手段。只要顺序是对的,大多数接入问题都能被快速定位。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)