
Ollama 结合 Open-WebUI 本地运行大模型

本文介绍了如何使用 Ollama 在本地运行大型语言模型,以及利用 Open-WebUI 提供的图形化界面与大语言模型进行交互。
-
一、Ollama 简介
-
二、Docker安装 Ollama
-
三、Open-WebUI
-
四、文档链接
一、Ollama 简介
Ollama 是一个开源框架,专门设计用于在本地运行大型语言模型(LLM)。它的主要特点和功能如下:
-
简化部署:Ollama 旨在简化在 Docker 容器中部署 LLM 的过程,使得管理和运行这些模型变得更加容易。安装完成后,用户可以通过简单的命令行操作启动和运行大型语言模型。例如,要运行 Gemma 2B 模型,只需执行命令
ollama run gemma:2b。 -
捆绑模型组件:它将模型权重、配置和数据捆绑到一个包中,称为 Modelfile,这有助于优化设置和配置细节,包括 GPU 使用情况。
-
支持多种模型:Ollama 支持多种大型语言模型,如 Llama 2、Code Llama、Mistral、Gemma 等,并允许用户根据特定需求定制和创建自己的模型。
-
跨平台支持:支持 Windows、macOS 和 Linux 平台。安装过程简单,用户只需访问 Ollama 的官方网站下载相应平台的安装包即可。
二、Docker安装 Ollama
选择Deep Learning类型的AMI,这个类型的AMI已经预先安装了英伟达的驱动。
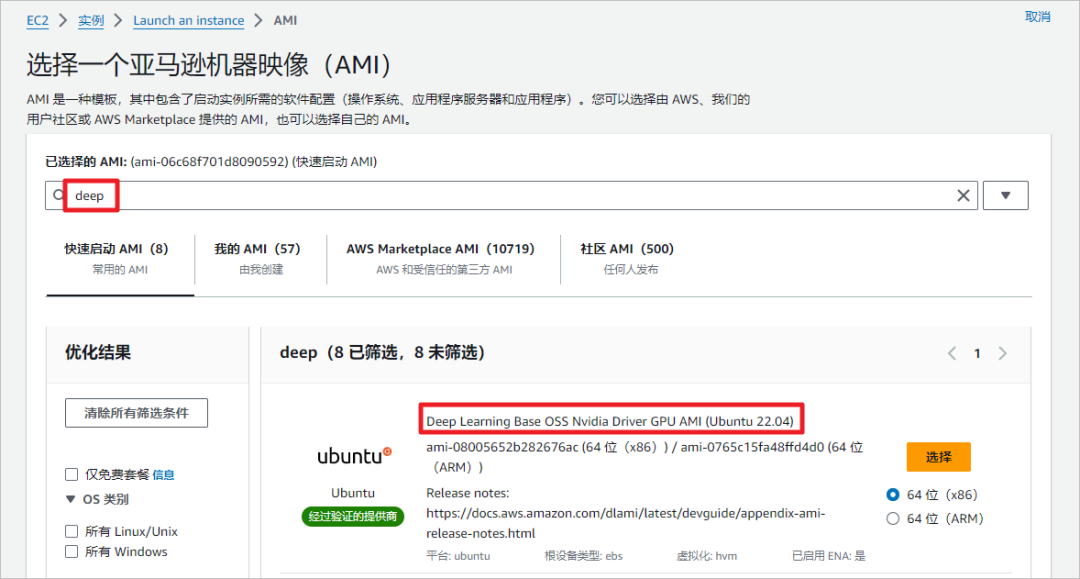
选择g4dn.xlarge类型实例,带有1个NVIDA T4显卡,共有16GB GPU,这是带有英伟达显卡最便宜的实例。这个AMI已经预装了docker包,如果没有安装的Ubuntu系列系统,可以通过下面命令安装。
apt update -y apt install docker -y systemctl start docker
拉取ollama docker镜像(依赖网速,2-3分钟左右)
docker pull ollama/ollama
查看镜像文件,镜像大概2GB左右。
~# docker images REPOSITORY TAG IMAGE ID CREATED SIZE ollama/ollama latest d5cbea22fd07 30 hours ago 1.98GB
根据Docker Hub ollama主页 https://hub.docker.com/r/ollama/ollama [1],快速启动容器,注意,这里没有添加GPU参数,是通过CPU加载启动的。
~# docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
查看容器状态。
root@ip-172-31-83-158:~# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e43072764685 ollama/ollama "/bin/ollama serve" 6 seconds ago Up 5 seconds 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollama
在docker容器内运行模型(1分钟左右拉起来)。
root@ip-172-31-83-158:~# docker exec -it ollama bash root@e43072764685:/# ollama run qwen2:0.5b >>> 你叫什么? 我叫通义千问。
新开一个SSH窗口,在模型回答问题时,查看通过top命令,查看CPU使用率,可以看到CPU已经满负荷运行了,正在使用CPU进行推理。
top - 08:41:19 up 5:14, 4 users, load average: 0.32, 0.25, 0.13 Tasks: 161 total, 3 running, 158 sleeping, 0 stopped, 0 zombie %Cpu(s): 31.9 us, 0.2 sy, 0.0 ni, 67.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st MiB Mem : 15779.1 total, 1575.5 free, 518.2 used, 13685.4 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 14806.4 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 7080 root 20 0 1067764 442088 344752 R 123.3 2.7 0:17.46 ollama_llama_se 7006 root 20 0 2365904 400032 389632 S 1.0 2.5 0:13.81 ollama 6986 root 20 0 1238716 13636 9856 S 0.7 0.1 0:00.23 containerd-shim
通过ollama list命令,查看下载的所有模型。
root@e43072764685:/# ollama list NAME ID SIZE MODIFIED qwen2:0.5b 6f48b936a09f 352 MB About a minute ago
在模型回答问题时,通过nvidia-smi命令查看GPU使用情况,通过CPU进行推理时,看到并没有暂用GPU资源。
root@ip-172-31-83-158:~# nvidia-smi Fri Jul 5 08:41:38 2024 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 | | N/A 33C P8 9W / 70W | 2MiB / 15360MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | No running processes found | +---------------------------------------------------------------------------------------+
删除容器。
root@ip-172-31-83-158:~# docker rm -f ollama ollama
重启启动ollama容器,通过GPU启动。
root@ip-172-31-83-158:~# docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama b094349fc98c8dee31640485ed88ecef38202e33baadcbb9d503ecc1055ac974
Ollama 环境变量
通过下面命令,ollama可以加载环境变量,可以根据实际需求决定是否添加对应的环境变量。
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama --restart always -e OLLAMA_KEEP_ALIVE=-1 ollama/ollama
“
ollama常用环境变量:
OLLAMA_KEEP_ALIVE=-1,模型加载后,默认的Keepalive是5分钟,修改为-1可以让模型持续启动,OLLAMA_KEEP_ALIVE=60 表示 60 秒,OLLAMA_KEEP_ALIVE=10m 表示10分钟。https://github.com/ollama/ollama/pull/3094
OLLAMA_ORIGINS=*,跨域访问环境变量,可以用与沉浸式翻译。
”
Ollama 升级
ollama升级过程参考,停止容器后,重新拉取容器启动即可。
root@ip-172-31-83-158:~# docker exec -it ollama bash root@3d1be8deba41:/# ollama -v ollama version is 0.1.40 (base) root@ip-172-31-79-195:~# docker pull ollama/ollama Using default tag: latest latest: Pulling from ollama/ollama 7646c8da3324: Pull complete d1060ab4fb75: Pull complete e58f7d737fbb: Pull complete Digest: sha256:4a3c5b5261f325580d7f4f6440e5094d807784f0513439dcabfda9c2bdf4191e Status: Downloaded newer image for ollama/ollama:latest docker.io/ollama/ollama:latest (base) root@ip-172-31-79-195:~# docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 -e OLLAMA_ORIGINS=* --name ollama --restart always ollama/ollama root@46648320fcd4:/# ollama -v ollama version is 0.3.7
三、Open-WebUI
OpenWebUI是一个可扩展、功能丰富且用户友好的自托管WebUI,它支持完全离线操作,并兼容Ollama和OpenAI的API。这为用户提供了一个可视化的界面,使得与大型语言模型的交互更加直观和便捷 [3]。
从docker hub拉取open-webui镜像(文件1G左右,看网速,2-3分钟)
docker pull dyrnq/open-webui:main
注意,官方文档是从 GitHub Container Registry (GHCR) 上拉取镜像,而不是从 Docker Hub。官方文档拉取命令如下:
docker pull ghcr.io/open-webui/open-webui:main
查看镜像
root@ip-172-31-83-158:~# docker images REPOSITORY TAG IMAGE ID CREATED SIZE dyrnq/open-webui main 8aa8279a3e25 10 hours ago 3.9GB ollama/ollama latest d5cbea22fd07 30 hours ago 1.98GB
启动docker镜像,映射出来3000端口。
root@ip-172-31-83-158:~# docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always dyrnq/open-webui:main
查看EC2的公网IP地址。
root@ip-172-31-83-158:~# curl ifconfig.me 54.243.6.37
访问Open WebUI。
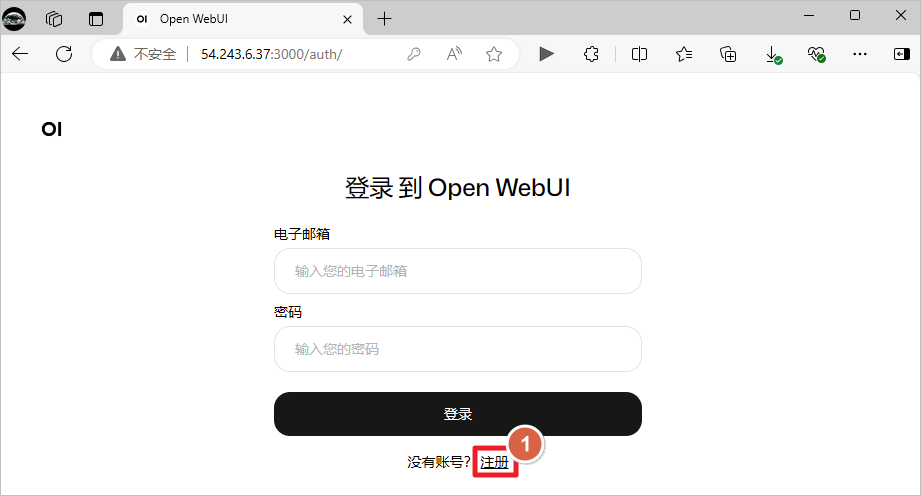
创建账号,这个是本地账号,随便添加账号信息即可。
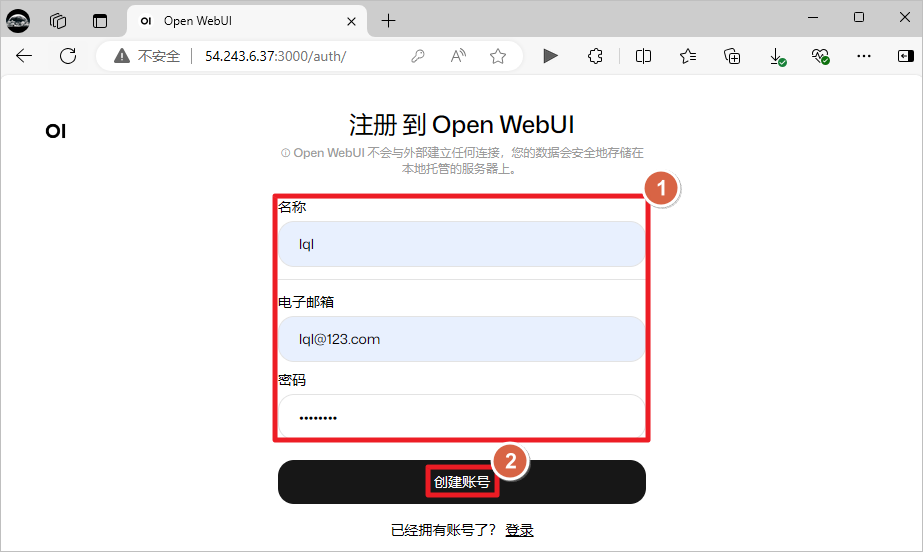
选择ollama中的模型,聊天测试。
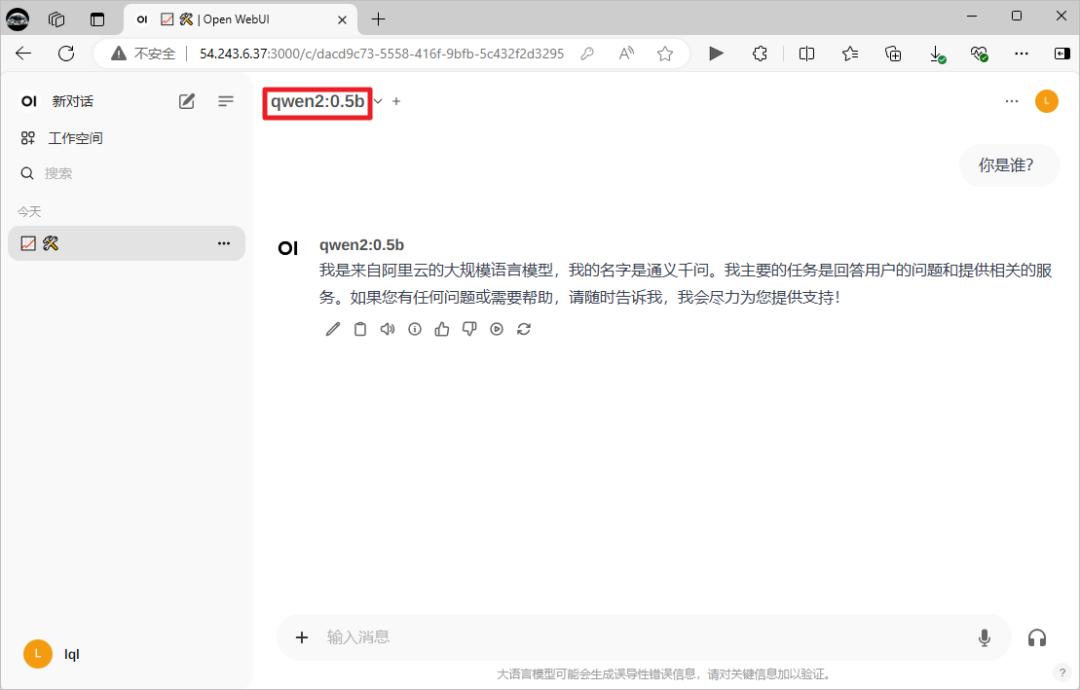
可以直接拉取目前ollama没有的模型。
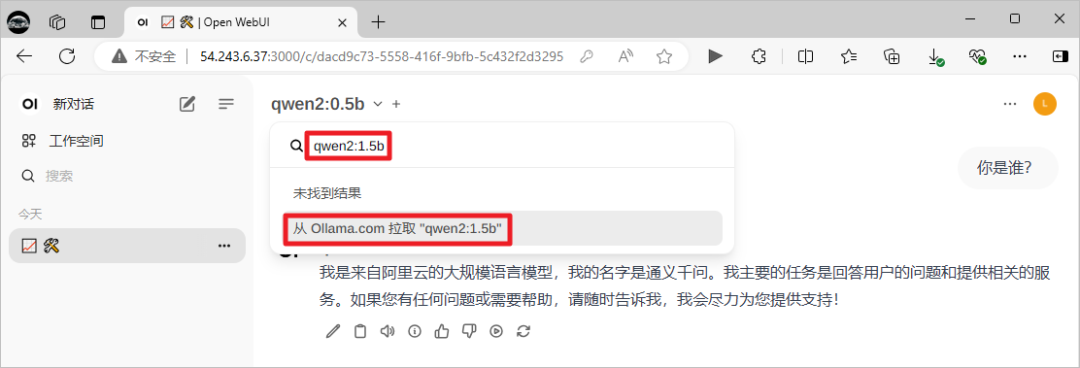
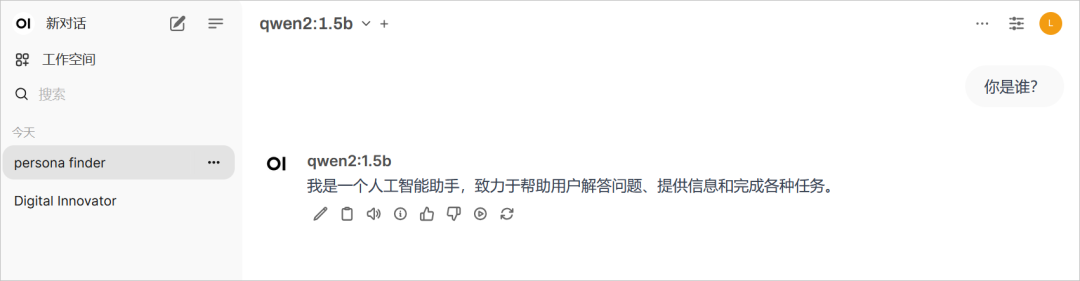
与下载的新模型进行对话。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 30
30 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)