
学习笔记:主流大模型框架对比分析(Ollama、vLLM、SGlang、TensorRT-LLM等)
学习笔记:主流大模型框架对比分析(Ollama、vLLM、SGlang、TensorRT-LLM等)
随着DeepSeek大模型应用在各行业细分场景的落地,大家在选择合适的硬件配置和目标场景时通常也会用到大模型推理框架的选择(我自己电脑上用ollama部署了R1的蒸馏版),很多DeepSeek大模型一体机在部署时会选择不同的框架,比如常见的有vLLM、SGlang、TensorRT-LLM等,今天和朋友交流时聊到大模型框架的作用是什么?主流的框架有哪些?以及各自的优劣势如何,我也是现学现卖,跟大家分享一下!
一、大模型框架的定义
大模型推理框架是用于优化和加速大模型推理过程的工具或平台,通过模型压缩、并行计算、内存优化等技术,解决大模型高计算量、高内存消耗等问题。其核心目标是提升推理速度、降低硬件成本,并满足实时性需求,是大模型+应用落地的重要一环,推理框架选择可能的考虑因素如下:
1、性能指标(高吞吐和低延时):对于在线客服、金融交易和智能文档处理等对延迟与吞吐量要求极高的场景,推荐选择 vLLM、TensorRT-LLM 或 Hugging Face TGI,它们在多 GPU 部署和低延迟响应方面表现尤为突出。
2、部署环境(个人和单台部署):Ollama支持零配置安装,适配主流的PC系统如Mac/Windows/Linux等,适合个人开发者快速验证模型(如运行Llama 7B),Llama.cpp 则满足了无 GPU 环境下的基本推理需求。
3、需要国产硬件部署情况下:LMDeploy 针对国产 GPU 进行了深度优化,具备多模态处理优势,适合国内企业和政府机构在特定硬件环境下部署
4、对应新兴技术探索的需求:SGLang 与 MLC-LLM 分别在高吞吐量和编译优化上展示了前沿技术潜力,虽然当前还存在一定局限,但未来发展前景值得期待。
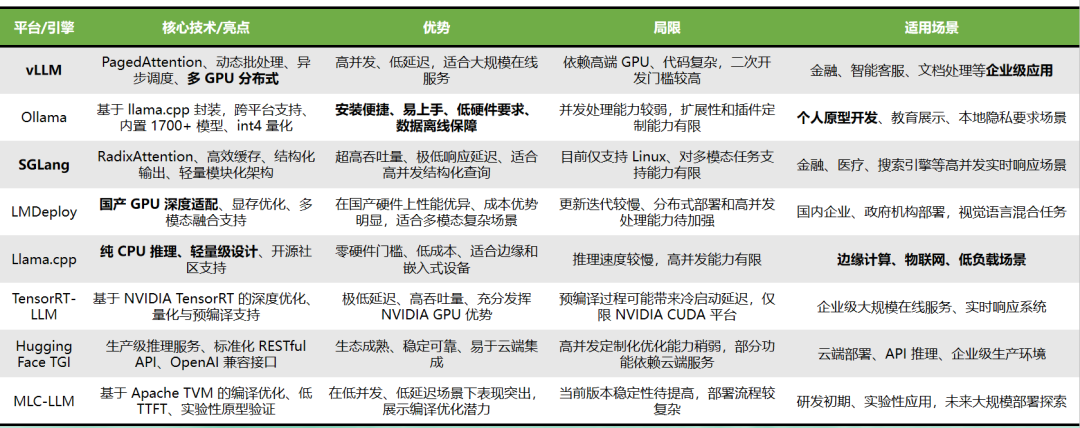
**二、**常见推理框架介绍:
1、vLLM全称是Virtual Large Language Model,是加州大学伯克利分校(伯克利大学LMSYS组织)开源的一个大语言模型高速推理框架,专注于通过显存优化与计算加速技术提升模型推理效率,适用于企业级高并发场景和边缘设备部署。
核心技术: PagedAttention,动态批处理,多GPU分布式。
优势: 高并发、低延迟,适合大规模在线服务。
局限: 依赖高端GPU,代码复杂,二次开发门槛较高。
适用场景: 金融、智能客服、文档处理等企业级应用。
2、Ollama,是 Jeffrey Morgan 开发的一款开源工具,是一个遵循MIT开源协议的独立开源项目,它改变了在本地终端上运行大语言模型的方式。 Ollama 具有友好的用户界面,并与 LLaMA 2 和 Mistral 等流行模型兼容,,支持在Windows、Linux和macOS等主流操作系统本地部署运行。
核心技术: 基于llama.cpp封装,跨平台支持,内置1700+模型,int4量化。
优势: 安装便捷,低硬件要求,数据离线保障。
局限: 并发处理能力较弱,扩展性有限。
适用场景: 个人原型开发、教育展示、本地隐私要求场景。
**3、**SGLang 是伯克利团队开发的另一款大模型推理引擎,专注于 LLM Programs 的优化。它通过 RadixAttention 技术实现高效的 KV Cache 重用,并支持结构化输出和复杂控制流。SGLang 的设计目标是简化 LLM 的编程接口,使其更适合多轮对话、推理任务和多模态输入等复杂场景。
核心技术: RadixAttention,高效缓存,结构化输出,轻量模块化架构。
优势: 超高吞吐量,极低响应延迟,适合高并发结构化查询。
局限: 目前仅支持Linux,对多模态任务支持能力有限。
适用场景: 金融、医疗、搜索引擎等高并发实时响应场景。
4、LMDeploy 是一个高效且友好的大型语言模型(LLMs)和视觉-语言模型(VLMs)部署工具箱,由上海人工智能实验室模型压缩和部署团队开发,涵盖了模型量化、离线推理和在线服务等功能。
核心技术: 国产GPU深度适配,显存优化,多模态融合支持。
优势: 在国产硬件上性能优异,成本优势。
局限: 更新迭代较慢,分布式部署和高并发处理能力待加强。
适用场景: 国内企业、政府机构部署,视觉语言混合任务。
5、Llama.cpp是一个高性能的CPU/GPU大语言模型推理框架,适用于消费级设备或边缘设备。开发者可以通过工具将各类开源大语言模型转换并量化成gguf格式的文件,然后通过llama.cpp实现本地推理。
核心技术: 纯CPU推理,轻量级设计,开源社区支持。
优势: 零硬件门槛,低成本,适合边缘和嵌入式设备。
局限: 推理速度较慢,高并发能力有限。
适用场景: 边缘计算、物联网、低负载场景。
6、TensorRT-LLM是NVIDIA 推出的大语言模型(LLMs)推理加速框架,为用户提供了一个易于使用的 Python API,并使用最新的优化技术将大型语言模型构建为 TensorRT 引擎文件,以便在 NVIDIA GPU 上高效地进行推理。
核心技术: 基于NVIDIA TensorRT的深度优化,量化与预编译支持。
优势: 极低延迟,高吞吐量,充分发挥NVIDIA GPU优势。
局限: 预编译过程可能带来冷启动延迟,仅限NVIDIA CUDA平台。
适用场景: 企业级大规模在线服务,实时响应系统。
7、Hugging Face TGI是 Hugging Face 开发的生产级推理容器,可用于轻松部署大语言模型。它支持流式组批、流式输出、基于张量并行的多 GPU 快速推理,并支持生产级的日志记录和跟踪等功能。
核心技术: 生产级推理服务,标准化RESTful API,OpenAI兼容接口。
优势: 生态成熟,稳定可靠,易于云端集成。
局限: 高并发定制化优化能力稍弱。
适用场景: 云端部署,API推理,企业级生产环境。
**8、**MLC LLM(Multi-Language Customizable Local LLM)是一种本地大语言模型。它允许将任何语言模型本地部署在各种硬件后端和本地应用程序上,并提供了高效的框架,可以根据不同用例进一步优化模型性能。旨在解决本地环境中的部署问题,尤其是那些没有python或其他必要依赖项的环境。
核心技术: 基于Apache TVM的编译优化,低TTFT,实验性原型验证。
优势: 在低并发、低延迟场景下表现突出。
局限: 当前版本稳定性待提高,部署流程复杂。
适用场景: 研发初期,实验性应用,未来大规模部署探索。
三、一张图总结8个主流推理框架优劣势和场景:

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)