
codellama_lmdeploy对话问答模型
CodeLlama
论文
模型结构
Code Llama 是基于LLAMA预训练和微调的生成文本模型,支持很多种编程语言,包括 Python, C++, Java, PHP, Typescript (Javascript), C#, Bash 等等。具备代码续写、代码填空、对话、python专项等 4 种能力。
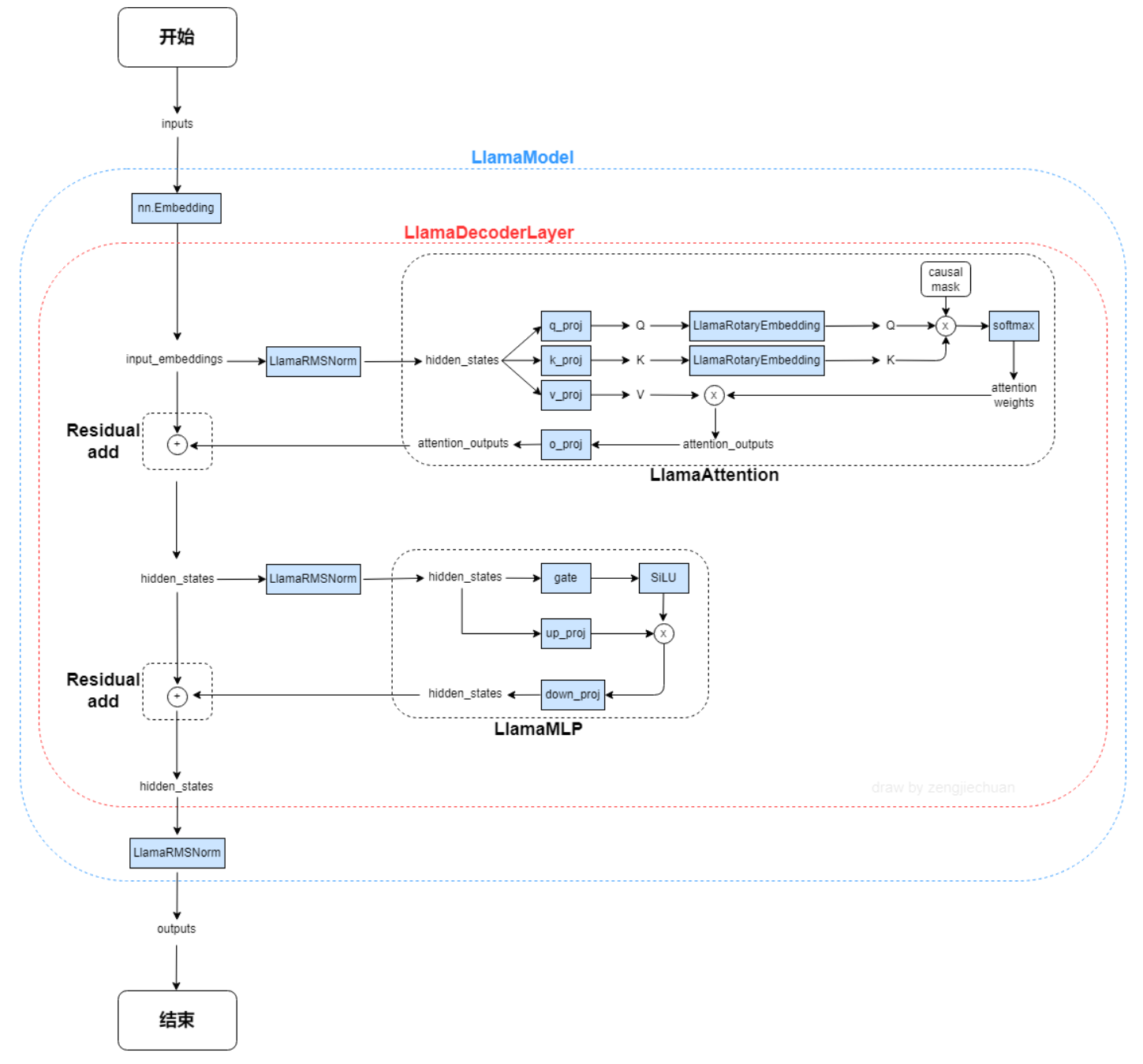
LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。以下是与原始架构的主要区别: 预归一化。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。 SwiGLU 激活函数 [PaLM]。使用 SwiGLU 激活函数替换 ReLU 非线性以提高性能。使用 2 /3 4d 的维度而不是 PaLM 中的 4d。 旋转嵌入。移除了绝对位置嵌入,而是添加了旋转位置嵌入 (RoPE),在网络的每一层。
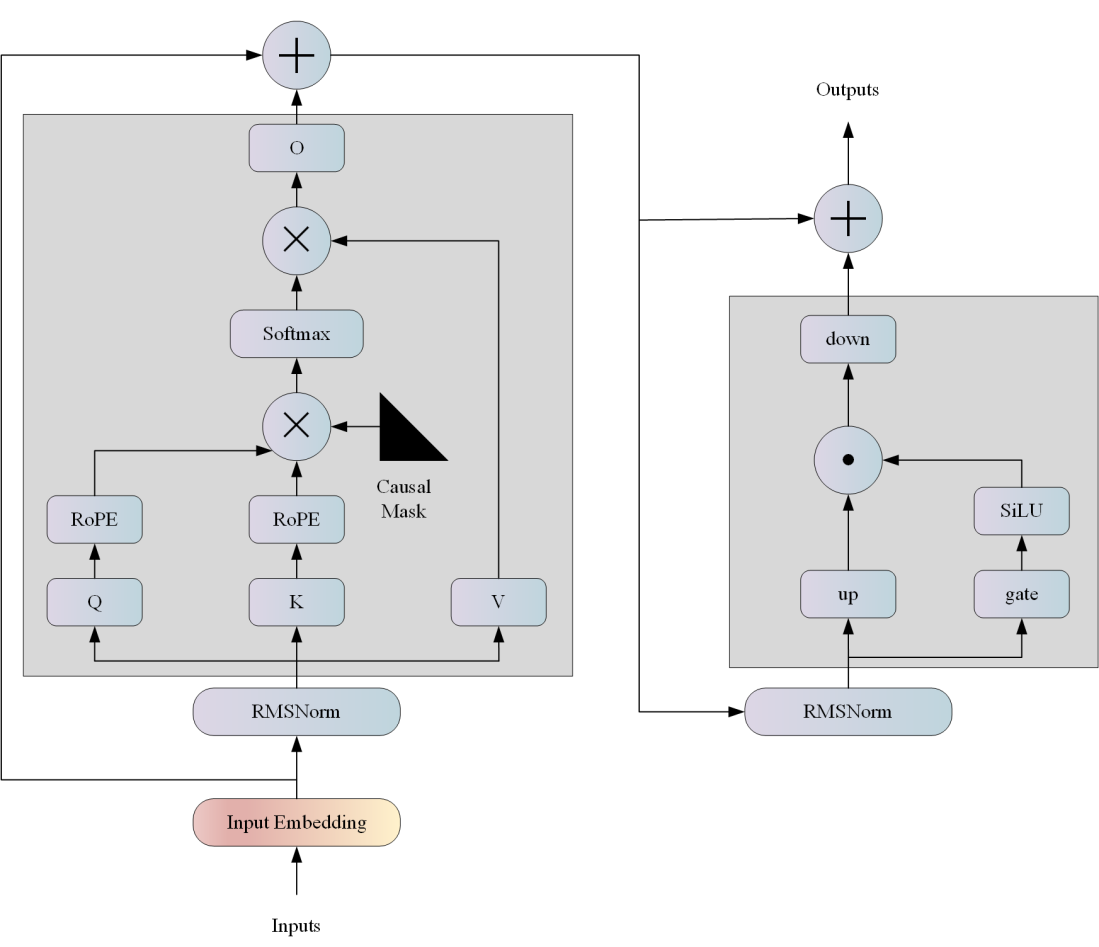
算法原理
Code Llama 是一组预训练和微调的生成文本模型,其规模从 7 亿到 34 亿个参数不等。
环境配置
提供光源拉取推理的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name codellama --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v <Host Path>:<Container Path> <Image ID> /bin/bash
cd lmdeploy
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
source /opt/dtk/cuda/env.sh
推理
源码编译安装
# 若使用光源的镜像,可以跳过源码编译安装,镜像里面安装好了lmdeploy。
git clone http://developer.hpccube.com/codes/modelzoo/codellama_lmdeploy.git
cd codellama_lmdeploy
git submodule init && git submodule update
cd lmdeploy
mkdir build && cd build
sh ../generate.sh
make -j 32
make install
cd .. && python3 setup.py install
模型下载
它在 HuggingFace 上发布了基座模型,Python模型和指令微调模型:
模型在SCNet上的快速下载链接:
模型和能力的对应关系为:
| 模型 | 代码续写 | 代码填空 | 对话 | Python专项 |
|---|---|---|---|---|
| 基座模型 | Y | Y(7B,13B), N(34B) | N | N |
| Python微调模型 | Y | N | N | Y |
| 指令微调模型 | Y | Y(7B,13B), N(34B) | Y | N |
运行
接下来,可参考如下章节,在控制台与 codellama 进行交互式对话。
注意:
- transformers最低要求 v4.33.0
lmdeploy.turbomind.chat支持把代码块拷贝到控制台,结束输出的方式为回车,再输入"!!",再回车。其他非 codellama 模型,仍然是两次回车结束输入。
代码续写
lmdeploy chat turbomind ./workspace --cap completion
./workspace:模型路径
代码填空
lmdeploy chat turbomind ./workspace --cap infilling
./workspace:模型路径
输入的代码块中要包含 <FILL>,比如:
def remove_non_ascii(s: str) -> str:
""" <FILL>
return result
turbomind.chat 输出的代码即是要填到 <FILL> 中的内容
对话
lmdeploy chat turbomind ./workspace --cap chat
./workspace:模型路径
Python 专项
lmdeploy chat turbomind ./workspace --cap python
./workspace:模型路径
建议这里部署 Python 微调模型
服务
目前,server 支持的是对话功能,其余功能后续再加上。
启动 sever 的方式是:
# --tp: 在 tensor parallel时,使用的GPU数量
lmdeploy serve api_server ./workspace --server-name 0.0.0.0 --server-port ${server_port} --tp 1
打开 http://{server_ip}:{server_port},即可访问 swagger,查阅 RESTful API 的详细信息。
你可以用命令行,在控制台与 server 通信(在新启的命令行页面下执行):
# restful_api_url 就是 api_server 产生的,比如 http://localhost:23333
lmdeploy serve api_client restful_api_url
或者,启动 gradio,在 webui 的聊天对话框中,与 codellama 交流:
# restful_api_url 就是 api_server 产生的,比如 http://localhost:23333
# server_ip 和 server_port 是用来提供 gradio ui 访问服务的
# 例子: lmdeploy serve gradio http://localhost:23333 --server-name localhost --server-port 6006
# --server_port要和restful_api_url的端口不一样。
lmdeploy serve gradio restful_api_url --server-name ${server_ip} --server-port ${server_port}
注意:如果打不开网页,则按照一下办法调整
从https://github.com/bumblebeeMMa/DownLoad_frpc_linux_amd64 下载frpc_linux_amd64文件;
本地改名为frpc_linux_amd64_v0.2
上传到gradio安装路径下面,gradio安装包路径可以使用如下方法找到,在终端输入下面语句:
python
import gradio
gradio
关于 RESTful API的详细介绍,请参考这份文档。
result
精度
无
应用场景
算法类别
对话问答
热点应用行业
金融,科研,教育
源码仓库及问题反馈
ModelZoo / CodeLlama_lmdeploy · GitLab
参考资料
GitHub - InternLM/lmdeploy: LMDeploy is a toolkit for compressing, deploying, and serving LLMs.

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 51
51 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)