
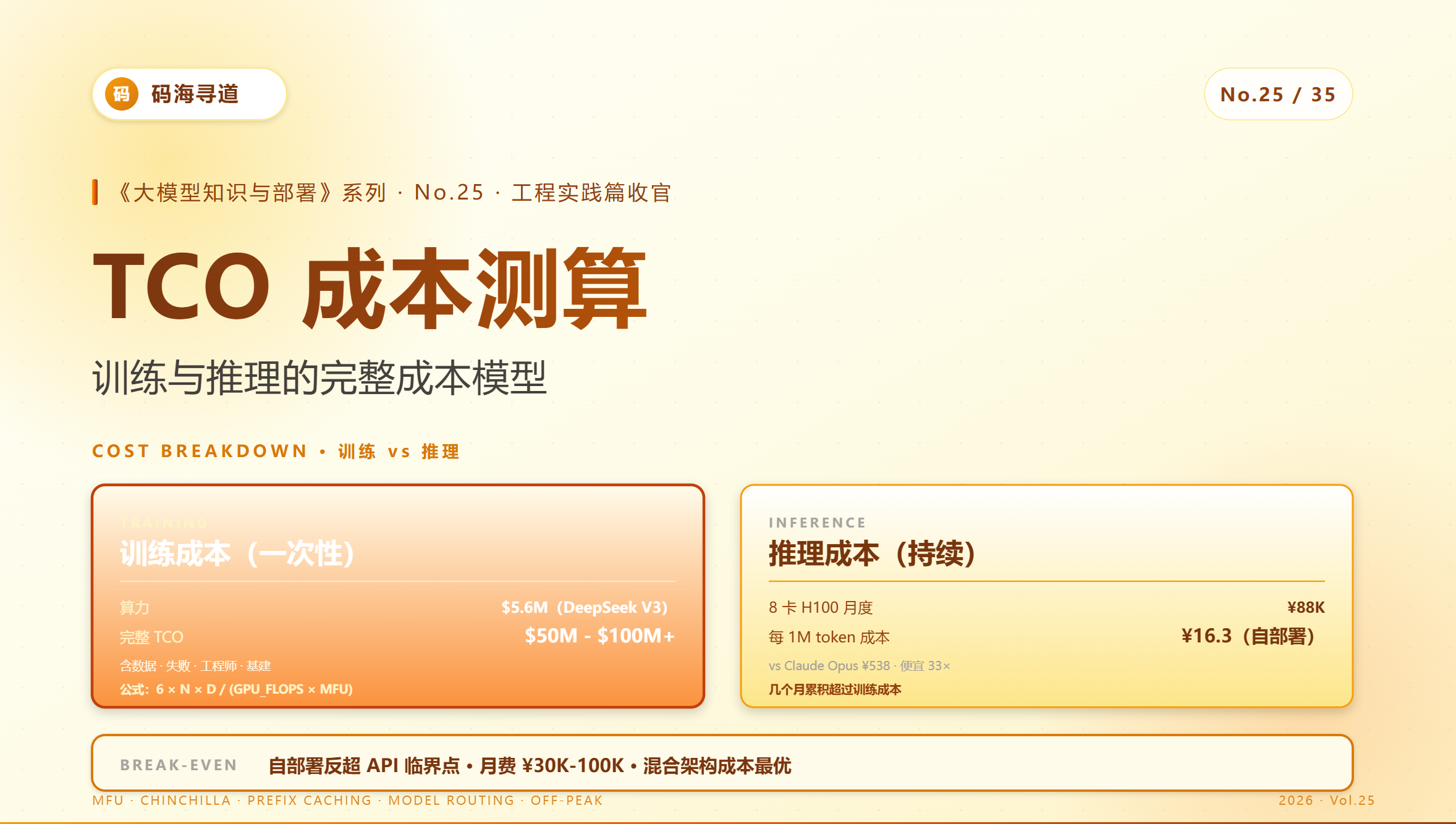
25.TCO 成本测算:训练与推理的完整成本模型
TCO 成本测算:训练与推理的完整成本模型
《大模型知识与部署》系列 · No.25 / 35(工程实践篇收官)
适合人群:AI 工程师、技术决策者、CFO
阅读时间:约 25 分钟
写在前面
前面 24 篇我们走完了"技术"——从架构、训练、推理优化、部署到工程实践。这一篇要把所有技术决策翻译成同一个语言:
钱。
为什么这个话题这么重要?
✓ CFO 看的是 TCO,不是 FLOPS
✓ 老板批不批预算看 ROI
✓ 选自部署还是 API 看月度账单临界点
✓ 团队规划看 18 个月预算
✓ 投资人估值看单位成本下降曲线
读完本文你将能:
- 算清训练一个 70B 模型要多少钱
- 算清推理 1M token 的真实成本
- 决策自部署 vs API(什么时候反超)
- 优化任何业务的 TCO 30-50%
我们开始。
一、TCO 的定义与误区
1.1 什么是 TCO
TCO(Total Cost of Ownership,总拥有成本) = 一项资产从获得到淘汰整个生命周期的所有成本之和。
对大模型来说:
TCO = 硬件采购 + 折旧 + 电力 + 网络 + 运维 + 软件 + 人力 + 机会成本
很多团队只算前两项,严重低估真实 TCO——这就是为什么"看起来便宜"的方案上线后处处花钱。
1.2 大模型 TCO 三大误区
误区 1:只算 GPU 单价
错误:8 张 H100 × 25 万 = 200 万
真实:服务器整机 350 万,电费 + 机房 100 万/年,运维 80 万/年
实际 TCO 是单价的 3-5 倍。
误区 2:忽视利用率
A 方案:买 16 卡,利用率 50% → 等效 8 卡
B 方案:买 8 卡,利用率 90% → 等效 7.2 卡
B 方案 TCO 远低于 A,但效果差不多。
误区 3:忽视时间成本
方案 A:自建训练集群,6 个月跑出模型
方案 B:用云租赁,2 个月跑出模型
B 多花 50% 硬件费,但提前 4 个月上线 → 业务收益 >> 硬件多花的钱
时间也是钱——尤其在大模型快速演进的当下。
二、训练 TCO:从一个真实案例开始
2.1 DeepSeek V3 训练成本拆解
DeepSeek V3 公开的 557 万美元 是怎么算的?
训练规模:14.8T tokens
模型规模:671B 总参数 / 37B 激活
GPU 资源:2.79M H800·小时
成本明细:
H800 租赁单价:$2/小时
总成本:2.79M × $2 = $5.58M ✓
但这是"狭义训练成本"。完整 TCO 还包括:
| 项目 | 金额(估算) |
|---|---|
| 算力(GPU·小时) | $5.58M |
| 数据采集与清洗 | $1-2M |
| 实验与失败成本 | $2-5M(多次失败重训) |
| 工程师团队(200 人 × 18 月) | $30-50M |
| 基础设施(机房、网络) | $5M |
| 完整 TCO | $50-100M+ |
核心认知:
媒体报道的"几百万美元训练成本"是冰山一角。
2.2 训练成本公式
对工程师来说,简化估算公式:
训练成本 ≈ 6 × N × D / GPU_FLOPS × 利用率 × 时薪
N:模型参数量
D:训练数据 tokens
GPU_FLOPS:硬件 FP16 算力
利用率:实际 MFU(Model FLOPS Utilization)通常 40-50%
时薪:GPU 小时单价
实操:训练 70B 模型多少钱
设定:
- N = 70B
- D = 14T tokens(Chinchilla 200×)
- H100 SXM:989 TFLOPS
- MFU = 45%
- 自购成本 ¥1/小时(按 3 年折旧 + 电费)
总 FLOPS = 6 × 70 × 10⁹ × 14 × 10¹² = 5.88 × 10²⁴ = 5.88 ZFLOPS
有效算力 = 989 × 10¹² × 0.45 = 445 × 10¹² FLOPS/秒
需要 GPU·秒 = 5.88 × 10²⁴ / 445 × 10¹² = 1.32 × 10¹⁰ 秒
转换 GPU·小时 = 3.67M GPU·小时
成本(自购)= 3.67M × ¥1/小时 = ¥3.67M
成本(云租)= 3.67M × ¥14/小时 = ¥51M
真实参考:
- Llama 3-70B 官方 ≈ 6.4M H100·小时(数据多了一倍,所以略高)
- DeepSeek V3 671B / 37B 激活 ≈ 2.79M(因为只算激活参数)
2.3 训练 TCO 优化策略
策略 1:用 MoE 降算力
DeepSeek V3 671B 总参数 / 37B 激活——训练算力按 37B 算,节省 90%。
策略 2:用 FP8 训练
DeepSeek V3 用 FP8 训练,比 BF16 节省 30-50% 算力。
策略 3:合成数据 + 精炼
Phi 系列用 GPT-4 合成"教科书"数据,3.8B 干掉 70B——用算法智慧替代算力。
策略 4:Continued Pretraining 而非 from scratch
不要"从零训",在开源底座上继续训:
从零训 70B:~¥3.7M
Continued pretrain 70B(5% tokens):~¥185K
成本降 20×。
三、推理 TCO:业务的"持续支出"
3.1 推理成本拆解
推理 TCO = 硬件折旧 + 电力 + 网络 + 运维 + 软件 + 人力
以 8 卡 H100 服务器(自购)3 年 TCO 为例:
| 项 | 金额 | 月均 |
|---|---|---|
| 服务器采购 | ¥2.5M | ¥69K(3 年折旧) |
| 电费 | 5.6 kW × 24 × 30 × ¥1.0 | ¥4K |
| 机房(机架、网络) | ¥3K/月 | ¥3K |
| 运维 SRE 摊销 | ¥10K | |
| 软件 / License | ¥2K | |
| 月度 TCO | ~¥88K |
3 年 TCO 总计:~¥3.16M。
3.2 每 1M token 真实成本
假设这台服务器跑 Llama-3-70B(FP8):
- 单卡吞吐:~400 tokens/s(含 prefill + decode 混合)
- 8 卡集群吞吐:~3000 tokens/s(考虑通信开销)
- 月可处理 tokens = 3000 × 86400 × 30 × 0.7(利用率)= 5.4 × 10⁹
每 1M token 成本 = ¥88K / 5400 = ¥16.3
对照主流 API(2026 中):
| 服务 | 输出价格(每 1M token) |
|---|---|
| Claude Opus 4.7 | ¥538($75 → 含税 ¥538) |
| GPT-5 | ¥287($40) |
| Claude Sonnet 4.6 | ¥108($15) |
| Gemini 2.5 Pro | ¥72($10) |
| Qwen3 API | ¥8(¥1.1 输入 + 输出加价) |
| 自部署 Llama-3-70B | ¥16.3 |
| DeepSeek-V3 API | ¥8(¥0.27 输入 + ¥1.1 输出) |
关键洞察:
- 自部署比 Claude / GPT 便宜 10-30×
- 但比 DeepSeek / Qwen 国产 API 贵 2×
这是当下 2026 年最重要的成本认知。
3.3 推理 TCO 优化策略
策略 1:量化压缩
- FP16 → INT8:吞吐 +50%、显存减半
- FP16 → INT4:吞吐 +120%、显存减 75%
直接效果:单 token 成本降 50-70%。
策略 2:高 batch 利用率
单序列:单卡 ~50 tokens/s
batch=64:单卡 ~2000 tokens/s
单 token 成本降 40×——这就是为什么 Continuous Batching 这么重要。
策略 3:模型分级
- 简单查询 → 7B 模型(成本 1/10)
- 复杂任务 → 70B 模型
- 极难任务 → Claude / GPT API
混合后整体成本下降 60-80%。
策略 4:Prefix Caching
对 RAG / Multi-turn 场景,重复 prefix 不算钱:
- OpenAI 的 prompt caching:50% 折扣
- Anthropic 的 prompt caching:90% 折扣
- 自部署:免费且彻底
策略 5:Off-peak 调度
非高峰跑批量任务(如离线总结),错峰利用闲置 GPU:
高峰:50% 容量在线服务
低峰:剩余 50% 跑离线任务
利用率从 50% → 90%
四、自部署 vs API:临界点分析
4.1 决策模型
月度 API 账单 = 调用量 × 单价
月度自部署 TCO = 固定(GPU 折旧 + 运维)
临界点:月 API 账单 = 月 TCO
调用量 = TCO / API 单价
4.2 实操案例
场景:要做一个客服助手,需要 Claude Sonnet 级别能力。
方案 A:用 Claude Sonnet API
- 单价:¥108 / 1M output token
- 假设月均生成 1B token
- 月费:¥108K
方案 B:自部署 Llama-3-70B FP8(同级能力)
- 8 卡 H100 服务器,月度 TCO:¥88K
- 容量:5.4B token/月
结论:
- 月调用 < 800M token:API 划算
- 月调用 800M-5B token:自部署划算
- 月调用 > 5B token:自部署 + 扩容
不同 API 的临界点
| 服务 | 反超月 token |
|---|---|
| Claude Opus | ~160M |
| GPT-5 | ~300M |
| Claude Sonnet | ~800M |
| Gemini Flash | 永远不反超(太便宜了) |
| DeepSeek V3 API | 永远不反超(更便宜) |
4.3 决策矩阵
| 业务规模 | 数据合规要求 | 推荐 |
|---|---|---|
| 月费 < ¥30K | 无 | 用 Claude / GPT API |
| 月费 < ¥30K | 严格 | 用国产 API |
| 月费 ¥30K-¥100K | 无 | 用 DeepSeek / Qwen API(最划算) |
| 月费 ¥30K-¥100K | 严格 | 单 H100 自部署 |
| 月费 > ¥100K | 无 | 混合:闭源 API + 自部署 |
| 月费 > ¥100K | 严格 | 全自部署 + 国产卡(合规) |
4.4 不要忽视隐藏成本
自部署除了 TCO 还有:
- 运维责任:服务挂了你修,不是云厂商
- 升级成本:模型版本迭代你要跟
- 冷启动慢:从订机柜到上线 1-3 个月
- 机会成本:现金占用大笔预算
API 模式则有:
- 不可控延迟:API 厂商抽风没办法
- 数据出域:合规风险
- 政策变化:定价可能上涨
4.5 实战:混合策略最实用
业界做得好的团队都用分层混合:
↑ 高复杂 / 重要请求 → Claude Opus / GPT-5(贵但好)
│ 中等任务 → 自部署 Llama-3-70B
│ 大量普通任务 → 自部署 Qwen3-32B
↓ 简单分类 → Qwen3-1.7B(端侧)
成本:高复杂 5% × 贵 + 中等 30% × 中 + 普通 65% × 廉
实测能把总成本压到纯 API 方案的 20-30%。
五、训练 + 推理生命周期 TCO
5.1 一个完整的大模型业务 18 个月成本
设定:
- 团队 30 人 AI 工程师
- 自研垂直模型(基于 Llama-3-70B + 持续微调)
- 业务量:3 亿 MAU / 日均 2 亿次调用
| 阶段 | 时间 | 成本 |
|---|---|---|
| 筹备(招人、买设备) | 1-3 月 | ¥10M(设备 ¥7M + 人力 ¥3M) |
| 数据准备 + 训练(含 5 次失败) | 4-9 月 | ¥8M(GPU 租赁 ¥3M + 人力 ¥5M) |
| 微调与对齐 | 10-12 月 | ¥3M |
| 推理上线 | 12 月+ | ¥3M/月(4 套 8 卡 H100 + 运维) |
| 持续迭代 | 13-18 月 | ¥18M(持续微调 + 推理扩容) |
| 完整 18 月 TCO | ~¥42M |
5.2 ROI 视角
月收入(来自 AI 业务):¥3M
月运营成本(推理 + 团队):¥4M
回本周期:约 24 个月(需要持续优化)
这就是为什么大模型业务前 1-2 年都很难赚钱——基础设施投入太重。
5.3 成本下降曲线(行业趋势)
2023-2026 推理成本下降速度:
2023:GPT-3.5 ¥21 / 1M output token
2024:GPT-4o ¥36 / 1M output token (能力升级)
2025:DeepSeek V3 ¥8 / 1M output token
2026:Qwen3 / DeepSeek 维持 ¥8 / 1M
单位智能价格每年下降 50%+。规划时一定要考虑这条曲线。
六、成本优化 Playbook
6.1 训练阶段
| 优化 | 收益 |
|---|---|
| 用开源底座 + Continued Pretraining | 节省 95% |
| 用 MoE 而不是 Dense | 节省 60-80% |
| FP8 训练 | 节省 30-50% |
| 数据精炼(Phi 路线) | 节省 50-90% |
| 用国产卡训练 | 节省 30-40% |
| 训练后蒸馏 → 小模型推理 | 推理成本节省 80% |
6.2 推理阶段
| 优化 | 收益 |
|---|---|
| FP8 / INT4 量化 | 节省 40-70% |
| 高 batch(Continuous Batching) | 节省 60-90% |
| Prefix Caching | 节省 30-50%(RAG 场景) |
| 分级模型路由 | 节省 60-80% |
| 投机解码 | 节省 30-50%(单序列场景) |
| Off-peak 调度 | 节省 30-50% |
| 国产 API 替代 | 节省 80-90%(vs Claude/GPT) |
6.3 整体架构
↑ 闭源 API(关键 / 复杂场景,5-10% 流量)
│
│ 自部署大模型(重要场景,20-30% 流量)
│
│ 自部署中模型(主力,40-50% 流量)
│
↓ 自部署小模型(简单任务,20-30% 流量)
这是 2026 年最实用的成本架构。
6.4 监控与归因
工业团队需要成本看板:
按业务线:哪个业务花得最多?
按模型:哪个模型用得最多?
按时间:高峰 vs 低峰
按用户:哪个 API key 最贵
LiteLLM Admin UI(第 19 篇讲过)直接支持。也可以自研接 BI 看板。
七、扩展 + 系列预告
7.1 长期成本的判断
未来 2-3 年的成本变化预判:
- 训练成本:年降 30-50%(架构 + 硬件)
- 推理成本:年降 50-70%(量化 + 优化 + 硬件)
- GPU 价格:H100 → B200 → B300 → … 性能 / 价比每代提升 2-3×
- 小模型崛起:3-7B 模型能力快速接近 70B → 推理成本骤降
对工程团队的启示:
- 不要现在就锁死多年硬件 —— 灵活租赁 + 渐进自购
- 始终关注国产 + 开源进展 —— 替换闭源的窗口期来得快
- 长期投资在数据 + 工程化 —— 这两个不会被硬件迭代抹除
7.2 系列预告
工程实践篇(第 21-25 篇)正式收官!
回顾这 5 篇:
| 篇号 | 主题 |
|---|---|
| 21 | GPU 选型指南 |
| 22 | 集群运维 |
| 23 | 模型权重管理 |
| 24 | 显存优化实战 |
| 25 | TCO 成本测算 |
至此,前 25 篇覆盖了从认知 → 训练 → 推理 → 部署 → 工程实践的完整链路——你已经具备做一家大模型公司的全部技术能力。
接下来进入应用生态篇(第 26-30 篇)——把模型变成产品:
- 第 26 篇:RAG 实战 - 从向量数据库到 GraphRAG
- 第 27 篇:Function Calling / Tool Use
- 第 28 篇:Agent 框架对比
- 第 29 篇:多模态部署
- 第 30 篇:Prompt 工程方法论
之后是前沿与思考篇(第 31-35 篇)——MoE / 推理模型 / 端侧 / 开源 vs 闭源 / 安全。
我们下篇见。
结语:技术决策最终都是钱的决策
读完本文你应该明白:
- TCO 不只是 GPU 单价——人力、机房、运维、机会成本都要算
- 训练成本远高于"算力"那一项——失败、迭代、数据是大头
- 推理成本随业务量持续累积——很快超过训练
- 自部署反超 API 的临界点:月费 ¥30K-100K
- 混合架构成本最优:闭源 API + 自部署多档模型
- 单位 token 价格年降 50%+——规划要预留下降空间
工程实践篇(第 21-25 篇)正式收官。前 25 篇完成 71.4% 的系列!
下一篇我们继续:
- 第 26 篇:RAG 实战 - 从向量数据库到 GraphRAG —— 把模型变成"懂业务知识"的应用,RAG 是最重要的方法之一。
我们下篇见。
📮 关于「码海寻道」
这里是一个聚焦 AI 工程化、大模型部署、后端架构实战的技术专栏。
写最一线的踩坑经验,做最务实的技术拆解。如果这篇文章对你有启发,欢迎点赞、转发、关注。我们下篇见。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)