
AI Agent 的记忆存在哪?
·
概述
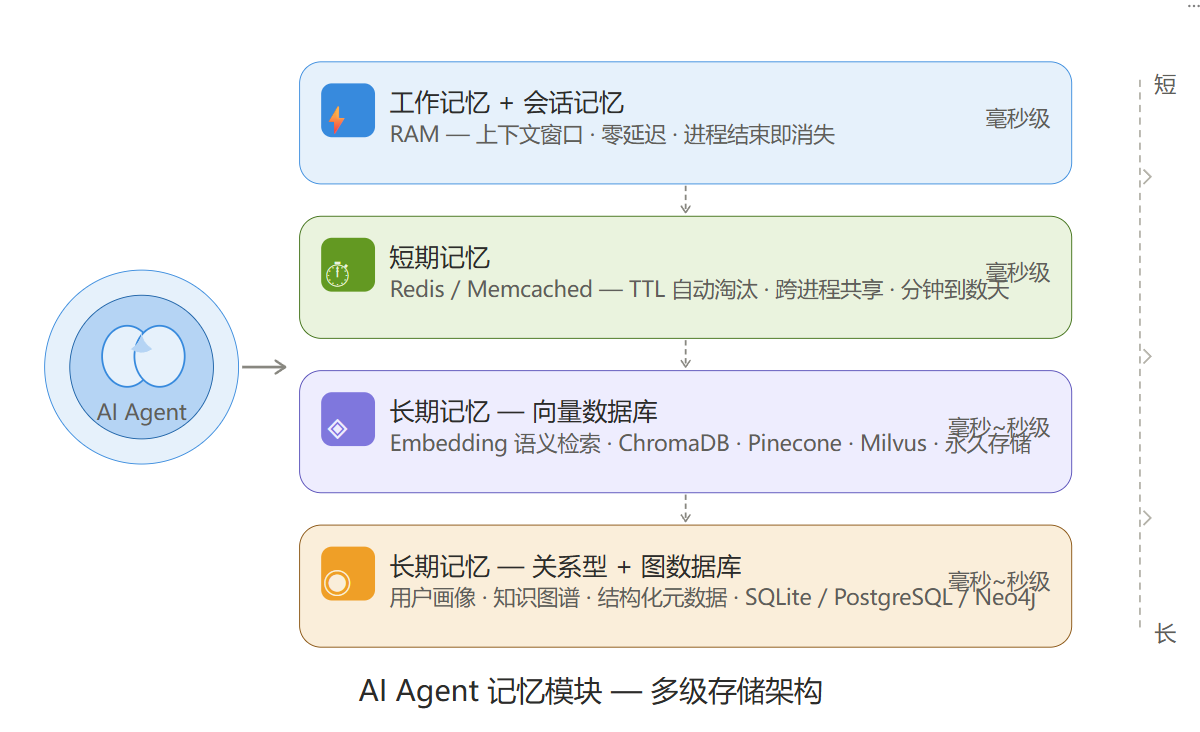
AI Agent 的记忆模块并非依赖单一介质,而是根据记忆类型分层存储在不同介质上,形成多级存储架构。
记忆分层与对应存储介质
| 记忆类型 | 生命周期 | 存储介质 | 典型实现 | 示例数据 |
|---|---|---|---|---|
| 会话记忆 (Conversation Memory) | 单次会话 | 内存 (RAM) | Python list/dict、上下文窗口 | 当前对话历史、临时指令 |
| 短期记忆 (Short-term Memory) | 数分钟~数天 | Redis / Memcached (分布式缓存) | KV 缓存、Session Store | 用户临时偏好、未保存的草稿 |
| 长期记忆 (Long-term Memory) | 持久化 | 向量数据库 + 关系型数据库 + 图数据库 | 多种组合 | 用户画像、历史对话摘要、知识图谱 |
| 工作记忆 (Working Memory) | 任务期间 | 内存 (RAM) | Scratchpad、中间变量 | 当前任务状态、Tool 调用结果 |
详细分析
1. 内存 (RAM) — 最快,但不持久
- 用途: 存储当前会话的完整历史、Prompt 上下文
- 上限: 受模型上下文窗口(Context Window)限制
- 优点: 零延迟,读写开销最小
- 缺点: 进程关闭即丢失;长对话会撑爆上下文窗口
2. Redis / Memcached (分布式缓存) — 快速,跨进程共享
- 用途: 跨请求的临时数据、用户 Session、短期偏好
- 特点:
- 支持 TTL(过期时间),自动淘汰
- 可跨多个服务实例共享
- 适合存储最近几轮的对话摘要,超出上下文窗口后快速注入
3. 向量数据库 (Vector DB) — 长期语义记忆的核心
- 用途: 存储历史对话、知识片段的 Embedding 向量,实现语义检索
- 典型产品:
- 本地/轻量: ChromaDB、FAISS (Facebook)、LanceDB、Qdrant
- 云端: Pinecone、Milvus、Weaviate、Elasticsearch (kNN)
- 数据形式:
{id, vector(1536维), metadata(时间戳/标签/用户ID), content(原始文本)} - 典型检索: 用户问"A",向量库返回"半年前用户提过的相关偏好"
4. 关系型数据库 (RDBMS) — 结构化元数据
- 用途: 存储用户画像、会话元信息、结构化配置
- 典型产品: SQLite(本地轻量)、PostgreSQL、MySQL
- 存储内容:
users表: 用户 ID、昵称、偏好设置sessions表: session_id、创建时间、摘要memories表: 关键记忆条目(提取后的文本 + 向量 ID)
5. 图数据库 (Graph DB) — 实体关系记忆
- 用途: 存储实体之间的复杂关系(谁认识谁、什么属于什么)
- 典型产品: Neo4j、ArangoDB
- 例子: "张三 → 是 → 李四的上级"、"项目A → 使用了 → 技术栈B"
6. 文件系统 / 对象存储 — 对话日志与快照
- 用途: 全量对话日志存盘、备份、审计
- 典型产品: 本地磁盘、S3/OSS/MinIO
- 场景: JSON Lines 格式记录完整对话流,供后续微调/分析
典型 Agent 框架的实现参考
| 框架 | 记忆存储方式 |
|---|---|
| LangChain | ConversationBufferMemory(内存) → ConversationSummaryMemory(内存+LLM摘要) → VectorStoreRetrieverMemory(向量库) |
| LangGraph | 状态图内置 Checkpointer(SQLite/Postgres),支持断点续跑 |
| MemGPT / Letta | 虚拟上下文管理,OS 式数据分页(内存↔长期存储自动调度) |
| AutoGen | 依赖开发者手动管理,通常对接 Redis + 外部 DB |
总结:多级存储架构图
┌─────────────────────────────────────────────────────┐
│ 用户请求 │
└──────────────────────┬──────────────────────────────┘
▼
┌─────────────────────────────────────────────────────┐
│ L0: RAM (上下文窗口) │
│ 当前对话历史 → 最高优先级,最快访问 │
└──────────────────────┬──────────────────────────────┘
▼ (检索增强)
┌─────────────────────────────────────────────────────┐
│ L1: Redis (近期缓存) │
│ 近期对话摘要、临时偏好 → TTL自动过期,跨请求共享 │
└──────────────────────┬──────────────────────────────┘
▼ (语义检索)
┌─────────────────────────────────────────────────────┐
│ L2: 向量数据库 (长期语义记忆) │
│ Embedding → 相似度检索 → 返回相关历史/知识片段 │
└──────────────────────┬──────────────────────────────┘
▼ (结构化查询)
┌─────────────────────────────────────────────────────┐
│ L3: RDBMS / GraphDB (持久化存储) │
│ 用户画像、关键事实、实体关系、完整日志 │
└─────────────────────────────────────────────────────┘
一句话: 记忆模块多采用 RAM(热) + Redis(温) + 向量库 + RDBMS/图库(冷) 的分层架构,以实现速度与持久化的平衡。
补充:Claude Code 的"反常规"选择——纯本地 Markdown 文件
它怎么做的
Claude Code 的记忆存储完全不走上述多级架构,而是采用极简方案:
| 记忆层级 | 介质 | 位置 | 内容 |
|---|---|---|---|
| 项目记忆 | Markdown 文件 | 项目根/CLAUDE.md |
项目级指令、约定、架构笔记 |
| 团队记忆 | Markdown 文件 | 项目根/.claude/MEMORY.md |
可由 git 共享的团队知识 |
| 用户全局记忆 | Markdown 文件 | ~/.claude/CLAUDE.md |
跨项目的个人偏好、习惯 |
| 用户私密记忆 | Markdown 文件 | ~/.claude/MEMORY.md |
不上 git 的私人配置 |
| 短期对话记忆 | RAM(上下文窗口) | 进程内存 | 当前对话历史 |
没有 Redis,没有向量数据库,没有 PostgreSQL——只有 Markdown 文件 + 文件系统目录结构。
为什么这样选
- 零运维:本地 CLI 工具,引入任何外部数据库都会抬高用户门槛。
- 人工可干预:用户可以随时打开 Markdown 文件查看、修改、清理,不需要任何管理界面。
- LLM 原生友好:整个文件直接注入 context,无需序列化/反序列化,无需 ORM。
- 天然版本化:文件可随项目一起 git 管理(或不 track,取决于隐私需求)。
- 隐私优先:数据 100% 在本地,不上传云端。
怎么做检索
没有向量语义检索,而是用轻量级替代方案:
- 目录结构天然划分记忆域(项目 vs 用户,共享 vs 私密)
- Markdown headers 做结构化索引,加载时扫描 headers 做相关性筛选
- 必要时让一个小模型过一遍 headers 判断哪些段落与当前请求相关
局限
- 不适合大规模语义检索(关键词匹配 ≠ 语义匹配)
- 记忆文件膨胀后,header 扫描 + 小模型筛选的准确率和速度会下降
- 跨设备同步依赖外部方案(iCloud/Dropbox 等)
详细见往期文章Claude code 源码精读 之记忆模块存储机制
启示
上述多级存储架构是服务端 AI 产品(多租户、海量记忆)的标准答案,而 Claude Code 的方案证明:对于本地单用户工具,Markdown 文件 + 目录结构 + grep/轻量模型召回的简单组合,远比堆砌 Redis + 向量库 + RDBMS 更合适。 架构选择应服务于产品场景,而非追求理论完备。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)