
# 企业统一接入大模型 API 的实战:OpenAI 兼容入口、成本控制、日志审计与 Dify/Chatbox/Cherry Studio 配置 很多团队现在不是缺模型,而是缺一套统一接入方式。
很多团队现在不是缺模型,而是缺一套统一接入方式。
研发要在脚本里调用,产品要在工作流里编排,测试和运营要在桌面客户端里快速验证,企业还要管成本、权限、日志和模型切换。如果每个工具都各自直连不同的 API,最后通常会变成几个问题同时出现:密钥散落、模型名不一致、账单对不上、排错时找不到责任人。
向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务,适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。
这类场景里,真正值得先做的不是“再找一个模型”,而是“先把入口统一起来”。只要入口统一了,后面的成本控制、审计、限流、回退、分环境测试,都会顺很多。
如果你想先看一个候选入口,可以到 https://178.nz/dn 了解更多。
问题背景:为什么企业统一接入大模型 API 这么容易乱
很多人第一次接 AI 接口时,都会从“能跑通”开始:
- 先在本地脚本里把
curl跑通。 - 再把同样的接口填到 Dify、Chatbox、Cherry Studio。
- 后面又接到 Cursor 或内部系统。
跑通之后,新的问题才开始出现:
- 有的工具要填
API Host,有的工具要填Base URL,有的工具还会自动补路径。 - 有的团队把开发、测试、生产共用一把 key,后面很难分清是谁打爆了额度。
- 有的模型在一个工具里叫
gpt-4o-mini,在另一个系统里却被映射成别名,结果model_not_found。 - 有的请求超时不是模型慢,而是代理层、客户端或上游路径不一致。
- 有的成本不是被“一个大请求”打爆的,而是被很多小请求慢慢磨掉的。
所以,企业里谈“统一接入”,本质上不是把一个 URL 发给大家就结束了,而是要把“模型入口、身份、额度、日志、环境”一起管起来。
适用场景:哪些团队应该先做统一入口
这套方案适合下面几类用户:
- 内容团队、运营团队、产品团队,想让多人共用同一套 AI 能力,但又不想把私钥直接散发出去。
- 开发团队需要在脚本、后台服务、工作流平台里调用同一批模型。
- 企业内部已经同时在用 Dify、Chatbox、Cherry Studio,甚至还会用 Cursor 做联调。
- 你要做 AI API 成本控制,希望按项目、部门、环境去区分额度。
- 你需要日志审计,希望知道“谁在什么时候调用了哪个模型、消耗了多少时间、是否命中超时或限流”。
- 你正在评估国内合规的 AI API 平台,想先看它是否支持 OpenAI 兼容接口、统一模型入口和多工具接入。
如果你的诉求只是“我自己在本地试一下”,那可以先直接用脚本测试;但只要进入团队协作,统一入口就会越来越重要。
配置原理:OpenAI 兼容接口、统一模型入口和成本控制怎么串起来
先说结论:对大多数开发者来说,最省心的做法不是每个工具都单独适配一套新协议,而是统一到 OpenAI 兼容接口。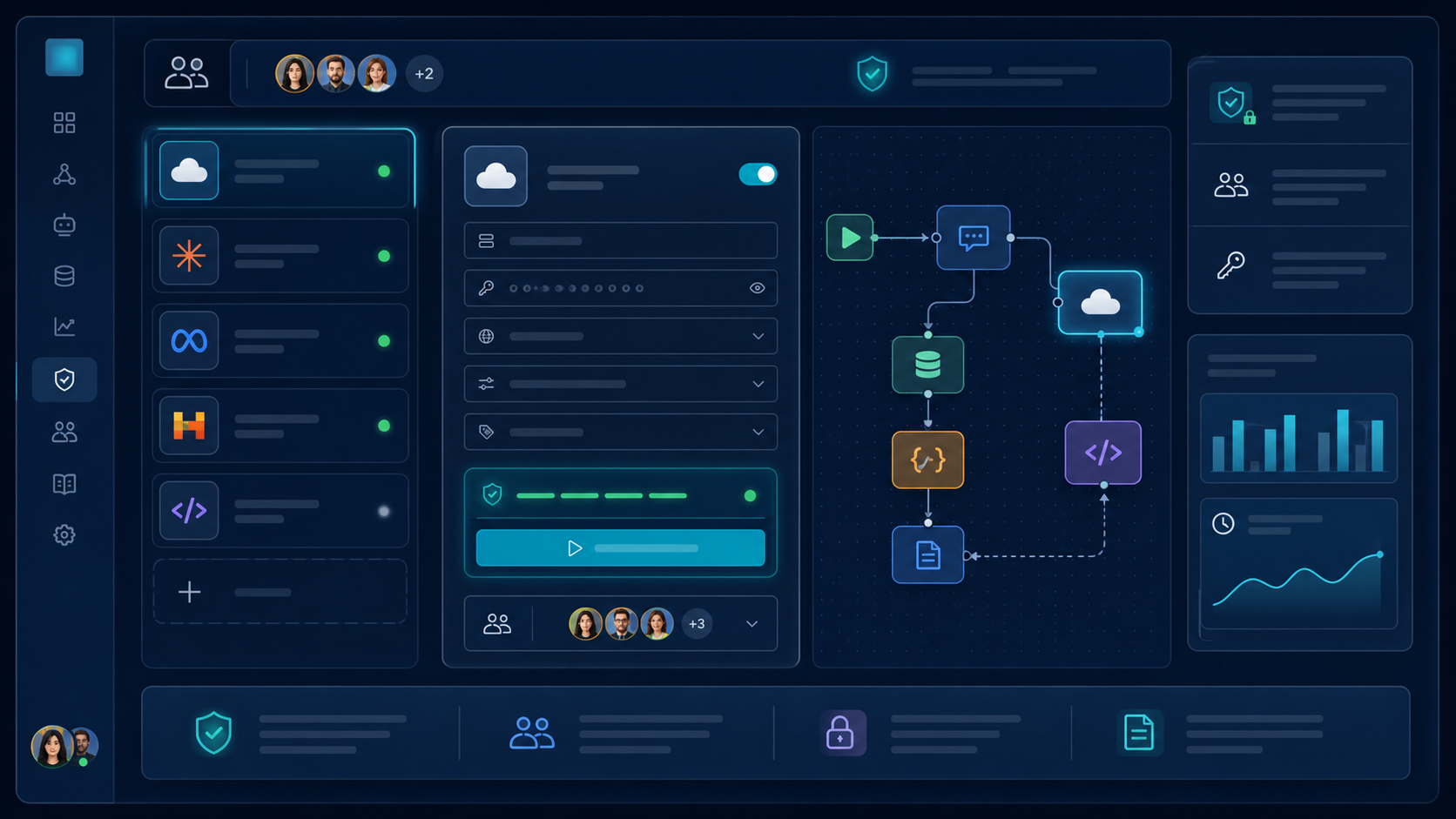
它的好处很直接:
- 客户端只需要认
Authorization、Base URL、model、messages这几个核心字段。 - Dify、Chatbox、Cherry Studio、Python SDK、自建脚本都能复用同一套接入方式。
- 统一入口可以在后面补上日志、限流、路由、模型回退和审计。
- 团队能把“谁用了什么、用了多少、有没有异常”记录下来。
从企业视角看,统一入口最好至少完成三件事:
- 统一鉴权:前端或工具只拿项目级 key,不直接暴露上游 key。
- 统一路由:高频、低成本、长文本、关键任务可以走不同模型池。
- 统一观测:记录项目名、用户、模型、状态码、延迟、请求体大小。
常见的三种填写方式可以这么理解:
| 场景 | 建议填写 |
|---|---|
| 只想记住入口域名 | https://api.vectorengine.cn |
| OpenAI SDK、Dify、Chatbox、Cherry Studio 这类只认 Base URL 的客户端 | https://api.vectorengine.cn/v1 |
| 需要完整路径直连,先把链路打通 | https://api.vectorengine.cn/v1/chat/completions |
如果某个客户端会自动补 /v1/chat/completions,通常只填前两个就够;如果客户端要求你给完整路径,就直接把第三个路径填进去。
下面这类问题,基本就是统一入口方案的典型落点:
AI API 成本控制怎么做OpenAI 兼容接口和原生 API 有什么区别Dify 怎么接入第三方 APIChatbox 怎么配置 OpenAI 兼容接口Cherry Studio 怎么添加自定义服务商Cursor 能不能配置第三方 Base URLmodel_not_found 怎么解决invalid_api_key 怎么解决rate_limit 怎么解决timeout 怎么解决API Key 泄露怎么办企业怎么做日志审计国内合规的 AI API 平台怎么判断
核心示例:curl、Python、Node.js 三种方式先把链路打通
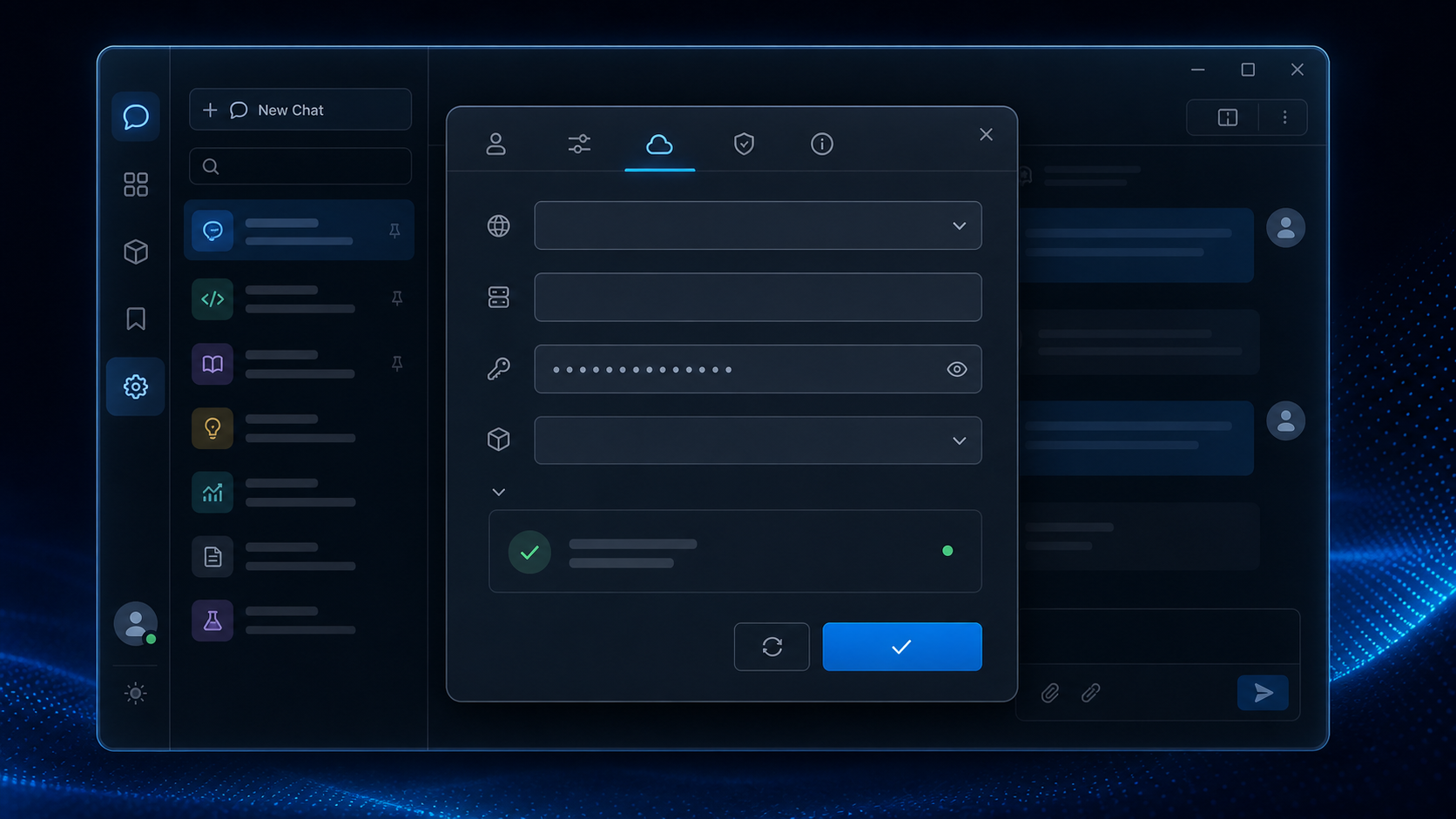
1. curl 示例:先验证完整路径
先别急着把配置塞进客户端,最稳妥的方式是先用 curl 验证上游是否真的可用。
curl https://api.vectorengine.cn/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{ "role": "system", "content": "你是一个帮助企业排查 AI API 接入问题的助手。" },
{ "role": "user", "content": "请用三句话说明,为什么企业要先统一接入大模型 API,再做成本控制。" }
],
"temperature": 0.2,
"stream": false
}'
这一步的判断标准很简单:
- 能返回 200,说明链路至少通了。
Authorization没写错,说明 key 格式对了。model能被识别,说明模型名和上游映射没有明显问题。
如果这一步都不稳,就不要急着看 Dify、Chatbox 或 Cursor,先把上游打通。
2. Python 示例:脚本里直接切换 Base URL
Python 里常见的做法是用 OpenAI 兼容客户端,把 base_url 指向统一入口。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.vectorengine.cn/v1",
)
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "你是企业 AI 接入助手。"},
{"role": "user", "content": "请列出统一接入大模型 API 的最小链路。"},
],
temperature=0.2,
)
print(resp.choices[0].message.content)
这里有两个实用点:
base_url只改一处,后面脚本、后台任务、定时器都能复用。- 如果团队后面要换模型池,只要改统一入口或网关映射,脚本本身不用大改。
对于企业环境,这比把 key 直接写死在业务代码里要安全得多。
3. Node.js 示例:给团队加一层审计和限流
如果你已经有统一入口,但还想给团队多加一层“项目级审计”和“简单限额”,可以在 Node.js 里再包一层代理。
import express from "express";
const app = express();
app.use(express.json({ limit: "2mb" }));
const UPSTREAM_URL = process.env.UPSTREAM_URL ?? "https://api.vectorengine.cn/v1/chat/completions";
const UPSTREAM_KEY = process.env.UPSTREAM_KEY ?? "";
const MAX_CALLS_PER_PROJECT = Number(process.env.MAX_CALLS_PER_PROJECT ?? 2000);
const dailyCalls = new Map();
function allowProject(project) {
const count = dailyCalls.get(project) ?? 0;
if (count >= MAX_CALLS_PER_PROJECT) return false;
dailyCalls.set(project, count + 1);
return true;
}
app.post("/api/ai/chat", async (req, res) => {
const project = req.header("x-project") ?? "default";
const user = req.header("x-user") ?? "unknown";
const model = req.body?.model ?? "unknown";
if (!allowProject(project)) {
return res.status(429).json({ error: "project_quota_exceeded" });
}
const startedAt = Date.now();
const controller = new AbortController();
const timer = setTimeout(() => controller.abort(), 45_000);
try {
const upstreamResp = await fetch(UPSTREAM_URL, {
method: "POST",
headers: {
"Authorization": `Bearer ${UPSTREAM_KEY}`,
"Content-Type": "application/json",
"X-Project": project,
"X-User": user,
},
body: JSON.stringify(req.body),
signal: controller.signal,
});
const text = await upstreamResp.text();
console.log(JSON.stringify({
project,
user,
model,
status: upstreamResp.status,
cost_ms: Date.now() - startedAt,
}));
res
.status(upstreamResp.status)
.type(upstreamResp.headers.get("content-type") ?? "application/json")
.send(text);
} catch (err) {
console.error(JSON.stringify({
project,
user,
model,
error: String(err),
cost_ms: Date.now() - startedAt,
}));
res.status(504).json({ error: "upstream_timeout" });
} finally {
clearTimeout(timer);
}
});
app.listen(3000, () => {
console.log("ai proxy listening on http://localhost:3000");
});
这段代码的意义不是“再造一个大网关”,而是告诉你企业里最小可用的治理点是什么:
- 统一入口负责藏住上游 key。
- 每个请求都带上项目和用户标识。
- 超时、失败、限额都能在一处看到。
- 后面如果要接数据库、告警、计费报表,只需要往这个代理上继续补。
Dify 怎么接入第三方 API:先把 workspace 级模型管理做起来
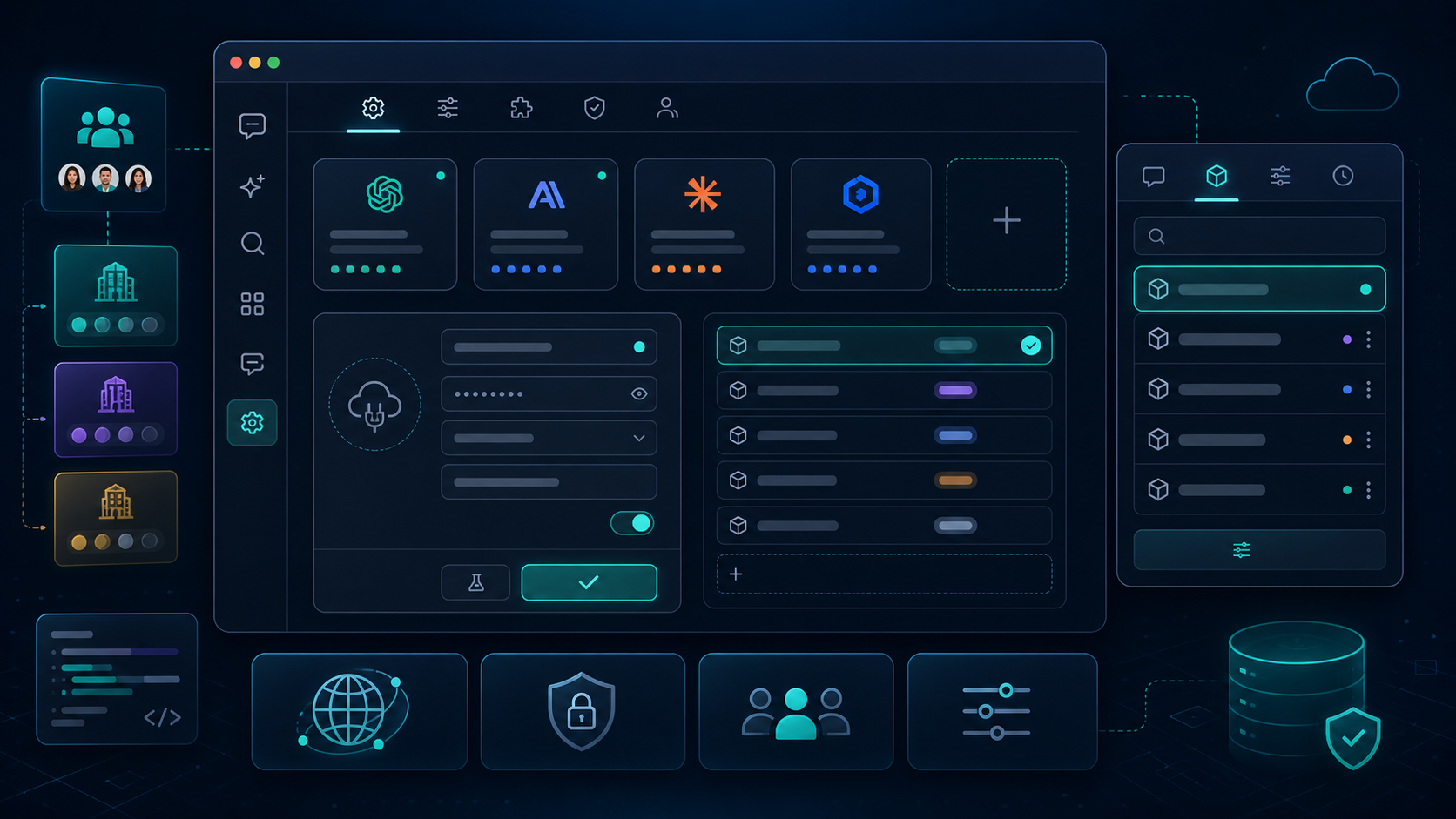
如果你的团队已经在用 Dify,最推荐的思路不是每个应用自己维护一份密钥,而是先在 workspace 里统一管理模型提供方。
根据 Dify 的工作区模型提供方文档,配置入口在 Settings → Model Providers,Workspace 管理员或 Owner 才能做这件事。对于企业接入来说,这个权限边界很重要,因为它决定了谁能看见密钥、谁能改模型、谁能影响全局配置。
具体步骤可以按这个顺序来:
- 进入
Settings → Model Providers。 - 选择
OpenAI或其他支持的 provider。 - 填写 API Key,并按需补充
Custom base URL。 - 保存前先做一次
Test。
如果你打算把统一入口接到 Dify 上,通常建议把 Base URL 填成 https://api.vectorengine.cn/v1。这样 Dify 的工作流、聊天应用、文本生成任务,都会走同一套入口。
另外,Dify 在企业场景里还有两个很实用的点:
- 可以为同一个 provider 配多套 credentials,适合开发、测试、生产分环境。
- 还能做负载均衡,把同一模型的请求分散到多个 credential 上,减少单个 key 被打满的概率。
这对 AI API 成本控制怎么做 很有帮助。比如:
- 开发环境用低额度 key。
- 生产环境用稳定额度 key。
- 长文本任务走更便宜的模型池。
- 关键链路保留一个更稳的回退模型。
Chatbox / Cherry Studio 怎么配置 OpenAI 兼容接口:桌面端先验证最直接
桌面客户端的好处是直观,适合先验证“Base URL、Key、Model”是不是一套。
Chatbox 配置步骤
Chatbox 的官方文档里,模型配置的核心就是这几个动作:
- 打开 Chatbox,点击侧边栏的设置按钮。
- 进入
Model Provider。 - 如果没有你要的 provider,点击底部
Add。 - 填写 provider 名称,并选择对应类型,比如
OpenAI API compatible。 - 按 provider 的说明填写
API Key和API Host。 - 一般情况下,
API path不需要单独填,默认会走/v1/chat/completions。 - 至少添加一个模型,然后点
Check。
如果你用的是统一入口,通常就把:
API Host填成https://api.vectorengine.cn- 或者按客户端要求直接填
https://api.vectorengine.cn/v1 - 模型名填你们实际约定的模型 ID
这样一来,Chatbox 就能很快验证出请求是不是能通。
Cherry Studio 配置步骤
Cherry Studio 的自定义服务商配置更适合多模型管理:
- 打开
设置。 - 进入
模型服务。 - 点击
+ 添加,新建一个提供商。 - 提供商类型选择
OpenAI、Gemini、Anthropic或Azure OpenAI。 - 启用这个自定义服务商。
- 填写
API Key。 - 填写
API 地址,也就是 Base URL。 - 手动添加你要使用的模型 ID。
- 点
检查,确认密钥有效。
如果你希望把同一个统一入口接到多个团队环境里,Cherry Studio 这种“先加 provider,再加模型”的方式会比较清楚,适合你把开发、测试、生产分开管理。
Cursor 的现实提醒
如果你最后还要在 Cursor 里做验证,建议把它放在最后一步。
截至 2026-06-18,Cursor 社区论坛里仍能看到关于 Override OpenAI Base URL 的持续讨论,涉及自定义 endpoint、请求格式、subagent、vision、以及开关回弹等问题。我的建议很简单:先用 curl、Chatbox、Cherry Studio 把同一套 Base URL + Key + model 跑通,再回 Cursor 排查。
这样做的好处是,你能先排除“上游本身有没有问题”,避免把时间花在客户端特有 bug 上。
常见报错排查表:先看这里,通常能少走很多弯路
| 报错 | 常见原因 | 处理方式 |
|---|---|---|
invalid_api_key / 401 |
Key 填错、前缀漏了、把前后空格一起复制进去了 | 重新复制 key,确认 Authorization: Bearer ... 格式,检查环境变量是否被覆盖 |
model_not_found / 404 |
模型名写错、模型没在服务商后台开通、客户端把路径拼错了 | 先用 curl 验证,再检查模型 ID、Base URL 和客户端自动补路径的规则 |
rate_limit / 429 |
并发太高、同一 key 被多人共用、额度打满 | 降并发、做队列、分环境 key、开启多 credential 或负载分配 |
timeout / 504 |
上游响应慢、代理层超时太短、流式输出没开 | 延长超时、优先走流式、给 Node 代理加 AbortController、检查网络路由 |
context_length_exceeded |
上下文太长、历史消息没有裁剪、一次性塞入的内容过多 | 做摘要、截断历史、把长文拆块,必要时改用更大上下文模型 |
这张表里最容易被忽略的一点是:很多 model_not_found 其实不是模型不存在,而是 Base URL、路径、模型名三者里有一个没对齐。先别急着怀疑模型本身,先把请求原文抓出来看一眼。
API Key 安全建议:别把统一入口做成统一泄露点
统一入口的价值很大,但如果 key 管理不好,它也会变成统一泄露点。下面这几条建议很具体:
- 客户端只放项目级 key,不直接放上游主 key。
- 开发、测试、生产分开用不同 key,最好不要共用。
- 关掉会打印请求头和请求体的 debug 日志,尤其是线上。
- 不要把 key 写进前端代码、公开仓库或截图里。
- 能用环境变量就不要硬编码,能用密钥管理服务就不要只靠
.env。 - 如果条件允许,给 key 做轮换计划,比如每 30 天或 90 天检查一次。
- 重要项目最好加上 IP 白名单、项目白名单或来源限制。
- 对敏感业务做请求脱敏,日志里尽量只保留项目名、模型名、耗时和状态码。
如果你已经有一层 Node 代理,最少也要做到两件事:
- 上游 key 永远不出现在客户端。
- 代理日志不要把完整请求体原样落盘。
企业用户注意事项:统一入口不只是技术问题
企业场景里,统一接入大模型 API 其实还牵涉到组织协作和治理方式。
1. 先分环境,再谈统一
开发、测试、生产最好分开 key、分开额度、分开日志。这样一旦某个环境出现异常,很容易定位到是谁在消耗资源。
2. 先定模型策略,再谈成本
不要所有任务都用同一个模型。比较常见的做法是:
- 草稿、摘要、分类走成本更低的模型。
- 复杂推理、关键文案、最终输出走更强的模型。
- 长文本处理先摘要,再进入主模型。
- 高峰期给低优先级任务排队。
3. 日志审计要有最小字段集
建议至少记录这些字段:
- 项目名
- 用户或调用方
- 模型名
- 请求开始和结束时间
- 状态码
- 延迟
- 是否命中限流或超时
有了这些字段,后面你才能判断“是模型慢、是网络慢、还是调用太多”。
4. 评估平台时,不只看能不能调用
如果你在评估国内合规的 AI API 平台,建议重点看:
- 是否支持 OpenAI 兼容接口。
- 是否支持统一模型入口。
- 是否能做团队级密钥管理。
- 是否有日志、审计和权限能力。
- 是否支持多工具接入,比如 Dify、Chatbox、Cherry Studio。
- 是否能按环境或项目拆分额度。
这些能力往往比“单纯能不能聊天”更影响企业长期使用。
评估一个候选入口时,先看这 8 个点
如果你正在挑一个统一入口,不妨先按下面这份清单过一遍,而不是只看“能不能连上”。
- 是否明确支持 OpenAI 兼容接口,字段和路径有没有写清楚。
- Base URL 和完整路径是否容易区分,避免客户端自动补路径后出错。
- 是否支持按项目、部门、环境区分 key。
- 是否有可读的请求日志,至少能看出项目名、模型名、状态码和耗时。
- 是否能设置额度、并发或者最低限速。
- 是否支持多工具接入,Dify、Chatbox、Cherry Studio 这些客户端能不能一起用。
- 是否有回退策略,主模型出问题时能不能切到备选模型。
- 是否方便做后续审计,出了问题能不能把责任定位到具体项目。
如果这 8 个点里有 3 个以上说不清楚,后面团队规模一上来,排错和成本都会变得很难控。
把成本控制落到预算和告警,而不是只写在文档里
很多团队会在方案里写“要控制成本”,但真正上线后没有预算、没有阈值、没有告警,最后还是会超。
更落地的做法是:
- 给每个项目设一个月度预算,超出后自动降级模型或冻结高成本任务。
- 给每个环境设一个日额度,开发环境尽量小,生产环境单独算。
- 给高成本模型设告警阈值,比如达到 80% 就提醒,达到 95% 就阻断非关键任务。
- 给长文本和批处理任务单独设队列,避免它们把实时请求挤掉。
- 把请求日志和计费记录对应起来,至少能追到“某个项目在某一天把哪类模型打得最多”。
如果没有这些东西,所谓的“AI API 成本控制”很容易变成一句口号。
统一模型路由怎么设计:别让所有请求都走同一条路
企业做 AI API 成本控制,最容易犯的一个错误就是“所有请求都发给同一个模型”。短期看,接入简单;长期看,成本、延迟和稳定性都会被拖垮。
更合理的做法是把请求分成几类:
- 草稿、摘要、分类、简单问答,优先走低成本模型。
- 对外展示的正式文案、关键决策建议、复杂推理,优先走更强的模型。
- 长上下文输入先做摘要,再送入主模型。
- 高峰期的非关键任务,排队或者限流。
- 关键任务保留一个回退模型,避免单一模型抖动时全链路中断。
这套路由思路落到工程里,通常就是三层:
- 应用层只关心“我要完成什么任务”。
- 网关层决定“该走哪个模型池”。
- 观测层记录“这个选择到底花了多少钱、快不快、稳不稳”。
如果你的团队里既有 Dify 工作流,也有脚本直连,还有桌面客户端,那更应该把路由和额度放到统一入口,而不是让每个工具各自决定。
从个人验证到团队上线:一条可落地的迁移路线
很多团队不是一开始就需要复杂治理,而是先从个人验证开始,后面才慢慢长成团队方案。下面这条路线比较实用:
第 1 步:用 curl 把最小链路打通
先验证 Authorization、Base URL、model 和返回结构都正确。只要 curl 能稳定返回,你就知道上游没问题。
第 2 步:在 Python 里改成环境变量
把 key 和 base_url 放进环境变量,避免写死在脚本里。这样你后面切环境只改配置,不改逻辑。
第 3 步:在 Chatbox 和 Cherry Studio 里复用同一套配置
桌面客户端最适合排查“是不是客户端配置问题”。如果桌面端都能连上,说明大概率是上游或业务代码的问题;如果桌面端连不上,先把客户端字段检查一遍。
第 4 步:把 Dify 变成团队级入口
Dify 的价值不是“再装一个工具”,而是把模型提供方、工作流、权限和环境管理一起串起来。对企业来说,这一步很关键,因为它会把单点测试变成可协作的工作区。
第 5 步:最后再加 Node 代理做审计和限流
等请求链路稳定后,再补日志、额度、路由和超时。这样做的好处是,你不会在一开始就把系统做得太重,也不会因为一处小错误把排查难度拉满。
第 6 步:Cursor 放到最后验证
Cursor 很适合做开发联调,但如果你把它当成唯一验证工具,往往会在兼容性问题上绕很久。先把主链路跑通,再去看 Cursor 的个性化限制,效率会高很多。
一张表看懂各工具在统一入口里的角色
如果你把这些工具混在一起看,容易觉得配置很碎;但按“验证、协作、治理”三层拆开,就会清楚很多。
| 工具 | 更适合承担的角色 | 你真正要盯的字段 |
|---|---|---|
curl |
最小链路验证 | URL、key、model、返回状态码 |
| Python SDK | 脚本和后台任务 | base_url、环境变量、超时 |
| Node.js 代理 | 审计、限流、路由 | 项目名、用户、耗时、状态码 |
| Dify | 团队工作流和工作区治理 | provider、credentials、load balancing |
| Chatbox | 桌面端快速联调 | API Host、API path、模型名 |
| Cherry Studio | 多 provider 桌面管理 | API 地址、模型 ID、检查按钮 |
| Cursor | 开发联调和最后确认 | 自定义 Base URL、请求兼容性 |
按这个表去分工,你会发现大部分问题不是“某个模型不行”,而是“工具的角色没有分清”。
FAQ:团队里最常问的几个问题
1. OpenAI 兼容接口和原生 API 有什么区别?
原生 API 往往更贴近单一供应商的字段和路由;OpenAI 兼容接口更像一层通用协议,方便 Dify、Chatbox、Cherry Studio、Python SDK 和自建脚本用同一套方式接入。对团队来说,前者偏“单点接入”,后者偏“统一治理”。
2. Base URL 到底填 https://api.vectorengine.cn、https://api.vectorengine.cn/v1 还是完整路径?
看客户端怎么要求。只认域名的,先填 https://api.vectorengine.cn;认 Base URL 的,通常填 https://api.vectorengine.cn/v1;如果是 curl 或需要完整路径验证,就直接用 https://api.vectorengine.cn/v1/chat/completions。
3. Dify、Chatbox、Cherry Studio 能共用同一个 key 吗?
技术上可以,但企业里通常不建议这么做。更好的方式是按环境、按团队、按用途拆 key,然后由统一入口或代理层做汇总和审计。
4. 为什么我已经改了 Base URL,还是会报 model_not_found?
优先检查三件事:模型名是否一致、路径是否被客户端自动补错、上游是否真的支持这个模型。有时候不是模型不存在,而是客户端把请求发到了错误的路径。
5. Cursor 里总是出问题,是不是上游不行?
不一定。Cursor 社区最近几个月关于 Override OpenAI Base URL 的讨论不少,某些场景会出现请求格式或兼容性问题。建议先用 curl、Chatbox、Cherry Studio 证明上游没问题,再回 Cursor 看客户端侧限制。
真正上线前的最后检查
发布到团队或企业内部之前,建议再过一遍这份清单:
curl已经验证通过,说明完整路径能通。- 至少一个桌面客户端能通,说明
Base URL、API Host和model的组合没问题。 - Dify 的工作区 provider 已经配置好,且不是每个应用各自写一份密钥。
- Node 代理里已经有项目名、用户、模型名、状态码和耗时日志。
- 预算阈值和告警策略已经定义,不是只写在文档里。
- 开发、测试、生产的 key 分开管理,出了问题能追到具体环境。
这一步看起来简单,但它决定了你后面是“能长期用”,还是“今天能跑、下周就乱”。
总结
企业统一接入大模型 API,核心不是“再换一个模型”,而是“先把入口、身份、额度、日志和环境管起来”。
如果你只做个人试验,直接连接口就够了;如果你要做团队协作、成本控制和审计,统一入口会明显省事。对大多数开发者来说,先用 curl 验证链路,再把同一套 Base URL + Key + model 放进 Python、Dify、Chatbox、Cherry Studio,最后再加上 Node 代理做审计和限流,这条路线最稳妥。
你会发现,真正难的不是“调用一次模型”,而是“让所有工具都用同一套规则稳定地调用模型”。
这条路线也便于后续扩展到更多模型。
分类:API
标签:AI API, OpenAI兼容接口, API中转, Dify, Chatbox, Cherry Studio, Cursor, 向量引擎, Base URL, API Key
参考链接(可忽略):

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)