
Ollama本地部署AI模型详细指南
·
Ollama本地部署AI模型详细指南
引言
- 简要介绍Ollama的核心功能及其在AI模型本地部署中的优势
- 说明本地部署的意义(隐私保护、离线使用、定制化开发等)
- 目标读者群体(开发者、研究者、技术爱好者)
Ollama基础概念
- 访问官网:前往 Ollama 官网。
- 选择版本:点击页面上的 “Download” 按钮。它会自动识别你的操作系统(Windows、macOS 或 Linux)。如果你想下载其他系统的版本,可以点击 “All platforms” 进行选择。
安装:
- Windows:运行下载的 .exe安装程序,按提示完成安装。
- macOS:将下载的 .dmg文件拖入 “Applications” 文件夹。
- Linux:按照官网提供的命令行指令进行安装。
第二步:启动与验证
启动 Ollama:
- Windows/macOS:在开始菜单或启动台中找到 “Ollama” 并点击运行。它会常驻在系统托盘(右下角)或菜单栏(右上角)。
- Linux:在终端中输入 ollama serve启动服务。
验证是否运行成功:
- 打开你的浏览器,访问 http://localhost:11434。
- 如果看到类似 "Ollama is running"的提示,说明服务已成功启动。这是 Ollama 的本地 API 地址。
第三步:下载(拉取)模型
- 这是核心步骤。你可以通过两种方式下载模型:
- 方式一:通过桌面界面(最简单)
- 点击系统托盘/菜单栏中的 Ollama 图标。
- 选择 “View logs & pulls”,这会打开一个命令行窗口。
- 在命令窗口中,输入拉取模型的命令,例如:
ollama pull qwen2.5:7b- 然后按回车。它会开始下载模型,你需要等待下载完成。
- 方式二:通过命令行/终端(通用)
- 直接打开你的终端(Command Prompt, Terminal, PowerShell 等)。
- 输入拉取模型的命令,例如:
ollama pull qwen2.5:7b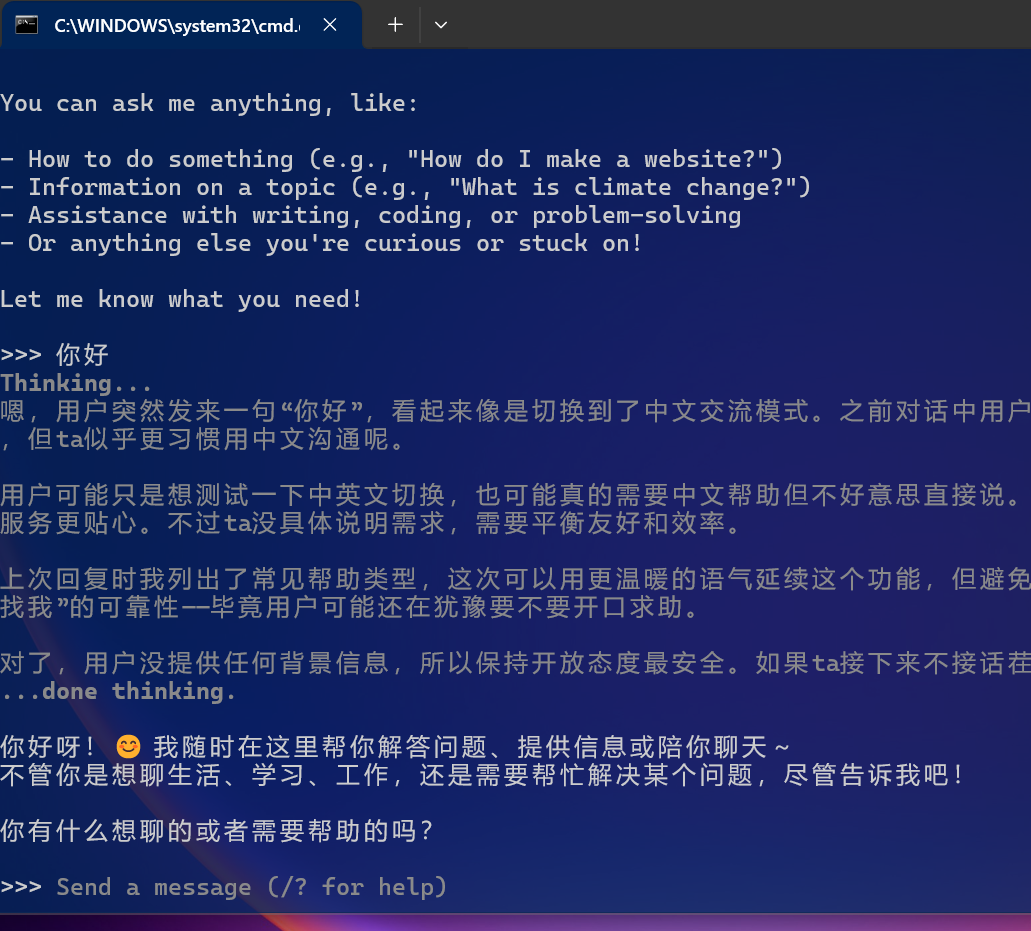
# 运行
ollama run qwen2.5:7b
# 查看已下载模型
ollama list
# 删除旧模型释放空间
ollama rm qwen2.5:7b
# 更新模型到最新版
ollama pull qwen2.5:7b
与Python结合:安装pip install openai
测试代码:
from openai import OpenAI
import time
# 配置本地Ollama服务
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama" # 任意非空字符串即可
)
def query_ollama(prompt: str, model: str = "deepseek-r1:8b", max_tokens=512):
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=max_tokens,
stream=False # 关闭流式获取完整响应
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 测试调用
if __name__ == "__main__":
test_prompt = "你能做什么"
start_time = time.time()
result = query_ollama(test_prompt)
print(f"Response (耗时 {time.time()-start_time:.2f}s):\n{result}")

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)