
跟着 Nanogpt 实践 Transformer
核心机制
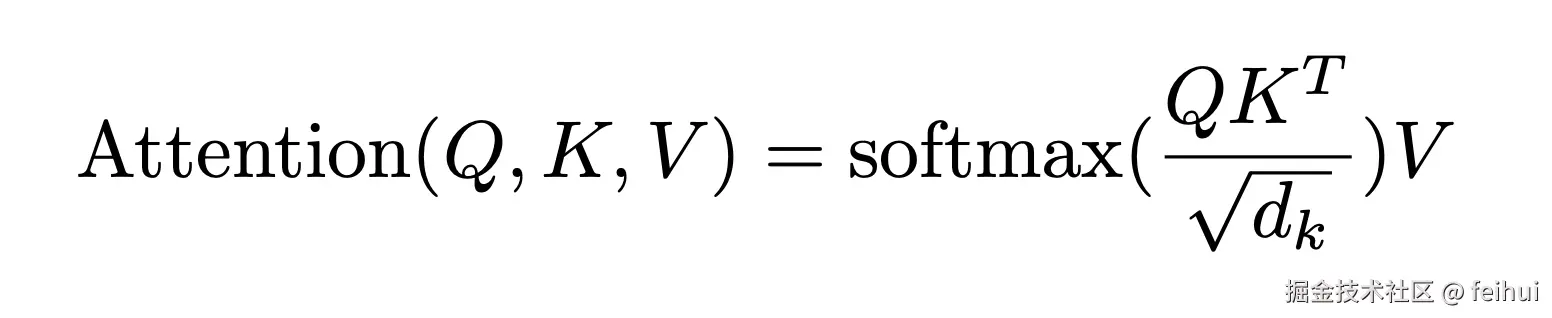

每个 token 定义三个语义 embedding:query / key / value,对输入序列每个 token query embedding 和(输入序列中)每个 token key embedding 计算点积 ( 计算相似度 ),经 softmax 转换成概率后与 ( 输入序列中 ) 每个 token value embedding 向量相乘得到代表当前 token 的新向量。如此,不包含上下文的 static embedding 就成为包含上下文的 dynamic embedding,实现并行计算和解决长距离依赖问题。
But 为什么是 query / key / value,说下我浅薄的理解:在不同的序列 ( 上下文 ) 中同一 token 或有不同的语义,如此就需要通过某种方式引入上下文信息,一个自然想法:引入其余 token 信息,如将序列中所有 token embedding ( 加权 ) 求和代表当前 token 在当前序列中包含上下文的 embedding?这不正是对应 query 和 key 的点积 ( 代表的相似性 ) ?那干嘛不直接学习点积结果?在单独的 ecoder 和 decoder 或许效果不错,但是在 ecoder 和 decoder 配置使用的情况下 ( 如翻译 ) ,进一步拆解点积结果成 query 和 key 是一个更好的设计:qeury 来自目标语言序列、query 和 value 来自原文语言序列。
此外,如何处理序列位置问题,毕竟同样的 token 序列但位置不同也会有不同的语义。一个直觉的想法便是引入 position embedding 与 token embedding 拼接,如此这个新的 embedding 就引入了位置信息,这种拼接方式可以达到目的,但也带来了明显的纬度膨胀和计算爆炸。另一种方式则是将 position embedding 和 token embedding 相加来引入位置信息,这种方式可以类比波段的叠加,不同的波段叠加在一起可以通过变化进行解析 ( 可以 embedding 是以 one hot 为输入的全链接层 )。
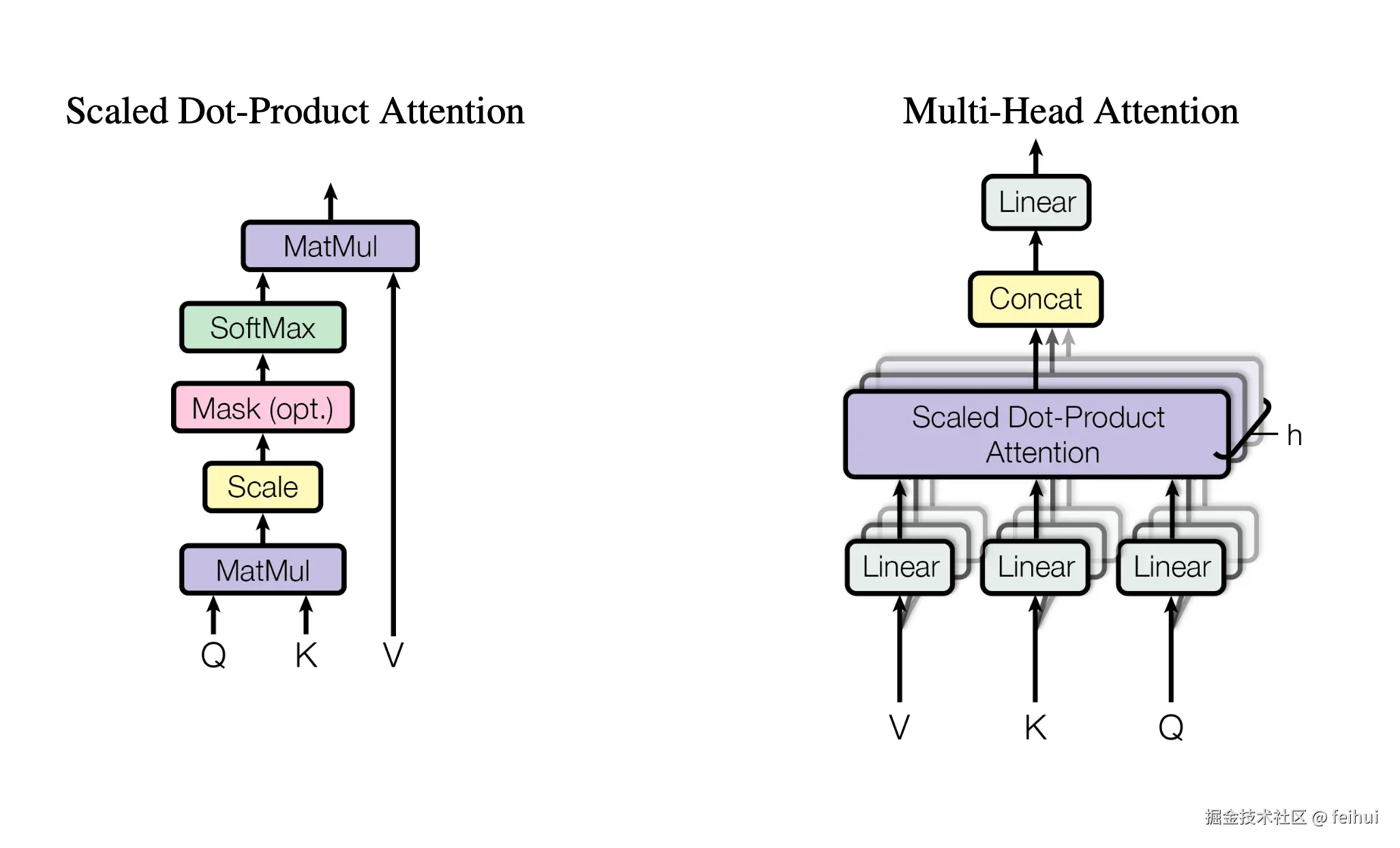
Nanogpt 对应核心代码如下:
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
# query / key / value 线性变换
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# output projection
# 输出线性变换
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size)).view(1, 1, config.block_size, config.block_size))
def forward(self, x):
# 并行处理 B 个 sample,每个 sample 包含 T 个 token,每个 token 包含 C 个维度
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# query、key、value 以及 mulit head 在一个线性变换中学习
# 通过 split 分割出 query、key、value
# 通过 view 改变矩阵形状拆 multi head
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
else:
# manual implementation of attention
# 计算 qeury 和 key 相关性
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
# 将相关性转换成 0 - 1 概率值
att = F.softmax(att, dim=-1)
# 随机将权重值 0,避免训练过拟合,增加模型鲁棒性
att = self.attn_dropout(att)
# value 权重和作为新 token embedding(如此包含上下文信息)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
# 拼接 multi head
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
# 拼接后 head 进行一次线性变化(类同多个卷积核不同的权重,学习不同的特征)
y = self.resid_dropout(self.c_proj(y))
return y
整体架构
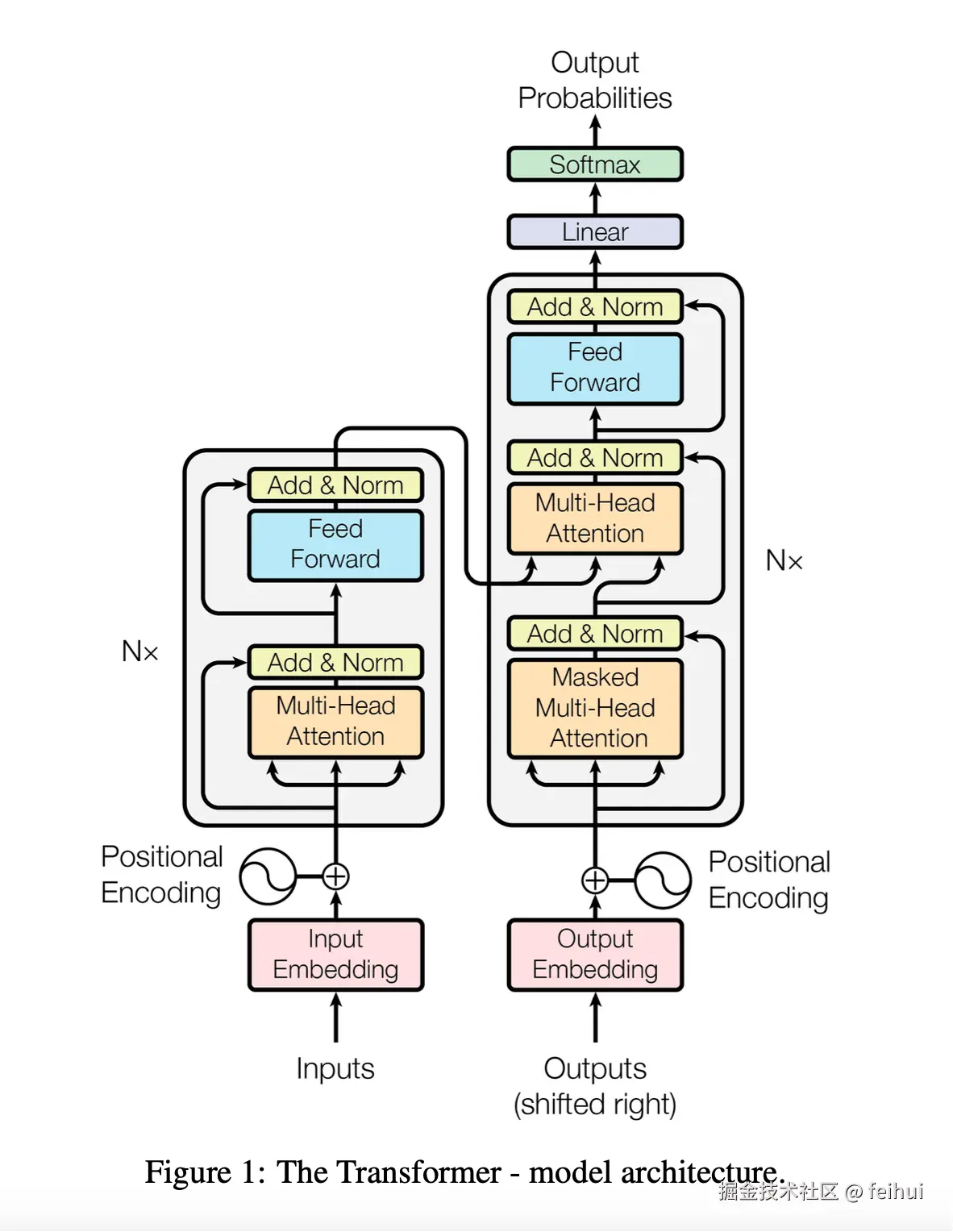
# Nanogpt 和论文略微不同的细节:
# 1. 使用可学习位置编码(Positional Embedding);
# 2. 先进行层归一化、再进行权重学习(Norm -> Mulit-Head Attention / Feed Forward -> ADD);
# 3. 仅实现 decoder:encoder 用于理解、decoder 用于续写、encoder + decoder 用于翻译;
class GPT.__init__:
self.transformer = nn.ModuleDict(dict(
# Output Embedding
wte = nn.Embedding(config.vocab_size, config.n_embd),
# Positional Embedding
wpe = nn.Embedding(config.block_size, config.n_embd),
drop = nn.Dropout(config.dropout),
# Nx
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
class Block__init__:
# Norm
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
# Multi-Head Attention
self.attn = CausalSelfAttention(config)
class CausalSelfAttention__init__:
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
# Norm
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
# Feed Forward
self.mlp = MLP(config)
class MLP__init__:
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
ln_f = LayerNorm(config.n_embd, bias=config.bias),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
前向传播
class GPT.forward:
# Output Embedding
tok_emb = self.transformer.wte(idx)
# Positional Embedding
pos_emb = self.transformer.wpe(pos)
x = self.transformer.drop(tok_emb + pos_emb)
# Nx
for block in self.transformer.h:
x = block(x)
class Block.forward:
# Norm -> Multi-Head Attention -> Add
x = x + self.attn(self.ln_1(x))
class CausalSelfAttention.forward:
B, T, C = x.size()
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.resid_dropout(self.c_proj(y))
# Norm -> Feed Forward -> Add
x = x + self.mlp(self.ln_2(x))
class MLP.forward:
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
# Linear
x = self.transformer.ln_f(x)
# 计算损失函数(交叉熵)
logits = self.lm_head(x)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取(扫下方二v码即可100%领取)

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)