
如何沉淀 Skill:Codex 和 WorkBuddy 用户实战指南
预计字数:3500 字 阅读时间:14 分钟 难度等级:⭐⭐(小白友好,无需技术基础) 核心价值:学会把重复使用的 AI 指令沉淀成可复用的 Skill,让 AI 编程助手进入全新效率档位
 AI·Agent用的越久,会发现一件事:
AI·Agent用的越久,会发现一件事:
你真正省下时间的地方,往往不是某次惊艳的对话,而是那些被你固化下来、可以反复调用的 Skill。
很多人把 Skill 理解成"再写一个 Prompt",这是最常见的误区。
Prompt 是一次性指令——每次对话都要重新表述一遍。
Skill 是把你反复使用的指令、参考资料、脚本、判断逻辑整体打包,让 AI 在合适的时候自动触发,并按你规定的流程执行。
今天分别用 OpenAI 的 Codex CLI 和腾讯的 WorkBuddy 两个工具,把 Skill 沉淀这件事从理念到实操讲清楚。
 为什么值得沉淀?
为什么值得沉淀?
判断一个东西值不值得沉淀成 Skill,只看一个问题:
你是否已经做过这件事三次以上,并且每次的做法都大同小异?
三次是一个好门槛。
- 做过一次,可能只是偶发需求;
- 做过两次,你还在摸索做法;
- 做到第三次,重复的部分就开始暴露出来
这些重复的部分,就是可以沉淀的骨架。
不是所有重复的事都值得做 Skill。判断标准很简单:
- 值得做:有稳定流程的任务。
- 比如提交代码前跑测试并生成报告、发布公众号文章、生成 API 文档。骨架稳定,血肉变化。
- 不值得做:依赖当下判断的任务。
- 比如调一个奇怪的 Bug、给某段代码做 Code Review。每次都需要根据具体上下文现场判断,硬写 Skill 反而让 AI 变死板。
- 中间态:整体灵活但某个子流程固定的任务。
- 比如 Code Review 整体是灵活的,但"跑完测试并总结失败用例"这一步是固定的——可以只把这步做成独立 Skill。
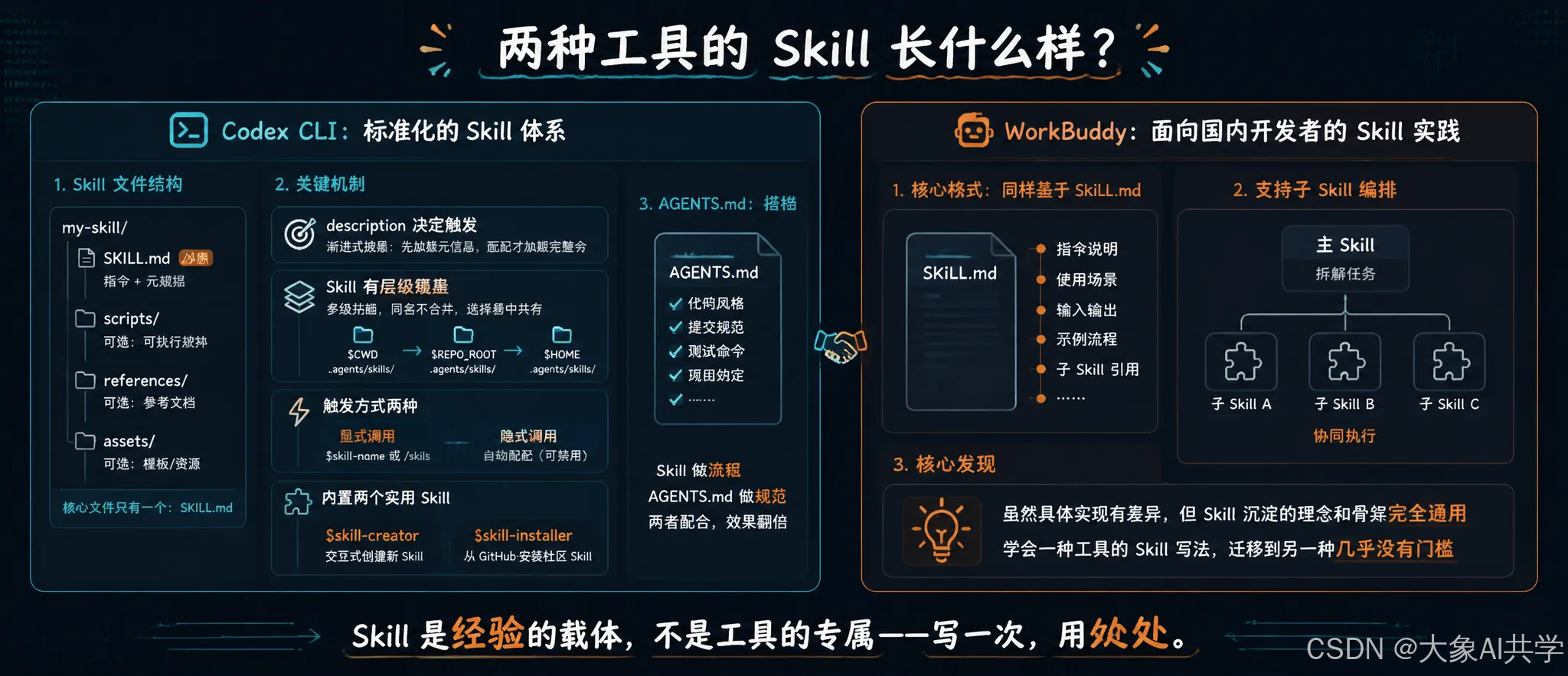
两种工具的 Skill 长什么样?
Codex CLI:标准化的 Skill 体系
Codex CLI 是 OpenAI 推出的终端编码代理,基于 Rust 编写,开源在 GitHub 上有 9 万多 star。
它有一套完整的 Skill 机制,也是目前三种主流 AI 编程工具中标准化程度最高的。
一个 Codex Skill 的文件结构是这样的:
my-skill/
├── SKILL.md # 必须:指令 + 元数据
├── scripts/ # 可选:可执行脚本
├── references/ # 可选:参考文档
└── assets/ # 可选:模板/资源核心文件只有一个:SKILL.md。
注意几个关键点:
- 1. description 决定触发。
Codex 的触发机制是"渐进式披露"
它不会在启动时就加载所有 Skill 的完整指令,只加载 name + description + 文件路径。
当你输入的指令和某个 Skill 的 description 匹配时,Codex 才会去读取完整的 SKILL.md。
这意味着 description 写得越精确,误触发越少。
- 2. Skill 有层级覆盖。 Codex 会从多个位置扫描 Skill:
- $CWD/.agents/skills/ — 当前工作目录级
- $REPO_ROOT/.agents/skills/ — 仓库根级
- $HOME/.agents/skills/ — 用户全局级
同名 Skill 不会合并,而是都会出现在选择器里。
这让你可以在不同项目中定制同名 Skill 的不同行为。
- 3. 触发方式有两种:
- 显式调用:在提示中输入 $commit-message-gen,或在 Codex 中运行 /skills
- 隐式调用:Codex 根据 description 自动匹配(可以通过配置禁用)
更方便的是,Codex 内置了 $skill-creator 和 $skill-installer 两个 Skill。
前者帮你交互式地创建新 Skill,后者帮你从 GitHub 安装社区 Skill。
- 4. AGENTS.md 是 Skill 的搭档。
类似于 Cursor 的 .cursorrules 或 Claude Code 的 CLAUDE.md,AGENTS.md 是项目级的指令文件,告诉 Codex 这个项目的代码风格、提交规范、测试命令等。
Skill 做流程,AGENTS.md 做规范——两者配合使用。
WorkBuddy:面向国内开发者的 Skill 实践
WorkBuddy 是腾讯推出的 AI 编程助手,有桌面版和 VS Code 插件。
它的 Skill 机制虽然没有 Codex 那样标准化文档,但实际使用的格式和理念是相通的——同样基于 SKILL.md,同样支持子 Skill 编排。
核心发现:
虽然具体实现有差异,但 Skill 沉淀的理念和骨架完全通用。
学会了一种工具的 Skill 写法,迁移到另一种几乎没有门槛。
Ps:同样的逻辑适用于所有市面的Agent产品和claw产品,比如Claude code(是最早skills规范的提出者),kimi-code等等。
 沉淀 Skill 的四个阶段
沉淀 Skill 的四个阶段
从"每次都手写"到"一个 Skill 自动搞定",中间有四个阶段。
很多人总想一步到位写个完美的 Skill,结果写出来不好用。
阶段一:手工重复
第一次做某件事,所有步骤都靠一条条指令推进。
这个阶段不要急着写 Skill,先把流程手工走通。
你还不知道哪里会踩坑,哪些步骤会变,哪些是固定的。
阶段二:整理步骤清单
做到第二、第三次,你开始意识到有几步是固定的,有几步每次不一样。把它们分开:
- 固定部分:连接方式、拉取命令、健康检查端点
- 变动部分:目标服务器地址、分支名、是否需要数据迁移
这一步的价值是把"流程"和"参数"分离。Skill 沉淀的是流程,参数留给调用时输入。
阶段三:写 Skill 骨架
这时候才开始动手写。一个好 Skill 有四个必须想清楚的要素:
① 触发词。 穷举用户可能说的表达。不要只写"部署时触发"——这种描述等于没写。要写具体的。
② 边界。 明确 Skill 不做什么,和它做什么一样重要。
③ 步骤。 把流程拆成编号步骤,每一步说清楚输入输出和依赖关系。
④ 参考文件。 Skill 目录里放脚本和模板。把易变的配置和固定的代码分开——配置放 Skill 外,脚本放 Skill 内。
阶段四:用了再改
写完 Skill 不是终点,而是起点。第一版几乎一定有问题。每次用的时候留意:
- 这次触发对了吗?有没有该触发没触发、不该触发却触发的情况?
- 哪一步 AI 没按预期做?是指令不清还是参考文件不够?
- 有没有出现"我又手动补了一段指令"的情况?如果有,那段指令该进 Skill。
Skill 是养出来的,不是写出来的。用一次改一次,三个月后它会变得非常顺手。
三个常见误区
误区一:追求大而全
一个 Skill 试图处理十种场景,结果每种都不够深入。
正确做法:宁可拆成三个小 Skill,各自聚焦。
误区二:把配置写死在 Skill 里
把 API key、服务器地址、用户 ID 这些易变的东西直接写进 SKILL.md 正文。
换台机器就废了,换个项目也要改。
正确做法:用 references/ 目录放配置模板,或者让 Skill 在运行时从环境变量读取。
误区三:写完就不管了
建议每次用完问自己三个问题:触发对了吗?AI 哪一步做得不好?我手动补了什么?把这三个问题的答案写进 Skill,下一次就会更好。
写在最后
Skill 沉淀的本质,是把你在 AI 编程助手使用中积累的流程经验,变成可复用的数字资产。
写 Prompt 是消耗,每次都从零开始。
写 Skill 是积累,越用越顺。
Codex 和 WorkBuddy 都给了你完整的 Skill 机制——前者有标准化的文件格式和内置工具,后者有灵活的子 Skill 编排和面向国内开发者的生态。
从今天开始,挑一件你已经做过三次以上的事,按照上面的四个阶段,把它沉淀成你的第一个 Skill。
你会发现,你对Ai的使用效率进入了一个完全不同的档位。
既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果可以给我个星标⭐,将不胜感激~谢谢你看我的文章,我们,下次再见。
#Skill沉淀 #Codex #WorkBuddy #AI编程 #大象AI共学
作者:大象-推动 AI 共学,让普通人轻松上手AI
相关链接
- Codex CLI GitHub:https://github.com/openai/codex
- WorkBuddy 官网:https://www.codebuddy.cn/home/

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)