
在m4芯片的macbook pro上部署并推理deepseek-r1到底能有多快呢
最近deepseek的战绩席卷全球,成为开源第一大模型。我正好有一台m4pro芯片的macbook pro,让我们看看如何在mbp上跑deepseek-r1,并测试一下速度。
首先查看一下电脑配置,我的电脑是24G+512G的m4 pro芯片的macbook。

然后看一下deepseek-r1有哪些模型
因为内存只有24G,所以32B以上模型是跑不了的,我这次就测试蒸馏后的14B模型。
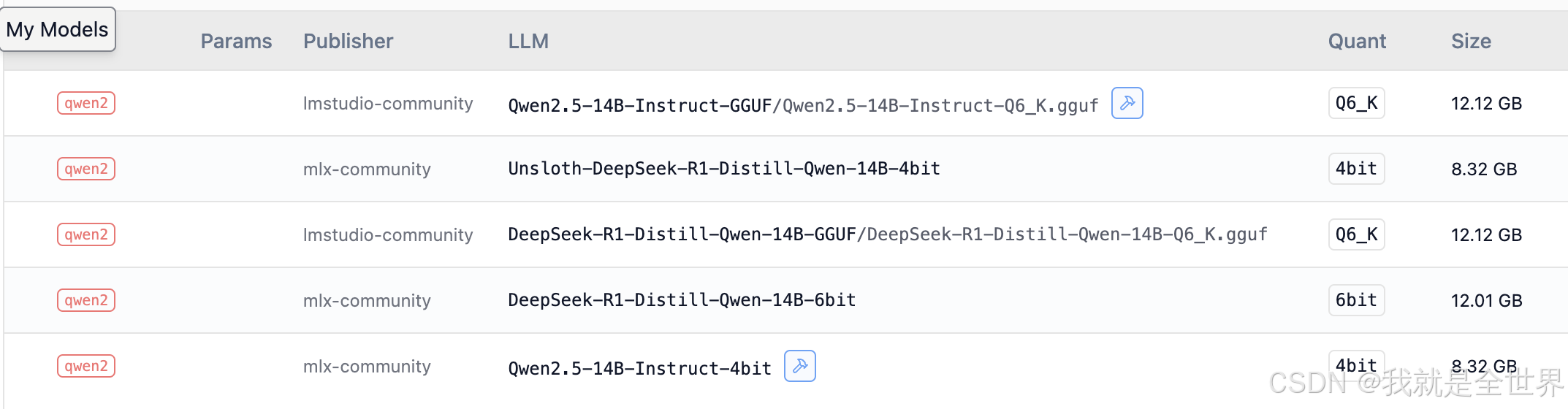
因为看模型报告对qwen2.5蒸馏后的模型性能比qwen2.5本身要好的多,所以也会加入qwen2.5的测试。还有gguf格式模型和苹果本身mlx引擎到底有什么不同。也会测试各模型的推理速度,让我们一起看看吧。
Qwen2.5-14B-Instruct-4bit
context length上下文长度:12K
mlx引擎推理效果: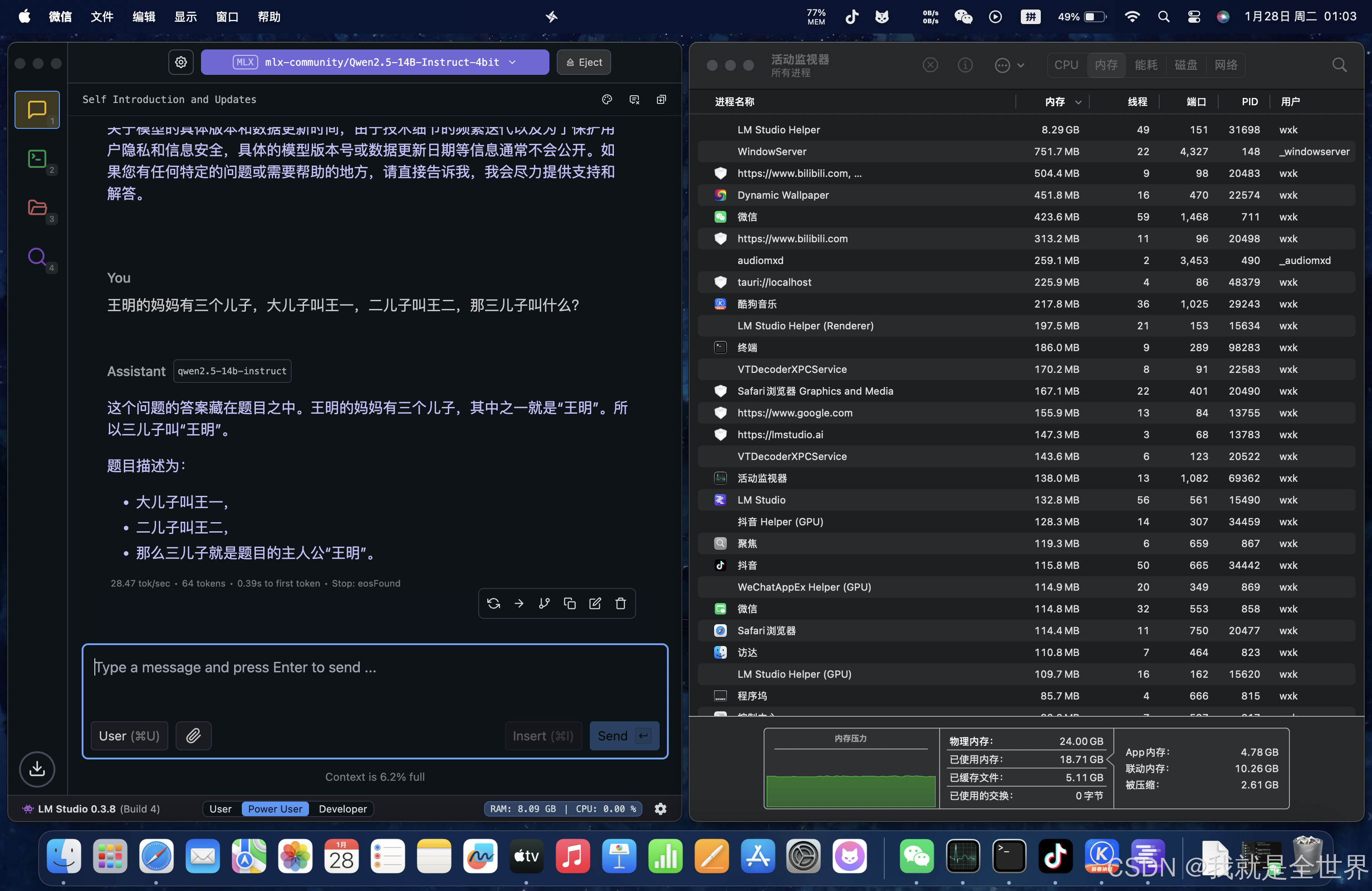
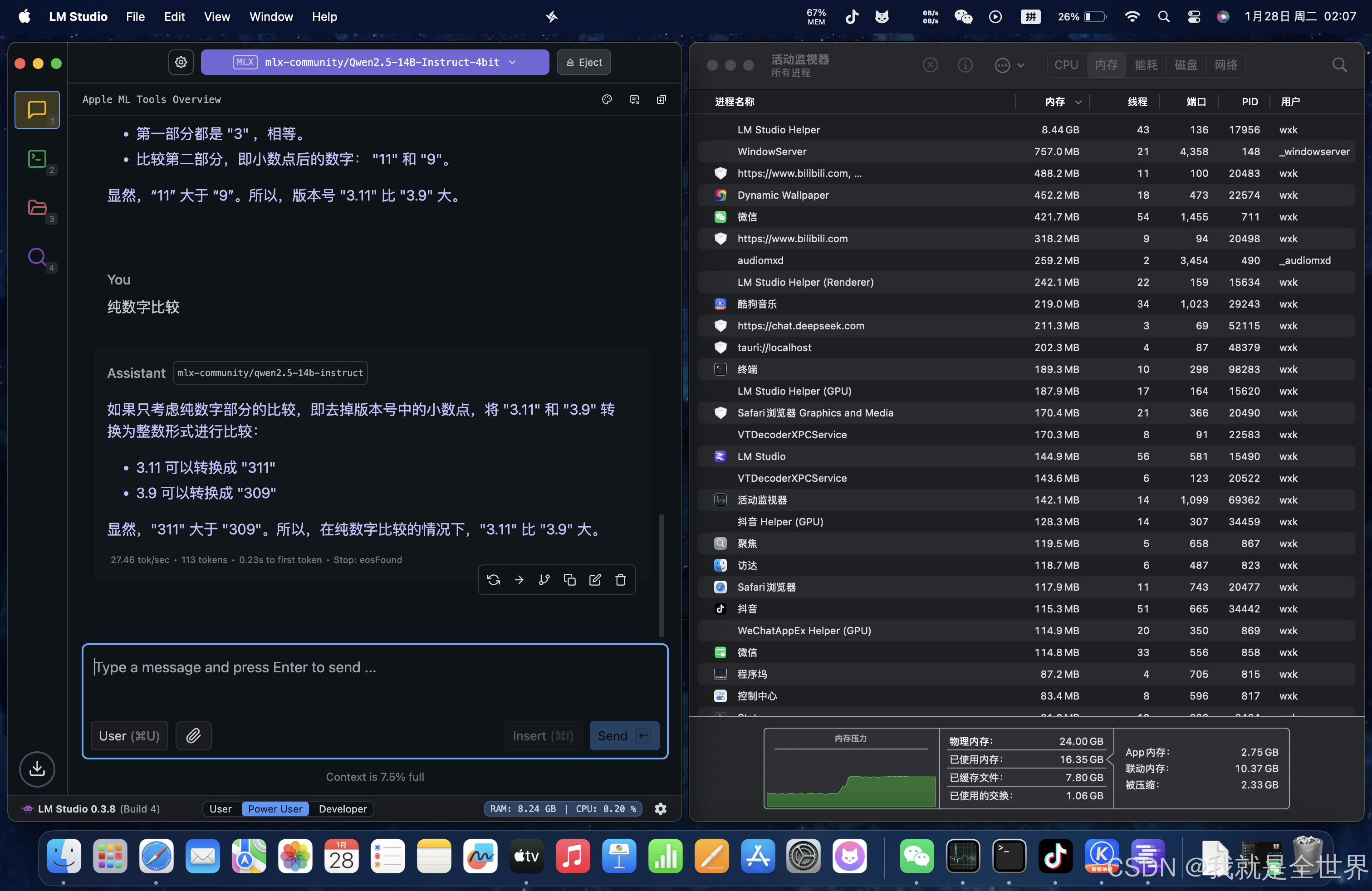
生成速度平均:28 tokens/s,0.4s to first token,总占用内存18.7G.
GGUF 推理效果: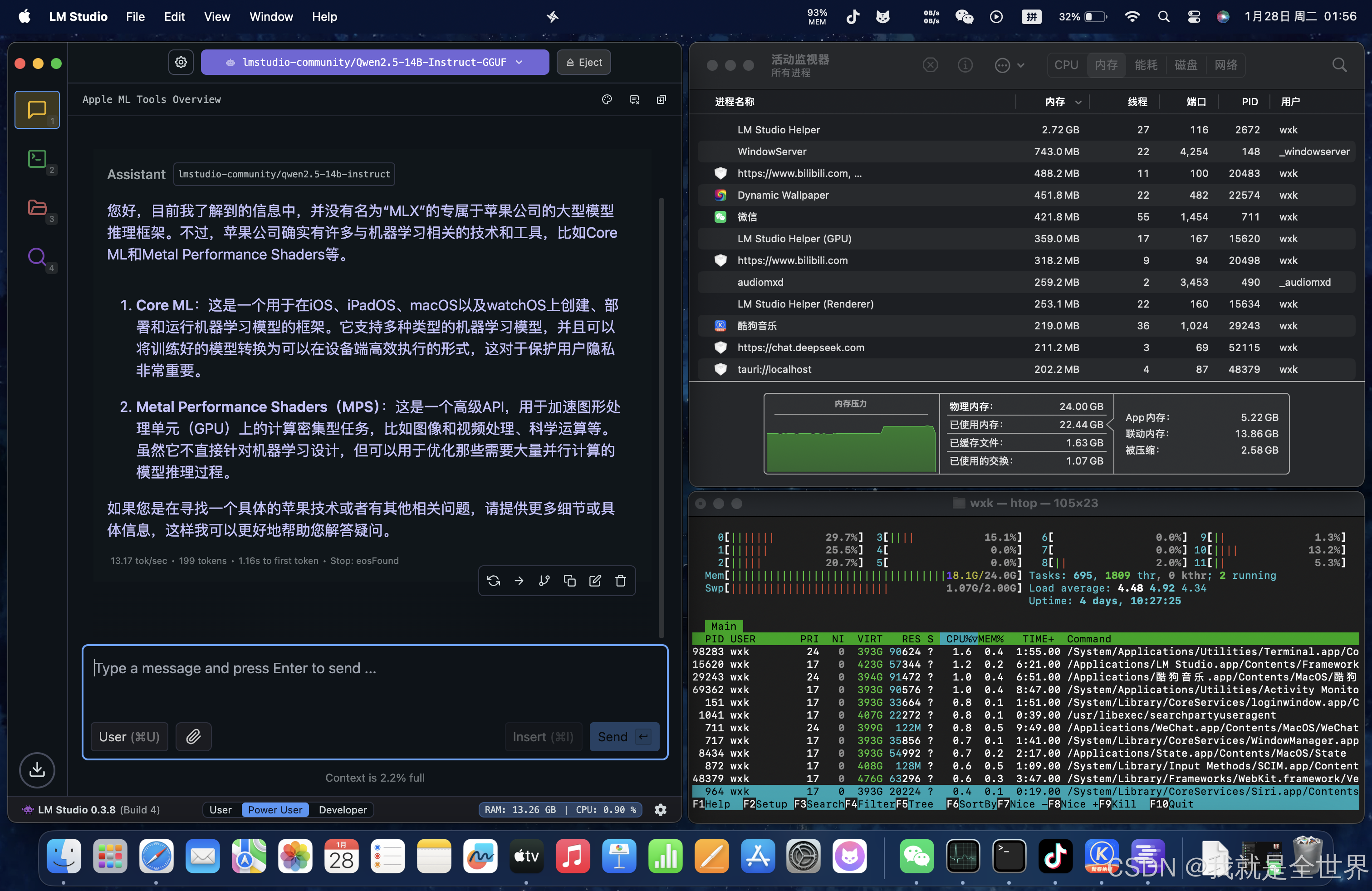
生成速度平均:13 tokens/s,1.16s to first token,总占用内存22.44G.
DeepSeek-R1-Distill-Qwen-14B-bit
mlx推理引擎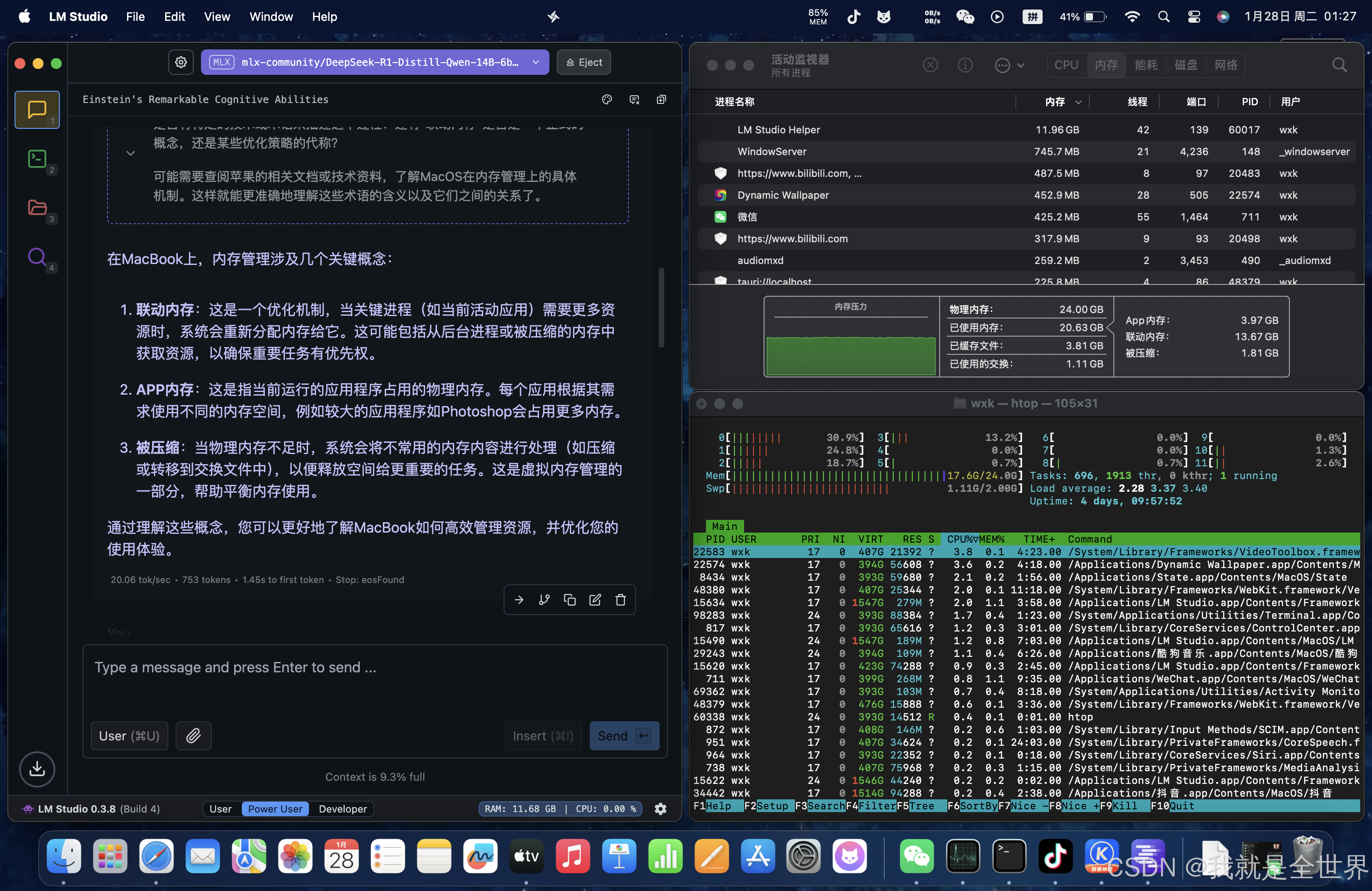
生成速度平均:20 tokens/s,1.45s to first token,总占用内存20G.
当然我也测试了unsloth微调优化的deepseek-r1-distill-qwen-14b-bit
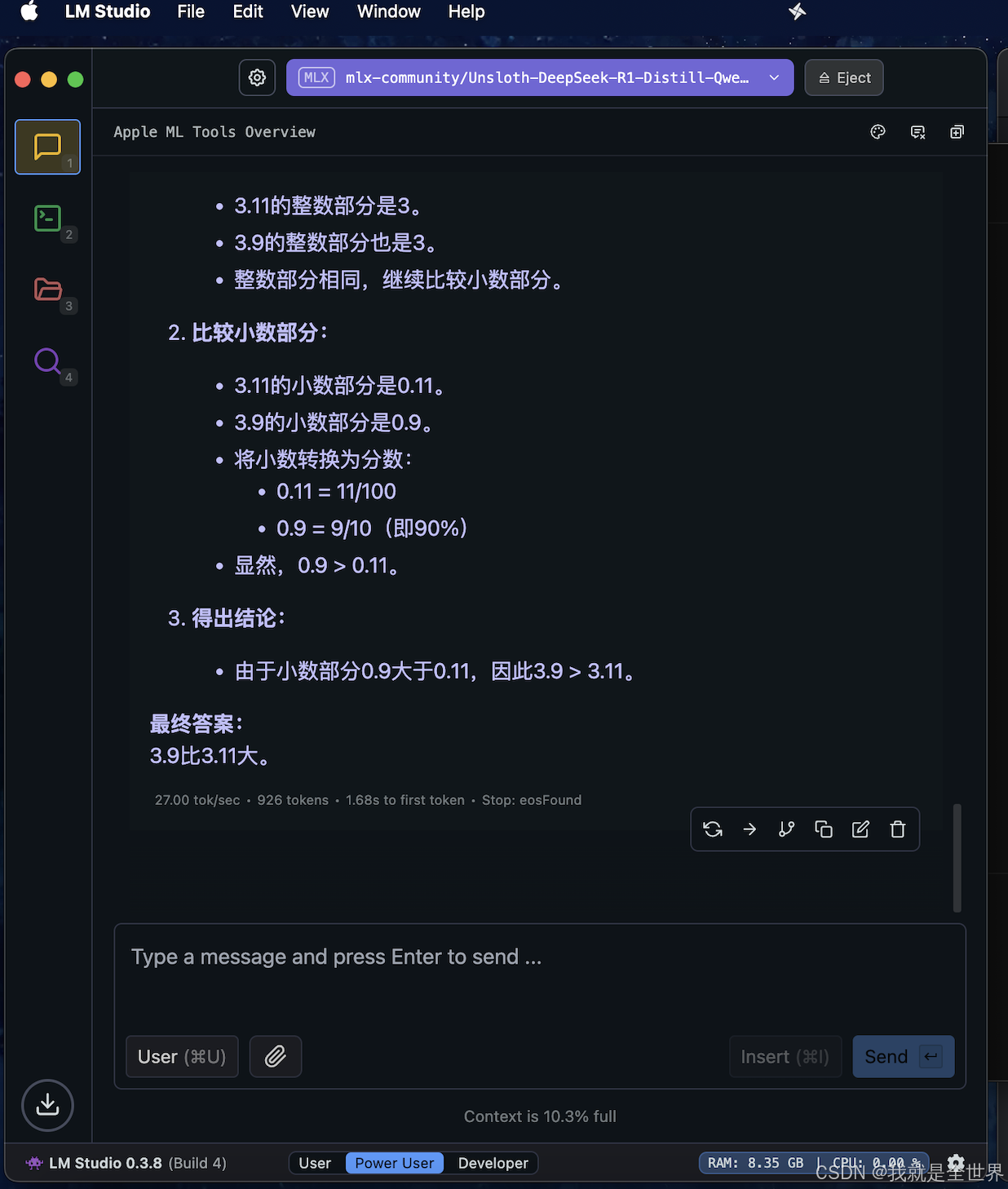
可以看到速度是真的快,生成速度27tokens/sec, 1.68s to first token
对比看,deepseek-r1蒸馏后的qwen-14B准确率确实要比qwen2.5要高,一个3.11和3.9哪个大的问题,deepseek-r1可以回答正确,但qwen2.5回答有明显错误。而速度来看,qwen2.5是最快的,其次是unsloth-deepseek-r1,然后是deepseek-r1,在m4 pro上都能达到20多tokens/s的速度。
总体来看,如果想在本地运行并使用大模型,推荐unsloth-deepseek-r1-qwen-14b-6bit这个模型,速度和回答准确率都不错!
搜索微信公众号“坤塔”并关注,快速发现不一样的世界!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)