
2026年6月18日 主流大模型对比:Claude Fable 5 三项领跑,GLM-5.2 Agentic 反超 GPT-5.5,Kimi K2.7 Code 上线
更新日期 2026.6.18
数据来源 https://vibecoding.dreamfree.space原文链接 https://vibecoding.dreamfree.space/articles/model_comparisons/20260617/
基于 Artificial Analysis 2026 年 6 月 17 日最新测试数据,本文对 19 款主流大模型做横向对比,按 Intelligence 指数 → Coding 指数 → Agentic 指数 三层展开——分别对应综合表现、写代码能力、长流程自动化能力。
本期最值得关注的 5 个变化:
- Claude Fable 5 异军突起:在本期 19 款集合中,Intelligence(60)、Coding(62.0)、Agentic(80.6)三项均为第一。
- GLM-5.2 Agentic 反超 GPT-5.5:开源旗舰 GLM-5.2 的 Agentic 指数达 75.9,高于 GPT-5.5 的 74.1。
- 国产新双雄:GLM-5.2(6 月 16 日)与 Kimi K2.7 Code(6 月 12 日)集中上线,成为国产阵营焦点。
- Kimi K2.7 Code 走专项路线:官方强调编程与 Agent 强化及 highspeed 版本,但榜单 Coding 指数(45.6)仍略低于 K2.6(47.1)。
- 模型名单更新:纳入 Claude Fable 5、MiniMax-M2.7 等,替换部分 6 月初旧型号。
一、快速对比总览
下表汇总 19 款主流模型的上下文、多模态与三项核心指数,便于横向比较(统计时间:2026 年 6 月 17 日):
| 模型 | 上下文长度 | 多模态 | Intelligence 指数 | Coding 指数 | Agentic 指数 |
|---|---|---|---|---|---|
| Claude Fable 5 | ✅ 1M | ✅ 文本+图像 | 60 | 62.0 | 80.6 |
| Claude Opus 4.8 | ✅ 1M | ✅ 文本+图像 | 56 | 56.7 | 77.8 |
| GPT-5.5 | ✅ 920k | ✅ 文本+图像 | 55 | 59.1 | 74.1 |
| GLM-5.2 | ✅ 1M | ❌ 纯文本 | 51 | 50.7 | 75.9 |
| Gemini 3.5 Flash | ✅ 1M | ✅ 文本+图像+音频+视频 | 50 | 45.0 | 70.3 |
| Claude Sonnet 4.6 | ✅ 1M | ✅ 文本+图像 | 47 | 50.9 | 63.0 |
| Gemini 3.1 Pro Preview | ✅ 1M | ✅ 文本+图像+音频+视频 | 46 | 55.5 | 59.1 |
| Qwen3.7 Max | ✅ 1M | ❌ 纯文本 | 46 | 50.1 | 66.6 |
| MiniMax-M3 | ✅ 1M | ✅ 文本+图像+视频 | 44 | 43.4 | 68.6 |
| DeepSeek V4 Pro | ✅ 1M | ❌ 纯文本 | 44 | 47.5 | 67.2 |
| Kimi K2.6 | ❌ 260k | ✅ 文本+图像+视频 | 43 | 47.1 | 66.0 |
| MiMo-V2.5-Pro | ✅ 1M | ❌ 纯文本 | 43 | 45.5 | 67.4 |
| Kimi K2.7 Code | ❌ 260k | ✅ 文本+图像+视频 | 42 | 45.6 | 61.9 |
| DeepSeek V4 Flash | ✅ 1M | ❌ 纯文本 | 42 | 38.7 | 61.3 |
| GLM-5.1 | ❌ 200k | ❌ 纯文本 | 40 | 43.4 | 67.1 |
| GPT-5.4 Mini | ✅ 400k | ✅ 文本+图像 | 40 | 51.5 | 58.9 |
| Qwen3.7 Plus | ✅ 1M | ✅ 文本+图像+视频 | 39 | 46.5 | 65.1 |
| MiniMax-M2.7 | ❌ 200k | ❌ 纯文本 | 38 | 41.9 | 61.5 |
| Claude Haiku 4.5 | ❌ 200k | ✅ 文本+图像 | 30 | 32.6 | 40.2 |
特别提示:Qwen3.7 Max 为纯文本模型,多模态需求请使用 Qwen3.7 Plus。GPT-5.5 上下文为 920k,并非 1M。
二、整体格局:先看 Intelligence 指数
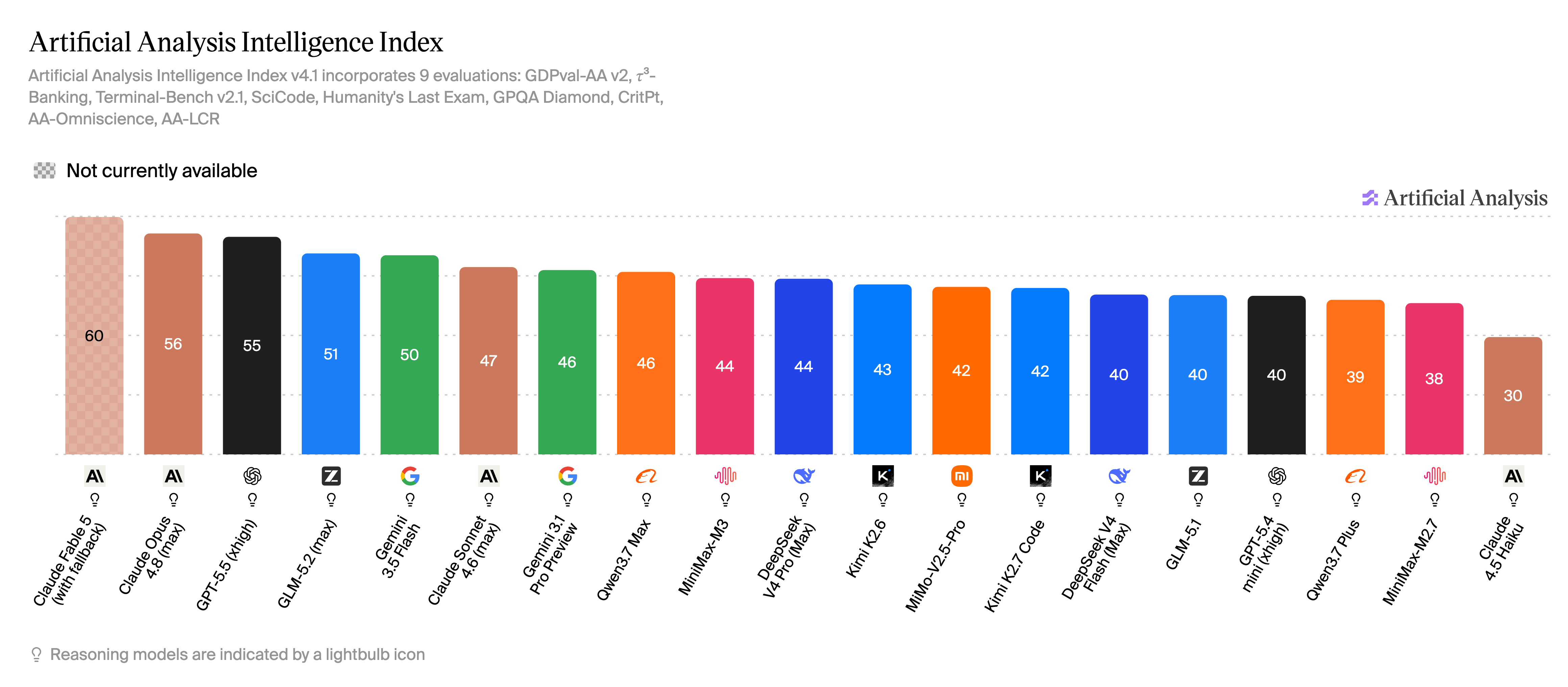
数据来源:Artificial Analysis - Intelligence Index
Intelligence 指数反映模型的综合表现——不只看谁更会写代码,也看谁在 OpenClaw、Claude Code、MCP 多工具链等复合场景里更扛得住。
- 全球头部:Claude Fable 5 居首,Claude Opus 4.8、GPT-5.5 紧随其后。Fable 5 在 Coding、Agentic 分项上同样领先,值得重点关注。
- 开源旗舰第一梯队:GLM-5.2 为开源阵营 Intelligence 最高,也是国产开源新旗舰中的领跑者;Gemini 3.5 Flash 紧随其后。
- 旗舰与中坚:Claude Sonnet 4.6、Gemini 3.1 Pro Preview、Qwen3.7 Max 仍处上游;MiniMax-M3、DeepSeek V4 Pro、Kimi K2.6、MiMo-V2.5-Pro 形成国产「中军」。
- 专项与性价比档:Kimi K2.7 Code、DeepSeek V4 Flash、GLM-5.1、MiniMax-M2.7 等覆盖「够用且省钱」区间;Claude Haiku 4.5 为轻量入口。
一句话总结 Intelligence 格局:海外头部仍由 Anthropic / OpenAI 把持,但开源阵营的 GLM-5.2 已经挤进全球第一观察圈,且 Agentic 分项已超过 GPT-5.5。
三、Coding 指数:开发者仍用脚投票
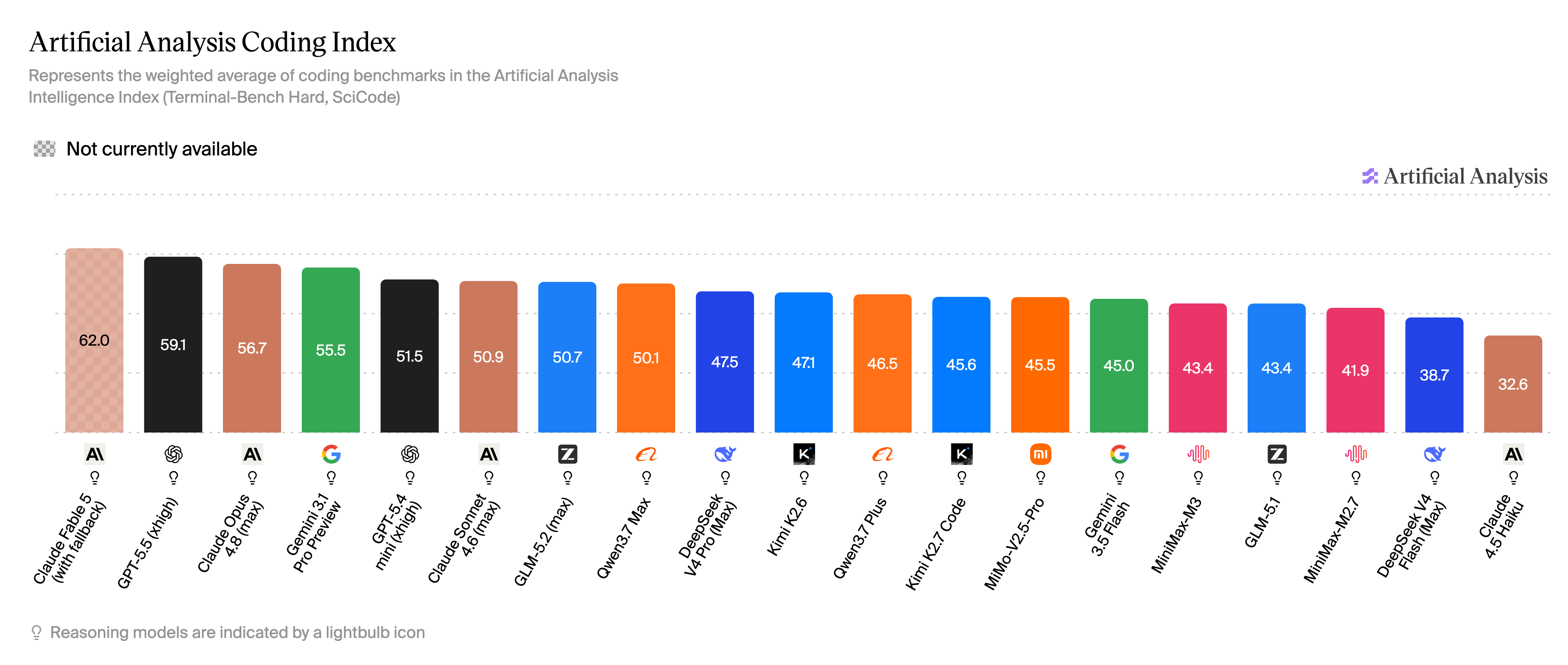
数据来源:Artificial Analysis - Coding Index
Coding 指数衡量模型写代码、改代码、理解代码库的水平,直接决定 Claude Code、Cursor、Windsurf 等工具背后的「手感」。
Coding 指数 TOP 解读:
- 第一梯队:Claude Fable 5 登顶,GPT-5.5、Claude Opus 4.8 构成海外编程铁三角。
- 次旗舰:Gemini 3.1 Pro Preview、Claude Sonnet 4.6、GLM-5.2、Qwen3.7 Max 紧随其后。
- 国产 Coding 中坚:DeepSeek V4 Pro、Kimi K2.6、Qwen3.7 Plus、Kimi K2.7 Code、MiMo-V2.5-Pro。
- 性价比档:MiniMax-M3、GLM-5.1、MiniMax-M2.7、DeepSeek V4 Flash。
国产 Coding 的关键反差:GLM-5.2 已进入全球 Coding 上游,是国产开源编程第一梯队;Kimi K2.7 Code 虽为最新编程专项,横向榜单上仍略低于 Kimi K2.6——官方自有 benchmark 显示相对 K2.6 在多项编程测试中有提升,但横向对比尚未全面反超。若看重专项体验与 highspeed 高速版,K2.7 Code 仍值得单独尝试。
四、Agentic 指数:长流程自动化的分水岭
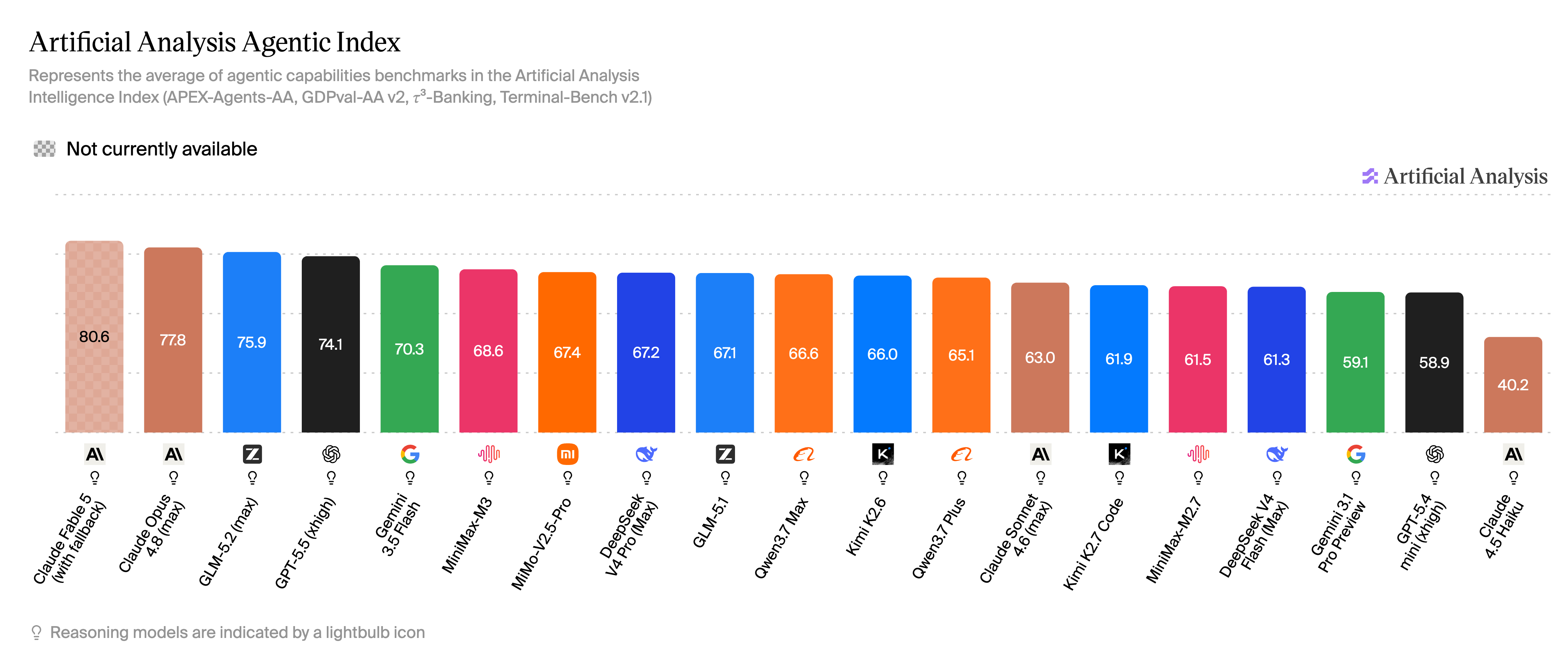
数据来源:Artificial Analysis - Agentic Index
Agentic 指数衡量模型自主完成多步骤任务、调用工具、驱动工作流的能力——与 OpenClaw 运营、Claude Code 自主修仓库、MCP 多工具编排等场景直接相关。
Agentic 指数 TOP 解读:
- 断层领先:Claude Fable 5 大幅领先 Claude Opus 4.8,是本期 Agentic 的「天花板」。
- 突出变化:GLM-5.2 超过 GPT-5.5,位居 19 款模型第三——开源阵营在长流程自动化上首次压过 OpenAI 旗舰。
- 第二集团:Gemini 3.5 Flash、MiniMax-M3、MiMo-V2.5-Pro、DeepSeek V4 Pro、GLM-5.1、Qwen3.7 Max、Kimi K2.6、Qwen3.7 Plus 紧随其后。
- 专项与轻量档:Claude Sonnet 4.6、Kimi K2.7 Code、MiniMax-M2.7、DeepSeek V4 Flash、Gemini 3.1 Pro Preview。
如果你买模型是为了「让它自己跑完一条工作流」,本期不能只看 Intelligence 总分——GLM-5.2 的 Agentic 表现、MiniMax-M3 的国产高位、Claude Fable 5 的断层领先,都比 Coding 排名更值得纳入采购决策。
五、国产核心厂商深度解析
1. GLM-5.2(智谱 AI):开源 Intelligence 旗舰,Agentic 反超 GPT-5.5
GLM-5.2 于 6 月 16 日发布,MIT 许可,753B 总参数 / 40B 激活,1M 上下文。三项指数:Intelligence 51、Coding 50.7、Agentic 75.9。
- Intelligence + Coding:51 / 50.7 的组合把它稳稳放进全球开源第一观察圈,Coding 与 Qwen3.7 Max、Claude Sonnet 4.6 同档。
- Agentic 75.9:高于 GPT-5.5(74.1),适合长仓库、多 MCP 工具、OpenClaw 类自动化。
- 产品生态:GLM Coding Plan 以 GLM-5.2 为套餐中枢,Lite / Pro / Max 三档覆盖个人开发者,并强调 Claude Code、OpenClaw 等 20+ 编程工具接入。
短板同样清晰:纯文本(无多模态)、套餐热度高时常需抢购。若你的场景强依赖图像/视频输入,应转向 Qwen3.7 Plus 或 Kimi 系列。
2. Kimi K2.7 Code(月之暗面):编程专项 + highspeed,不是榜单全能冠军
K2.7 Code 于 6 月 12 日发布,Modified MIT,1T 总参数 / 32B 激活,支持文本+图像+视频输入。三项指数:Intelligence 42、Coding 45.6、Agentic 61.9。
与 K2.6 的对照:
| 维度 | Kimi K2.6 | Kimi K2.7 Code |
|---|---|---|
| Intelligence | 43 | 42 |
| Coding | 47.1 | 45.6 |
| Agentic | 66.0 | 61.9 |
| 定位 | 上一代全能旗舰 | 最新编程专项 |
官方 quickstart 给出的增量故事在自有 benchmark上更漂亮:相对 K2.6,Kimi Code Bench v2 +21.8%、Program-Bench +11%、MLS Bench Lite +31.5%,Agent 相关基准约 +10%。同步上线的 highspeed 版本输出速度约为普通版 5–6 倍,适合日常高频编码。订阅入口:Kimi 会员与 Kimi Code。
要横向榜单上的 Coding / Agentic 综合排名,K2.6 仍略占优;要官方强调的编程专项体验与极速输出,K2.7 Code + highspeed 更值得试。
3. MiniMax-M3(稀宇科技):Agentic 国产高位 + 性价比参照
MiniMax-M3:Intelligence 44、Coding 43.4、Agentic 68.6(国产 Agentic 第一档),1M 上下文,支持文本+图像+视频。
综合分不如 GLM-5.2,Coding 专项不如 K2.7 Code,但 Agentic 仍处高位、输出快、套餐额度宽松——是 OpenClaw 日常辅助与高频自动化的务实之选。订阅入口:MiniMax Coding Plan。
4. Qwen3.7(阿里):Coding 长项仍在,Max / Plus 分工明确
阿里 Qwen3.7 系列在本期仍是国产 Coding 的传统强位:Qwen3.7 Max 的 Coding 与 Agentic 均处上游,Intelligence 也在第一集团的中段,整体没有掉队。若你本来就在用通义或百炼生态,这一代的核心变化不是「能不能写代码」,而是和 GLM-5.2、Kimi K2.7 Code 等新变量怎么分工。
Max 与 Plus 怎么选:
- Qwen3.7 Max:1M 上下文的纯文本旗舰,Coding 与 Agent 都是这代的默认首选;要代码能力先找 Max。
- Qwen3.7 Plus:同代的多模态版本,支持图像与视频输入;综合分略低于 Max,但适合「既要写代码、又要看图/看视频」的日常开发。
和本期其他国产新旗舰相比,Qwen 的路径更偏成熟生态 + 稳态上游:GLM-5.2 在 Intelligence 与 Agentic 上更抢眼,Kimi K2.7 Code 走编程专项与 highspeed,而 Qwen3.7 Max 的优势仍是 Coding 底子厚、接入 阿里云百炼 方便、团队里已有 Qwen 习惯时迁移成本最低。若你不需要绑某一家 Coding Plan,又想要一家「什么场景都能先拿来用」的国产默认,Max 依然稳妥。
5. 其他国产梯队(简述)
- DeepSeek V4 Pro / Flash:Pro 三项均衡,适合复杂任务兜底;Flash 走极致性价比与按量缓存,高频轻量任务很划算。按量入口:DeepSeek 开放平台
- MiMo-V2.5-Pro:Agentic 居国产第一集团,纯文本,适合看重自动化、又可接受无多模态的团队。接入入口:小米 MiMo
- GLM-5.1:已被 GLM-5.2 接替主线,仅作上一代参照;Agentic 仍不低,但上下文较短。
六、选型建议:按场景对号入座
先想清楚更看重 综合能力、写代码、日常 Agent 流程,还是 上下文 / 多模态 / 预算。国产场景里,本期更常落在 GLM-5.2、MiniMax-M3、DeepSeek V4 三条线之间;海外天花板仍是 Claude / GPT 一线,按预算与生态再选即可。
综合能力优先
- 要最强综合表现(海外):Claude Fable 5(三项领跑)或 Claude Opus 4.8
- OpenAI 生态:GPT-5.5
- 开源 + 长上下文(国产):GLM-5.2
- 均衡全能、API / 按量都友好(国产):DeepSeek V4 Pro
- 已在用通义 / 百炼:Qwen3.7 Max 仍是稳态默认
以写代码为主
- 第一梯队:Claude Fable 5、GPT-5.5、Claude Opus 4.8、GLM-5.2
- 国产 Coding 上游:GLM-5.2、DeepSeek V4 Pro、Qwen3.7 Max
- 编程专项 + 极速输出:Kimi K2.7 Code highspeed——横向对比 Coding 略低于 K2.6,但专项调校与高速版更适合日常高频写代码
日常 Agent 流程(OpenClaw、Hermes、酒馆等)
这类场景更看重多步任务能不能跑完、工具能不能调稳,以及高频使用时是否够快、够省额度。
- 高频日常助手、标准化任务(国产):MiniMax-M3、DeepSeek V4 Flash
- 均衡兜底、Pro 扛复杂 / Flash 扛轻量:DeepSeek V4 Pro 与 DeepSeek V4 Flash 可搭配使用
- 角色扮演、长对话为主的酒馆类场景:优先看 MiniMax-M3(响应快、额度宽松)或 DeepSeek V4 Flash(按量便宜);若要更强指令遵循与工具联动,再考虑 GLM-5.2
上下文与多模态
- 长上下文纯文本工程流:GLM-5.2、DeepSeek V4 Pro、Qwen3.7 Max
- 长上下文 + 多模态:MiniMax-M3、Qwen3.7 Plus、Gemini 3.5 Flash
- 可接受较短上下文、但要图像/视频输入:Kimi K2.6 / K2.7 Code
预算与套餐
- 月费 Coding Plan:GLM Coding Plan、MiniMax Coding Plan、Kimi Coding Plan(K2.7 系列)
- 按量付费、看重缓存价:DeepSeek V4 Flash(DeepSeek 开放平台)
- 按量或 API 主力、能力要均衡:DeepSeek V4 Pro、MiMo-V2.5-Pro
本文聚焦编程与 Agent 能力选型。纯聊天场景通常不必为此单独购买 Coding 套餐。
七、2026 年 6 月中旬榜单变化总结
- Claude Fable 5 在本期 19 款集合中 Intelligence / Coding / Agentic 三项均为第一。
- GLM-5.2 开源 Intelligence 达 51,Agentic 75.9 超过 GPT-5.5,成为国产最值得关注的新旗舰。
- Kimi K2.7 Code 上线,走编程专项 + highspeed 路线;横向 Coding 仍略低于 K2.6。
- 国产 Agentic 第一集团仍由 MiniMax-M3、MiMo-V2.5-Pro、DeepSeek V4 Pro、GLM 系列、Qwen / Kimi 共同构成,与海外头部的差距继续收窄。
数据来源 https://vibecoding.dreamfree.space
原文链接 https://vibecoding.dreamfree.space/articles/model_comparisons/20260617/

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)