
让AI帮你养知识库LLM-Wiki与Obsidian和Claude的实践
文章目录
这是一篇关于"如何让 AI 真正接管知识库日常维护"的完整实践记录。它不是工具评测,而是回答一个问题:为什么我们记了十年笔记,知识却还是用不起来——以及怎么用一套具体可操作的方法,让 AI 真正成为你的"知识库管家"。 文中所有步骤均来自我的真实配置,所有截图均为实际操作界面。
一,先说一个扎心的事实:你的笔记,正在变成死海
做技术的人大概都有个共同的习惯:疯狂收藏。
看到一篇好文章,剪藏;读了一本书,记几条笔记;开会有个想法,随手写进备忘录。日积月累,笔记软件里躺了几千条内容。然后呢?
然后就没有然后了。
绝大多数笔记的命运是:写完的那一刻,就是它最后一次被打开的时刻。 你不会再去翻它,因为它没有结构,没有索引,没有关联。真到要用的时候,你宁可重新 Google,也不愿在自己的笔记海里捞针。
这不是你懒。是整理这件事的成本,高到没人能长期坚持。给笔记分类,打标签,建链接、合并重复、修正过时内容——这些"养护"工作单调、耗时、且没有即时反馈,人天生不擅长做这种没有即时奖励的事。
于是知识库退化成"知识坟场":只进不出,只存不用。
更讽刺的是,AI 时代来了之后,这件事变得更糟了。你把问题丢给 AI,它秒回,你满意地关掉窗口——但你这次得到的答案、产生的思考,又消失在对话流里了。 AI 没有把你的新知识沉淀下来,没有更新你的知识库,没有在已有的内容之间建立关联。它来一下、答一下、就走,什么也没留下。
问题出在哪?
二,诊断:三个被忽视的根本问题
我把上面这些现象拆开,发现根源是三个问题,而它们恰恰是传统知识管理工具从未真正解决的。
问题一:知识"只被存储,不被理解"。
网盘、文档中台解决的是"放到一个地方",检索还靠文件名和关键词。你搜不到一份名叫《2024运营管理办法》里的"漏洞修复时效",因为文件名里没这几个字。存储 ≠ 可检索。
问题二:整理成本无人承担。
谁来给笔记建交叉引用?谁来发现"这篇笔记和那篇笔记讲的是同一件事"?谁来标记"这条信息已经过时了"?传统工具把这个活全推给了人,而人做不动。
问题三:AI 是"临时工",不是"常住民"。
你每次问答,AI 都是从零开始,对你的知识库一无所知。它不记得你昨天问过什么,不知道你有哪些笔记,更不会主动帮你把这次问答沉淀成知识。
这三个问题指向同一个答案:我们需要一种让 AI 既"读得懂"、又"住得下"、还能"持续整理"的知识库模式。 这就是 LLM Wiki。
三,核心转变:从"用 AI 查"到"让 AI 养"
先说清楚一个根本性的认知转变。
到目前为止,大多数人对 AI + 知识库的理解是 RAG(检索增强生成):建个向量库,问问题时 AI 去检索相关片段,基于片段回答。这解决了"幻觉"和"查不到",但它本质上是单向的、只读的——AI 永远只是个查询者。
LLM Wiki 反过来:把 AI 当成知识库的"常住管理员"。
它的核心思想:不只让 AI 在查询时检索,而是让 AI 增量地、持续地构建和维护整个 wiki。 每次有新内容进来,AI 负责提取要点、更新相关页面,建立双向链接、标记矛盾——把那些单调的"养护"工作接管过来。
这个转变用一句话概括:
从"AI 来回答你的问题",变成"AI 帮你打理你的知识"。
四,架构与工具:从零搭建的完整方案
下面进入实操部分,手把手教你怎么搭这套系统。
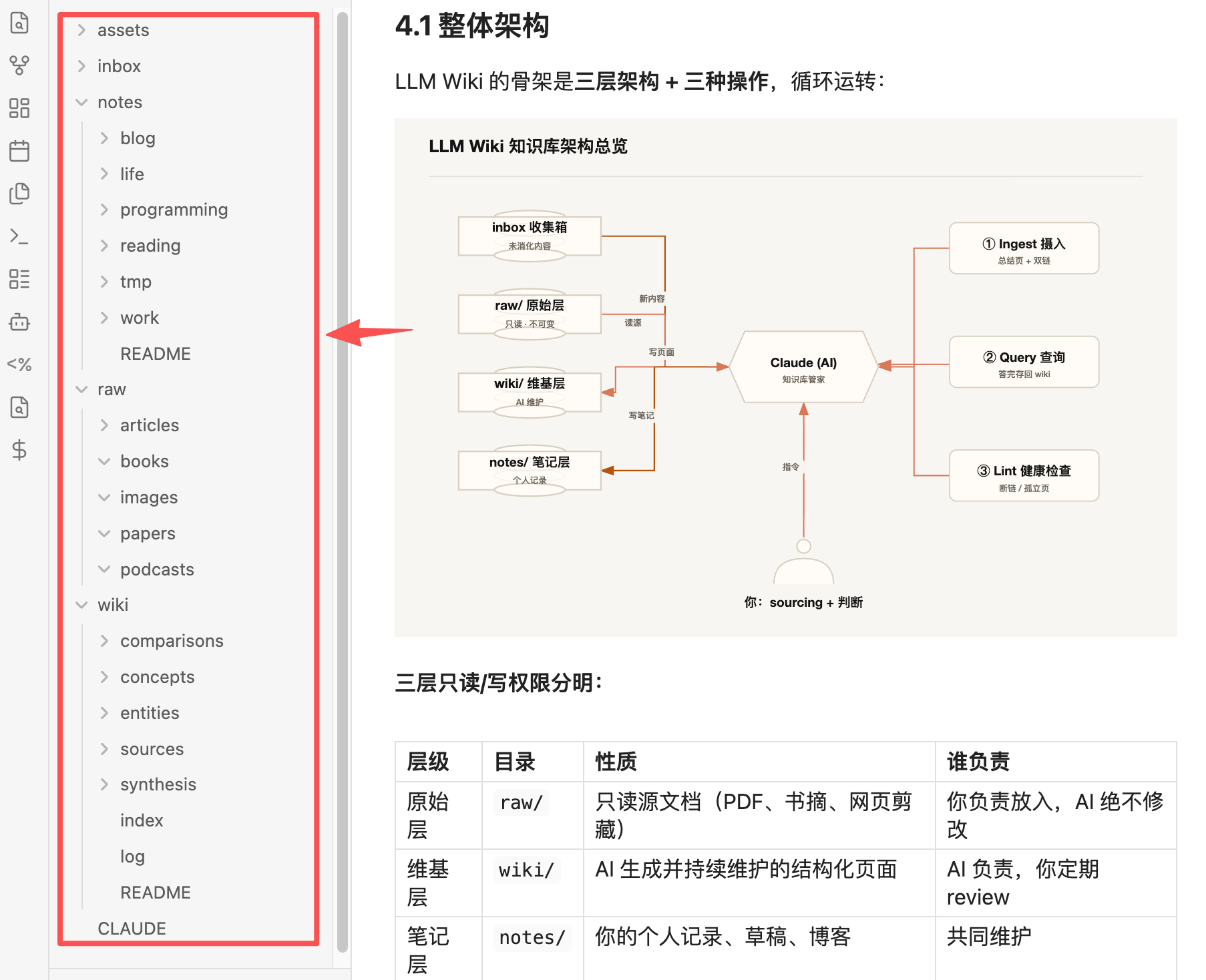
4.1 整体架构
LLM Wiki 的骨架是三层架构 + 三种操作,循环运转:

三层只读/写权限分明:
| 层级 | 目录 | 性质 | 谁负责 |
|---|---|---|---|
| 原始层 | raw/ |
只读源文档(PDF、书摘、网页剪藏) | 你负责放入,AI 绝不修改 |
| 维基层 | wiki/ |
AI 生成并持续维护的结构化页面 | AI 负责,你定期 review |
| 笔记层 | notes/ |
你的个人记录、草稿、博客 | 共同维护 |
三种操作驱动循环:
- Ingest(摄入):放入新来源 → AI 生成总结页 → 更新相关页面 → 建立双向链接 → 记入日志
- Query(查询):你提问 → AI 综合 wiki 回答 → 好答案存回 wiki 成为新页面
- Lint(健康检查):AI 扫描全库 → 报告断链/孤立页/过时内容 → 逐条修复
4.2 工具栈:Obsidian + Claudian + Claude Code
为什么是这套组合:

- Obsidian:知识库的载体。本地 Markdown + 双链 + YAML frontmatter,AI 能直接读写,不依赖任何封闭 API。Obsidian 就是"家",AI 得住进来才能养。
- Claudian:Obsidian 的社区插件,把 Claude 直接接进了 Obsidian。AI 能读当前笔记上下文、读 vault 任意位置、直接修改文件——Claudian 是"门",把 AI 请进 Obsidian。
- Claude Code:命令行 AI Agent,能执行长链路任务(读文件、跑脚本、改多个文件)。LLM Wiki 的养护工作(扫描全库、建批量链接、跑 lint)需要这种能动手改文件的 Agent,而不只是聊天。** Claude Code 是 AI 干活的手。**
- CLAUDE.md:规范文件(放在 vault 根目录),给 AI 看家的"职责说明书"。规定目录结构、页面模板、日志格式、行为规则。好管家需要好规矩。
📷 Obsidian 界面截图,展示
inbox/、raw/、wiki/、notes/四个目录的实际文件组织,以及 Claudian 插件在 Obsidian 侧边栏的配置状态。
4.3 搭建步骤(完整从零到能跑)
第一步:安装 Obsidian(免费,跨平台)
去 obsidian.md 下载安装。打开后新建 vault(相当于一个仓库),命名为 my-knowledge-base。
第二步:安装 Claudian 插件
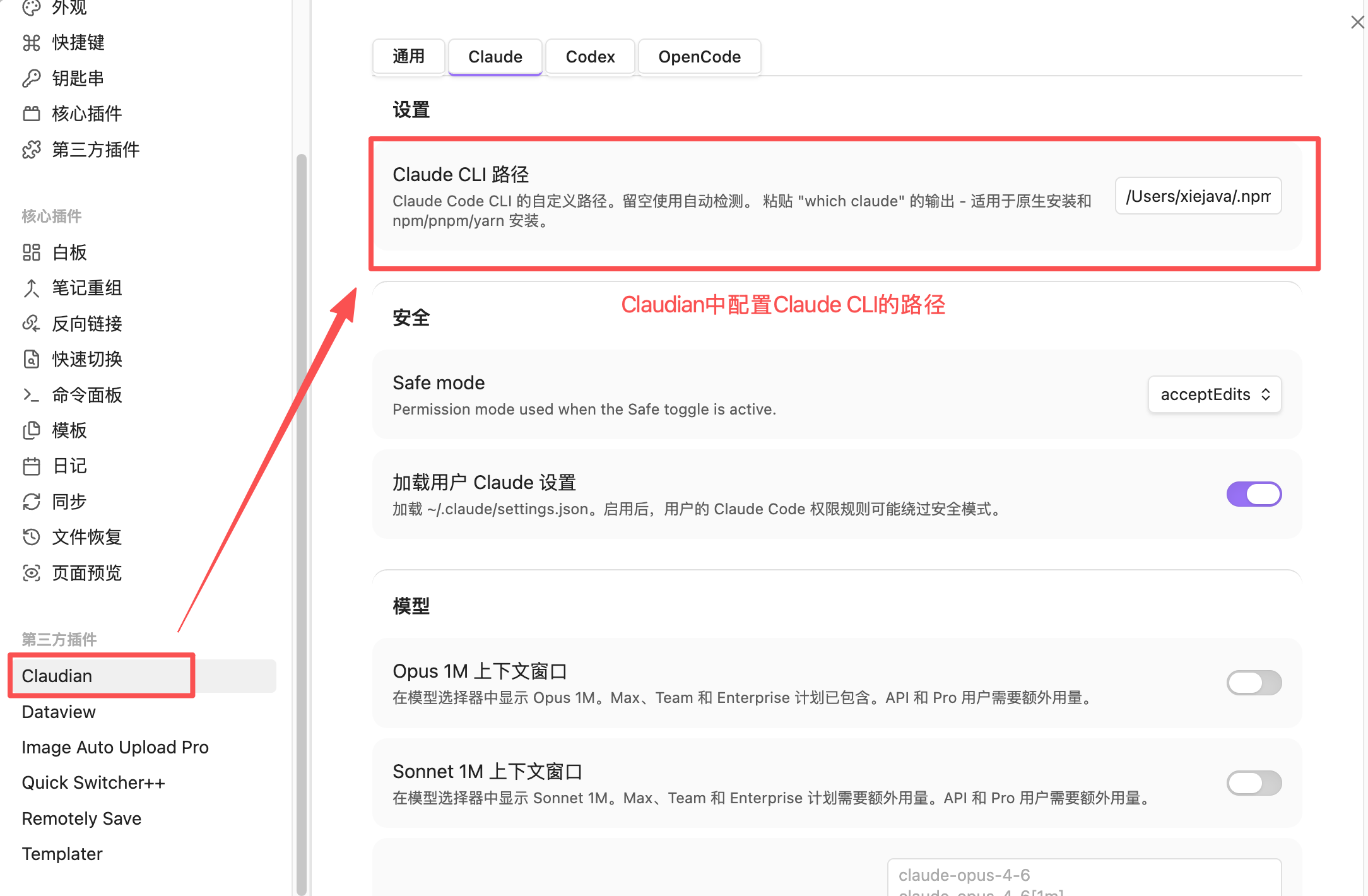
Settings → Community Plugins → 搜索 "Claudian" → 安装 → 启用。
安装后在Claudian中配置Claude CLI的路径 ,相当于为Obsidian配置一个AI大脑。
Claudian 插件安装完成后在Claudian中配置Claude CLI的路径。
第三步:建立目录结构
在 vault 根目录按以下结构创建文件夹:
my-knowledge-base/
├── inbox/ # 收集箱:新内容先放这里
├── raw/ # 原始来源(只读)
│ ├── articles/ # 网页剪藏
│ ├── books/ # 书籍笔记
│ ├── papers/ # 论文
│ └── podcasts/ # 播客笔记
├── wiki/ # 维基站(AI 维护)
│ ├── concepts/ # 概念页
│ ├── entities/ # 实体页
│ ├── sources/ # 来源总结
│ ├── synthesis/ # 综合分析
│ ├── comparisons/ # 对比表
│ ├── index.md # 内容索引
│ └── log.md # 操作日志
└── notes/ # 个人笔记
├── blog/ # 博客文章
├── programming/ # 技术笔记
├── reading/ # 读书笔记
└── work/ # 工作笔记
第四步:写 CLAUDE.md(核心规范文件)
在 vault 根目录新建 CLAUDE.md,内容如下(可直接复制,按需修改):
# LLM Wiki Schema - 我的知识库维护规范
## 角色定位
- **你(用户)**:sourcing(筛选来源)、exploration(探索)、asking right questions(提问)
- **我(AI Agent)**:所有的 grunt work — 总结、关联归档、维护 bookkeeping
## 目录结构
(见上方表格,复制过来即可)
## 三种操作
### Ingest(新来源摄入)
当你提交新来源时:
1. 读取来源内容
2. 与你讨论关键要点
3. 在 wiki/sources/ 创建总结页
4. 更新相关 concept/entity 页(新建或补充)
5. 在 wiki/index.md 添加条目
6. 在 wiki/log.md 追加记录,格式:`## [YYYY-MM-DD] ingest | 标题`
### Query(查询)
当你问我问题时:
1. 先读 wiki/index.md 定位相关页面
2. 读相关 wiki 页面
3. 综合给出答案,标注来源
4. **如果答案有价值,存回 wiki 成为新页面**(对比表、分析、发现的新关联)
### Lint(健康检查)
定期检查:
- 页间矛盾
- 过时信息被新来源 supersede
- 孤立页面(无 inbound links)
- 重要概念未被独立建页
- 缺失交叉引用
格式:`## [YYYY-MM-DD] lint | 检查结果摘要`
## 工具
- search_files: 内容搜索
- read_file: 读取页面
- patch: 编辑页面
## 冲突处理
- 如发现冲突,询问用户保留哪版
第五步:在 Claude Code 里配置 vault 路径
如果你用 Claude Code 跑 lint 等跨文件操作,需要让它知道 vault 在哪。最简单的方式:直接 cd 到 vault 目录(也就是知识库所在的目录)启动 Claude Code,它会自动以该目录为工作根。
第六步:跑通第一次 Ingest(完整流程示例)
假设你想把一篇刚读的文章纳入 wiki。完整流程如下:
你:把这篇文章 ingest 一下
AI(Claude Claudian)执行:
1. 读取文章内容
2. 生成 wiki/sources/<文章名>.md(来源总结页)
3. 判断文章涉及哪些已有概念,在对应 concept 页补充关联链接
4. 在 wiki/index.md 来源表新增一行
5. 在 wiki/log.md 写入:
## [2026-06-19] ingest | <文章标题>
6. 告知你完成,列出做了什么
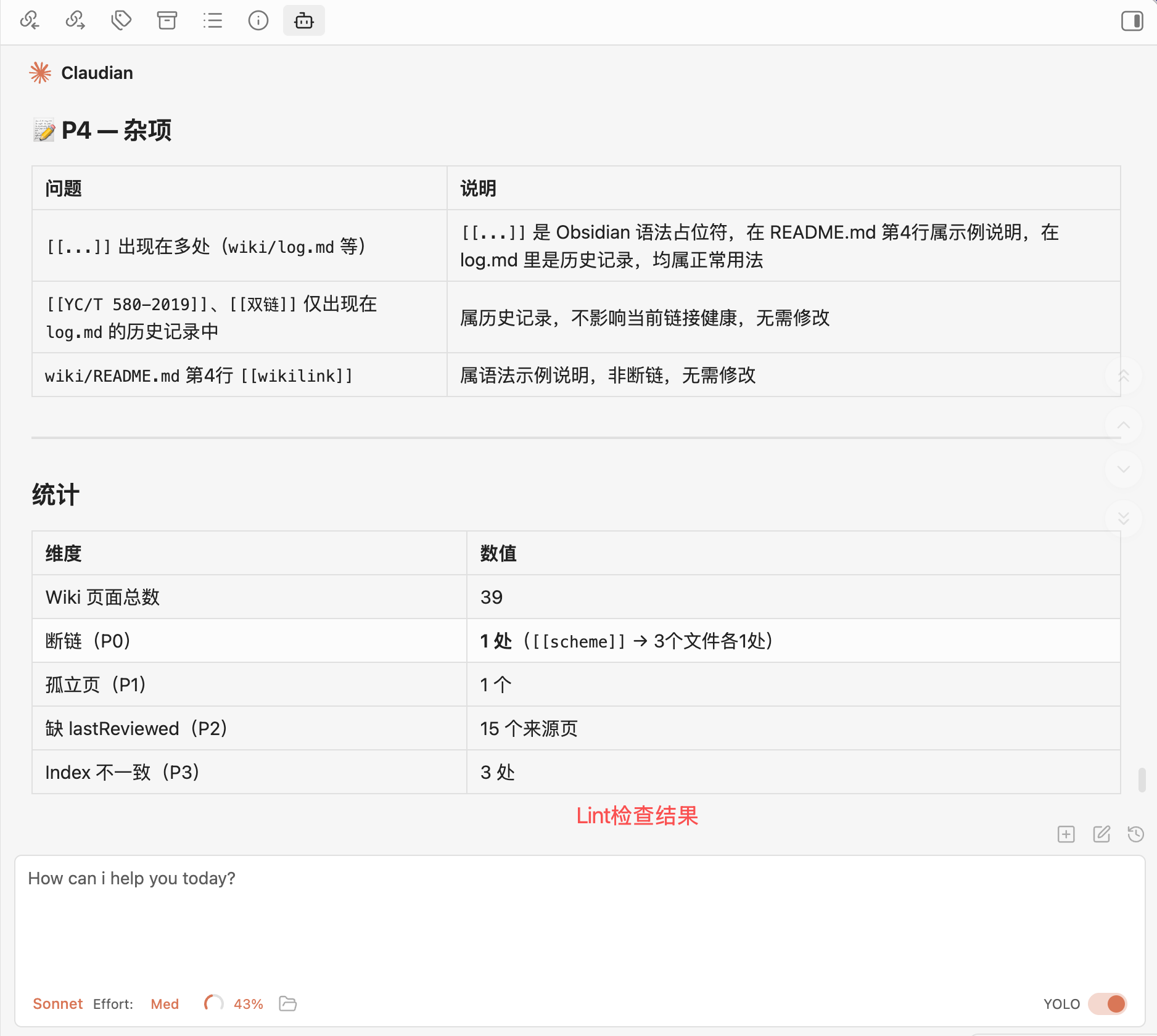
你:lint 一下
AI 执行全库扫描,输出:
- 🔴 断链:X 处(具体列出哪些链接指向不存在页面)
- 🟡 孤立页:X 个(具体列出哪些页面没有被任何页面链接)
- 📋 未索引文件:X 个
- 🟡 缺 lastReviewed:X 个页面
你:修一下
AI 逐条修复(或问你要不要批量确认后再改)
📷 Obsidian 调用Claude 跑 lint 后的输出截图,展示"发现 1 处断链、1个孤立页"的分级报告。
五,三个真实养护场景(从我的 vault 来的)
光讲方法论是空的,下面是这套系统在我自己的知识库里真实发生的三个场景。
场景一:Ingest——摄入一个新来源的全过程
我研究了腾讯开源的 WeKnora 知识框架,想把它纳入知识库。我对 AI 说"把这份研究 ingest"。AI 自动完成了:
- 生成来源总结页
wiki/sources/weknora.md——提炼一句话评价、核心内容、对知识库的贡献; - 创建实体页
wiki/entities/weknora.md——记录定位、关键特征、局限; - 更新索引
wiki/index.md——在实体表和来源表各加一行; - 追加日志
wiki/log.md——## [2026-06-18] ingest | WeKnora 腾讯开源 LLM 知识框架; - 建立双向链接——在已有的"AI-miniSOC Agent 底座对比"和"安全运营体系"页面里,各加一条指向 weknora 的关联链接,并写明它在这套架构里扮演什么角色。
整个过程我只说了一句话。AI 做完了原本需要我花一小时手动整理的事。
场景二:Lint——AI 主动发现知识库的"病灶"
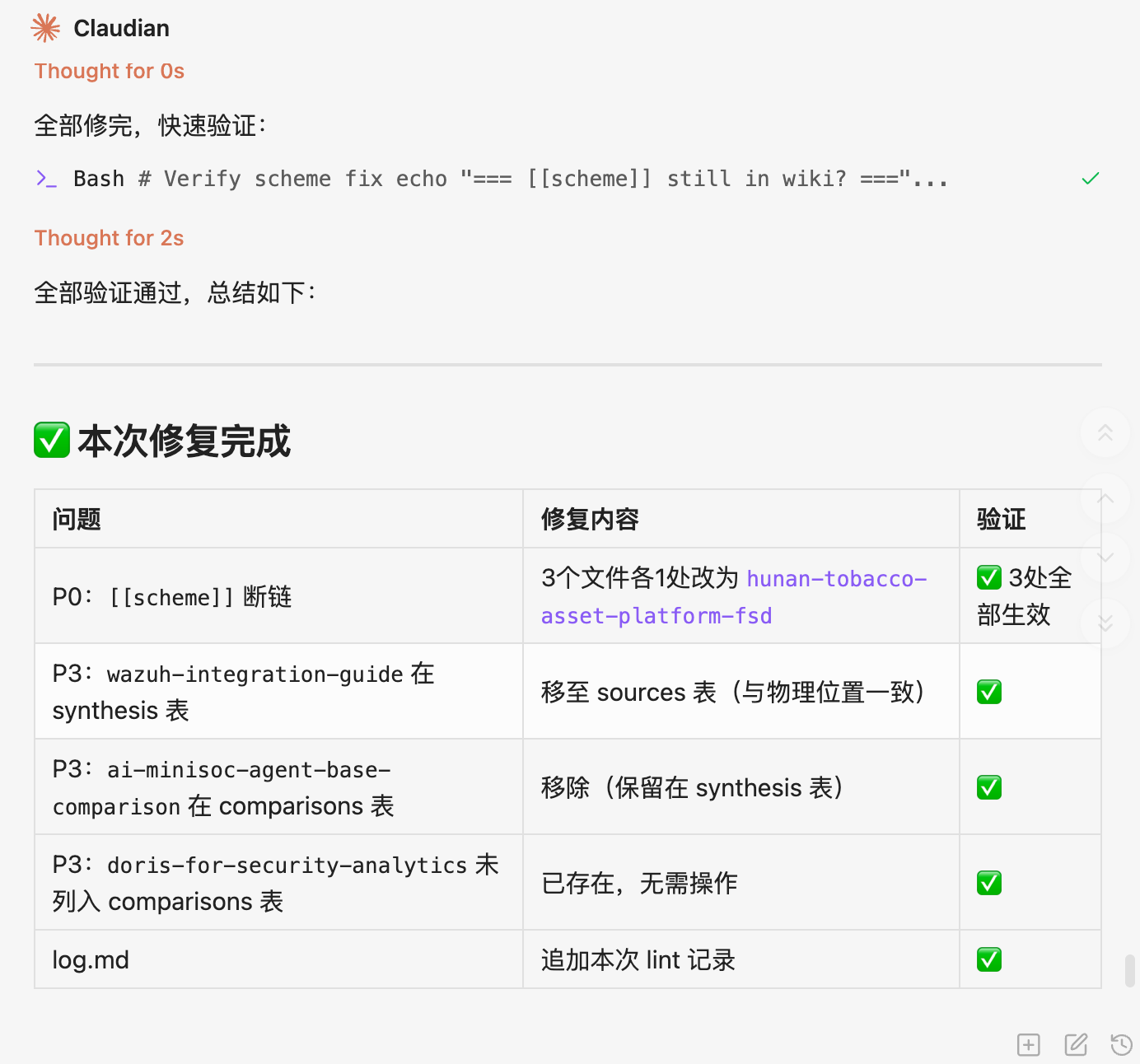
更让我惊喜的是 lint。我让 AI 给知识库做一次健康检查,它扫完全部 wiki 页面后,输出了这份分级报告:
- 🔴 P0 断链:有几处
[[soc]]、[[双链]]链接指向了不存在的页面——要么是写错了,要么是该建页没建; - 🟡 P1 孤立页:8 个页面没有任何别的页面链接到它,成了知识孤岛;
- 🟡 元数据缺失:3 个页面完全没有 frontmatter,19 个页面缺"上次复核日期"字段;
- 📋 未索引文件:磁盘上存在、但没被纳入 index.md 的页面。
这份报告最有价值的地方在于:这些问题我自己永远发现不了。 我每天用这个 vault,却看不见它的腐化。AI 用一次全量扫描,把那些"慢慢烂掉"的地方全部照出来了。
更妙的是,它不只是抛问题,还给了优先级和修复建议——我让它逐条修,断链补建、孤立页加链接、缺字段补全。他不但全部修复还进行验证,保证了知识库的健康。
这就是"养护"最朴素的样子:让一个不会累、不偷懒的 AI,定期替你巡检整个知识库。
场景三:Query 的闭环——好答案存回 wiki
传统 AI 问答是单向消费。LLM Wiki 的 query 多了一步:如果这次问答产生了有价值的综合(比如一张对比表、一个新发现的关系),AI 会把它写成新页面存回 wiki。
比如我之前问 AI"WeKnora 和 RAGFlow 怎么选",AI 综合了一轮分析后,主动在 wiki 里创建了一张对比表,并写进 index.md。下次再有人问类似问题,直接命中沉淀好的结论,不用重新推理。
这意味着知识库会越用越厚、越用越聪明——因为它在"学习"每一次高质量问答。
六,效果与反思:什么变了,什么没变
用了这套模式一段时间后,我最直接的感受是:知识库从"一个我偶尔翻翻的仓库",变成了"一个会自己生长的活物"。
具体的变化:
- 新知识进来的成本趋近于零。我说一句话,AI 完成摄入全套动作。
- 旧知识不再腐烂。lint 定期巡检,断链和孤立页无所遁形。
- 知识之间长出了网。交叉链接让任意一个知识点都能顺藤摸瓜找到相关的全部页面。
- AI 问答有了记忆和根据地。它基于我的 wiki 回答,不再凭空生成;好答案又反哺 wiki。
但我也必须诚实地说——有些事 AI 仍然替代不了人:
- "什么值得纳入"是人的判断。AI 不会主动去发现世界上有什么值得学,sourcing(找来源、提对的问题)永远是你的核心价值。LLM Wiki 明确把角色定位为"你负责 sourcing,AI 负责 bookkeeping"。
- 价值判断和取舍。AI 能总结,但"这条结论对我重要吗"“这个观点我认同吗”,得你来定。
- 最终的质量把关。AI 会犯错,会过度链接。信任但不放任,每次它改完,扫一眼。
一句话:AI 接管了知识库的"体力活",但"脑力活"——判断什么重要、什么是对的——还是你的。
七,给你的落地建议
如果你也想让自己的笔记不再变死海,三条建议:
第一,先选一个 AI 能直接读写文件的载体。 Obsidian(本地 Markdown)是最稳的选择——开放,双链,AI 友好。别选封闭的、只能通过私有 API 访问的工具,AI 进不去,一切白搭。
第二,给 AI 一套明确的"养护规矩"。 写一份 CLAUDE.md:规定目录结构(raw/wiki/notes)、页面模板(frontmatter 规范)、三种操作(ingest/query/lint)的流程、日志格式。AI 是好管家,但好管家也需要职责说明书。
第三,从最小闭环开始,别贪大。 不要一上来就想自动化一切。先让 AI 帮你做一件事——比如每次读完一篇文章,让它生成一个来源总结页。跑顺了,再加 lint,加交叉链接,加 query 存回。让知识库"活起来"靠的不是一次性大工程,而是持续的小循环。
八,结语
回到开头那个问题:为什么我们记了十年笔记,知识却还是用不起来?
答案不是我们不够自律,而是我们一直把"养护知识库"这件本该由机器做的事,扛在了自己肩上。
LLM Wiki + Obsidian + Claude 的组合,本质上是一次分工的重新划分:把单调的、可持续的、规则化的养护工作交给 AI,把真正需要人的思考(sourcing、判断、创造)留给人。
有你的知识库开始自己生长、自己纠错、自己把新知识和旧知识织成一张网的时候,你会发现——"第二大脑"这个喊了多年的概念,第一次有了落地的手感。
你的笔记,终于不必再变成死海了。
相关阅读

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)