
为什么 Superpowers 的 brainstorming skill 坚决不写代码?我翻了它的源文件
你有没有用 Claude Code 的时候遇到这种情况——
让它帮你加一个功能,三百行代码噼里啪啦就下来了,跑起来一看,逻辑对了七八成,但剩下那两成全是它自己发明的需求。你说这是测试的 bug,它说好,又改了一通,结果把能跑的地方也顺手改坏了。
这不是 Claude Code 不够聪明。是它太"勤快"了——不问、不验、不收,直接上手干。
Superpowers 解决的就是这个问题。 不是给 Claude 加能力,而是给 Claude 加纪律。
这个插件在 GitHub 上六个月跑到 185,000 stars(v5.1.0,2026 年 5 月),但码哥观察了一下,大多数人装完之后用法是这样的:开一个新功能,喊一句 /brainstorming,然后一路回答问题,最后让它写代码。仅此而已。
相当于买了套瑞士军刀,每次只用开瓶器。
这篇文章从 Superpowers 的 SKILL.md 源文件出发,拆解那些大多数人没认真看过的核心 skill,把完整工作流跑通。
Superpowers 是什么:不是插件,是工程纪律的文本分发
先说一个可能颠覆你认知的事情:Superpowers 里的每一个 skill 本质上是一个 Markdown 文件,里面写的是"当你遇到这类任务时,你必须按这个流程走"。
不是代码,不是工具调用,就是纯文本的行为约束。
这背后有一个很深刻的观察:AI 编程 Agent 缺的从来不是能力,而是纪律。Claude 知道该写测试,但在"快速给我跑一遍看看"的语境下,它会跳过;Claude 知道 debug 要找根因,但你说"快帮我改一下",它就直接猜着改了。
Superpowers 做的事情就是——用文本"强制执行"这些工程师该有的纪律,让 Claude 不管你怎么催,都不会绕过应走的流程。
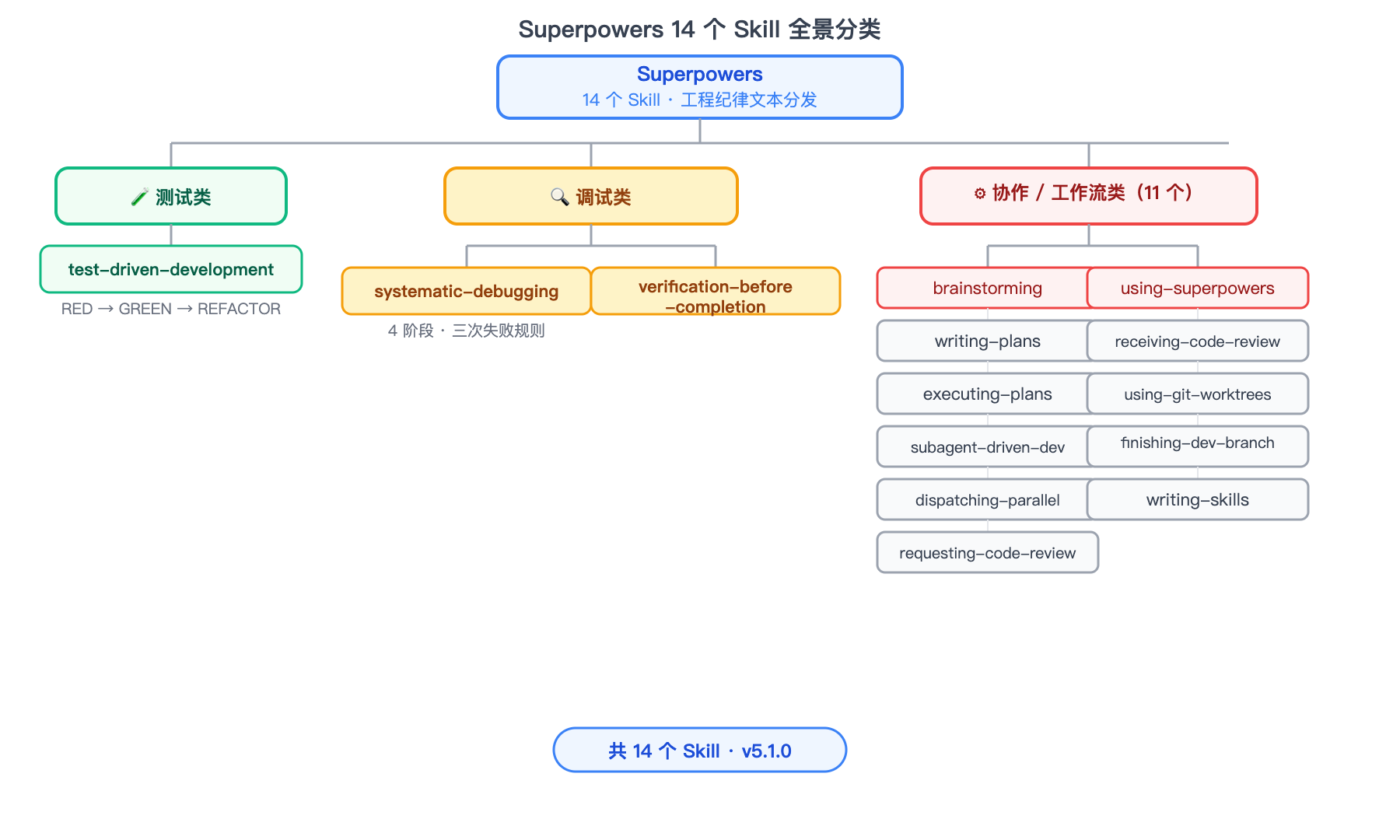
插件目前包含 14 个 skill,分三类:
测试类: test-driven-development
调试类: systematic-debugging、verification-before-completion
协作/工作流类: brainstorming、writing-plans、executing-plans、subagent-driven-development、dispatching-parallel-agents、requesting-code-review、receiving-code-review、using-git-worktrees、finishing-a-development-branch、writing-skills、using-superpowers
下面拆解最核心的五个。
brainstorming:有一道硬门,过不去就不许写代码
这是大多数人用得最多、也用得最浅的 skill。
多数人的用法是:喊 /brainstorming,回答几个问题,然后……让它直接开写。相当于只走了 brainstorming 的前三步,最关键的后六步全跳过了。
打开 brainstorming 的 SKILL.md,第一个硬约束是这样写的(原文引用):
<HARD-GATE>
Do NOT invoke any implementation skill, write any code, scaffold any project,
or take any implementation action until you have presented a design
and the user has approved it.
</HARD-GATE>
注意这是 <HARD-GATE>,不是 "建议",是"不管你觉得多简单,过不了这道门,一行代码都不许写"。
完整的 brainstorming 流程是 9 步:
- 探索项目现状(看文件、commits、文档)
- 如果有视觉问题,先提供可视化伴侣(独立消息)
- 逐条问澄清问题(每次只问一个)
- 提出 2-3 个方案并给出推荐理由
- 按章节展示设计方案,每段都要确认
- 把设计写入
docs/superpowers/specs/YYYY-MM-DD-<topic>-design.md并 commit - 自检 spec:扫描 TBD/TODO、内部矛盾、范围、歧义
- 让用户审阅 spec 文件
- 移交 writing-plans skill
最容易跳过的是步骤 6-8。
大多数人跑到步骤 4-5 就觉得"差不多了,直接写吧",结果设计没有落到文档里,后面执行阶段 Claude 的"记忆"就开始漂移,做到一半忘了之前说好的接口怎么定义。
还有一个细节:brainstorming 明确规定,它的终态只有一个——移交 writing-plans。不许调用 frontend-design,不许调用 mcp-builder,只能移交 writing-plans。这强制让你走完整个设计→计划→实现链条,而不是跳着来。
码哥用这个 skill 做过一次重构任务,第一次走完整 9 步花了 40 分钟,感觉很慢。但后面执行阶段几乎没有返工。对比之前直接让 Claude 上手写,"设计"环节省了 30 分钟,但后来改了三轮,总时间反而多了两小时。
有一个反直觉的设计: brainstorming 里说,"如果你觉得这个项目太简单、不需要设计,那更要走流程。简单项目里的隐含假设,是浪费工作的最大来源。"
就连一个配置改动,也必须走完整流程,设计可以短(几句话),但不能省。
systematic-debugging:四阶段,禁止没有根因就动手
这是码哥认为 Superpowers 里价值最被低估的 skill。
普通的调试姿势是:报错了 → 把错误贴给 Claude → 它说"可能是 X,试试改这里" → 你试了 → 没好 → 再贴 → 它说"那可能是 Y" → 反复横跳。
这种模式下,按照 Superpowers 里的数据:系统调试平均耗时 2-3 小时;用 systematic-debugging,15-30 分钟。
差距这么大的原因是:Claude 的默认模式是猜,systematic-debugging 强制它必须找到根因才能提修复。
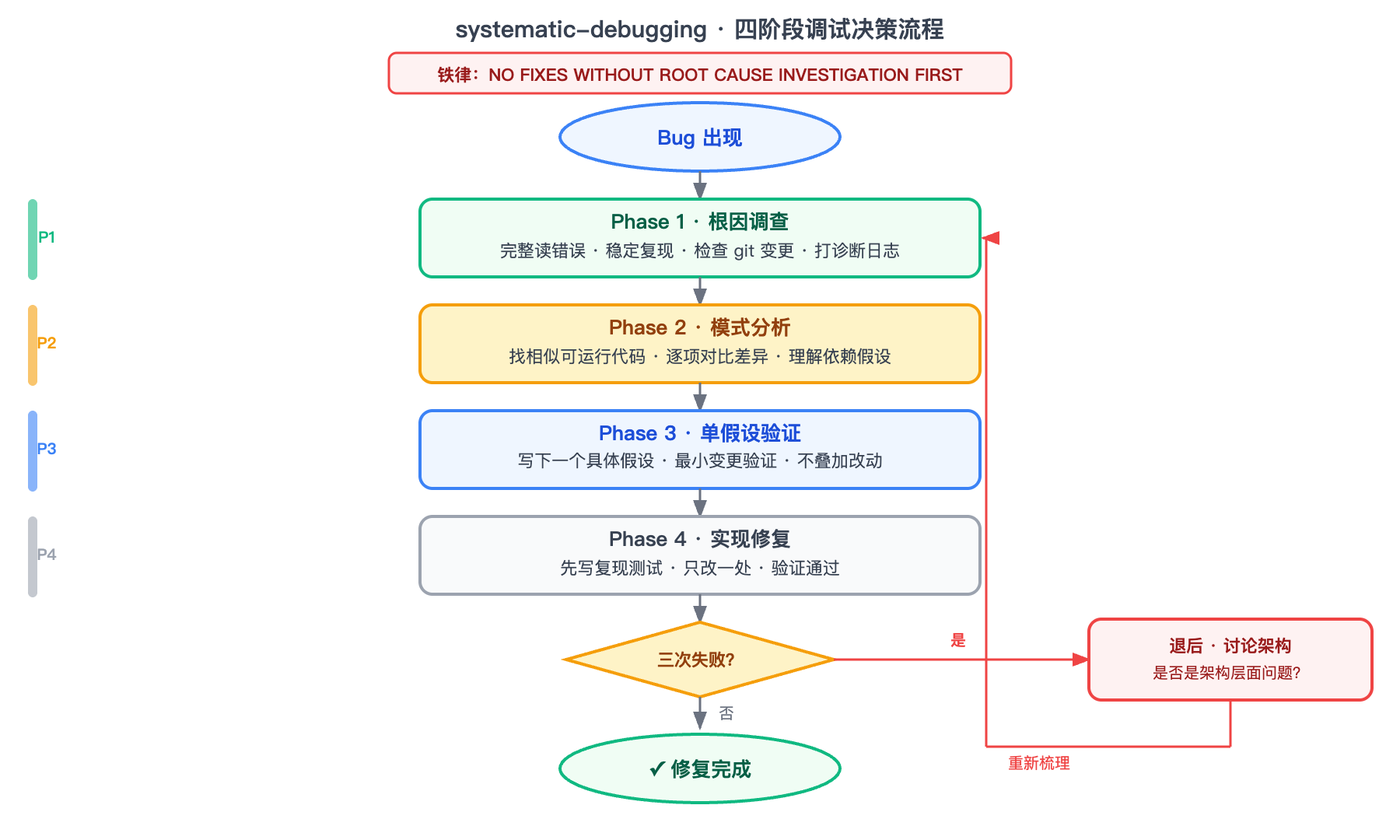
铁律(原文):
NO FIXES WITHOUT ROOT CAUSE INVESTIGATION FIRST
四个阶段(必须按顺序,前一阶段没完成不许进下一阶段):
Phase 1:根因调查
- 完整读错误信息(不是"看一眼",是"读完整")
- 稳定复现步骤
- 检查最近的 git 变更
- 对多组件系统,在每个边界打诊断日志,先跑一次收集证据,再分析哪里断了
Phase 2:模式分析
- 找到同一个 codebase 里类似的、能跑通的代码
- 和坏的代码逐项对比差异("每一个差异,不管多小,都列出来,不要假设那个没关系")
- 理解依赖和假设条件
Phase 3:单假设验证
- 写下一个具体的假设("我认为 X 是根因,因为 Y")
- 做最小变更验证
- 不对的话:换新假设,不要叠加改动
Phase 4:实现修复
- 先写能复现问题的测试
- 只改一处
- 如果三次修复都没解决问题:停下来,讨论是不是架构层面的问题
这里有一个最实用的设计:Phase 4 有个"三次失败规则"。
如果试了 3 次修复都没有解决,systematic-debugging 要求你停下来,不再尝试第四次,而是退后一步讨论"是不是这个模式本身就有问题"。
这和大多数工程师的直觉是相反的——大多数人在第三次失败之后会更焦虑地试第四次、第五次。但每次额外的猜测修复,都在给代码引入新的不确定性,而且还在浪费时间。
Superpowers 里有一份"常见借口对照表",码哥觉得写得非常准:
| 借口 | 真相 |
|---|---|
| "这个 issue 很简单,不用走流程" | 简单的 bug 也有根因,流程对简单问题反而更快 |
| "紧急情况,没时间调查" | 系统性调试比猜测快多了,"紧急"不是理由 |
| "先试一下再说" | 第一次就确立猜测模式,后面就一直猜 |
| "我已经大概知道问题在哪了" | 知道症状不等于知道根因 |
在 systematic-debugging 的基础上,还加了一张「调试决策流程图」来帮读者更直观理解四阶段:
writing-plans:每个步骤 2-5 分钟,不许有 TBD
brainstorming 结束后,会移交给 writing-plans。这个 skill 的核心职责是:把 spec 拆成可以被 AI 或人类一步步执行的任务清单。
关键设计决定:每个步骤的粒度是 2-5 分钟。
具体什么意思?一个任务里的步骤是这样的:
- [ ] Step 1: 写一个失败的测试
- [ ] Step 2: 跑一下,确认它确实失败了
- [ ] Step 3: 写最小实现让测试通过
- [ ] Step 4: 跑测试,确认通过
- [ ] Step 5: Commit
注意,"写一个失败的测试"和"跑一下确认它失败"是两个独立步骤,不是一步。这种粒度设计的目的是:让 subagent 或者你自己在执行时,每一步都有明确的完成判定标准,不会"做了一半,不知道算不算完成"。
writing-plans 还有一个"零占位符"规则:
以下写法会被认为是计划失败,必须修正:
- "TBD"、"TODO"、"后续实现"
- "添加适当的错误处理"(不写具体怎么处理)
- "写上述内容的测试"(不给测试代码)
- "类似 Task N"(重复内容,不允许引用)
这个规则是为了解决一个真实问题:当 Claude 在后续执行计划时,如果遇到 TBD,它要么停下来问,要么自己发挥——两个都是噩梦。
计划写完之后,writing-plans 会给你两个执行选项:
选项 1:subagent-driven-development(推荐) —— 每个任务派一个新的 subagent,带两轮审查
选项 2:executing-plans —— 在当前会话里串行执行,适合没有 subagent 支持的环境
subagent-driven-development vs executing-plans:怎么选
这是很多人困惑的地方,选错了效率差一大截。
subagent-driven-development 的工作方式:
- 每个任务 spawn 一个全新的 subagent
- 新 subagent 拿到计划文件和当前任务,干净的上下文开始工作
- 两轮审查:先看 spec 合规性,再看代码质量
- 完成后回报,主 agent 决定是否继续下一个任务
executing-plans 的工作方式:
- 在当前会话里串行执行所有任务
- 上下文累积,会话越来越长
- 批量执行,定期设置检查点让你介入
怎么选的规则很简单:
| 情况 | 选哪个 |
|---|---|
| Claude Code / Codex 等支持 subagent 的平台 | subagent-driven-development |
| Cursor、不支持 subagent 的环境 | executing-plans |
| 任务数量多、上下文容易漂移 | subagent-driven-development |
| 简单小任务、不想多绕一圈 | executing-plans |
Superpowers 的文档里直接说:"如果你的环境支持 subagent,就用 subagent-driven-development,代码质量会显著更高。"原因是干净的上下文让 Claude 不会被之前的错误尝试带偏。
实际感受:码哥有一次做一个有 8 个任务的功能,用 executing-plans 跑,跑到第五个任务时 Claude 开始"综合"前面几个任务的修改,把一个已经通过的测试改坏了。换 subagent-driven-development,每个 subagent 只看自己的任务,这种"上下文串扰"就基本消失了。
代价是:subagent-driven-development 每个任务都要重新加载 plan 文件,调用开销略高。但按 token 效率算,避免一次返工节省的成本远大于这个开销。


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)