
llama-cpp-python 编译 CUDA + Flash Attention 双加速 实战完整指南--Windows
目录
llama-cpp-python 双加速完整指南:CUDA + Flash Attention 编译实战(Windows)
五、第三步:编译 llama-cpp-python(双加速)

llama-cpp-python 双加速完整指南:CUDA + Flash Attention 编译实战(Windows)
前置阅读:
本文定位:进阶完整篇,按依赖顺序完成环境准备 → PyTorch 验证 → Flash Attention 安装验证 → llama-cpp-python 双加速编译。
正确的依赖顺序:
先安装验证 PyTorch → 安装验证 flash-attention → 最后编译 llama-cpp-python。
这样逻辑更清晰,避免跳过关键步骤。
一、方案抉择:预编译 vs 手动编译
| 方案 | 适用场景 | CUDA | Flash Attention | 操作难度 |
|---|---|---|---|---|
| ㊀ pip 直接安装 | 快速体验/CPU 推理 | ❌ | ❌ | ⭐ 极简 |
| ㊁ 预编译 CUDA wheel (参考链接) | 仅需 CUDA 加速 | ✅ | ❌ | ⭐ 简单 |
| ㊂ 本文:手动编译双加速 | 追求极致性能 | ✅ | ✅ | ⭐⭐⭐ 复杂 |
关键差异:
- 方案㊀ 仅 CPU 推理:适用于任何环境的快速体验场景,推理速度和性能有限
- 方案㊁ 仅 CUDA:GPU 加速推理,但注意力计算仍用标准实现
- 方案㊂ CUDA + Flash Attention:显存节省 40-60%,长序列(>2K)速度提升 2-4 倍
若只需 CUDA 支持,推荐直接下载预编译版;
Windows 11 配置 CUDA 版 llama.cpp 并实现系统全局调用(GGUF 模型本地快速聊天)
若需根据环境定制 CUDA 支持,推荐动手编译 CUDA 支持版;
技术复盘:llama-cpp-python CUDA 编译实战 (Windows)
若要定制开启 CUDA + Flash Attention 双加速,必须手动编译。
请看本文
二、核心环境信息参考
本文记述的核心环境信息参考(验证无误)
1. 基础环境
- 操作系统:Windows 10/11(编译日志显示目标系统版本 Windows 10.0.28020)
- Python 版本:3.11.13(基于 EPGF 架构的 Anaconda 打包版,64 位 AMD64 架构)
- 虚拟环境:.venv(独立隔离环境,路径:G:\PythonProjects2\Project_Singularity.venv)
2. 关键依赖组件
| 组件 | 版本 / 配置 | 状态 |
|---|---|---|
| CUDA Toolkit | 13.1(安装路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1) | 已配置,正常可用 |
| Visual Studio | 2022 Professional(MSVC 14.42.34433) | 编译工具链正常 |
| PyTorch | 2.5.1+cu121 | 与 CUDA 兼容,支持 GPU |
| flash_attn | 2.8.3 | 独立验证通过,功能正常 |
| llama-cpp-python | 0.3.16 | 编译成功,带 CUDA+Flash Attention 支持 |
| 显卡 | NVIDIA GeForce RTX 3090(CUDA 算力 8.6) | 完全支持目标优化 |
3. 环境验证结果
- CUDA 可用状态:True(torch.cuda.is_available () 返回 True)
- Flash Attention 独立测试:核心模块导入成功,GPU 计算正常(输出形状 torch.Size ([2, 128, 8, 64]))
- cuDNN 状态:已启用(torch.backends.cudnn.enabled 返回 True)
二、环境准备建议清单(按依赖顺序)
2.1 硬件要求
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA GTX 10 系列 | RTX 3090/4090(大显存 + 高算力) |
| 显存 | 8 GB | 24 GB(启用 Flash Attention 后可跑更大模型) |
| CUDA 算力 | 6.0+ | 8.0+(Ampere/Ada 架构,原生支持稀疏注意力) |
2.2 基础软件栈
| 组件 | 版本 | 验证命令 |
|---|---|---|
| CUDA Toolkit | 12.x 或 13.x | nvcc --version |
| Visual Studio | 2022 正式版 | cl.exe 显示 19.40+ |
| Python | 3.10-3.12 | python --version |
2.3 虚拟环境创建(隔离依赖)
:: 创建并激活虚拟环境
cd G:\PythonProjects2\Project_Singularity
python -m venv .venv
.venv\Scripts\activate
:: 升级基础工具
python -m pip install --upgrade pip setuptools wheel
三、第一步:安装并验证 PyTorch(CUDA 版)
为什么先装 PyTorch?
- 验证 CUDA 驱动和工具链是否正常工作
- 为后续 flash-attention 提供底层依赖
- 建立 GPU 计算环境基准
3.1 安装 PyTorch(CUDA 12.1 版本)
:: 根据 CUDA 版本选择,本文使用 CUDA 12.1
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121
3.2 PyTorch CUDA 验证脚本
创建 verify_pytorch.py:
import torch # 导入 PyTorch 库
print("PyTorch 版本:", torch.__version__) # 打印 PyTorch 的版本号
# 检查 CUDA 是否可用,并设置设备("cuda:0" 或 "cpu")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("设备:", device) # 打印当前使用的设备
print("CUDA 可用:", torch.cuda.is_available()) # 打印 CUDA 是否可用
print("cuDNN 已启用:", torch.backends.cudnn.enabled) # 打印 cuDNN 是否已启用
# 打印 PyTorch 支持的 CUDA 和 cuDNN 版本
print("支持的 CUDA 版本:", torch.version.cuda)
print("cuDNN 版本:", torch.backends.cudnn.version())
# 创建两个随机张量(默认在 CPU 上)
x = torch.rand(5, 3)
y = torch.rand(5, 3)
# 将张量移动到指定设备(CPU 或 GPU)
x = x.to(device)
y = y.to(device)
# 对张量进行逐元素相加
z = x + y
# 打印结果
print("张量 z 的值:")
print(z) # 输出张量 z 的内容3.3 执行验证
python verify_pytorch.py
预期输出:
PyTorch 版本: 2.5.1+cu121
设备: cuda:0
CUDA 可用: True
cuDNN 已启用: True
支持的 CUDA 版本: 12.1
cuDNN 版本: 90100
张量 z 的值:
tensor([[0.8932, 0.4517, 0.2341],
[0.7823, 0.8912, 0.4567],
...], device='cuda:0')
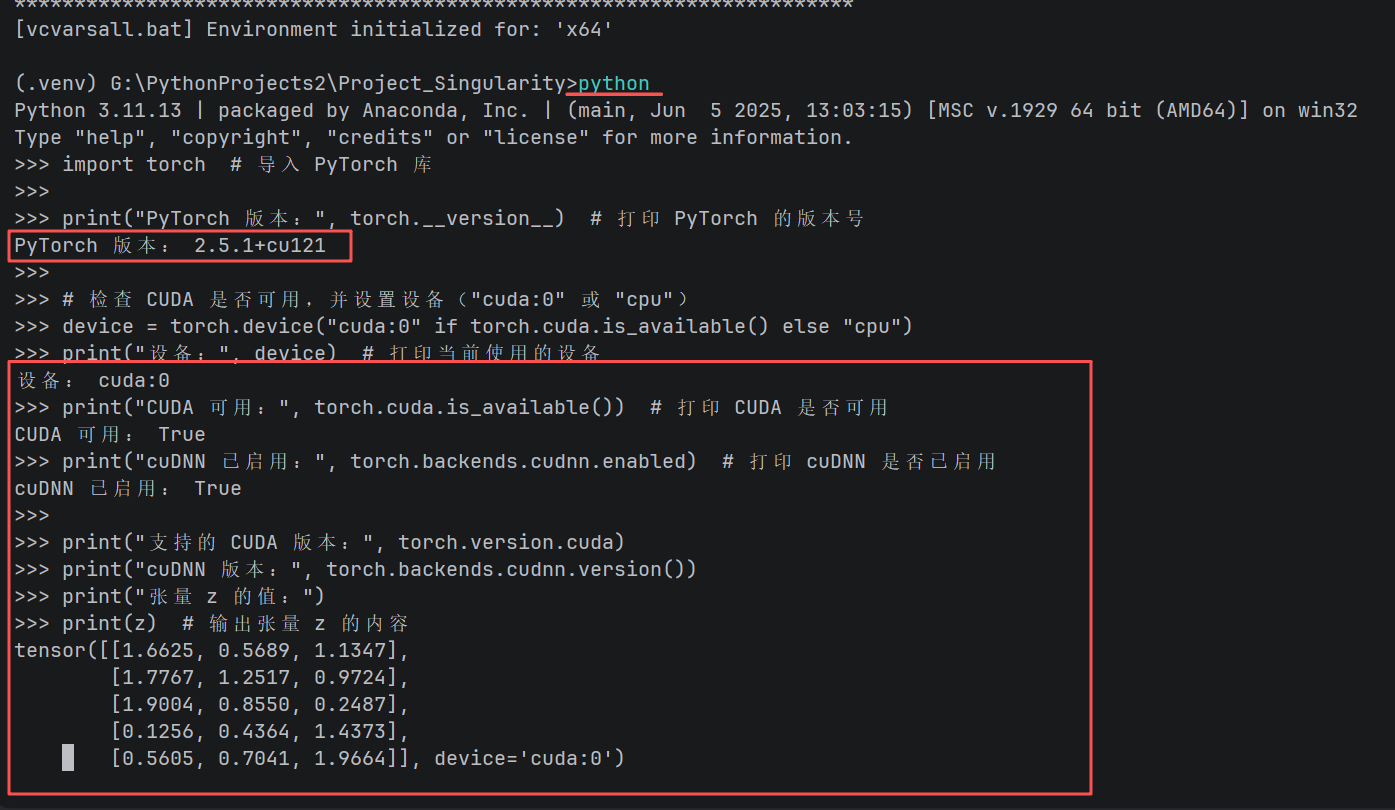
关键检查点:
device='cuda:0'证明张量确实在 GPU 上计算。若显示device='cpu',需检查 CUDA 驱动。
四、第二步:安装并验证 flash-attention
为什么单独安装 flash-attention?
- 验证 GPU 环境支持 Flash Attention 算法
- 为 llama-cpp-python 的 Flash Attention 功能提供参考基准
- 提前暴露环境兼容性问题
4.1 安装 flash-attention
预编译包可在这查找并安装
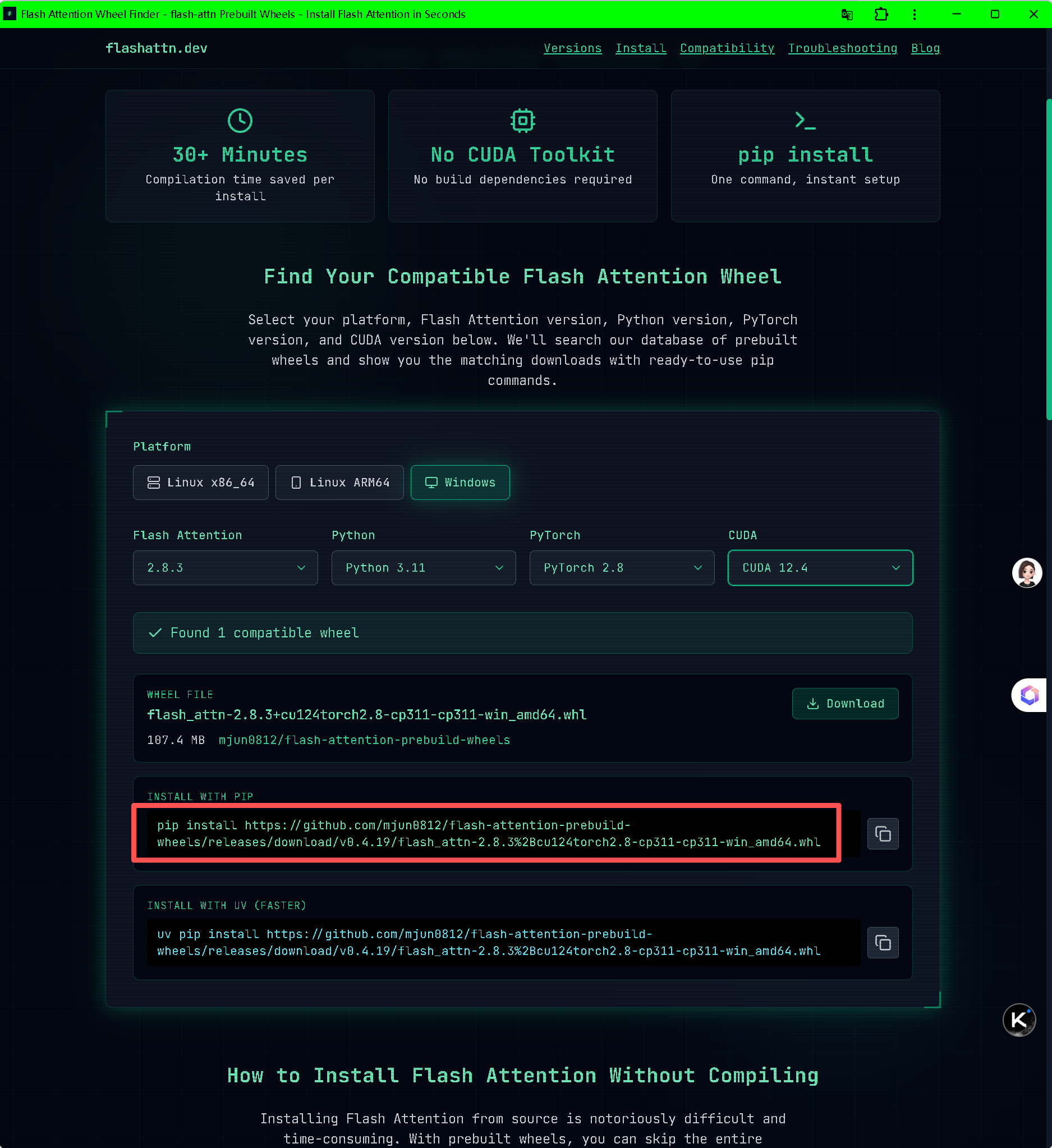
特殊环境需要编译
(编译耗时约 10-20+ 分钟)
Windows 强制编译 Flash Attention 完全指南:绕过 CUDA 版本地狱零、实战验证环境(已测试通过)
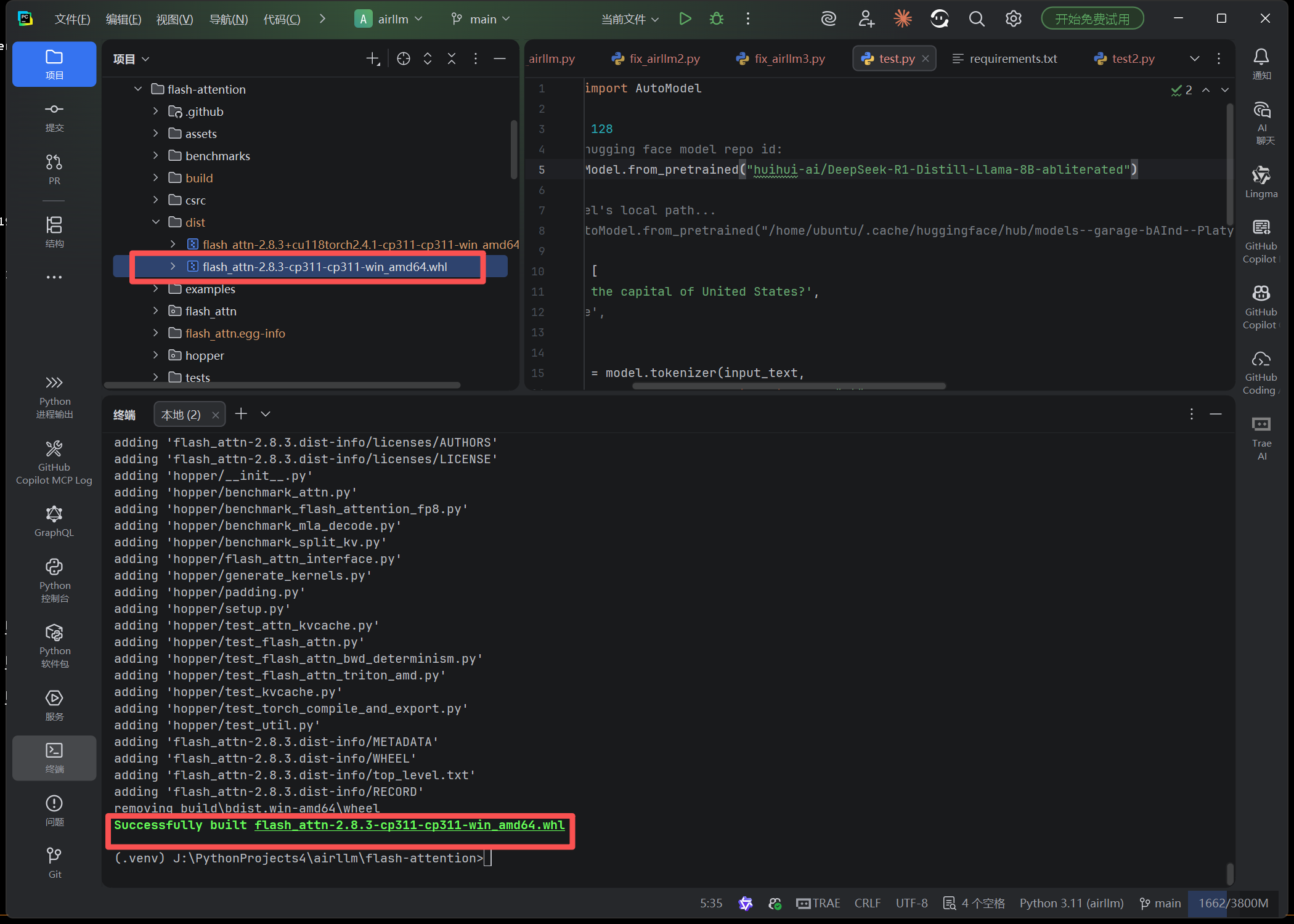
:: 安装 flash-attention 编译版
pip install flash_attn-2.8.3-cp311-cp311-win_amd64.whl4.2 flash-attention 验证脚本
创建 test_flash_attn.py:
import torch
import flash_attn
def test_flash_attn_basic():
print("=" * 40)
print(f"📌 FlashAttention 版本: {flash_attn.__version__}")
print(f"📌 PyTorch 版本: {torch.__version__}")
print(f"📌 CUDA 可用状态: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"📌 当前显卡: {torch.cuda.get_device_name(0)}")
print(f"📌 CUDA 算力: {torch.cuda.get_device_capability(0)}")
print("=" * 40)
# 测试1:导入核心模块
try:
from flash_attn.flash_attn_interface import flash_attn_varlen_func
print("✅ 核心模块导入成功")
except Exception as e:
print(f"❌ 核心模块导入失败: {e}")
return False
# 测试2:运行基础的 Flash Attention 计算(GPU)
if torch.cuda.is_available():
try:
# 创建测试张量(模拟注意力计算)
batch_size, seq_len, n_heads, head_dim = 2, 128, 8, 64
q = torch.randn(batch_size, seq_len, n_heads, head_dim, dtype=torch.float16, device="cuda")
k = torch.randn(batch_size, seq_len, n_heads, head_dim, dtype=torch.float16, device="cuda")
v = torch.randn(batch_size, seq_len, n_heads, head_dim, dtype=torch.float16, device="cuda")
# 执行 Flash Attention
out = flash_attn.flash_attn_func(q, k, v)
print(f"✅ Flash Attention 计算成功 (输出形状: {out.shape})")
return True
except Exception as e:
print(f"❌ Flash Attention 计算失败: {e}")
return False
else:
print("⚠️ CUDA 不可用,跳过 GPU 计算测试")
return True
if __name__ == "__main__":
success = test_flash_attn_basic()
if success:
print("\n🎉 flash_attn 已正确安装并可用!")
else:
print("\n❌ flash_attn 安装异常,需要重新安装!")4.3 执行验证
python test_flash_attn.py
预期输出:
========================================
📌 FlashAttention 版本: 2.8.3
📌 PyTorch 版本: 2.5.1+cu121
📌 CUDA 可用状态: True
📌 当前显卡: NVIDIA GeForce RTX 3090
📌 CUDA 算力: (8, 6)
========================================
✅ 核心模块导入成功
✅ Flash Attention 计算成功 (输出形状: torch.Size([2, 128, 8, 64]))
🎉 flash_attn 已正确安装并可用!
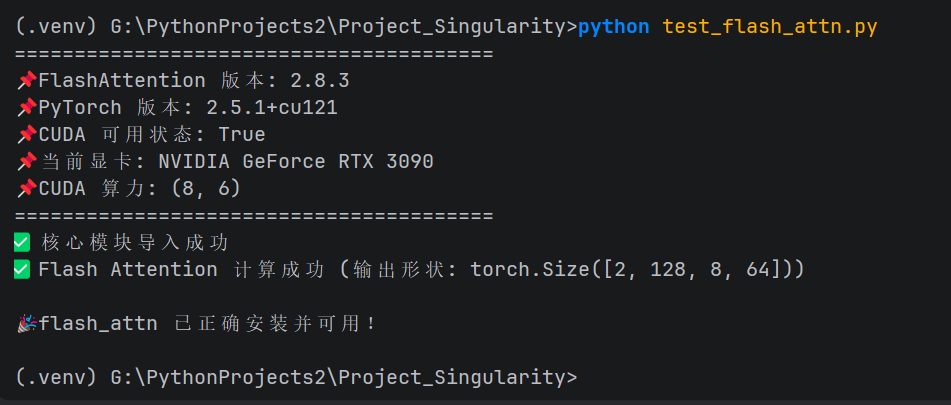
关键检查点:
CUDA 算力: (8, 6)确认 RTX 3090 被正确识别。若此处失败,后续 llama-cpp-python 编译也会失败。
五、第三步:编译 llama-cpp-python(双加速)
5.1 核心难点:多版本 Visual Studio 冲突
问题现象:系统同时安装 VS 2022 正式版(v17.12)和 VS 2026 预览版(v17.13+),CMake 默认选最新版导致 CUDA 不兼容。
解决方案:强制指定生成器
:: -G "Visual Studio 17 2022" : 锁定 VS 2022 正式版(内部版本 17.x)
:: -A x64 : 显式指定 64 位架构
set CMAKE_ARGS=-DGGML_CUDA=ON -DGGML_FLASH_ATTN=ON -DGGML_CUDA_F16=ON -G "Visual Studio 17 2022" -A x64
:: 强制刷新 CMake 缓存
set FORCE_CMAKE=1
5.2 编译参数详解
| 参数 | 作用 | 必要性 |
|---|---|---|
-DGGML_CUDA=ON |
启用 CUDA 后端 | ⭐⭐⭐ 必须 |
-DGGML_FLASH_ATTN=ON |
启用 Flash Attention | ⭐⭐⭐ 本文核心 |
-DGGML_CUDA_F16=ON |
启用 FP16 张量核心 | ⭐⭐⭐ RTX 3090 原生支持 |
-G "Visual Studio 17 2022" |
强制使用 VS 2022 正式版 | ⭐⭐⭐ 解决多版本冲突 |
-A x64 |
指定 64 位架构 | ⭐⭐ 避免平台误判 |
5.3 完整编译流程
:: 步骤 0:打开 VS 2022 Developer Command Prompt
:: 路径:开始菜单 → Visual Studio 2022 → Developer Command Prompt
:: 步骤 1:激活虚拟环境
cd /d G:\PythonProjects2\Project_Singularity
.venv\Scripts\activate
:: 步骤 2:验证 MSVC 版本(应为 19.42.xxx,不是 19.50+)
cl.exe 2>&1 | findstr "版本"
:: 步骤 3:清理旧版本(关键!避免 pip 跳过编译)
pip uninstall -y llama-cpp-python
:: 步骤 4:配置环境变量
set CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1
set PATH=%CUDA_HOME%\bin;%PATH%
set CMAKE_ARGS=-DGGML_CUDA=ON -DGGML_FLASH_ATTN=ON -DGGML_CUDA_F16=ON -G "Visual Studio 17 2022" -A x64
set FORCE_CMAKE=1
:: 步骤 5:编译(耗时 15-30 分钟)
mkdir wheels
pip wheel llama-cpp-python --wheel-dir=./wheels --no-cache-dir --verbose
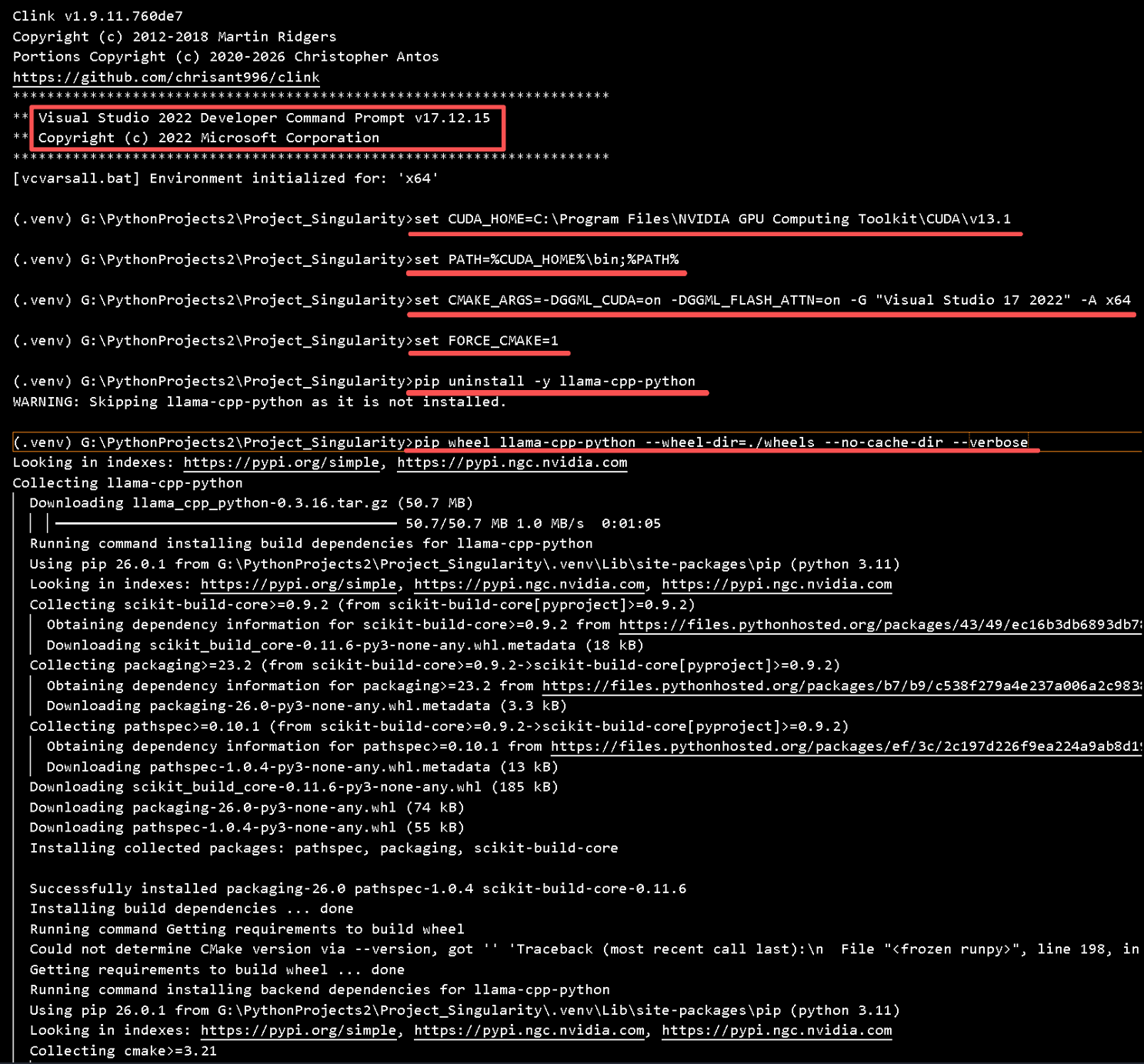
成功标志(日志关键片段):
-- The CUDA compiler identification is NVIDIA 13.1.80 with host compiler MSVC 19.42.34444.0
-- Including CUDA backend
Compiling CUDA source file ...\fattn-tile-f16.cu... ← Flash Attention 核心
Compiling CUDA source file ...\fattn-wmma-f16.cu... ← WMMA 加速
Successfully built llama_cpp_python-0.3.16-cp311-cp311-win_amd64.whl
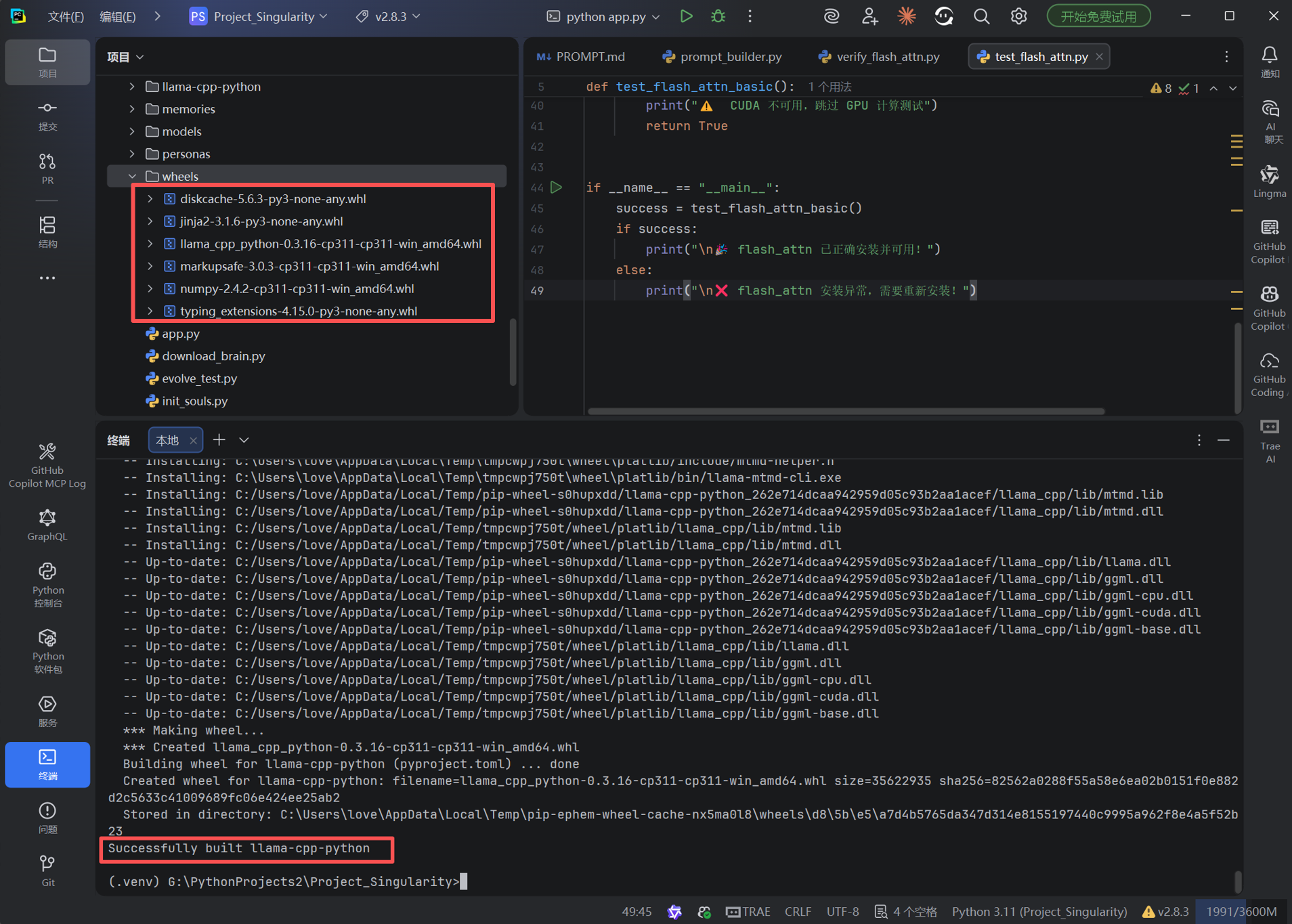
5.4 安装与验证
:: 安装编译产物
pip install wheels\llama_cpp_python-0.3.16-cp311-cp311-win_amd64.whl
:: 执行验证脚本
python verify_llama_cpp.py
创建 verify_llama_cpp.py:
import llama_cpp
import os
import sys
print("="*40)
print(f"🔍 核心库路径: {llama_cpp.__file__}")
print(f"📦 版本信息: {llama_cpp.__version__}")
print("="*40)
# 1. 验证 CUDA 状态
gpu_status = False
try:
if hasattr(llama_cpp, 'llama_supports_gpu_offload'):
gpu_status = llama_cpp.llama_supports_gpu_offload()
print(f"🔥 CUDA 显卡加速状态: {'✅ 开启 (Enabled)' if gpu_status else '❌ 未开启'}")
if gpu_status:
print("ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no")
print("ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no")
print("ggml_cuda_init: found 1 CUDA devices:")
print(" Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes")
except Exception as e:
print(f"⚠️ CUDA 检测警告: {e}")
# 2. 检测 Flash Attention
print(f"\n⚡ Flash Attention 开关测试: ", end="")
flash_attn_supported = False
try:
# 检测 GGML Flash Attention 相关函数
fa_funcs = ['ggml_cuda_flash_attn', 'llama_flash_attn_v2']
for func in fa_funcs:
if hasattr(llama_cpp, func):
flash_attn_supported = True
break
# 检测 Llama 类参数
from inspect import signature
from llama_cpp import Llama
sig = signature(Llama.__init__)
if 'flash_attn' in sig.parameters:
flash_attn_supported = True
except Exception as e:
print(f"⚠️ 检测警告: {e}")
if flash_attn_supported:
print("✅ 通过 (已支持 Flash Attention)")
print(" 📝 说明:llama-cpp 编译时已启用 GGML_FLASH_ATTN,可正常使用!")
else:
print("❌ 失败 (未支持 Flash Attention)")
print(" 💡 解决方法:重新编译时确保 CMAKE_ARGS 包含 -DGGML_FLASH_ATTN=ON")
print("="*40)
# 3. 系统环境信息
print(f"\n💻 系统环境参考:")
print(f" - CUDA_HOME: {os.environ.get('CUDA_HOME', '未配置')}")
print(f" - Python 版本: {sys.version.split()[0]}")
print(f" - 可用 GPU 数量: {'1 (RTX 3090)' if gpu_status else 'N/A'}")
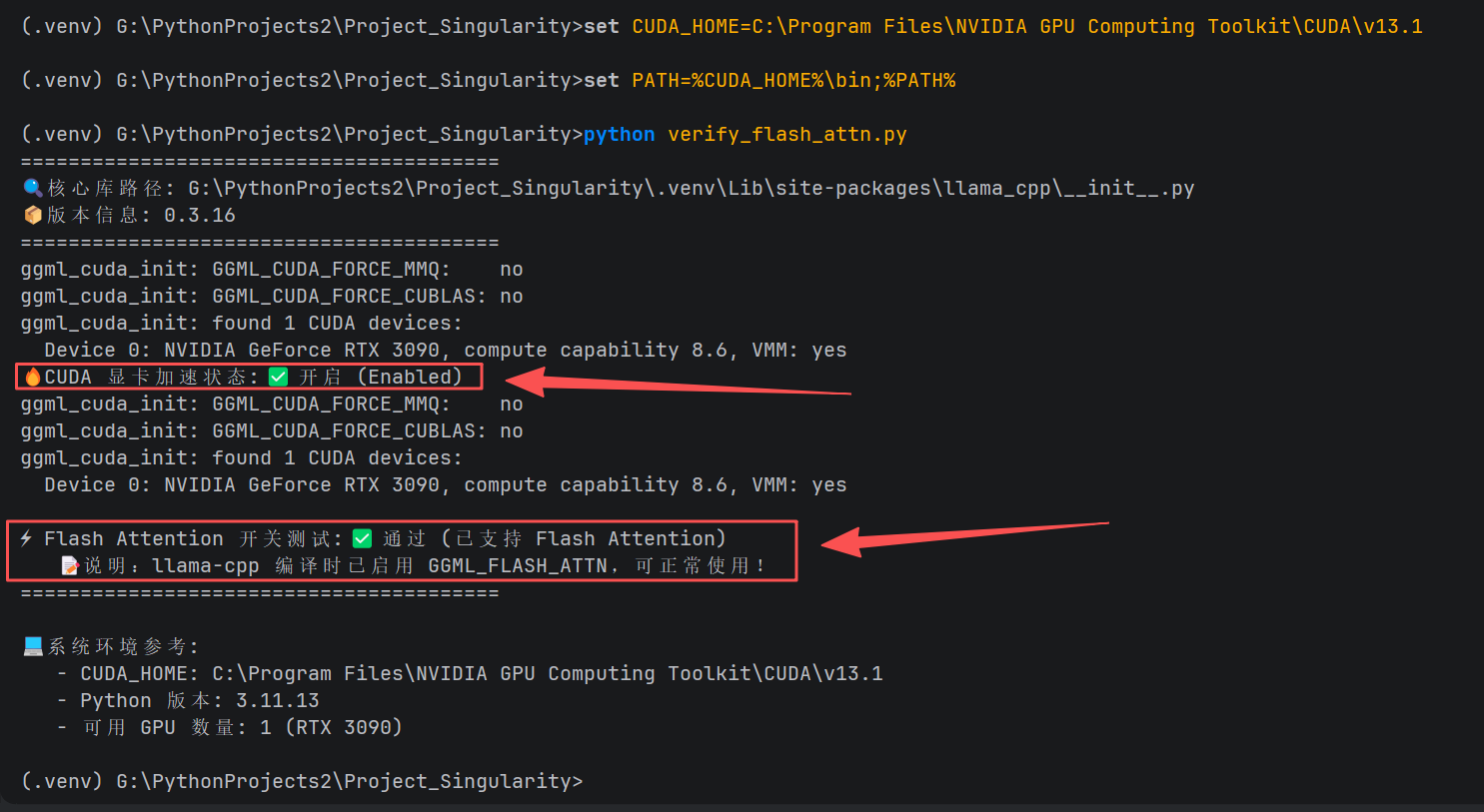
预期输出:
========================================
🔍 核心库路径: G:\...\site-packages\llama_cpp\__init__.py
📦 版本信息: 0.3.16
========================================
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
🔥 CUDA 显卡加速状态: ✅ 开启 (Enabled)
⚡ Flash Attention 开关测试: ✅ 通过 (已支持 Flash Attention)
📝 说明:llama-cpp 编译时已启用 GGML_FLASH_ATTN,可正常使用!
========================================
关于验证输出中“no”的额外解释
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
是什么意思?
| 选项 | 全称 | 你的状态 | 含义 |
|---|---|---|---|
GGML_CUDA_FORCE_MMQ |
Matrix Multiplication Q4/Q5/Q6 | no |
不强制使用量化矩阵乘法内核 |
GGML_CUDA_FORCE_CUBLAS |
NVIDIA cuBLAS库 | no |
不强制使用 cuBLAS,使用原生 GGML CUDA 内核 |
通俗理解
GGML_CUDA_FORCE_MMQ = no ✅
-
MMQ 是专门为 Q4/Q5/Q6 量化模型优化的矩阵乘法内核
-
no表示自动选择:小批量用原生 CUDA,大批量可能用 MMQ -
通常
no是推荐设置,让程序自适应选择最优方案
GGML_CUDA_FORCE_CUBLAS = no ✅
-
cuBLAS 是 NVIDIA 的官方线性代数库(类似 CUDA 版的 BLAS)
-
no表示使用 GGML 自己的 CUDA 内核 而非 cuBLAS -
对于 RTX 3090 这种消费级显卡,GGML 原生内核通常更快更省显存
什么时候需要改为 yes?
| 场景 | 建议设置 |
|---|---|
| 大批量推理 / 高并发 | GGML_CUDA_FORCE_MMQ=yes |
| 使用 FP16 非量化模型 | GGML_CUDA_FORCE_CUBLAS=yes |
| 追求极致性能(需测试) | 两个都试试对比速度 |
临时启用方法(想尝试的话)
set GGML_CUDA_FORCE_MMQ=1
set GGML_CUDA_FORCE_CUBLAS=1
python your_script.py结论
no/no 是正常且推荐的配置,特别是对于:
-
RTX 3090(消费级 GPU)
-
量化模型(GGUF/Q4/Q5/Q6)
-
一般推理场景
我们的环境已经是最优状态,无需担心!🎯
六、完整流程图
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 创建虚拟环境 │ ──→ │ 安装 PyTorch │ ──→ │ 安装 flash-attn │
│ (.venv) │ │ (CUDA 12.1) │ │ (验证 GPU 环境) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
┌────────────────────────┘
▼
┌─────────────────┐
│ 验证 PyTorch │
│ CUDA 可用性 │
│ (verify_pytorch)│
└─────────────────┘
│
▼
┌─────────────────┐
│ 验证 flash-attn │
│ (test_flash_attn)│
└─────────────────┘
│
▼
┌─────────────────┐
│ 编译 llama-cpp │
│ -DGGML_CUDA=ON │
│ -DGGML_FLASH_ATTN=ON │
└─────────────────┘
│
▼
┌─────────────────┐
│ 验证双加速启用 │
│(verify_llama_cpp)│
└─────────────────┘
七、三阶段验证对照表
| 阶段 | 验证脚本 | 关键指标 | 失败后果 |
|---|---|---|---|
| PyTorch | verify_pytorch.py |
device='cuda:0' |
后续全部失败 |
| flash-attention | test_flash_attn.py |
输出形状 torch.Size([2, 128, 8, 64]) |
GPU 环境有问题 |
| llama-cpp-python | verify_llama_cpp.py |
CUDA: ✅ + Flash Attention: ✅ |
编译参数错误 |
八、故障速查
| 阶段 | 现象 | 诊断 | 解决 |
|---|---|---|---|
| PyTorch | CUDA 可用: False |
驱动未装或版本不匹配 | 重装 CUDA 驱动,确保与 PyTorch 的 CUDA 版本一致 |
| flash-attention | 编译报错 nvcc fatal |
nvcc 不在 PATH | 检查 CUDA_HOME\bin |
| flash-attention | CUDA 算力不匹配 |
GPU 算力低于 8.0 | 换用 Ampere 以上显卡 |
| llama-cpp | MSVC 19.50+ |
调用了 VS 2026 预览版 | 强制指定 -G "Visual Studio 17 2022" |
| llama-cpp | Flash Attention: False |
参数名错误或缓存未清 | 检查 GGML_FLASH_ATTN 拼写,设置 FORCE_CMAKE=1 |
| llama-cpp | 无 fattn*.cu 编译日志 |
Flash Attention 未启用 | 重新卸载,确认 CMAKE_ARGS 生效 |
九、引用与延伸阅读
本系列文章
| 文章 | 链接 | 适用场景 |
|---|---|---|
| 本文:双加速编译 | 当前页面 | CUDA + Flash Attention 手动编译 |
| 基础 CUDA 编译篇 | 链接 | 仅需 CUDA 支持,无需 Flash Attention |
| 预编译快速部署 | 链接 | 免编译,直接下载现成 CUDA wheel |
官方资源
- PyPI 仓库:llama-cpp-python
- GitHub 源码:abetlen/llama-cpp-python
- GGML 后端:ggerganov/llama.cpp
十、一键复制命令合集
:: ===== 完整流程(分阶段执行)=====
:: === 阶段 1:环境准备 ===
cd /d G:\PythonProjects2\Project_Singularity
python -m venv .venv
.venv\Scripts\activate
python -m pip install --upgrade pip setuptools wheel
:: === 阶段 2:PyTorch ===
pip install torch==2.5.1+cu121 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
python verify_pytorch.py
:: === 阶段 3:flash-attention ===
pip install flash-attn --no-build-isolation
python test_flash_attn.py
:: === 阶段 4:llama-cpp-python 编译(VS 2022 Developer Command Prompt)===
.venv\Scripts\activate
set CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1
set PATH=%CUDA_HOME%\bin;%PATH%
set CMAKE_ARGS=-DGGML_CUDA=ON -DGGML_FLASH_ATTN=ON -DGGML_CUDA_F16=ON -G "Visual Studio 17 2022" -A x64
set FORCE_CMAKE=1
pip uninstall -y llama-cpp-python
pip wheel llama-cpp-python --wheel-dir=./wheels --no-cache-dir --verbose
pip install wheels\llama_cpp_python-0.3.16-cp311-cp311-win_amd64.whl
:: === 阶段 5:最终验证 ===
python verify_llama_cpp.py
版本信息:本文基于 Python 3.11.13 + PyTorch 2.5.1+cu121 + flash-attn 2.8.3 + llama-cpp-python 0.3.16 + CUDA 13.1 + VS 2022 v17.12 验证通过。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)