
Ollama、vLLM以及LMDeploy部署模型
·
1.VScode远程连接autodl并创建虚拟环境
conda create -n bigmodel python==3.10
conda activate bigmodel
# 配置pip安装加速:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121
2.大模型本地化部署
2.1 Ollama部署模型qwen3
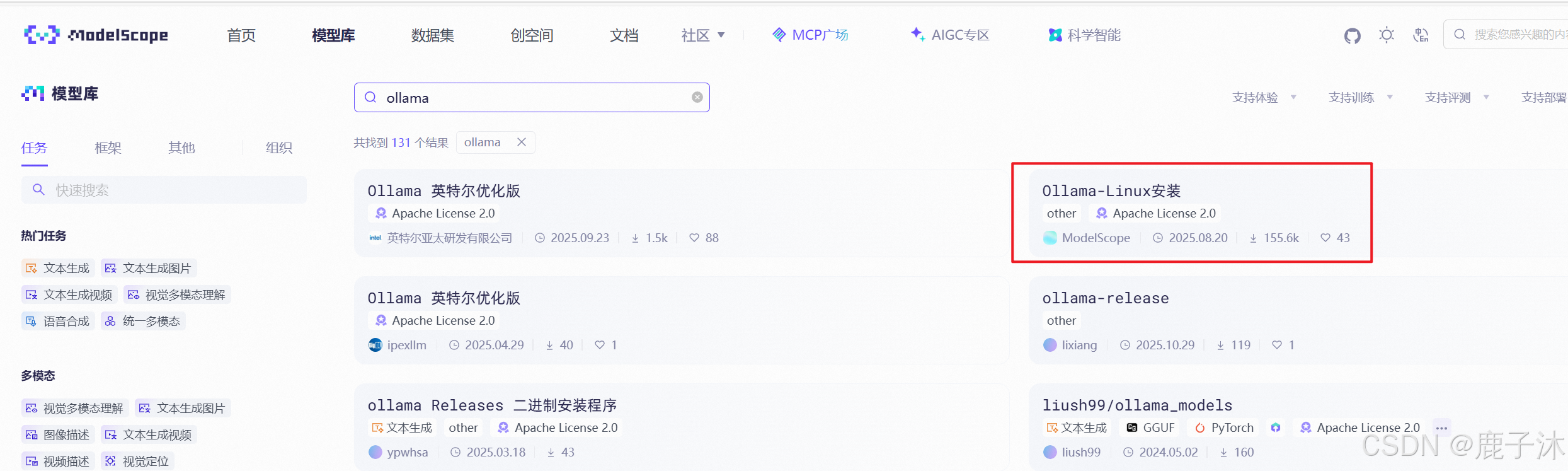
1. 在安装之前先安装一下魔塔社区
pip install modelscope
使用命令行下载:
# 使用命令行前,请确保已经通过pip install modelscope 安装ModelScope。
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux --revision v0.11.5
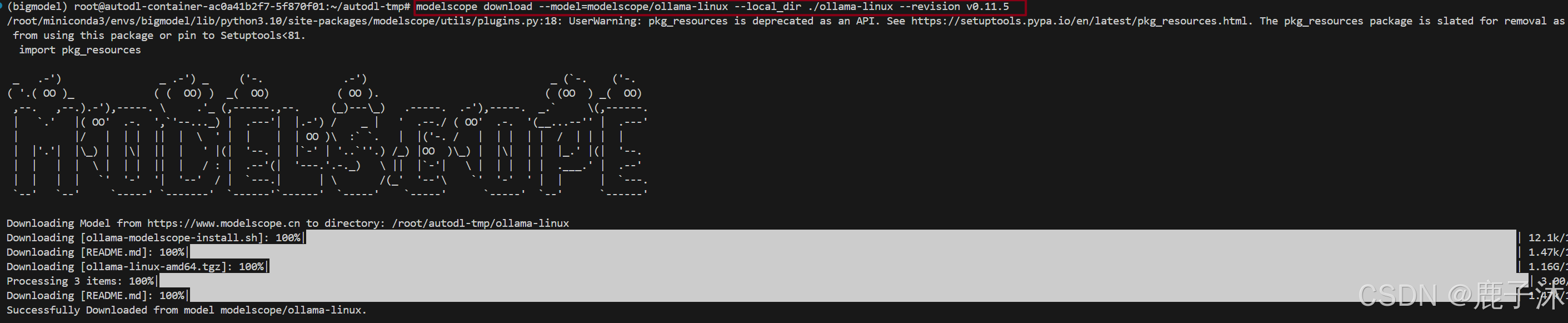
2. 安装ollama
# 运行ollama安装脚本
cd ollama-linux
sudo chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh
也可以通过git clone来下载安装包:
#Git clone,可以使用--depth 1选项减少下载的git历史文件
git clone https://www.modelscope.cn/modelscope/ollama-linux.git --depth 1 --branch v0.11.5
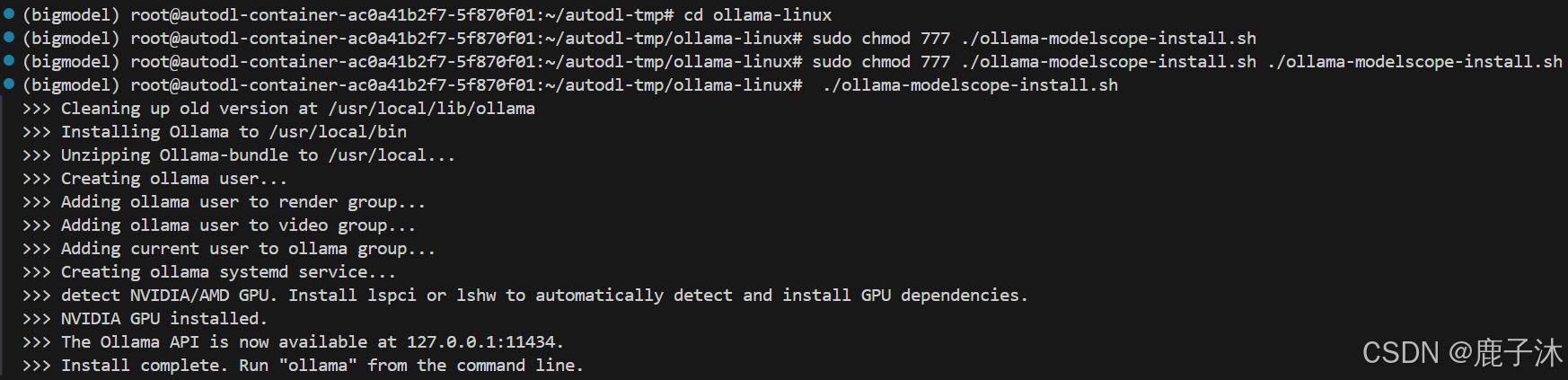
3. 开启服务
ollama serve
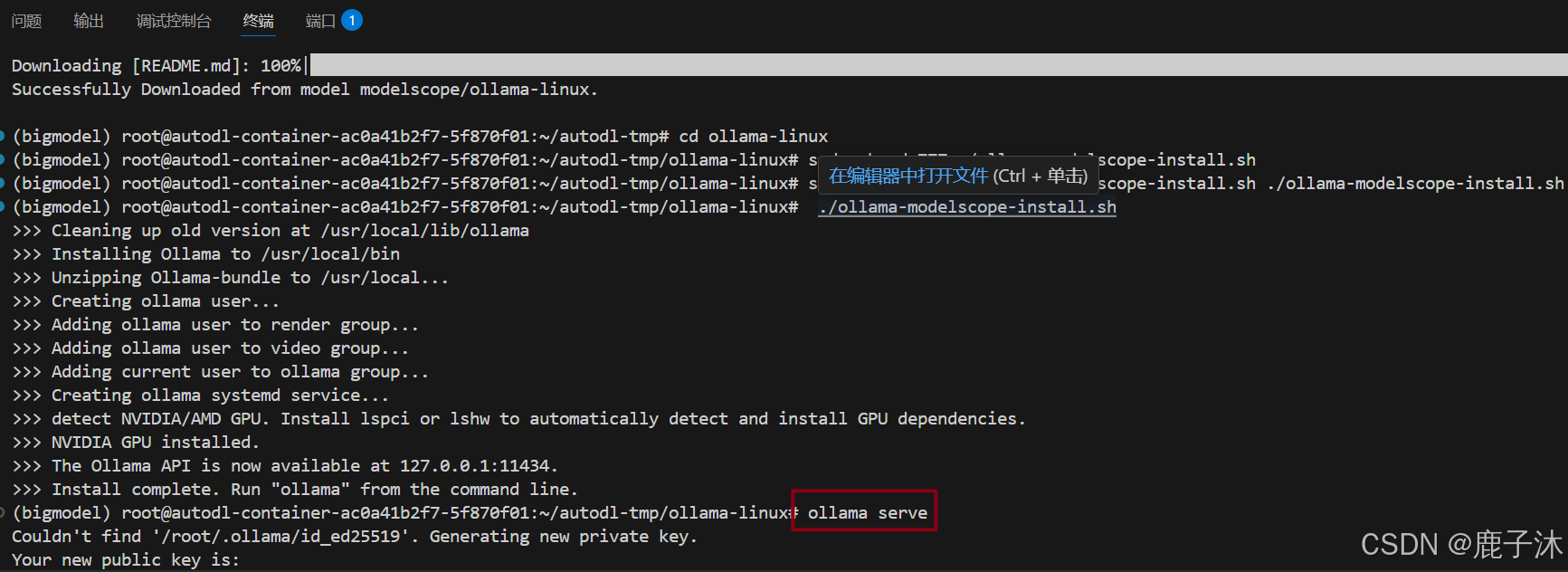
开启服务后此终端窗口不能关闭,新打开一个窗口
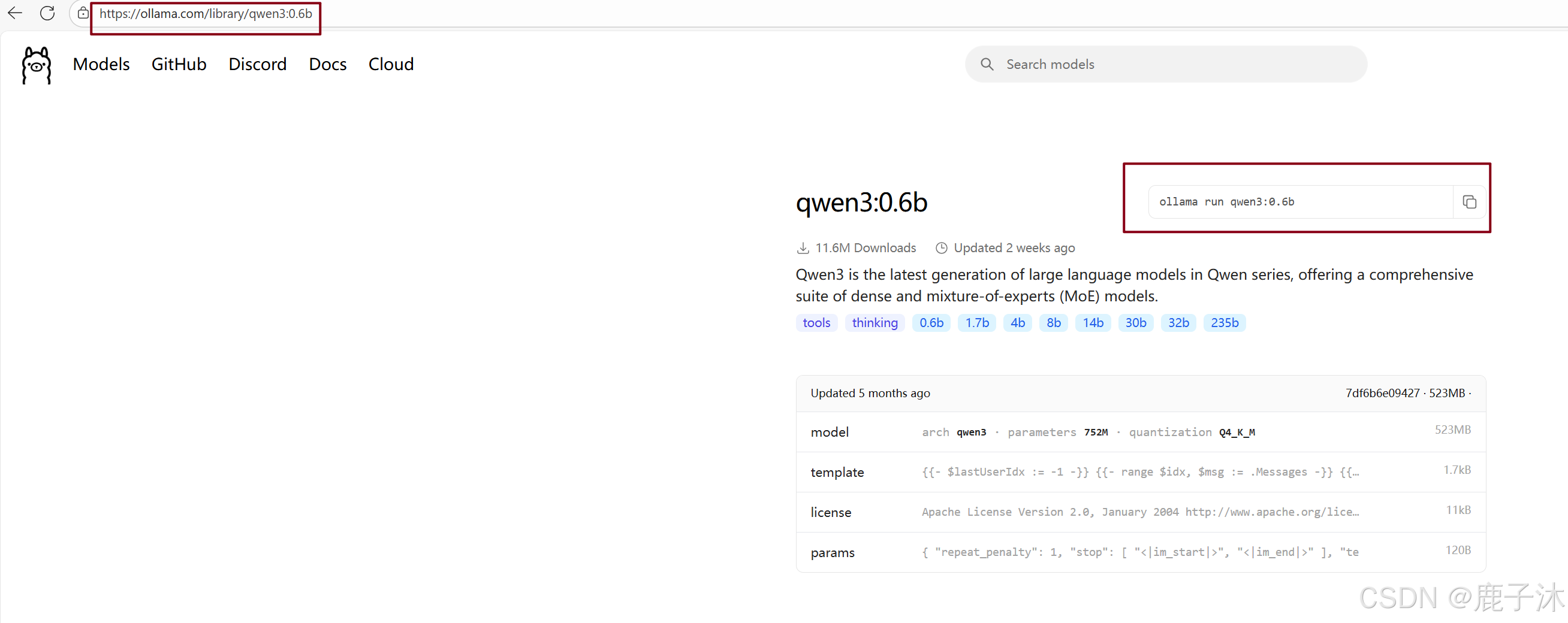
4. 自动将模型拉取到服务器上
ollama run qwen3:0.6b
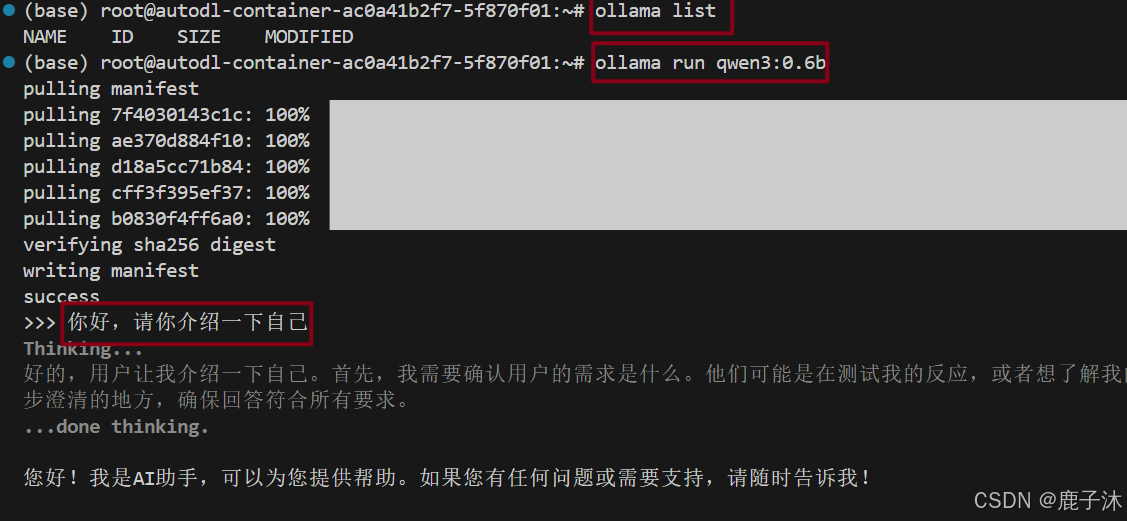 结束对话:
结束对话:
/exit

注:
- ollama只适用于个人,由于魔塔社区上qwen3:0.6B是1.5G,而ollama中是522M,ollama是轻量级本地部署框架,上面的模型是进行过量化压缩的
- ollama只能跑gguf的模型
从魔塔社区上下载未量化压缩的: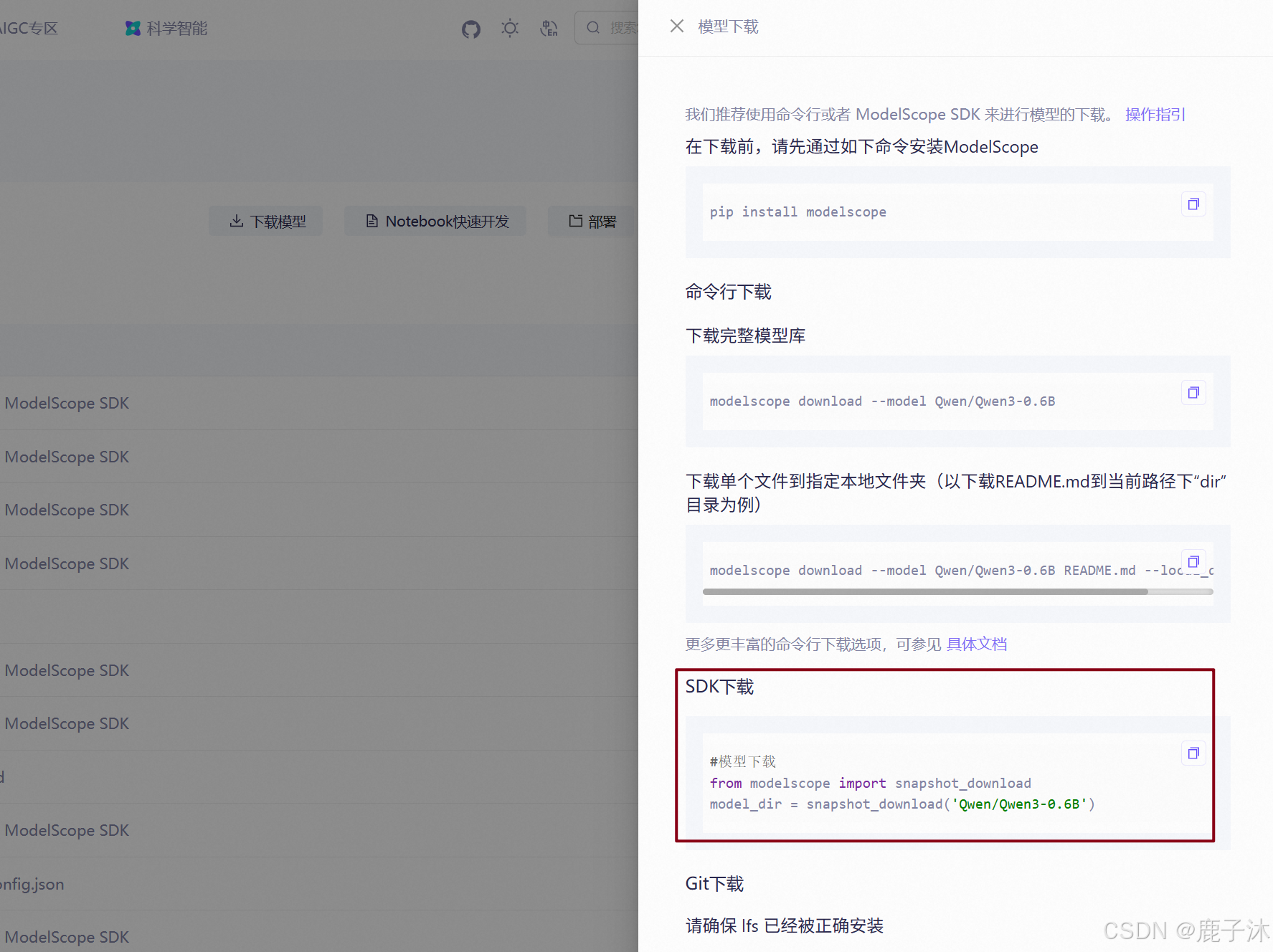

2.2 vLLM部署模型
- 部署要求
操作系统:Linux
Python:3.9-3.12
GPU算力在7.0以上:V100、T4、RTX20xx、A100、L4、H100等
vllm官方文档:https://docs.vllm.com.cn/en/latest/getting_started/quickstart.html
conda create -n vllm python=3.12 -y
conda activate vllm
pip install vllm
- 开启服务
vllm serve /root/autodl-tmp/Qwen/Qwen3-0.6B
会出现一个转发端口
- 使用api调用本地模型
# 使用openai的API风格调用本地模型
from openai import OpenAI
client=OpenAI(base_url = "http://localhost:8000/v1/", api_key="suibianxie")
chat_completion = client.chat.completions.create(
messages=[{"role":"user", "content":"你好,请介绍下你自己。"}], model = "/root/autodl-tmp/Qwen/Qwen3-0.6B"
)
print(chat_completion.choices[0])

注:显存会占满,因为vllm框架在占显存,不是模型占显存,当服务停止后,显存才会释放
2.2 LMDeploy部署模型
官方文档:https://lmdeploy.readthedocs.io/zh-cn/latest/
- 环境部署
python:3.9-3.13
CUDA:11.3以上
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy
- 部署模型
lmdeploy serve api_server /root/autodl-tmp/Qwen/Qwen3-0.6B

# 使用openai的API风格调用本地模型
from openai import OpenAI
client=OpenAI(base_url = "http://localhost:23333/v1/", api_key="suibianxie")
chat_completion = client.chat.completions.create(
messages=[{"role":"user", "content":"你好,请介绍下你自己。"}], model = "/root/autodl-tmp/Qwen/Qwen3-0.6B"
)
print(chat_completion.choices[0])

3. 补充
- 调用本地ollama中的deepseek模型进行单轮对话
#使用openai的API风格调用ollama
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1/",api_key="suibianxie")
chat_completion = client.chat.completions.create(
messages=[{"role":"user","content":"你好,请介绍下你自己。"}],model="deepseek-r1:1.5b"
)
print(chat_completion.choices[0])
- 调用本地ollama中的deepseek模型进行多轮对话
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:11434/v1/",api_key="suibianxie")
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="deepseek-r1:latest")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()
- 先加载模型,后加载分词器
将模型从魔塔社区下载下来
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen1.5-1.8B-Chat', cache_dir='/root/autodl-tmp')
加载模型
#使用transformer加载qwen模型
from transformers import AutoModelForCausalLM,AutoTokenizer
DEVICE = "cuda"
#加载本地模型路径为该模型配置文件所在的根目录
model_dir = "/root/autodl-tmp/Qwen/Qwen1.5-1.8B-Chat"
#使用transformer加载模型
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype="auto",device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_dir)
#调用模型
#定义提示词
prompt = "你好,请介绍下你自己。"
#将提示词封装为message
message = [{"role":"system","content":"You are a helpful assistant system"},{"role":"user","content":prompt}]
#使用分词器的apply_chat_template()方法将上面定义的消息列表进行转换;tokenize=False表示此时不进行令牌化
text = tokenizer.apply_chat_template(message,tokenize=False,add_generation_prompt=True)
#将处理后的文本令牌化并转换为模型的输入张量
model_inputs = tokenizer([text],return_tensors="pt").to(DEVICE)
#将数据输入模型得到输出
response = model.generate(model_inputs.input_ids,max_new_tokens=512)
print(response)
#对输出的内容进行解码还原
response = tokenizer.batch_decode(response,skip_special_tokens=True)
print(response)
- 补充知识
大模型推理速度:lmdeploy > vllm > ollama > huggingface
一般huggingface的推理主要是验证模型微调后的效果,排除由于框架的差异性所导致的效果误差

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)