
Token 到底是什么?在Claude使用中为什么同样的字数计费能差 6 倍?不同模型还不同?
标签:
Token大模型NLPGLMClaude CodeLLM计费
摘要:每天用大模型都在花 Token,但它到底是什么?为什么不直接按“字”算?为什么同样的汉字,在 GPT、GLM 和 Claude Code 里计费能差出几倍?本文用 4 个核心对比,带你彻底搞懂 Token 的底层逻辑与账单黑洞。
文章目录
现在每天用大模型,尤其是最近GLM5.2出来了,只要在工作,基本都在花 Token。但 Token 到底是什么?为什么不直接按“字”算?为什么不直接给模型看你的字?
这篇我们就用几个最直观的对比,把这些问题一次讲透。
一、为什么不直接用“字”或“词”?
你可能想:直接把汉字一个一个喂给模型不就行了?干嘛还要拆?
答案是:按字拆,模型会崩溃;按词拆,模型会哑火。
锚点一:按字母/字拆,序列太长且没有语义
英文“unhappiness”有 12 个字母。如果按字母拆,模型要处理 12 步才能读完一个词。一篇 1000 词的英文文章,按字母拆变成 5000 到 6000 个单元,计算量直接爆炸。
更致命的是:“u”和“n”分开看毫无意义。
模型得每次重新学“u+n=un=否定”这个关系。就像让你一个笔画一个笔画地读文章,字都认不全,更别提理解了。
锚点二:按“词”拆,词表爆炸且遇到生词就死
那就按整词拆?问题更大。光是英文就有几十万词,加上中文组合、专业术语、网络新词,词表轻松炸到几百万。每个词一个独立编号,模型参数跟着膨胀,训练成本上天。
更致命的是:遇到没见过的词,模型直接罢工。
“DeepSeek”这个词如果词表没收录,模型完全不认识,只能输出一个 <UNK>(未知词标记),一个字都说不出来。
锚点三:Token 才是唯一解
来看四个场景对比:
| 场景 | 按字/字母拆 | 按词拆 | Token(子词) |
|---|---|---|---|
| “中国” | 2 个单元 | 1 个单元 | 1 个单元 |
| “unhappiness” | 12 个单元 | 1 个(如果有收录) | 3 个(un + happi + ness) |
| “DeepSeek”(新词) | 8 个单元 | <UNK> 哑火 |
2~3 个(Deep + Seek) |
| “夔”(生僻字) | 1 个单元 | <UNK> 哑火 |
3 个(字节兜底) |
按字永远太碎,按词遇到生词就死。只有 Token 在每种情况下都能处理。它可能不是最优,但永远不会哑火。 这就是它成为标准答案的原因。
二、Token 拆完之后,模型靠什么“理解”?
锚点一:AI 眼里没有“字”,只有数字
你输入“我今天想吃火锅”,模型看到的是 [163, 5287, 2045, 8906, 6721]。所有人类文字,在进模型之前,已经被 Tokenizer 拆成了一串编号。你以为模型在“读”你的字,它其实在“读”一串整数。
锚点二:编号没用,5287 和 5288 没有近义关系
但光给模型一个编号 6721(火锅),它能理解“火锅”是什么吗?不能。
因为编号只是个身份证号。5287 和 5288 之间,除了数字差 1,没有任何语义关系。你不能因为“火锅”是 6721、“烧烤”是 6722,就认为它俩意思接近。万一“键盘”排在 6723 呢?身份证号只能“找到”一个人,不能“理解”一个人。
锚点三:向量才有语义

所以,编号还得再查一次表,变成一串浮点数——词向量(Embedding)。这才是模型真正“吃”进去的东西:
6721(火锅)→[0.23, -0.15, 0.81, ...]6722(烧烤)→[0.21, -0.13, 0.79, ...]9100(键盘)→[-0.44, 0.62, -0.08, ...]
向量不是随便编的。在预训练阶段,模型已经学会了让意思相近的词,向量也相近。“火锅”和“烧烤”的向量挨得很近,“火锅”和“键盘”隔得很远。模型靠的不是编号理解词义,靠的是向量之间的距离。
完整链条:你打的字 → Tokenizer 拆成 Token → 查词表得到编号 → 查向量表得到 Embedding → 模型靠向量距离理解语义。
三、同样的字,凭什么不同模型花出的 Token 差这么多?
Tokenizer 不是“按字收费”,是“看身份收费”。而且,不同的模型,词表是不一样的。 同样一段中文,在 GPT、GLM 和 Claude 里的账单可能完全不同。
锚点一:中文压缩率(GPT vs GLM)
如果你让模型处理大段中文,你会发现国产模型通常更省钱。
- GPT 的“零售价”:早期 GPT 的词表以英文为主。遇到中文,很多常见词没被合并,只能拆碎了算。比如“火锅”,在某些英文模型里可能被拆成 2 个甚至 3 个 Token。
- GLM 的“团购价”:像智谱的 GLM 系列(如 GLM5.2),专门对中文词表做了深度优化。大量中文高频词(如“中国”、“火锅”、“人工智能”)都被收录为单个 Token。
- 结果:处理同样的 1 万字中文,GLM 消耗的 Token 数通常显著低于纯英文底层训练的模型。
锚点二:生僻字与代码(Claude Code 怎么算?)
到了写代码或者遇到生僻字,情况又变了。
- 生僻字退回字节:“夔”这个字太生僻,绝大多数词表都没收。Tokenizer 只能退回到字节级别。一个汉字在 UTF-8 里占 3 个字节,于是被拆成 3 个 Token。买一个东西被拆成零件,每个零件单独收费。
- Claude Code 的代码优势:当你在 IDE 里使用 Claude Code 等专门为编程优化的 Agent 时,它们对代码的 Token 化极其高效。它们会把常见的代码片段(如
public static void main或大量的缩进空格)压缩成极少的 Token,但在处理大段中文自然语言时,压缩率可能不如本土的 GLM。
| 场景 | 例子 | 汉字/字符数 | Token 消耗预估 | 计费逻辑 |
|---|---|---|---|---|
| 🟢 中文高频词 | 中国 | 2 | 1 (GLM 等优化模型) | 词表收录,享受“团购价” |
| 🟡 一般中文 | 火锅 | 2 | 2 (部分海外模型) | 没被合并,按单字“零售” |
| 🔴 生僻字 | 夔 | 1 | 3 (退回字节) | 词表不认识,被拆成零件卖 |
| 🔵 代码块 | function() |
10 | 1~2 (Claude Code 等) | 针对代码特化,极致压缩 |
一篇 1000 字的文章,全用常见词组可能只花 600 个 Token,塞满生僻字可能花 2000 个。如果你在不同的平台上跑(比如拿 Claude 跑中文小说,拿 GLM 跑英文代码),账单的差距会更加离谱。
四、Token 怎么变成你的账单?
最后一步:Token 数怎么变成钱。用餐厅比喻,账单里藏着五项费用: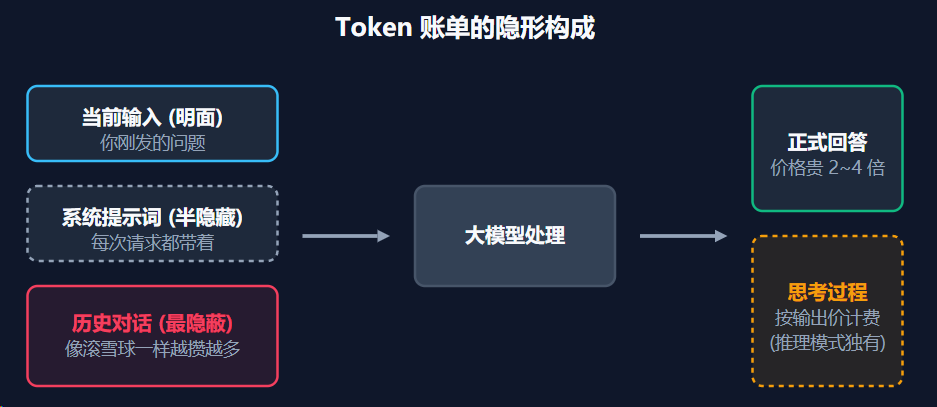
| 费用项 | 餐厅比喻 | 计价 | 隐藏程度 |
|---|---|---|---|
| 输入 Token | 你点的菜 | 输入价(便宜) | 明面 |
| 输出 Token | 厨师做的菜 | 输出价(贵 2~4 倍) | 明面 |
| System Prompt | 茶位费 | 输入价,每次都收 | 半隐藏 |
| 历史对话累积 | 之前的菜反复端上桌 | 输入价,滚雪球 | 最隐蔽 |
| 思考 Token | 厨师试菜过程 | 输出价,可能比答案还长 | 半隐藏 |
账单里最刺人的三个黑洞:
- 你说的便宜,它说的贵。输出 Token 单价是输入的 2~4 倍,因为“写”比“读”费算力。
- 历史对话是最大的坑。模型没有记忆。每次你发新消息,之前所有的对话历史都会重新打包发给模型。第 1 轮输入 100 个 Token,第 10 轮可能变成 2000 个。你每说一句话,之前说过的每个字都在反复计费。
- 模型“思考”也要钱。开了深度推理模式(如 DeepSeek-R1)后,模型在正式回答前会先“想”一遍。这段思考也是 Token,按输出价算,有时比最终回答还长。
收尾:全文一张表
| 核心问题 | 答案 | 记忆锚点 |
|---|---|---|
| 为什么不直接用字? | 太碎没语义,序列太长 | “unhappiness” 按字母拆=12 个单元 |
| 那按词呢? | 词表爆炸,生词哑火 | “DeepSeek” 没收录 → <UNK> 说不出话 |
| 为什么用 Token? | 什么都能拆,永远不罢工 | 只有 Token 列没有哑火 |
| 模型靠什么理解? | 不是编号,是向量 | “火锅”靠近“烧烤”,远离“键盘” |
| 不同的模型差多少? | 词表不同,计费天差地别 | 中文用 GLM 省钱,写代码用 Claude Code 高效 |
| 账单上有什么? | 五项费用,三项隐藏 | 历史对话 = 之前的菜反复端上桌 |
你打的是字,拆的是 Token,理解的是向量,花的是钱——而每一步都有你看不见的折损和加价。这就是 Token 的完整一生。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)