
LLM之Agent(五十五)|如何构建一个超越99%人的Claude Loop Engineering(循环工程)
我不再提示Claude了。我只是运行一个循环,让它提示,然后思考下一步做什么。我的工作是写循环。
—— Boris Cherny, Anthropic Claude Code负责人, 2026年6月
如果你关注AI领域的最新动态,最近有个词正在悄然走红——Loop Engineering(循环工程)。
这要从OpenClaw的创造者Peter发布的一条推文说起。
过去,AI是工人,人类是导演、监督者和检查者。每完成一步,人类都得亲自输入提示、阅读结果、再输入下一个提示。
但循环工程彻底扭转了这个局面。
不再需要人类每次手动输入提示,而是把任务分配给AI,由AI执行、审查结果,如果没完成就继续执行。整个迭代过程被设计成一个自动化系统。
换句话说,人类正在从"输入提示的人"转变为**"构建提示输入系统的人"**。
在你继续阅读之前 🦸🏻♀️
如果喜欢这篇文章:
- 点赞收藏支持我 👏
- 关注我获取最新文章 🫶
什么是循环?
过去两年,我们一直在逐个任务地提示AI代理。这个假设正在改变。
与其简单地让AI"创建一个落地页"然后亲自监督后续每一步,不如设计一个自我持续的循环:发现 → 规划 → 执行 → 验证 → 改进。重复这个循环直到达成目标。
循环是你自己设计的。它可以在大多数代理框架中实现。问题不是"用什么工具",而是"如何连接"。
单代理循环
最简单的形式是单个代理自我循环。
研究 → 创建草稿 → 对比目标 → 修复薄弱环节 → 重复直到达标
你不需要在每个步骤点击提示。代理自己处理整个周期。就像一个人反复重写草稿。
舰队循环(多代理)
在更大的配置中,一群代理在循环中运行。
目标传给编排代理(Orchestrator)→ 编排代理分解目标交给专业代理(Specialist)→ 专业代理再把更细的任务分配给子代理(Sub-agent)。
整个树状结构代表一个持续的循环:发现 → 规划 → 执行 → 验证,直到目标实现。
如果单循环是"一个人独自重写草稿",那舰队循环就是"一个团队端到端地运行项目"。
开环与闭环
有两种类型的循环。理解这个区别对实际应用的成功至关重要。
开环:探索型
有条件和目标,但给代理广阔的探索空间。它可以尝试和发现多条路径,创造出最初没有完全预料到的东西。
这是一个有前景的领域。创造性成果很可能在这里诞生。
但成本是个问题。一个真正自由探索的开环系统会消耗海量token。对于90%没有无限预算的人来说,目前还不现实。此外,如果应用到标准松散的项目上,它就是一台垃圾制造机。
闭环:约束型
人类预先设计端到端的流程。
清晰的目标 ↓ 确定的步骤 ↓ 每步都有评估 ↓ 停止条件,或交回人类(附带性能数据反馈)
代理在循环中运行,但在人类制定的框架内。每次运行都将学到的经验传递给下一次,因此准确度会随着每次执行而提高。由于路径受限,它可以在正常预算下运行。当前工作中产生成果的几乎全是这种模式。
闭环系统中的角色分工可以简化为:
- 编排代理(Orchestrator)——持有整体目标
- 专业代理(Specialist)——拥有并执行具体步骤
- 子代理(Sub-agent)——执行详细任务
- 评估关卡(Evaluation Gate)——防止低质量输出通过
开环是"探索",闭环是"执行"。先设计后者,等预算和精度到位后再释放前者。这是当前现实的顺序。
内置在工具中的"循环"
"重复同一个任务"的概念现在已经成为编码代理的正式功能。以Claude Code为例,已经加入了几个命令:
/loop:定期重复提示或命令/goal:定义完成条件,持续工作多个回合直到满足条件(2026年5月11日版本2.1.139加入)- Dynamic Workflows:AI自己编写工作流程,拆分成几十到几百个子代理并行执行(2026年5月28日版本2.1.154加入,使用关键词
ultracode调用)
它们的共同点是:减少人来来回回地给指令、检查结果、再给指令的过程。只要提前提供条件和流程,AI会自己处理剩下的。
代理循环的基础——ReAct与Reflexion
循环工程不是凭空出现的概念。它基于两个重要的研究模式。
ReAct(Reason + Act)
源自普林斯顿大学和谷歌的联合研究,这种架构在推理和行动之间交替。
┌──────────────────────────────────────┐
│ ReAct Pattern │
│ │
│ Thought(思考) │
│ ↓ │
│ Action —— 执行工具 │
│ ↓ │
│ Observation —— 接收结果 │
│ ↓ │
│ Thought —— 循环回到这里 │
│ ... │
│ Final Answer(最终答案) │
└──────────────────────────────────────┘
在编程语境中:
- 理解目标
- 写代码
- 运行代码并观察输出(或错误)
- 推断哪里出了问题
- 修正并重新运行
- 重复直到测试通过
Reflexion
这是ReAct的高级版本,一种将失败进行语言化表达并用于指导后续尝试的模式。
任务执行 → 失败 → 用自然语言反思失败原因 → 将反思存入记忆 → 在下一次尝试中利用反思来改善表现
在循环工程中,Reflexion的核心理念通过外部记忆(如SKILL.md和progress.txt文件)来实现。
内循环 vs 外循环
循环有两层。理解这个区别是循环工程的核心。
内循环(单任务内的验证循环)
在一个任务中,代理在回应之前验证自己的工作。
用户说:"修复auth.ts中的失败测试。"
❌ 弱代理:编辑文件 → "完成了!"
✅ 强代理:编辑文件 → 创建测试 → 运行测试 → 检测失败 → 修复边界情况 → 重新运行测试 → 确认所有测试通过(绿色)→ "完成了!"
关键点:两者使用完全相同的工具循环基础设施。区别在于模型是否"选择"调用验证工具。
外循环(跨会话的学习循环)
这是代理在多个会话之间从过去的经验中学习的循环。
会话1:处理分页时失败 → 记录"分页最佳实践"到SKILL.md → 会话2:遇到类似任务 → 读取SKILL.md,从一开始就正确处理分页
| 对比项 | 内循环 | 外循环 |
|---|---|---|
| 范围 | 单个任务内 | 跨会话 |
| 目的 | 提高任务可靠性 | 随时间改进 |
| 状态维持 | 上下文窗口内 | 持久化文件(AGENTS.md, SKILL.md等) |
| 当前成熟度 | 许多代理已具备 | 仍在开发中 |
循环工程在其设计中涵盖了这两个方面。
构成循环的"5+1"组件
Addy Osmani总结,一个运转良好的循环由五个组件加上记忆组成。
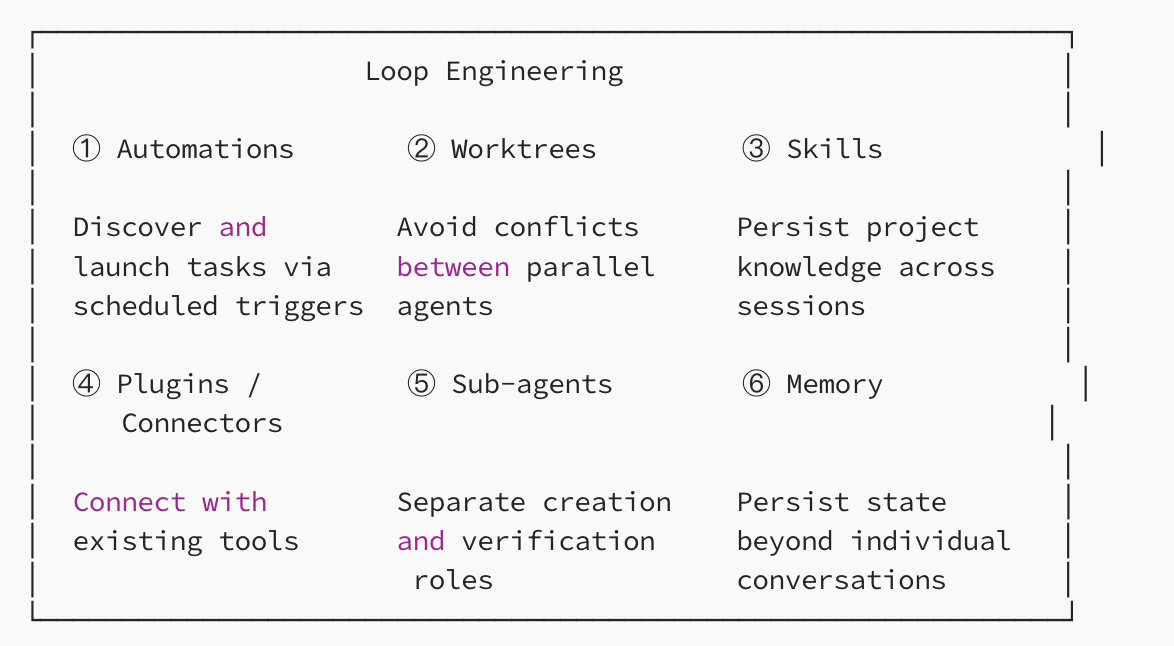
各部分详解
① 自动化执行
循环的核心。它是定期发现任务并激活代理的机制。
# 最简单的循环 (Ralph循环原型)
while true; do
claude --print \
--system-prompt "$(cat system_prompt.md)" \
"$(cat task_prompt.md)" \
>> output.log
sleep 300 # 每5分钟一次
done
② Worktrees(工作树)
当多个代理同时在同一个代码仓库上工作时,提供独立的工作空间以防止文件变更冲突。
# 使用Git worktree进行并行执行
git worktree add ../agent-1-workspace feature/auth-fix
git worktree add ../agent-2-workspace feature/api-refactor
# agent-1和agent-2同时在不同的分支上工作 → 无冲突
③ Skills(技能)
"这个项目里应该怎么写东西"之类的规则和流程。避免了每次都要从头解释一切。
<!-- .claude/skills/testing.md -->
测试指南
- 测试框架: Vitest
- 文件命名规范: *.test.ts
- Mock库: MSW (Mock Service Worker)
- 覆盖率目标: 80%或以上
- 边界情况: 始终包含边界情况和错误场景的测试
④ 插件/连接器(Plugins / Connectors)
连接AI与现有工具(如GitHub、Jira、Slack、数据库)的机制。
# MCP服务器配置示例
mcp_servers:
github:
command: "github-mcp-server"
env:
GITHUB_TOKEN: "${GITHUB_TOKEN}"
slack:
command: "slack-mcp-server"
env:
SLACK_BOT_TOKEN: "${SLACK_BOT_TOKEN}"
⑤ 子代理(Sub-agents)
这个模式分离了"创造者"和"验证者"的角色。受到GAN(生成对抗网络)概念的启发。
┌───────────┐ 生成代码 ┌───────────┐
│ 生成器 │ ─────────→ │ 评估器 │
│ (创造者) │ │ (审查者) │
│ │ ←───────── │ │
└───────────┘ 反馈意见 └───────────┘
↑ │
│ 提供计划 │
│ ┌───────────┐ │
└───│ 规划器 │ ←─────┘
│ (规划者) │ 评估结果
└───────────┘
这个三代理循环被Anthropic采用,能达到单个代理无法企及的质量水平。
⑥ 记忆(Memory)
循环的生命线。通过在会话之外持久化状态,超越了上下文窗口的限制。
<!-- progress.md -->
## 已完成任务
- [x] 重构了认证模块 (PR #142)
- [x] 为API端点添加了测试 (PR #143)
## 进行中
- [ ] 数据库迁移
## 经验教训
- 在PostgreSQL 16中,JSON路径语法已变更
- 测试环境中需要Redis mock
"代理会忘记,但仓库不会。" —— Addy Osmani
端到端循环设计示例
实战案例:每日Issue分类 + 自动修复循环
#!/bin/bash
# daily_loop.sh —— 每天早上6点通过cron执行
REPO_DIR="/path/to/project"
PROGRESS_FILE="$REPO_DIR/.loop/progress.md"
MAX_ITERATIONS=5
cd "$REPO_DIR"
for i in $(seq 1 $MAX_ITERATIONS); do
echo "=== 迭代 $i / $MAX_ITERATIONS ==="
# 步骤1: 发现新Issue (自动化执行)
# 步骤2: 在隔离分支中工作 (worktree)
# 步骤3: 参考技能文件并应用修复
# 步骤4: 运行测试 (机械性成功检查)
# 步骤5: 将结果记录到进度文件 (记忆)
claude --print \
--system-prompt "$(cat .claude/loop_system.md)" \
"读取进度文件并处理下一个Issue。
完成后,更新进度文件。
如果所有Issue都已完成,输出DONE。" \
2>&1 | tee -a .loop/run.log
# 硬停止:检测到DONE就退出
if grep -q "DONE" .loop/run.log; then
echo "所有任务已完成"
break
fi
done
循环流程
[cron 每天早上6点] ──→ 启动 daily_loop.sh
│
┌────▼────────┐
│ progress.md │ ← 读取之前的进度 (加载状态)
└────┬────────┘
│
┌────▼─────────────────┐
│ 检查GitHub Issues │ ← 插件/连接器
│ 获取未解决的Issue │
└────┬─────────────────┘
│
┌────▼─────────────────┐
│ 创建git worktree │ ← worktree隔离
│ 在隔离分支中工作 │
└────┬─────────────────┘
│
┌────▼─────────────────┐
│ 参考CLAUDE.md/skills/ │ ← skills层
│ 应用代码变更 │
└────┬─────────────────┘
│
┌────▼─────────────────┐
│ 运行测试 │ ← 机械性验证
│ npm test && npm run │
│ lint │
└────┬─────────────────┘
│
成功吗?
│
否 ────▼──────→ 重试修复
│ (由子代理验证)
│
是
│
┌────▼─────────────────┐
│ 创建Pull Request │
│ 更新progress.md │ ← 记忆更新
└────┬─────────────────┘
│
下一个Issue或终止
最后:这不仅仅是AI开发的事
如果要用一句话概括其本质:
不是给高能力个体自由,而是设计一个他们能取得成果的环境。
同样的道理也适用于人类团队。仅仅雇佣有才能的人是不够的,还需要上下文、规则、反馈、评估标准和进度管理。
AI时代的管理正在从给详细指令,转向设计好的约束条件。
💡 设计循环,而不是提示。
💬 讨论时间
你现在的工作流程中,有哪些步骤是可以变成"循环"的?是日常代码审查、Bug修复、还是内容创作?欢迎在评论区分享你的想法!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)