
本地跑大模型:Xoribits、OpenLLM、LocalAI、ChatGLM、Ollama、NVIDIA TIS 解析
- 全景速览
| 框架 | 定位 | 是否分布式 | 异构硬件 | API 兼容 | 2025-08 最新版本 |
|---|---|---|---|---|---|
| Xoribits Inference | 企业级大模型推理平台 | ✅ 原生分布式 | GPU/CPU/MPS | OpenAI 100% | v0.15.3 |
| OpenLLM | 云原生 LLM PaaS | ✅ K8s 原生 | GPU/CPU | OpenAI | 0.6.x |
| LocalAI | 本地轻量 OpenAI 替代 | ❌ 单机 | CPU/GPU(GGML) | OpenAI 100% | v2.16 |
| ChatGLM | 中文大模型系列 | ❌ 官方脚本 | GPU | OpenAI-like | 4.0 |
| Ollama | 极简本地运行器 | ❌ 单机 | GPU/CPU | REST+CLI | 0.3.x |
| NVIDIA TIS | 生产级 GPU 推理服务 | ✅ 多节点 | GPU/CPU | HTTP/gRPC/KServe | 25.02 |
- 详细解析
2.1 Xoribits Inference(Xinference)——“国产之光,企业首选”

- • 核心卖点
- • 一条命令拉起 50+ 开源模型(Baichuan、ChatGLM、Qwen、Yi…)
- • 原生分布式:内置调度器,可按模型大小把不同副本分配到不同节点
- • 异构加速:vLLM/SGLang/Llama.cpp/Transformers 四引擎自由切换
- • 企业特性:不停机滚动升级、高可用、密钥管理、日志审计
- • 安装体验
conda create -n xi python=3.10pip install "xinference[all]" # 一次装全xinference launch --model-name chatglm3 --size-in-billions 6 --endpoint http://0.0.0.0:9997
浏览器打开 http://localhost:9997 即可对话;生产环境用 xinference-supervisor + xinference-worker 组成集群。
- • 适用场景
需要“私有化+高吞吐+可观测”的企业级 AIGC、智能客服、知识库。
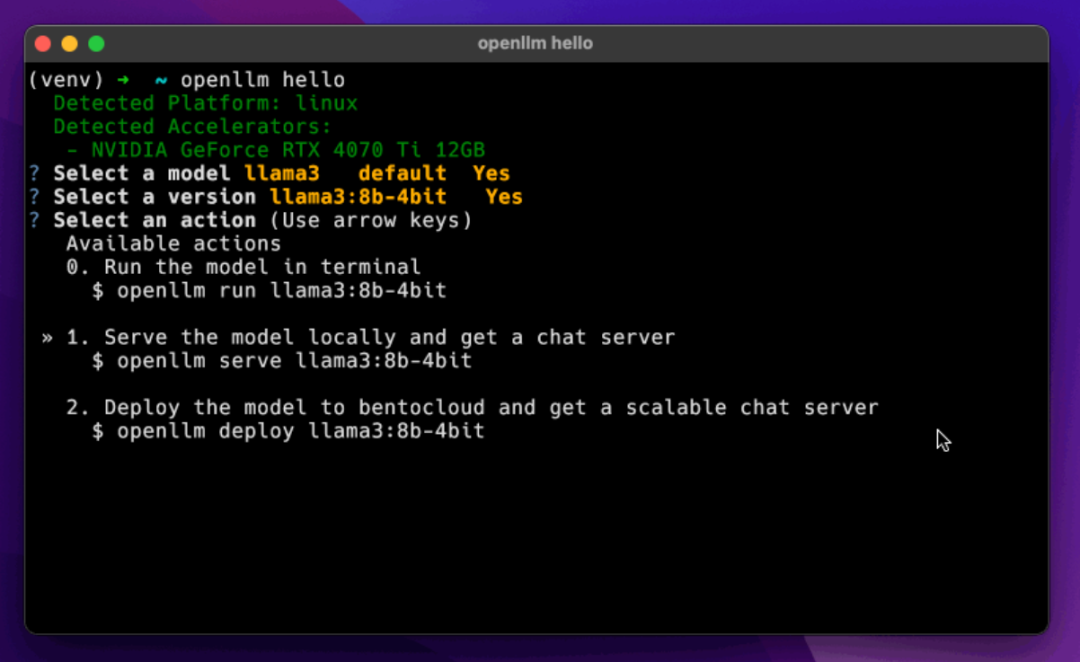
2.2 OpenLLM——“Kubernetes 时代的 LLM PaaS”
-
• 架构亮点```plaintext
openllm build llama3.1:8b-4bitopenllm serve llama3.1:8b-4bit --production --workers 4
-
• 原生对接 K8s、BentoCloud,支持自动扩缩。
-
• 三层设计:模型服务层 / API 兼容层 / 部署管理层
-
• 一条命令构建 Bento:
- • 优势
多云混合交付、DevOps 友好、支持微调后再打包成镜像。 - • 局限
对 GPU Driver/CUDA 版本有强依赖;需要懂 K8s;单机小实验反而显得重。
2.3 LocalAI——“CPU 救星,OpenAI 平替”

- • 技术原理
纯 Go + C++ 绑定,llama.cpp / whisper.cpp / bert.cpp 全家桶;ggml/q4_0 量化后 6B 模型在 4C8G 笔记本也能跑。 - • 启动最快
docker run -p 8080:8080 localai/localai:latest-aio-cpucurl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{"model": "ggml-gpt4all-j", "messages":[{"role":"user","content":"Hello"}]}'
- • 最佳用法
把 OpenAI SDK 的base_url指向 LocalAI,零改动迁移已有应用。
2.4 ChatGLM —— 中文语境下的“小而美”

- • 模型矩阵
ChatGLM-6B(基座)→ ChatGLM2-6B(推理速度↑)→ ChatGLM3-6B(工具调用)→ GLM-4-9B(2024 新版) - • 落地姿势
-
- 直接用 Ollama 一行命令
ollama run chatglm3;
- 直接用 Ollama 一行命令
-
- 或用 Xinference/OpenLLM 把 ChatGLM 作为后端,获得 REST API。
- • 注意
官方原始脚本仅支持单机 GPU;生产环境务必套上 Xinference/LocalAI 这类外壳做负载。
2.5 Ollama——“MacBook 上的 LLM 神器”
- • 设计哲学
把模型+环境打包成一个 “Modelfile”,Docker 化思维;安装即用,更新即用。 - • 常用指令
ollama pull llama3.1:8bollama run llama3.1:8b
- • 二次开发
提供 Go SDK & REST API,嵌入桌面应用最方便。 - • 局限
不支持分布式;GPU 多卡并行需要额外脚本。
2.6 NVIDIA Triton Inference Server(TIS)——“极致性能的工业怪兽”
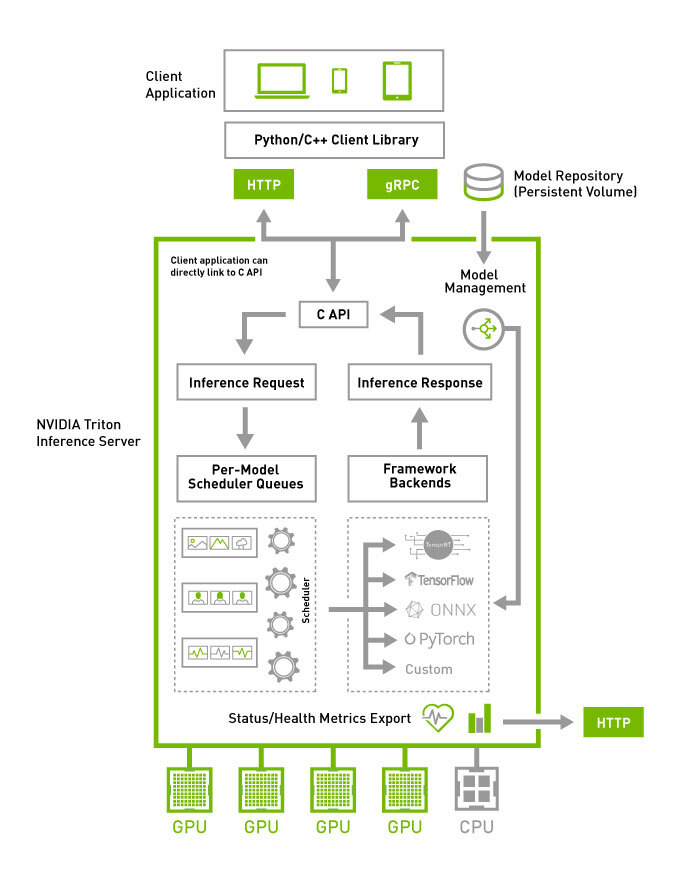
- • 功能一览
- • 支持 TensorRT / PyTorch / ONNX / vLLM 后端
- • 动态批处理、模型并发、多 GPU 流并行
- • KServe & Seldon Core 标准 API,原生 Prometheus 监控
- • 部署示例
# 拉取 25.02 镜像docker run --gpus all -p8000:8000 nvcr.io/nvidia/tritonserver:25.02-py3 tritonserver --model-repository=/models
- • 适用场景
对延迟 < 50 ms、并发 > 1000 QPS 的在线推理,或需要多模型 A/B Test 的金融、广告、搜索场景。
- 如何选型?一张图总结
| 需求 | 首选 | 次选 | 不选 |
|---|---|---|---|
| 公司内网、高可用、多模型 | Xoribits | OpenLLM | Ollama |
| 云原生、K8s 批量交付 | OpenLLM | Xoribits | LocalAI |
| 个人电脑 / CPU 尝鲜 | LocalAI | Ollama | NVIDIA TIS |
| GPU 极限吞吐、极低延迟 | NVIDIA TIS | Xoribits+vLLM | OpenLLM |
| 纯中文对话 demo | ChatGLM3+Ollama | ChatGLM3+Xinference | LocalAI+英文模型 |
- 延伸阅读
- •
Xinference 官方文档:https://inference.readthedocs.io/zh-cn/latest/ - •
OpenLLM 快速开始:https://github.com/bentoml/OpenLLM - •
LocalAI AIO 镜像:https://localai.io/basics/getting_started/ - •
Ollama 模型库:https://ollama.com/library - •
NVIDIA Triton 性能调优白皮书(2025):https://developer.nvidia.com/blog/triton-25-02-tuning-guide/
Happy LLMing!
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 20
20 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)