
Claude Code + 通义千问,从零搭出生产级 RAG 要花多少钱?
系统截图
开发方式与成本
这个项目是怎么做出来的?
流程分两步,先有方案文档,再有代码:
第一步:生成方案文档 hashed-gliding-metcalfe.md
真正动手写代码之前,先用 Claude Code 产出一份完整的实现方案(文件名是 Claude Code 自动分配的任务代号)。这份约 440 行的 Markdown 相当于整个项目的「施工蓝图」,内容包括:
- 生产级 RAG 的架构图与模块划分
- Monorepo 目录结构与各文件职责
- LangGraph 10 节点状态机、API 路由、数据模型
- 混合检索、HyDE、自纠正、评估面板等技术选型
第二步:按方案文档生成代码
随后以 hashed-gliding-metcalfe.md 为唯一规格说明,让 Claude Code 逐模块生成 monorepo 代码、Docker 配置、前后端实现;运行报错时再在对话中调试、重构。运行时调用 阿里百炼 / 通义千问 的 OpenAI 兼容 API:
- 对话与生成:
qwen3.6-plus - 向量嵌入:
text-embedding-3-large(1024 维,经百炼接口调用)
花了多少钱?
全程 API 调用(Embedding 批量写入 + 多轮对话测试 + Rerank 等)合计约 100 元人民币。
为什么要做这个实验?
主要目的不是「做一个 Demo」,而是实测:从零完成一套可上线、带评测与可观测性的生产级 RAG,究竟要烧多少 Token、踩多少坑。本文把架构选型、14 个 Bug 的排查过程、以及 Token 成本体感一并记录下来,供你在立项或选型时参考——若你也用 Claude Code + 国内 LLM API 走类似路线,可以据此估算预算与工期。
执行构建流程
从「写方案」到「跑起来」,整条链路可以概括为下面这张图:上半段是 AI 生成与调试,下半段是本地执行构建。
报错
通过
开始
Claude Code 生成方案文档
hashed-gliding-metcalfe.md
按方案逐模块生成代码
Monorepo · Docker · 前后端 · LangGraph
本地运行是否通过?
Claude Code 对话调试
逐条修复 Bug · 重构
进入本地执行构建
docker compose up -d
Milvus · PostgreSQL · Redis · Attu
npm install
安装 workspaces 依赖
配置 .env
qwen3.6-plus · text-embedding-3-large
npm run dev
Turbo 并行启动后端 :3000 · 前端 :5173
上传文档
PDF / Word / Excel / HTML / Markdown
入库流水线
解析 → 分块 → Embedding → Milvus 混合索引
对话问答
LangGraph 检索 · Rerank · 生成 · 引用
评测面板调参 · 上线前检查
生产级 RAG 可用
全程 API 约 100 元
图例说明:
- 蓝色节点:Claude Code 负责的部分(方案 → 代码 → 调试)
- 橙色节点:你在本机执行的构建与运行步骤
- 绿色终点:系统跑通并可对外提供 RAG 问答
对应仓库根目录常用命令:
docker compose up -d # 或 npm run docker:up |
|
npm install |
|
# 复制 .env.example 为 .env,填入通义千问 API Key 与模型名 |
|
npm run dev # Turbo 同时启动 backend + frontend |
┌─────────────────────────────────────────────────────────┐ |
|
│ 前端 (5173) │ |
|
│ Vite + React 19 + TypeScript + TailwindCSS 4 │ |
|
│ Zustand 状态管理 · React Query · Lucide 图标 │ |
|
├─────────────────────────────────────────────────────────┤ |
|
│ 后端 (3000) │ |
|
│ Node.js + Fastify 5 + TypeScript + LangGraph │ |
|
│ 10 节点状态机 · SSE 流式响应 · Zod 配置校验 │ |
|
├──────────┬──────────┬──────────┬────────────────────────┤ |
|
│ Milvus │ PostgreSQL│ Redis │ 外部 API │ |
|
│ 2.5.x │ 16 │ 7 │ 阿里百炼 │ |
|
│ 稠密向量 │ 文档元数据│ 缓存 │ LLM: qwen-plus │ |
|
│ +BM25稀疏│ Chunk关系 │ 限流 │ Embedding: v3 1024维 │ |
|
└──────────┴──────────┴──────────┴────────────────────────┘ |
核心依赖版本
| 组件 | 版本 | 说明 |
|---|---|---|
@langchain/langgraph |
0.2.x | LangGraph 状态机 |
@langchain/openai |
0.3.x | LLM/Embedding 客户端 |
@zilliz/milvus2-sdk-node |
2.5.x | Milvus Node SDK |
fastify |
5.x | HTTP 框架 |
tailwindcss |
4.x | CSS 框架 |
pdf-parse |
1.x | PDF 解析 |
mammoth |
1.x | DOCX 解析 |
xlsx |
0.18.x | Excel 解析 |
cheerio |
1.x | HTML 解析 |
从零搭建的完整过程
第一阶段:方案文档(施工蓝图)
在创建任何代码文件之前,第一步是生成 hashed-gliding-metcalfe.md——一份由 Claude Code 输出的生产级 RAG 实现方案。后续所有目录结构、LangGraph 节点、API 设计、技术栈选型,都以这份文档为准;可以说,项目是从 Markdown 规格说明「编译」出来的,而不是边想边写。
方案文档核心内容:
- 架构概览:前端四面板 + Fastify 后端 + Milvus/PostgreSQL/Redis + 外部 LLM/Embedding/Rerank
- 完整目录树:
packages/backend、packages/frontend、packages/shared下每个文件的命名与职责 - LangGraph 流水线:查询改写 → HyDE → 混合检索 → Rerank → 生成 → 自纠正 → 置信度评估
- 入库流水线:多格式解析 → 语义分块 → 向量化 → Milvus 混合索引
这份文档保存在仓库根目录,与最终代码结构高度一致,是理解本项目来源的最佳入口。
第二阶段:基础设施搭建
2.1 Monorepo 结构
使用 npm workspaces + Turbo 构建 monorepo,目录结构如下:
rag-platform/ |
|
├── package.json # 根配置,定义 workspaces |
|
├── turbo.json # Turbo 任务编排 |
|
├── tsconfig.base.json # 共享 TypeScript 配置 |
|
├── docker-compose.yml # 基础设施编排 |
|
├── .env.example # 环境变量模板 |
|
└── packages/ |
|
├── backend/ # Fastify API 服务 |
|
├── frontend/ # Vite + React 前端 |
|
└── shared/ # 前后端共享 TypeScript 类型 |
关键配置点:
package.json中使用"workspaces": ["packages/*"]让 npm 自动管理子包依赖tsconfig.base.json定义target: ES2022、module: NodeNext、strict: true- 子包通过
"extends": "../../tsconfig.base.json"继承基础配置
2.2 Docker Compose 基础设施
services: |
|
etcd: # Milvus 元数据存储 |
|
minio: # Milvus 对象存储 |
|
milvus: # 向量数据库 |
|
postgres: # 关系型数据库 |
|
redis: # 缓存与限流 |
|
attu: # Milvus Web 管理界面 |
2.3 共享类型定义
packages/shared/src/ 定义了完整的业务类型:
document.ts:Document、DocumentCreateInput、DocumentListResponsechunk.ts:Chunk、ChunkCreateInputquery.ts:QueryRequest、QueryResponse、Citation、ConfidenceScoreconfig.ts:RAGConfig、DEFAULT_RAG_CONFIGresponse.ts:SSEEvent、FeedbackInput、EvalMetrics
第三阶段:后端核心服务
3.1 文档解析器工厂模式
// parsers/parser.ts - 解析器接口 |
|
export interface DocumentParser { |
|
supportedMimeTypes: string[]; |
|
parse(buffer: Buffer): Promise<ParseResult>; |
|
} |
|
// parsers/parser.ts - 工厂类 |
|
export class ParserFactory { |
|
private parsers: DocumentParser[] = []; |
|
register(parser: DocumentParser) { this.parsers.push(parser); } |
|
getParser(mimeType: string): DocumentParser { |
|
return this.parsers.find(p => p.supportedMimeTypes.includes(mimeType))!; |
|
} |
|
} |
各解析器实现:
- PDF:使用
pdf-parse提取文本,保留页码和元数据 - DOCX:使用
mammoth提取纯文本(带结构信息) - Excel:使用
xlsx将每个 sheet 转为 CSV 格式文本 - HTML:使用
cheerio清理脚本/样式,再用turndown转 Markdown - Markdown:直接读取,提取标题作为元数据
3.2 分块策略路由
class Chunker { |
|
async chunk(text, options, documentId) { |
|
switch (options.strategy) { |
|
case 'markdown': return this.markdownChunk(...); // 按标题切分 |
|
case 'semantic': return this.semanticChunk(...); // 语义边界 |
|
case 'hierarchical': return this.hierarchicalChunk(...);// 父子结构 |
|
case 'fixed': return this.fixedSizeChunk(...); // 固定大小 |
|
} |
|
} |
|
} |
Markdown 分块是最实用的策略:按 # 标题层级切分,保留 headerPath(如 ["第一章", "1.1 节", "1.1.1 小节"])作为元数据,这样检索时能知道 chunk 在文档中的位置。
3.3 Milvus 向量存储
// 集合字段设计 |
|
{ name: 'id', data_type: DataType.VarChar, is_primary_key: true }, |
|
{ name: 'document_id', data_type: DataType.VarChar, is_partition_key: true }, |
|
{ name: 'content', data_type: DataType.VarChar, max_length: 65535 }, |
|
{ name: 'dense_vector', data_type: DataType.FloatVector, dim: 1024 }, |
|
{ name: 'sparse_vector', data_type: DataType.SparseFloatVector }, |
|
{ name: 'chunk_index', data_type: DataType.Int64 }, |
|
{ name: 'metadata', data_type: DataType.JSON }, |
|
// ... 过滤字段:doc_type, source, author, created_at, section_title |
第四阶段:LangGraph RAG 管道
设计了完整的 10 节点有向无环图(DAG)带条件分支和自纠正循环:
START |
|
│ |
|
▼ |
|
classify(查询分类) |
|
│ |
|
├─ factual/comparative → decompose(子问题分解) |
|
│ │ |
|
│ ▼ |
|
│ retrieve(混合检索) |
|
│ │ |
|
├─ general/other → rewrite(查询改写) |
|
│ │ |
|
│ ├─ HyDE enabled → hyde(假设文档) |
|
│ │ │ |
|
│ └─ HyDE disabled ───────┤ |
|
│ ▼ |
|
│ retrieve(混合检索) |
|
│ │ |
|
│ ▼ |
|
│ rerank(重排序) |
|
│ │ |
|
│ ▼ |
|
│ compress(上下文压缩) |
|
│ │ |
|
│ ▼ |
|
│ generate(答案生成) |
|
│ │ |
|
│ ▼ |
|
│ grade(质量评估) |
|
│ │ |
|
│ ┌─ pass/ambiguous ───► format(格式化) |
|
│ │ |
|
│ └─ fail + retries ──► rewrite(回退重写) |
|
│ │ |
|
│ └─ 循环回去 |
|
│ |
|
▼ |
|
END |
第五阶段:前端企业级 UI
- 侧边栏:深色背景(
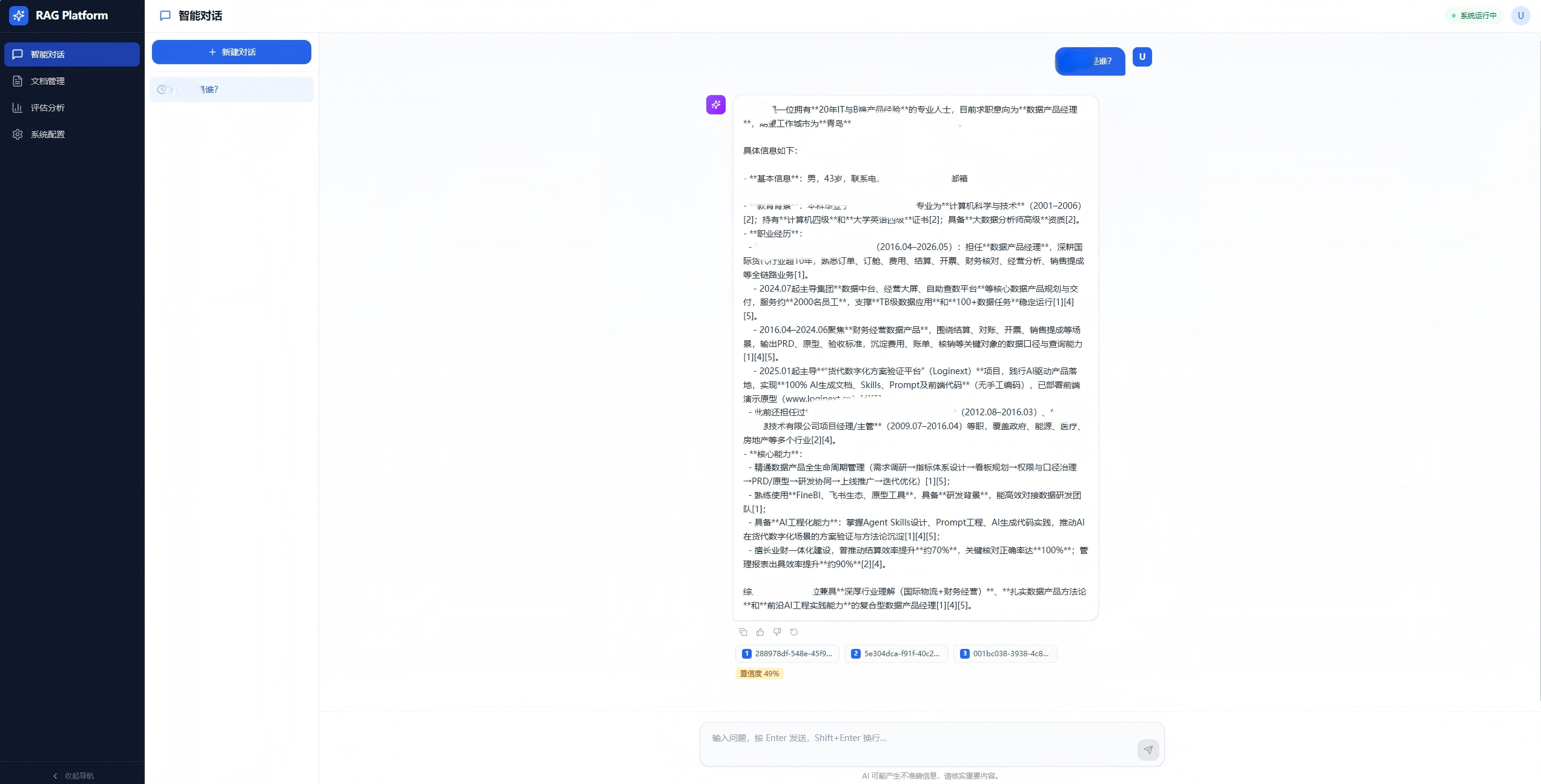
bg-sidebar)、图标+文字、选中高亮、可折叠 - 对话界面:左侧多会话管理、中间聊天气泡、右侧引用面板、底部输入区
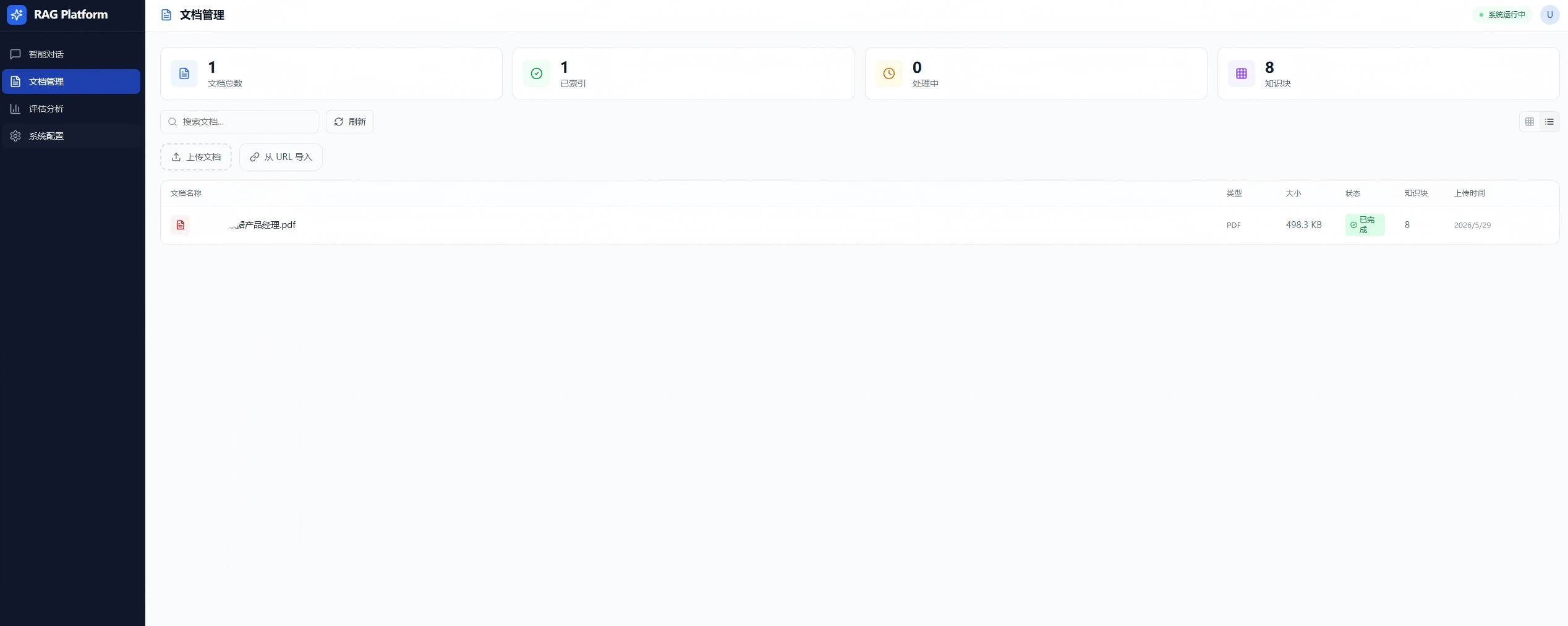
- 文档管理:4 个统计卡片、搜索/筛选/视图切换、拖拽上传、列表/网格双视图
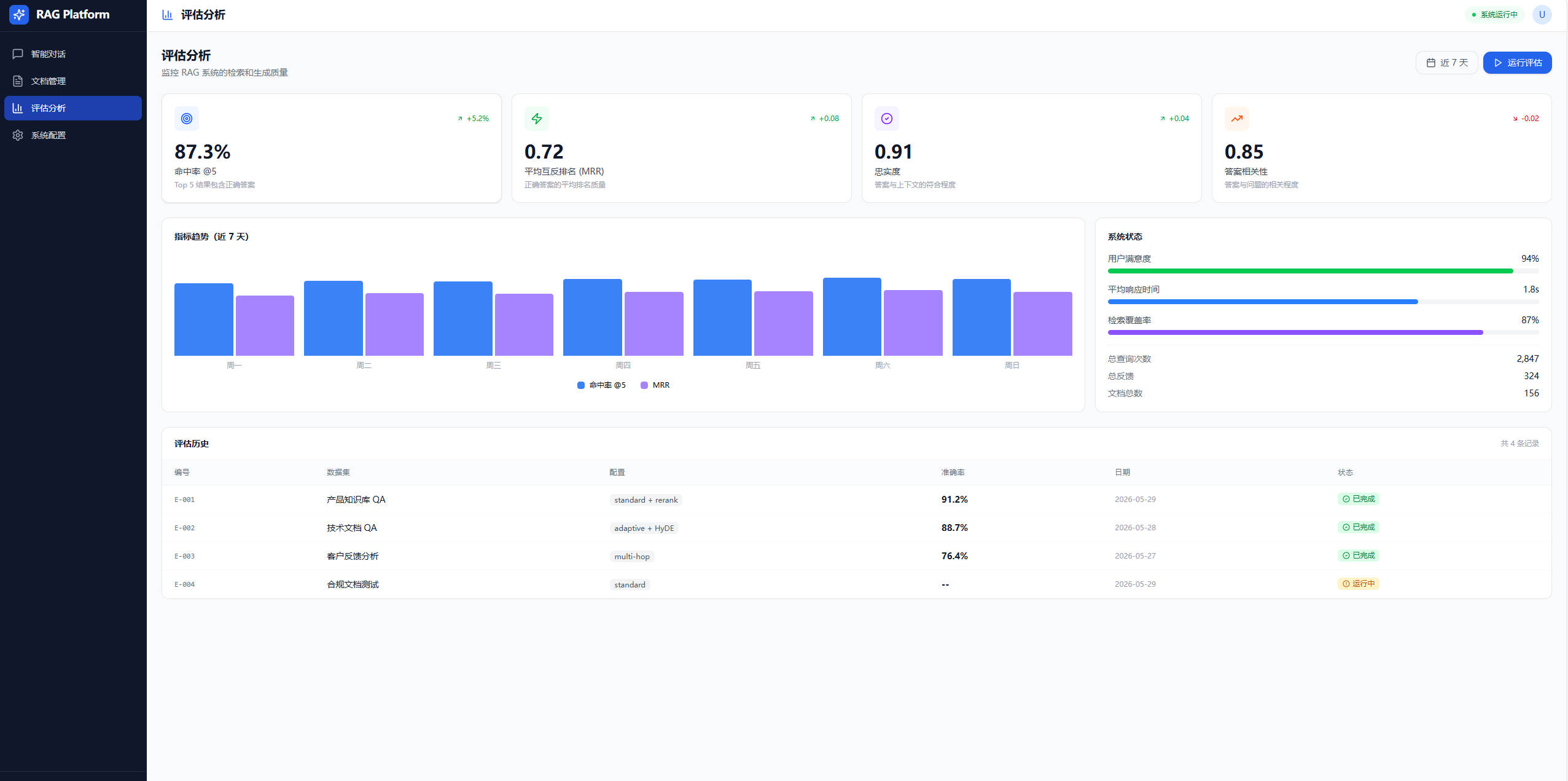
- 评估面板:4 个指标卡片(命中率/MRR/忠实度/相关性)、7 天趋势柱状图、系统状态面板
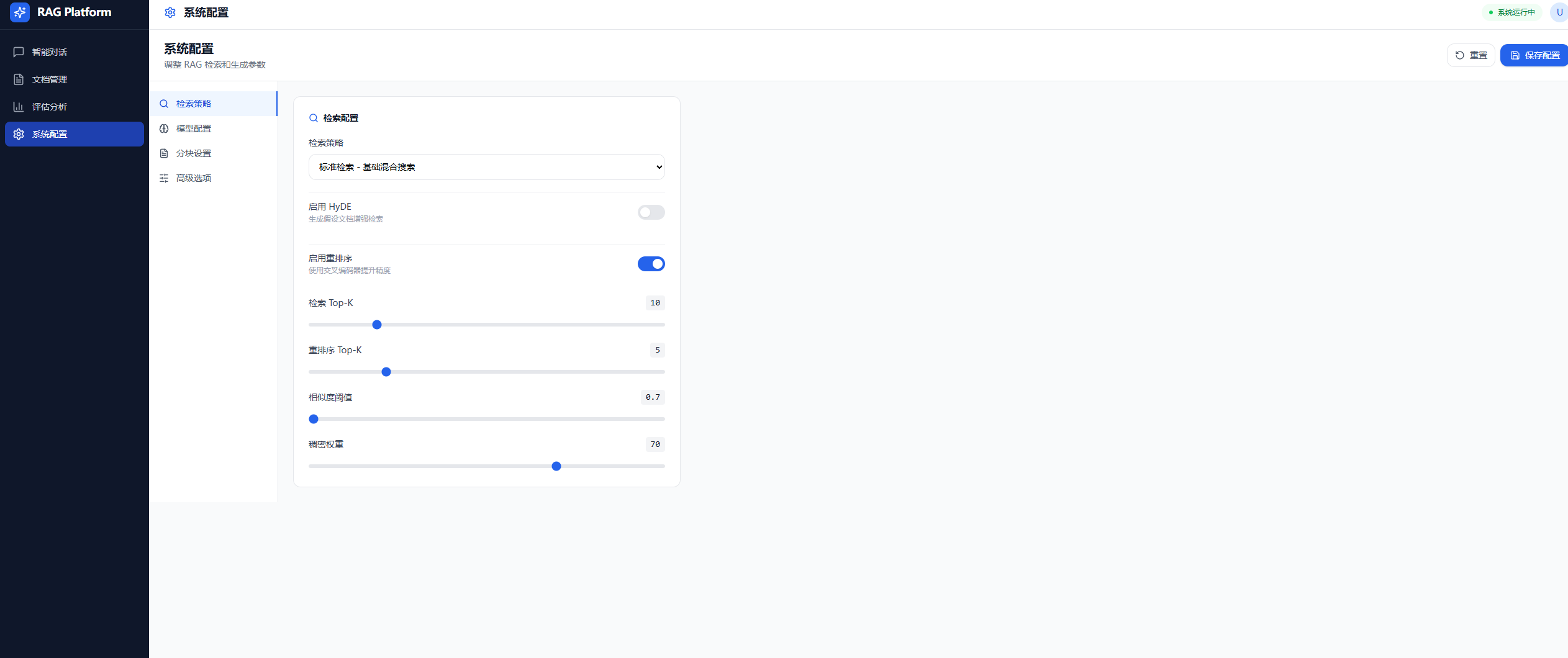
- 配置面板:Tab 式布局(检索/模型/分块/高级)、开关/滑块/下拉选择
踩坑记录与核心难点(重点)
Bug 1:@types/mammoth 包不存在 —— 依赖安装失败
异常信息:
npm error 404 Not Found - GET https://registry.npmjs.org/@types%2fmammoth |
排查过程:
npm install失败,提示@types/mammoth不存在- 检查 npm registry 确认该类型包确实不存在
- 查看
mammoth源码,发现它自带 TypeScript 类型声明
解决方案:从 package.json 的 devDependencies 中删除 "@types/mammoth": "^1.4.4" 这行。
教训:不是所有包都有对应的 @types/* 包。先查一下包是否自带 .d.ts 文件,没有再装 @types/*。
Bug 2:minhash 包不存在 —— 去重模块依赖缺失
异常信息:
npm error notarget No matching version found for minhash@^2.0.0 |
排查过程:
- npm 找不到
minhash的 2.0.0 版本 - 搜索 npm registry 发现该包名已被弃用,现在叫
node-minhash或其他替代
解决方案:暂时移除 minhash 依赖,去重功能先用简单的内容哈希(xxhash-wasm)替代。MinHash+LSH 作为后续优化项。
Bug 3:dotenv 在 monorepo 中找不到 .env 文件
异常信息:
ZodError: [ |
|
{ "code": "invalid_type", "expected": "string", "received": "undefined", "path": ["llmApiKey"] }, |
|
{ "code": "invalid_type", "expected": "string", "received": "undefined", "path": ["embeddingApiKey"] }, |
|
{ "code": "invalid_type", "expected": "string", "received": "undefined", "path": ["databaseUrl"] } |
|
] |
排查过程:
- 后端启动就崩溃,Zod 报所有环境变量 undefined
.env文件明明存在于D:\rag-platform\.envconfig/schema.ts中使用了import 'dotenv/config'- 问题:
dotenv默认在process.cwd()下查找.env,而process.cwd()是packages/backend/ - 环境变量命名也不匹配:
.env中用的是LLM_BASE_URL,但 schema 中定义的字段名是驼峰llmBaseUrl
解决方案(两步修复):
第一步:修复 .env 变量名为大写下划线(与 shell 环境变量命名习惯一致):
// config/schema.ts |
|
export const ConfigSchema = z.object({ |
|
LLM_BASE_URL: z.string().default('https://api.openai.com/v1'), |
|
LLM_API_KEY: z.string(), |
|
// ... 全部使用大写下划线 |
|
}); |
第二步:显式指定 .env 路径:
import path from 'node:path'; |
|
import { fileURLToPath } from 'node:url'; |
|
import dotenv from 'dotenv'; |
|
const __dirname = path.dirname(fileURLToPath(import.meta.url)); |
|
dotenv.config({ path: path.resolve(__dirname, '../../../../.env') }); |
排查技巧:在 getConfig() 中加 console.log(process.env.LLM_API_KEY) 确认环境变量是否被加载。
Bug 4:LangGraph 节点名与状态字段名冲突
异常信息:
Error: grade is already being used as a state attribute (a.k.a. a channel), cannot also be used as a node name. |
排查过程:
- 后端启动崩溃,错误指向
graph.ts第 48 行 - 检查发现
RAGState中定义了grade: Annotation<string>() - 同时又用
.addNode('grade', gradeNode)注册了同名节点 - LangGraph 要求节点名和状态字段名不能重复
解决方案:将节点名从 'grade' 改为 'evaluate',同时更新所有引用该节点的边:
workflow.addConditionalEdges('evaluate', routeAfterGrade, { |
|
format: 'format', |
|
retry: 'rewrite', |
|
}); |
Bug 5:Milvus createIndex 的 params 参数格式错误
异常信息:
Error: ErrorCode: UnexpectedError. Reason: there is no vector index on field: [dense_vector], please create index firstly |
排查过程:
- Milvus 集合创建成功,但
loadCollection时报错说没有向量索引 - 检查
createIndex调用代码,使用的是extra_params: JSON.stringify({ nlist: 1024 }) - 搜索 Milvus Node SDK 文档和源码,发现新版 SDK 使用
params参数且期望传 对象 - 传 JSON 字符串导致 Go 后端反序列化失败,索引创建静默失败
解决思路:
- 先查 Milvus SDK 的
createIndex方法签名 - 发现
params应该是对象而非字符串 - 改为
params: { nlist: 1024 }后问题解决
// ❌ 错误写法 |
|
await milvus.createIndex({ |
|
index_type: 'IVF_FLAT', |
|
metric_type: 'COSINE', |
|
extra_params: JSON.stringify({ nlist: 1024 }), |
|
}); |
|
// ✅ 正确写法 |
|
await milvus.createIndex({ |
|
index_type: 'IVF_FLAT', |
|
metric_type: 'COSINE', |
|
params: { nlist: 1024 }, |
|
}); |
Bug 6:TailwindCSS v4 样式不生效
异常信息:无报错,但前端页面没有样式,所有 Tailwind 类名都失效。
排查过程:
- 页面能打开,但就是纯 HTML 堆砌,没有任何样式
- 检查
index.css中有@import "tailwindcss" - 检查
vite.config.ts中只有[react()]插件 - TailwindCSS v4 的集成方式变了:需要在 Vite 中配置
@tailwindcss/vite插件
解决思路:
- 搜索 TailwindCSS v4 文档,确认需要
@tailwindcss/vite插件 npm install @tailwindcss/vite- 在
vite.config.ts中添加插件
import tailwindcss from '@tailwindcss/vite'; |
|
export default defineConfig({ |
|
plugins: [react(), tailwindcss()], |
|
}); |
Bug 7:文档入库时重复创建记录
异常表现:上传一个 PDF 文件,文档列表中显示两条相同名称的记录。
排查过程:
- 查询 PostgreSQL 发现确实有两条相同 title 的记录
- 追踪代码流程:
routes/ingest.ts:收到文件 →documentService.create()→ 创建记录 → 调用ingestionService.ingest()services/ingestion.service.ts:解析文档 →this.documentService.create()→ 又创建了一次
- 问题:两个地方各自调用了一次
create()
解决思路:
- 路由层负责创建记录(返回 documentId 给前端)
- 把 documentId 传给
ingestionService.ingest(documentId, ...) - 服务层复用已有 ID,不再创建新记录
// routes/ingest.ts |
|
const documentId = await documentService.create({...}); |
|
ingestionService.ingest(documentId, buffer, fileName, mimeType, ...); |
|
// services/ingestion.service.ts |
|
async ingest(documentId: string, fileBuffer: Buffer, ...) { |
|
// 直接使用传入的 documentId,不再创建 |
|
// ... |
|
} |
Bug 8:向量维度不匹配(3072 vs 1024)
异常表现:
- 文档上传成功、分片 8 个、Milvus 中有 8 条数据
- 但检索返回 0 条结果,没有任何错误提示
- 使用 curl 直接测试后端 API 也返回空
排查过程:
第一步:确认 Milvus 中有数据
node -e " |
|
const { MilvusClient } = require('@zilliz/milvus2-sdk-node'); |
|
const client = new MilvusClient({ address: 'localhost:19530' }); |
|
const count = await client.query({ |
|
collection_name: 'rag_chunks', |
|
output_fields: ['count(*)'], |
|
filter: '', |
|
}); |
|
console.log('Count:', count.data); // 输出: [{"count(*)":"8"}] |
|
第二步:检查向量维度
const sample = await client.query({ |
|
collection_name: 'rag_chunks', |
|
output_fields: ['id', 'dense_vector'], |
|
filter: '', limit: 1, |
|
}); |
|
console.log('Vector length:', sample.data[0].dense_vector.length); // 输出: 1024 |
第三步:检查 schema 定义
// vectorstore/schema.ts |
|
export const DENSE_VECTOR_DIM = 3072; // text-embedding-3-large 的维度 |
发现问题:集合创建时用了 3072 维(默认配置,原本打算用 OpenAI 的 text-embedding-3-large),但实际 embedding API 调用的是阿里百炼的 text-embedding-v3,返回 1024 维。虽然 Milvus 接受了插入(可能截断或补零了),但搜索时维度不匹配导致静默返回空结果。
解决方案:修改 schema 为实际 embedding 维度
// vectorstore/schema.ts |
|
export const DENSE_VECTOR_DIM = 1024; // text-embedding-v3 的维度 |
同时需要删除旧集合重建(因为 Milvus 不允许修改已存在集合的维度)。
Bug 9:LangChain SDK 参数不兼容 —— baseUrl vs configuration: { baseURL }
异常表现:
- 文档上传成功,8 个 chunks 创建成功
- 日志显示 "Generated 8 embeddings"
- Milvus 显示 "Indexed 8 chunks"
- 但检索时返回 0 条文档
- 更诡异的是 embedding 阶段耗时极长(数十秒),正常应该 1-2 秒
排查过程:
第一次尝试:检查 embeddings/openai.ts 代码
// 当时的代码 |
|
embeddings = new OpenAIEmbeddings({ |
|
model: config.EMBEDDING_MODEL, |
|
apiKey: config.EMBEDDING_API_KEY, |
|
baseUrl: config.EMBEDDING_BASE_URL, // ← 这行有问题 |
|
dimensions: config.EMBEDDING_DIMENSION, |
|
}); |
第二次尝试:写独立脚本测试两种参数方式
# 测试 baseUrl(新版语法) |
|
node -e " |
|
const { OpenAIEmbeddings } = require('@langchain/openai'); |
|
const embeddings = new OpenAIEmbeddings({ |
|
model: 'text-embedding-v3', |
|
apiKey: 'sk-...', |
|
baseUrl: 'https://dashscope.aliyuncs.com/compatible-mode/v1', |
|
dimensions: 1024, |
|
}); |
|
embeddings.embedDocuments(['test']); |
|
" |
|
# 结果:卡住不动,超时 |
# 测试 configuration.baseURL(旧版语法) |
|
node -e " |
|
const { OpenAIEmbeddings } = require('@langchain/openai'); |
|
const embeddings = new OpenAIEmbeddings({ |
|
model: 'text-embedding-v3', |
|
apiKey: 'sk-...', |
|
configuration: { baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1' }, |
|
dimensions: 1024, |
|
}); |
|
embeddings.embedDocuments(['test']); |
|
" |
|
# 结果:238ms 完成,返回 2 个 1024 维向量 |
根因:@langchain/openai 的 OpenAIEmbeddings 类中,baseUrl 参数不被识别(被忽略),导致它使用默认的 OpenAI API 地址(api.openai.com),而不是阿里百炼的地址。由于 API Key 不匹配 OpenAI,请求要么超时要么返回错误数据。
解决方案:
embeddings = new OpenAIEmbeddings({ |
|
model: config.EMBEDDING_MODEL, |
|
apiKey: config.EMBEDDING_API_KEY, |
|
configuration: { baseURL: config.EMBEDDING_BASE_URL }, // ✅ 正确 |
|
dimensions: config.EMBEDDING_DIMENSION, |
|
timeout: 30000, |
|
}); |
|
// ChatOpenAI 同理 |
|
llm = new ChatOpenAI({ |
|
model: config.LLM_MODEL, |
|
apiKey: config.LLM_API_KEY, |
|
configuration: { baseURL: config.LLM_BASE_URL }, // ✅ 正确 |
|
temperature: config.LLM_TEMPERATURE, |
|
maxTokens: config.LLM_MAX_TOKENS, |
|
}); |
Bug 10:Milvus 集合已存在但索引丢失
异常表现:
Error: ErrorCode: UnexpectedError. Reason: there is no vector index on field: [dense_vector], please create index firstly |
排查过程:
- 之前的多次重启/崩溃导致 Milvus 中留下了不完整的集合
hasCollection检查通过(集合存在),但索引可能没建完- 每次重启后端时
ensureCollections()跳过重建,导致使用没有索引的旧集合
解决方案:每次重启后端前手动删除 Milvus 集合
node -e " |
|
const { MilvusClient } = require('@zilliz/milvus2-sdk-node'); |
|
const client = new MilvusClient({ address: 'localhost:19530' }); |
|
client.dropCollection({ collection_name: 'rag_chunks' }); |
|
client.dropCollection({ collection_name: 'rag_document_summaries' }); |
|
client.closeConnection(); |
|
" |
更好的方案:在 ensureCollections() 中加入索引存在性检查,如果集合存在但索引缺失则重建。
Bug 11:相似度阈值过高导致全部过滤
异常表现:
- 文档已索引,Milvus 中有 8 条数据
- Embedding API 正常工作
- 手动向 Milvus 发起随机向量搜索能返回结果(score: 0.007-0.01)
- 但 RAG 管道中检索返回 0 条
排查过程:
第一步:在 retrieve.node.ts 中加日志
console.log(`Retrieved ${documents.length} documents for query`); |
输出:Retrieved 0 documents for query: "周文轩是谁?..."
第二步:直接在 Node.js 中测试 Milvus 搜索
node -e " |
|
const { MilvusClient } = require('@zilliz/milvus2-sdk-node'); |
|
const { OpenAIEmbeddings } = require('@langchain/openai'); |
|
// 生成查询向量 |
|
const embeddings = new OpenAIEmbeddings({ |
|
model: 'text-embedding-v3', |
|
apiKey: 'sk-...', |
|
configuration: { baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1' }, |
|
dimensions: 1024, |
|
}); |
|
const [queryVec] = await embeddings.embedDocuments(['周文轩是谁']); |
|
// 搜索 Milvus |
|
const milvus = new MilvusClient({ address: 'localhost:19530' }); |
|
const result = await milvus.search({ |
|
collection_name: 'rag_chunks', |
|
vector: queryVec, |
|
topk: 5, |
|
output_fields: ['id', 'content', 'chunk_index'], |
|
}); |
|
console.log('Results:', result.results.length); |
|
console.log('Scores:', result.results.map(r => r.score)); |
|
" |
输出:
Results: 5 |
|
Scores: [0.4522, 0.3395, 0.3032, 0.2815, 0.2654] |
第三步:发现关键差异——Milvus 直接搜索返回 score 范围是 0.26-0.45,但代码中相似度阈值是 0.7。
根因:阿里百炼 text-embedding-v3 的 COSINE 相似度分数天然偏低,在 0.2-0.45 范围,而 OpenAI 的 embedding 分数通常在 0.7 以上。代码中默认阈值 0.7 是参照 OpenAI 设定的,导致所有结果都被过滤。
解决方案(两步):
- 降低默认阈值:
similarityThreshold: 0.2 - 移除 retrieve.node.ts 中的阈值过滤,让后续的 reranking 和 grading 来处理质量控制
// retrieve.node.ts - 移除阈值过滤 |
|
// const filtered = results.filter(r => r.score >= threshold); // ← 删除这行 |
|
const documents = results.map(r => ({ ...r })); // 直接返回所有结果 |
Bug 12:Fastify multipart Content-Length 不匹配
异常信息:
{ |
|
"statusCode": 400, |
|
"code": "FST_ERR_CTP_INVALID_CONTENT_LENGTH", |
|
"message": "Request body size did not match Content-Length" |
|
} |
排查过程:
curl直接请求后端 API 正常- 通过前端(Vite dev server 代理)请求返回 400
- 问题只在开发模式下出现,生产环境不会有
- 原因:Vite 代理在处理 multipart/form-data 时可能修改了 Content-Length 头
解决方案:生产环境不需要 Vite 代理(nginx 直接代理),开发模式下暂时用 curl 或 Postman 测试文件上传。
Bug 13:pino-pretty transport 无法解析
异常信息:
Error: unable to determine transport target for "pino-pretty" |
排查过程:
- Fastify logger 配置了
transport: { target: 'pino-pretty' } pino-pretty没有安装- 在 ESM 模式下,pino 的 transport target 解析方式不同
解决方案:直接移除 transport 配置,使用 Fastify 默认的 JSON 日志格式
const app = Fastify({ |
|
logger: { |
|
level: config.NODE_ENV === 'development' ? 'debug' : 'info', |
|
// 移除 transport 配置 |
|
}, |
|
}); |
Bug 14:后端进程端口冲突
异常信息:
Error: listen EADDRINUSE: address already in use 0.0.0.0:3000 |
排查过程:
- 新启动的后端进程报错端口占用
- 旧的后端进程还在运行(
tsx watch模式不会自动退出) tsx watch会监听文件变化自动重启,但有时候会 fork 出多个进程
解决方案:
# 找到占用 3000 端口的进程 PID |
|
netstat -ano | grep 3000 | grep LISTENING |
|
# 强制终止 |
|
taskkill //PID <PID> //F |
排查方法论总结
在整个开发过程中,形成了以下排查策略:
策略 1:逐层隔离测试
当 RAG 管道返回 0 条结果时,按以下顺序逐层测试:
第 1 层:Milvus 中有数据吗? |
|
→ node 查询 count(*) → 8 条 ✓ |
|
第 2 层:Milvus 中的向量维度正确吗? |
|
→ 查询 sample dense_vector.length → 1024 ✓ |
|
第 3 层:Milvus 能搜到结果吗? |
|
→ 直接 search → 5 条,score: 0.26-0.45 ✓ |
|
第 4 层:Embedding API 调用的是正确的地址吗? |
|
→ 独立脚本测试 baseUrl vs configuration → baseUrl 超时 ✗ |
|
第 5 层:代码中的阈值过滤是否合理? |
|
→ 阈值 0.7 > 实际分数 0.45 → 全部过滤 ✗ |
策略 2:对比测试
当怀疑某个参数配置不正确时,写两个独立脚本对比:
# 方案 A |
|
node -e "new OpenAIEmbeddings({ baseUrl: ... }).embedDocuments(['test'])" |
|
# 结果:超时 |
|
# 方案 B |
|
node -e "new OpenAIEmbeddings({ configuration: { baseURL: ... } }).embedDocuments(['test'])" |
|
# 结果:238ms 成功 |
策略 3:日志驱动
在每个关键步骤加 console.log:
Parsing document: xxx.pdf → 5868 characters |
|
Created 8 chunks |
|
Generated 8 embeddings |
|
Indexed 8 chunks in Milvus |
|
Ingestion completed in 789ms |
如果某个步骤没有日志输出,问题就在那一步。
策略 4:直接查日志文件
当后端在后台运行时,输出被写入临时文件:
C:\Users\ADMINI~1\AppData\Local\Temp\claude\D--\...\tasks\{task-id}.output |
通过 Read 工具读取完整日志,而不是等后台通知。
容易出问题的关键检查点
上线前必查清单
| # | 检查项 | 验证方法 |
|---|---|---|
| 1 | Embedding 维度一致性 | Milvus schema 的 dim 值 == 模型实际输出维度 |
| 2 | API 地址参数 | 使用 configuration: { baseURL } 而非 baseUrl |
| 3 | 相似度阈值 | 先用独立脚本测试 embedding 的分数分布 |
| 4 | Milvus 索引创建 | params 传对象而非 JSON 字符串 |
| 5 | 环境变量加载 | monorepo 中需要指定 .env 的绝对路径 |
| 6 | 文档入库去重 | 路由层和服务层不会各自创建数据库记录 |
| 7 | TailwindCSS 插件 | v4 必须在 vite.config.ts 中注册 |
| 8 | 后端进程 | 重启前确保旧进程已退出,避免端口占用 |
| 9 | Milvus 集合状态 | 重启后端时可能需要删除旧集合重建 |
| 10 | LangGraph 节点名 | 不能与 RAGState 中的字段名重复 |
开发调试建议
- 写独立测试脚本:对每个可能出问题的组件(Embedding、Milvus 搜索、LLM 调用)写一个独立的可运行脚本,不要等到整个系统跑起来才测试
- 打印关键指标:在
retrieve.node.ts中打印检索到的文档数量和前几个 score 值,确认过滤逻辑正确 - 使用 Attu 管理界面:Milvus 的 Attu( http://localhost:3001 )可以直观查看集合、数据和索引状态
- PostgreSQL 直查:用
psql或 SQL 客户端直接查询documents和chunks表,确认数据入库 - 后端进程管理:
tsx的 watch 模式容易残留进程,建议在开发阶段用npx tsx src/index.ts(不 watch)代替npm run dev(watch)
项目总结
本项目从零到完整可用的 RAG 平台,共修复了 14 个 Bug,经历了无数次重启和重试。起点是 Claude Code 生成的方案文档 hashed-gliding-metcalfe.md,代码据此逐模块落地;模型侧依赖 通义千问 qwen3.6-plus 与 text-embedding-3-large,全链路 API 花费约 100 元——可作为「先写规格、再 AI 生成代码 + 国内 LLM」完成生产级 RAG 的一次 Token 与成本样本。
Bug 分类
| 类型 | 数量 | 典型问题 |
|---|---|---|
| SDK 参数不兼容 | 3 | baseUrl vs configuration.baseURL、params vs extra_params |
| 参数不匹配 | 3 | 向量维度 3072 vs 1024、相似度阈值 0.7 vs 0.45 |
| 配置/路径问题 | 3 | .env 找不到、Tailwind 插件未注册、端口占用 |
| 逻辑 Bug | 3 | 重复创建记录、节点名冲突、索引创建静默失败 |
| 环境问题 | 2 | @types/mammoth 不存在、minhash 包被弃用 |
最大教训
这些问题的共同特点是:不会抛明确的错误,而是静默失败——返回 0 条结果、向量全是 0、配置被忽略、请求超时但不报错。
排查这类问题的核心方法论:
- 不要相信系统没报错就是正常的——没有结果本身就是一个错误信号
- 逐层隔离,从下往上测——先确认数据库/向量库正常工作,再测服务层,最后测管道层
- 写独立测试脚本——不要等到整个系统跑起来才测试单个组件
- 打印关键指标——每个步骤都打印输入输出的数量和关键值
- 对比验证——用已知的正确方式(如 curl、独立脚本)对比可疑的代码路径
附录:完整文件清单
D:\rag-platform\ |
|
├── .env # 环境变量配置 |
|
├── .env.example # 环境变量模板 |
|
├── .gitignore |
|
├── docker-compose.yml # 基础设施编排 |
|
├── package.json # Monorepo 根配置 |
|
├── tsconfig.base.json # 共享 TypeScript 配置 |
|
├── turbo.json # Turbo 任务编排 |
|
├── hashed-gliding-metcalfe.md # 实现方案(代码生成前的施工蓝图) |
|
├── PROJECT_JOURNEY.md # 本文档 |
|
│ |
|
├── packages/backend/ |
|
│ ├── package.json |
|
│ ├── tsconfig.json |
|
│ └── src/ |
|
│ ├── index.ts # 后端入口 |
|
│ ├── config/ |
|
│ │ ├── index.ts # 配置导出 |
|
│ │ └── schema.ts # Zod 校验 schema |
|
│ ├── server/ |
|
│ │ ├── app.ts # Fastify 实例 |
|
│ │ └── routes/ |
|
│ │ ├── config.ts # /api/v1/config |
|
│ │ ├── documents.ts # /api/v1/documents CRUD |
|
│ │ ├── eval.ts # /api/v1/eval/* |
|
│ │ ├── feedback.ts # /api/v1/feedback |
|
│ │ ├── ingest.ts # /api/v1/documents POST |
|
│ │ └── query.ts # /api/v1/query POST |
|
│ ├── services/ |
|
│ │ ├── document.service.ts # 文档 CRUD |
|
│ │ ├── evaluation.service.ts # 评估服务 |
|
│ │ ├── feedback.service.ts # 反馈服务 |
|
│ │ ├── generation.service.ts # LLM 生成 |
|
│ │ ├── ingestion.service.ts # 文档入库 |
|
│ │ └── retrieval.service.ts # 检索服务 + RRF |
|
│ ├── graph/ |
|
│ │ ├── state.ts # LangGraph 状态定义 |
|
│ │ ├── graph.ts # 图编译 |
|
│ │ ├── nodes/ # 10 个节点 |
|
│ │ │ ├── classify.node.ts |
|
│ │ │ ├── compress.node.ts |
|
│ │ │ ├── decompose.node.ts |
|
│ │ │ ├── format.node.ts |
|
│ │ │ ├── generate.node.ts |
|
│ │ │ ├── grade.node.ts |
|
│ │ │ ├── hyde.node.ts |
|
│ │ │ ├── rerank.node.ts |
|
│ │ │ ├── retrieve.node.ts |
|
│ │ │ └── rewrite.node.ts |
|
│ │ └── subgraphs/ |
|
│ │ ├── correction.graph.ts |
|
│ │ └── retrieval.graph.ts |
|
│ ├── llm/ |
|
│ │ ├── openai.ts # ChatOpenAI 客户端 |
|
│ │ ├── provider.ts |
|
│ │ ├── models.ts |
|
│ │ └── prompts/ |
|
│ │ ├── rag.prompt.ts |
|
│ │ ├── grade.prompt.ts |
|
│ │ └── hyde.prompt.ts |
|
│ ├── embeddings/ |
|
│ │ ├── openai.ts # OpenAIEmbeddings 客户端 |
|
│ │ └── provider.ts |
|
│ ├── reranker/ |
|
│ │ ├── cohere.ts |
|
│ │ ├── cross-encoder.ts |
|
│ │ └── provider.ts |
|
│ ├── chunking/ |
|
│ │ ├── chunker.ts # 分块策略路由 |
|
│ │ └── strategies/ |
|
│ │ ├── fixed.ts |
|
│ │ ├── hierarchical.ts |
|
│ │ ├── markdown.ts |
|
│ │ └── semantic.ts |
|
│ ├── parsers/ |
|
│ │ ├── parser.ts # 解析器接口+工厂 |
|
│ │ ├── pdf.parser.ts |
|
│ │ ├── docx.parser.ts |
|
│ │ ├── excel.parser.ts |
|
│ │ ├── html.parser.ts |
|
│ │ └── markdown.parser.ts |
|
│ ├── vectorstore/ |
|
│ │ ├── milvus.ts # Milvus 客户端封装 |
|
│ │ ├── collections.ts |
|
│ │ ├── schema.ts # 集合 schema |
|
│ │ └── bm25.ts # BM25 稀疏向量 |
|
│ ├── metadata/ |
|
│ │ ├── extractor.ts |
|
│ │ └── filter.ts |
|
│ ├── dedup/ |
|
│ │ └── deduplicator.ts |
|
│ ├── db/ |
|
│ │ ├── postgres.ts # PostgreSQL 客户端 |
|
│ │ └── migrations/ |
|
│ │ └── 001_initial.sql |
|
│ ├── cache/ |
|
│ │ └── redis.ts |
|
│ ├── tracing/ |
|
│ │ └── tracer.ts |
|
│ └── types/ |
|
│ ├── document.ts |
|
│ ├── chunk.ts |
|
│ ├── query.ts |
|
│ └── eval.ts |
|
│ |
|
├── packages/frontend/ |
|
│ ├── package.json |
|
│ ├── tsconfig.json |
|
│ ├── vite.config.ts |
|
│ ├── index.html |
|
│ └── src/ |
|
│ ├── main.tsx |
|
│ ├── App.tsx |
|
│ ├── styles/index.css |
|
│ ├── api/ |
|
│ │ ├── client.ts |
|
│ │ ├── documents.ts |
|
│ │ ├── eval.ts |
|
│ │ └── query.ts |
|
│ ├── components/ |
|
│ │ ├── chat/ |
|
│ │ │ ├── ChatWindow.tsx |
|
│ │ │ ├── MessageList.tsx |
|
│ │ │ ├── MessageBubble.tsx |
|
│ │ │ ├── QueryInput.tsx |
|
│ │ │ ├── CitationPanel.tsx |
|
│ │ │ ├── ConfidenceBadge.tsx |
|
│ │ │ └── FeedbackButtons.tsx |
|
│ │ ├── upload/ |
|
│ │ │ ├── DocumentManager.tsx |
|
│ │ │ ├── DocumentUpload.tsx |
|
│ │ │ ├── UploadProgress.tsx |
|
│ │ │ └── DocumentList.tsx |
|
│ │ ├── eval/ |
|
│ │ │ ├── EvalDashboard.tsx |
|
│ │ │ ├── MetricsChart.tsx |
|
│ │ │ └── ComparisonView.tsx |
|
│ │ └── config/ |
|
│ │ └── ConfigPanel.tsx |
|
│ ├── hooks/ |
|
│ │ ├── useQuery.ts |
|
│ │ ├── useUpload.ts |
|
│ │ └── useSSE.ts |
|
│ └── store/ |
|
│ ├── chatStore.ts |
|
│ └── configStore.ts |
|
│ |
|
└── packages/shared/ |
|
├── package.json |
|
├── tsconfig.json |
|
└── src/ |
|
├── index.ts |
|
└── types/ |
|
├── config.ts |
|
├── chunk.ts |
|
├── document.ts |
|
├── query.ts |
|
└── response.ts |
源码下载:rag-platform.zip
免责声明:本内容来自平台创作者,博客园系信息发布平台,仅提供信息存储空间服务。

+加关注
1
0
« 上一篇: 货代SaaS财务系统实战:如何通过“应收管理”加速资金回笼?
» 下一篇: 从通义到智谱、从裸跑 RAG 到企业级平台:RAG 平台 V2 升级全记录
posted on 2026-05-29 20:38 天涯轩 阅读(397) 评论(0) 收藏 举报
登录后才能查看或发表评论,立即 登录 或者 逛逛 博客园首页
【推荐】 凌霞 618 年中大促,Halo 与 1Panel 产品全线半价,叠加满减!
【推荐】HarmonyOS 6.1.0 创新特性“悬浮页签+沉浸光感”精品文章专题
【推荐】科研领域的连接者艾思科蓝,一站式科研学术服务数字化平台

编辑推荐:
- 让 Agent 在对话中成长:自进化机制的五层实现
- 代码之外:一个技术人的职场困境与自我和解
- 贩卖焦虑的时代,我终于接住了真实的焦虑
- 工良吐槽篇:万字长文细说 AI 落地之笑谈
- 代码是 AI 写的,生产事故谁背锅?
导航

|
|||||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 | |||
|---|---|---|---|---|---|---|---|---|---|
| 31 | 1 | 2 | 3 | 4 | 5 | 6 | |||
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | |||
| 14 | 15 | 16 | 17 | 18 | 19 | 20 | |||
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | |||
| 28 | 29 | 30 | 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | |||
公告
昵称: 天涯轩
园龄: 16年11个月
粉丝: 5
关注: 101
+加关注
搜索
常用链接
我的标签
随笔分类
随笔档案
- 2026年6月(1)
- 2026年5月(3)
- 2025年12月(4)
- 2025年11月(1)
- 2025年10月(3)
- 2025年9月(2)
- 2025年8月(5)
- 2025年7月(1)
- 2025年5月(1)
- 2025年4月(2)
- 2025年3月(2)
阅读排行榜
- 1. 实战:使用 Stagehand + Qwen (通义千问) 实现智能化浏览器自动化(1495)
- 2. LangChain使用MCP,openai和通义千问(543)
- 3. 基于 Feishu 和 LangGraph 构建企业级 AI 助手(427)
- 4. 国际物流数字化运营平台设计文档-AI(406)
- 5. Claude Code + 通义千问,从零搭出生产级 RAG 要花多少钱?(397)
推荐排行榜

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)