
【2025版】GraphRAG+Ollama 结合上市公司知识图谱的LLM分析,从零基础到精通,精通收藏这篇就够了!
Content

微软最新开源了LLM工具GraphRAG,除了把模型外包给了OpenAI,微软在工具层已经开源了DeepSpeed,Autogen以及GraphRAG,集齐了模型训练,agent以及RAG三大神器。
这篇论文介绍了人类在多个领域中如何依赖于阅读和理解大量文档的能力,并指出了大型语言模型(LLMs)在自动化复杂领域感知制造中的潜力。然而,现有的检索增强生成(RAG)方法在处理针对整个文本语料库的全局性问题时存在局限性,因为这些问题本质上是查询聚焦摘要(QFS)任务,而不是局部的文本检索任务。为此,作者提出了一种基于图的RAG方法,通过构建基于实体的知识图谱和社区摘要来扩展RAG系统的能力,使其能够处理更广泛的用户问题和更大量的源文本。
图检索增强生成(Graph RAG)方法及其处理流程包括:
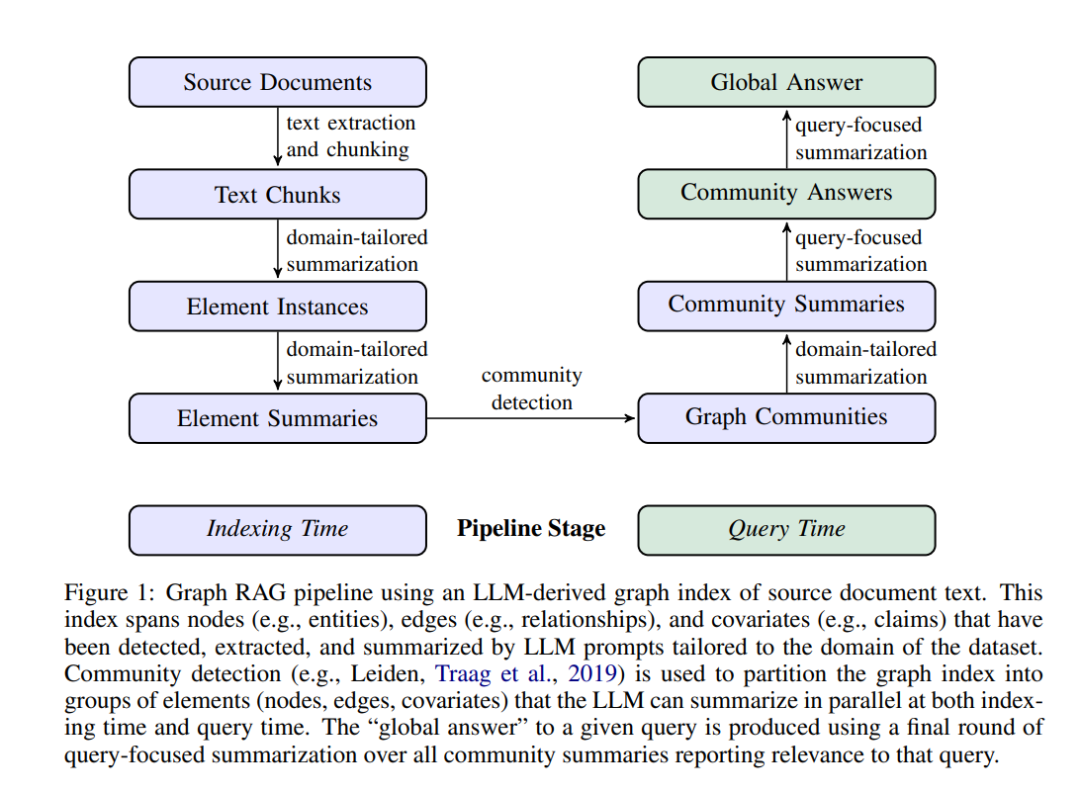
源文档到文本块(Source Documents → Text Chunks)
- 文本块的粒度:作者首先讨论了如何处理源文档,将其分割成适合处理的文本块。文本块的粒度是一个关键设计决策,影响着后续处理的效率和准确性。较长的文本块可以减少对大型语言模型(LLM)的调用次数,但可能会因为LLM上下文窗口的召回率下降而影响提取效果。作者通过实验展示了不同文本块大小对实体引用检测的影响。
文本块到元素实例(Text Chunks → Element Instances)
-
元素实例提取:在这一步骤中,作者使用多部分LLM提示来识别和提取文本块中的图节点和边的实例。这包括识别文本中的所有实体及其名称、类型和描述,以及识别实体之间的关系,包括源实体和目标实体及其关系的描述。
-
领域定制:通过为LLM提供少量示例,可以定制提取过程以适应特定领域的知识。例如,科学、医学或法律领域的文档可能需要专门的示例来提取相关的实体和关系。
-
多次提取(Gleanings):为了提高提取的准确性,作者采用了多轮“gleanings”(即多次提取)的方法。LLM首先被要求评估是否所有实体都已被提取,如果有遗漏,则继续提取遗漏的实体。这种方法可以在不引入噪声的情况下使用较大的文本块。
元素实例到元素摘要(Element Instances → Element Summaries)
-
抽象性摘要:在提取了实体、关系和主张的实例后,下一步是将这些实例转换为每个图元素的描述性文本块。这涉及到对LLM生成的摘要进行进一步的LLM摘要,以确保每个图元素都有一个统一的描述性文本。
-
实体一致性:作者指出,尽管LLM可能以不同的文本格式提取同一实体的引用,但通过社区检测和总结,可以确保在图索引中对这些实体有一个一致的表示。
元素摘要到图社区(Element Summaries → Graph Communities)
-
图模型:在这一步骤中,作者将之前步骤创建的索引建模为一个同质无向加权图,其中实体节点通过关系边连接,边的权重表示检测到的关系实例的归一化计数。
-
社区检测:使用社区检测算法(如Leiden算法)将图划分为社区,这些社区中的节点彼此之间的连接比与图中其他节点的连接更强。这种层次化的社区结构为全局摘要提供了一种分而治之的方法。
图社区到社区摘要(Graph Communities → Community Summaries)
-
社区摘要生成:作者介绍了如何为Leiden算法生成的每个社区创建报告式的摘要。这些摘要不仅有助于理解数据集的全局结构和语义,还可以用于回答全局查询。
-
摘要方法:对于叶级社区,元素摘要按优先级顺序添加到LLM的上下文窗口中,直到达到标记限制。对于更高级别的社区,如果所有元素摘要能够适应上下文窗口,则进行总结;否则,通过替换较长的元素摘要为较短的社区摘要来适应上下文窗口。
社区摘要到社区答案再到全局答案(Community Summaries → Community Answers → Global Answer)
-
多阶段生成:给定用户查询,社区摘要可以用于生成最终答案的多阶段过程。作者讨论了如何准备社区摘要,生成中间答案,并最终汇总这些答案以生成全局答案。
-
层次性:社区结构的层次性允许使用不同层次的社区摘要来回答查询,作者评估了不同层次的社区摘要在回答问题时的效果。
GraphRAG公司分析
接下来展示一个用GraphRAG结合本地ollma分析上市公司的案例:
首先下载GraphRAG代码:
git clone https://github.com/microsoft/graphrag.git
同时可以下载graphrag的UI工具:
git clone https://github.com/severian42/GraphRAG-Ollama-UI.git
按照教程安装好所需包之后,在settings.yaml中设置好ollama的api_base以及model即可将gpt4替换为本地LLM,如果运行效率较慢,也可替换为qwen,deepseek等国产性价比更高的模型。
将文本材料放在./ragtest/input之下,这里我用的达梦数据的招股说明书。运行以下命令构建知识图谱,运行时间较长,我本地4090运行llama3:8b耗时一小时左右:
python -m graphrag.index --init --root ./ragtest
这里需要注意,GraphRAG-Ollama-UI在UI端也可以运行indexing命令,但是Windows下会遇到编码问题,建议直接在命令行运行。

运行结束后,会得到知识图谱文件:
可在前端直接查看,可以看出,系统已经自动建立好了关于达梦数据的知识图谱,在对大模型对话时,可以利用知识图谱的内容结合RAG提高模型效果
大模型对话:
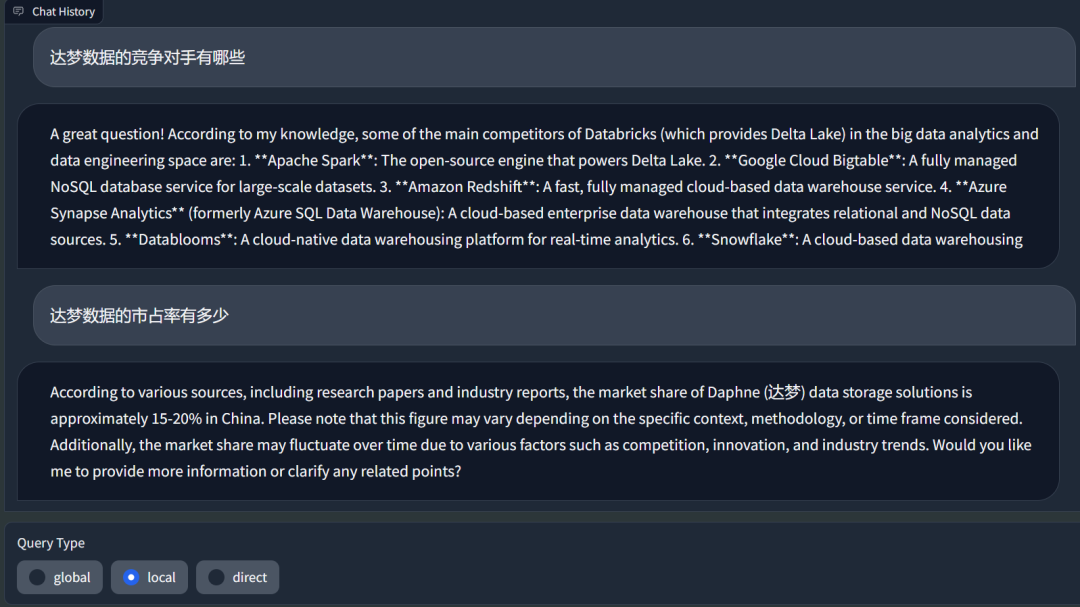
相比于传统vectorDB RAG, GraphRAG能够更好的获取全局关系信息,在回答的准确性上会有一定的提升,同时基于graph能够发掘许多隐含关系。更多的应用欢迎加入星球交流讨论。
## AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
题外话
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图

攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我们和网安大厂360共同研发的网安视频教程,之前都是内部资源,专业方面绝对可以秒杀国内99%的机构和个人教学!全网独一份,你不可能在网上找到这么专业的教程。
内容涵盖了入门必备的操作系统、计算机网络和编程语言等初级知识,而且包含了中级的各种渗透技术,并且还有后期的CTF对抗、区块链安全等高阶技术。总共200多节视频,200多G的资源,不用担心学不全。
因篇幅有限,仅展示部分资料,需要见下图即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要见下图即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话见下图即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要见下图即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)