
AI开发者必看:Qwen3-32B+Ollama镜像快速部署入门指南
AI开发者必看:Qwen3-32B+Ollama镜像快速部署入门指南
想体验媲美顶级商用模型的理解与推理能力,又担心部署复杂、资源消耗大?今天,我们就来聊聊如何通过CSDN星图平台的Ollama镜像,快速、零门槛地部署和使用Qwen3-32B这个大模型。
Qwen3-32B是通义千问系列的最新力作,拥有320亿参数。别看它参数规模不是最大的,但性能表现却相当惊艳,尤其在代码生成、逻辑推理和多语言任务上,能力直逼一些规模更大的模型。对于开发者来说,这意味着你可以用更少的计算资源,获得接近顶级模型的开发体验。
过去,部署这样一个大模型,你可能需要折腾环境、配置参数、处理各种依赖,光是准备工作就能劝退不少人。但现在,通过预置的Ollama镜像,整个过程被简化到了“点击即用”的程度。接下来,我就带你一步步走完这个流程,让你在10分钟内就能和Qwen3-32B对话。
1. 为什么选择Qwen3-32B与Ollama镜像?
在开始动手之前,我们先简单了解一下你即将使用的“利器”。
Qwen3-32B模型有什么特别之处?它是通义千问第三代模型家族中的“实力派”。虽然参数量是320亿,但通过精心的架构设计和海量数据训练,它在多项基准测试中表现出了超越其参数规模的强大能力。简单来说,就是“小而精悍”。对于开发者而言,它的两大优势非常突出:
- 强大的代码能力:无论是代码补全、bug修复,还是根据注释生成整段代码,它都能提供高质量的产出,是编程辅助的得力工具。
- 出色的逻辑推理:在处理需要多步推理、分析复杂问题场景时,它能展现出清晰的思维链,帮助你梳理逻辑。
那么,Ollama又是什么?你可以把它理解为一个专门用于在本地(或云端服务器)运行大型语言模型的“容器”和“管理工具”。它把模型运行所需的所有环境、依赖都打包好了,让你无需关心底层细节,只需要一条简单的命令就能拉取和运行模型。
而CSDN星图平台的Ollama镜像,则是在此基础上更进一步。平台已经为你准备好了包含Ollama和Qwen3-32B模型的完整系统环境,做成了一个“开箱即用”的虚拟机镜像。你只需要在星图平台找到这个镜像,点击部署,就会自动生成一个包含了所有环境的云服务器实例。之后,通过一个内置的Web界面,你就能直接与模型交互,省去了在命令行中操作的所有步骤。
这种组合带来的核心好处就是:极致的便捷性。你不需要购买昂贵的GPU,不需要安装CUDA、PyTorch等复杂的深度学习框架,甚至不需要熟悉Linux命令。整个过程就像使用一个普通的网页应用一样简单。
2. 环境准备:找到并启动镜像
理论说再多,不如动手试一次。整个部署过程只需要在网页上点几下鼠标,我们马上开始。
2.1 第一步:定位Ollama模型入口
首先,你需要进入CSDN星图平台。成功登录后,在平台内找到名为“Ollama”的模型展示或应用入口。这个入口通常在设计上会比较醒目,可能会在“AI模型”、“热门应用”或“镜像广场”等区域。
当你找到类似下图的入口时,直接点击它即可进入Ollama的模型管理界面。 
这个界面就是你和所有通过Ollama管理的模型交互的“控制台”。在这里,你可以看到可用的模型列表,并进行选择和切换。
2.2 第二步:选择Qwen3-32B模型
进入Ollama界面后,你的目光应该聚焦在页面顶部。这里会有一个模型选择的下拉菜单或者输入框,这是整个操作的核心。
点击这个选择框,在模型列表中寻找并选择 qwen3:32b。这个标签就代表了我们今天要使用的320亿参数版本的Qwen3模型。 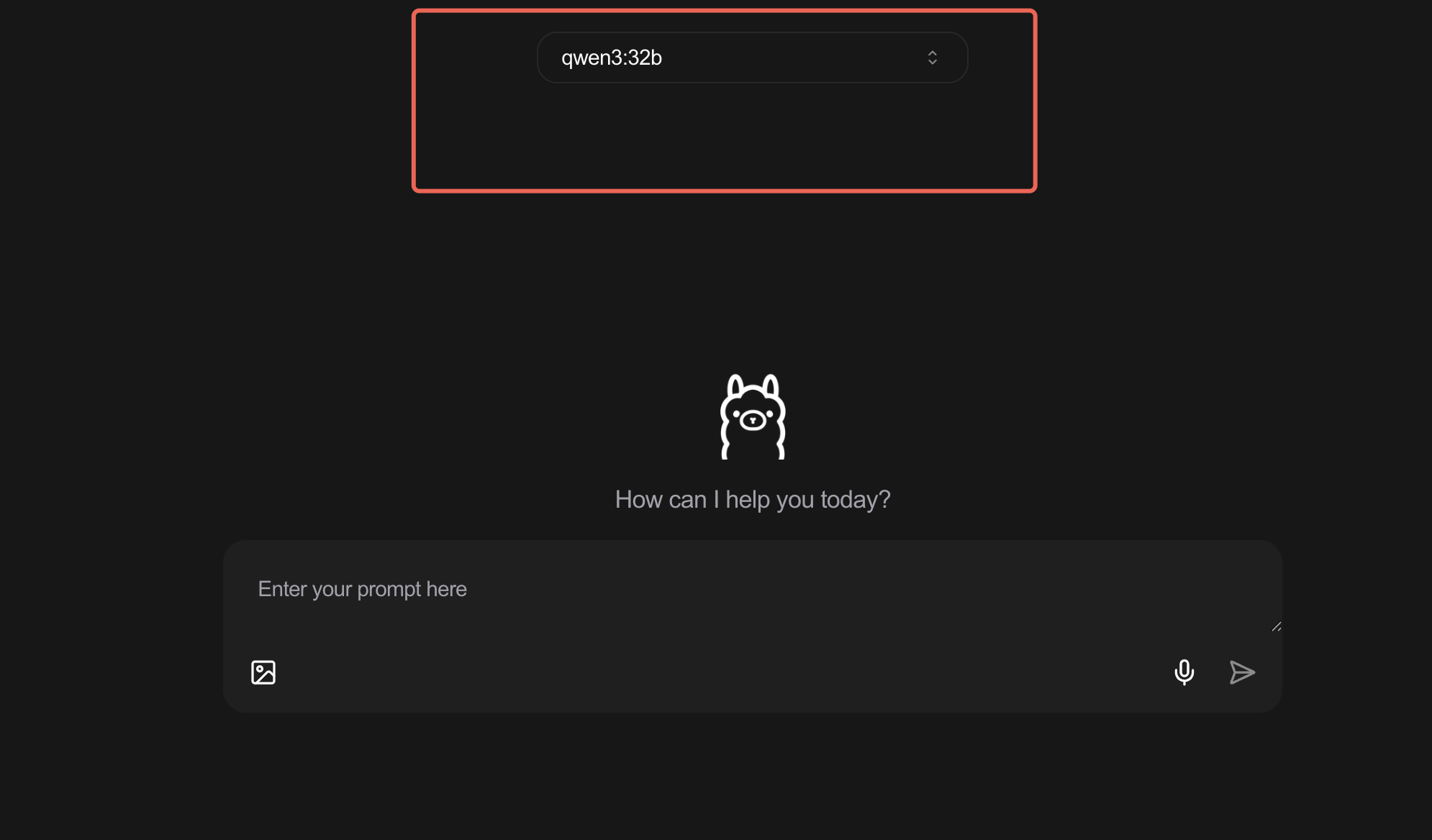
选择之后,系统可能会需要几秒钟到一分钟的时间来加载这个模型(如果它是第一次被使用,可能会从网络拉取模型文件,速度取决于你的网络)。请耐心等待页面提示加载完成。一旦准备就绪,页面下方的交互区域就会变得可用。
2.3 第三步:开始与模型对话
模型加载完成后,一切就绪。页面下方会有一个清晰的输入框,通常旁边会有“发送”、“提问”或类似的按钮。
现在,你就可以像使用任何聊天软件一样,在输入框中键入你的问题了。比如,你可以尝试问:
- “用Python写一个快速排序函数。”
- “解释一下什么是注意力机制,用简单的比喻。”
- “帮我规划一个三天的北京旅游行程。”
输入问题后,按下回车键或点击发送按钮,Qwen3-32B模型就会开始思考并生成回答,结果会实时显示在输入框上方的对话区域。 
至此,你已经成功部署并启动了Qwen3-32B模型。整个过程是不是比预想的要简单得多?你已经在使用一个强大的320亿参数语言模型了。
3. 快速上手:你的第一个实践案例
为了让你立刻感受到Qwen3-32B的能力,我们抛开复杂的测试,直接来一个开发者最关心的实用场景:让它帮你写代码。
假设你现在需要一个Python脚本,用来递归地扫描一个目录下的所有文件,并计算它们的MD5校验和(常用于检查文件完整性)。我们来看看如何与模型协作完成这个任务。
你的提问(Prompt)可以这样写:
请写一个Python脚本,要求如下:
- 递归遍历指定目录下的所有文件和子目录。
- 计算每个文件的MD5哈希值。
- 将结果输出为一个CSV文件,包含三列:文件路径、文件大小(字节)、MD5值。
- 请添加必要的异常处理和注释。
将这段描述发送给Qwen3-32B。几秒钟后,你可能会得到类似下面的高质量代码:
import os
import hashlib
import csv
import argparse
def calculate_md5(file_path):
"""计算单个文件的MD5哈希值"""
hash_md5 = hashlib.md5()
try:
with open(file_path, "rb") as f:
# 分块读取大文件,避免内存占用过高
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
except IOError as e:
print(f"无法读取文件 {file_path}: {e}")
return None
return hash_md5.hexdigest()
def scan_directory_and_calculate_md5(root_dir):
"""递归扫描目录并计算文件MD5"""
results = []
for dirpath, dirnames, filenames in os.walk(root_dir):
for filename in filenames:
full_path = os.path.join(dirpath, filename)
try:
file_size = os.path.getsize(full_path)
md5_hash = calculate_md5(full_path)
if md5_hash: # 只有成功计算MD5时才记录
# 将路径转换为相对路径,更简洁
rel_path = os.path.relpath(full_path, start=root_dir)
results.append([rel_path, file_size, md5_hash])
print(f"已处理: {rel_path}")
except OSError as e:
print(f"处理文件 {full_path} 时出错: {e}")
return results
def save_to_csv(data, output_file):
"""将结果保存到CSV文件"""
try:
with open(output_file, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['文件路径', '文件大小(字节)', 'MD5哈希值'])
writer.writerows(data)
print(f"结果已保存至: {output_file}")
except IOError as e:
print(f"写入CSV文件失败: {e}")
if __name__ == "__main__":
# 使用argparse让脚本可以通过命令行参数指定目录
parser = argparse.ArgumentParser(description='递归计算目录下文件的MD5值')
parser.add_argument('directory', help='要扫描的根目录路径')
parser.add_argument('-o', '--output', default='file_md5_summary.csv',
help='输出CSV文件名 (默认: file_md5_summary.csv)')
args = parser.parse_args()
root_directory = args.directory
output_filename = args.output
if not os.path.isdir(root_directory):
print(f"错误: 路径 '{root_directory}' 不是一个有效的目录。")
exit(1)
print(f"开始扫描目录: {root_directory}")
file_data = scan_directory_and_calculate_md5(root_directory)
if file_data:
save_to_csv(file_data, output_filename)
print(f"共处理了 {len(file_data)} 个文件。")
else:
print("在指定目录下未找到任何文件。")
你看,通过一次清晰的提问,我们得到的不只是一段代码,而是一个功能完整、考虑周全的脚本:
- 功能完整:完全满足了我们提出的四点要求。
- 代码健壮:包含了文件读取异常、路径错误处理。
- 用户友好:使用了
argparse库支持命令行参数,并提供了实时处理进度打印。 - 注释清晰:每个主要函数都有文档字符串说明。
你可以直接复制这段代码,保存为一个.py文件,在命令行中运行python script.py /path/to/your/directory来使用它。这就是Qwen3-32B在代码生成任务上的一个直观展示。你可以尝试修改需求,比如让它只扫描特定后缀的文件,或者将结果输出为JSON格式,看看它如何应对。
4. 发挥模型潜力:实用技巧与进阶探索
成功运行了第一个例子,你可能已经跃跃欲试了。为了让你更好地驾驭这个工具,这里有一些实用技巧和进阶探索方向。
4.1 如何提出更好的问题(Prompt技巧)
模型的输出质量,很大程度上取决于你的输入指令是否清晰。试试下面这些方法:
- 角色扮演:在问题前指定它的角色。“你是一个经验丰富的Python后端开发工程师,请...”
- 结构化指令:像我们刚才那样,使用“1. 2. 3.”或者“要求:”来分点列出你的需求,这能让模型更好地理解复杂任务。
- 提供示例:对于格式有严格要求的任务(比如生成特定结构的JSON或表格),可以先给一个输入输出的例子。“请将以下自然语言描述转换为SQL查询。例如,输入‘找出所有年龄大于25岁的用户’,输出‘SELECT * FROM users WHERE age > 25;’。现在请转换:‘计算上个月每个产品的销售总额’。”
- 分步思考:对于复杂的逻辑或数学问题,可以要求它“一步步思考”。这能激发它的推理能力,并让你看到它的思考过程。
4.2 探索Qwen3-32B的更多能力
除了代码生成,这个镜像中的模型还能做很多事情:
- 技术咨询与学习:向它询问任何技术概念、框架对比(如Spring Boot vs Django)、算法原理等。
- 文档与内容处理:让它总结一篇长技术文章的核心观点,或者将一段混乱的会议纪要整理成结构清晰的待办事项列表。
- 创意与头脑风暴:为你的新项目起名、撰写产品介绍文案、构思博客文章大纲。
- 多语言任务:它支持多种语言,你可以尝试用英文、日文等其他语言与它交流,或者进行翻译工作。
4.3 注意事项与局限性了解
虽然强大,但了解其局限性有助于你更有效地使用它:
- 知识截止日期:像所有大模型一样,它的知识不是实时的。对于2023年7月之后的最新事件、软件版本或新闻,它可能不了解。
- 需要事实核查:它可能会“自信地”生成一些听起来合理但实际错误的信息(即“幻觉”)。对于关键的事实、数据或代码中的重要逻辑,建议进行二次核实。
- 上下文长度:模型能一次性处理和记忆的对话文本长度是有限的。如果对话非常长,它可能会忘记很早之前的内容。
- 非实时计算:它不能执行代码、查询实时数据库或访问互联网(除非镜像集成了相关工具)。它的所有回答都基于训练时学到的模式。
5. 总结
通过这篇指南,我们完成了一次极其顺畅的Qwen3-32B模型体验之旅。回顾一下核心步骤:找到Ollama镜像入口 -> 选择qwen3:32b模型 -> 在输入框提问。整个过程在图形化界面中完成,无需触碰命令行,真正实现了零基础部署。
Qwen3-32B通过Ollama镜像提供的这种开箱即用体验,极大地降低了高性能大模型的使用门槛。无论你是想快速验证一个AI应用的想法,还是需要一个大模型作为编程助手、学习伙伴,这都是一种高效且低成本的方式。
现在,你已经拥有了一个强大的AI工具。接下来最好的学习方式就是不断地使用它。从简单的问答开始,逐渐尝试更复杂的指令和任务,你会发现它能成为你工作和学习中一个非常有价值的“副驾驶”。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 18
18 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)