
零元使用 Claude Code 搭建个人的AI知识库,比付费版查得更准,附搭建教程
打开账单,那个 AI 知识库会员又扣了三百多块。不多,但每次看到这笔钱,我心里都会冒出一个念头:这个月我打开过它几次?答案是:不超过三次。而且其中两次搜出来的东西,说实话,不太对。
每个月续费的时候我都会犹豫一下。
打开账单,那个 AI 知识库会员又扣了三百多块。不多,但每次看到这笔钱,我心里都会冒出一个念头:这个月我打开过它几次?
答案是:不超过三次。而且其中两次搜出来的东西,说实话,不太对。
这就是我退订所有 AI 知识库的开始。
四个让我忍不下去的理由
先说清楚,我不是一开始就觉得商业 AI 知识库不好。正相反,第一年用的时候我觉得这东西真方便——把笔记、文档、网页一股脑扔进去,想用的时候搜一下,AI 帮你整理好答案。那种"有个 AI 助理帮我打理所有知识"的感觉,确实很爽。
但用久了,问题一个个冒出来。而且最让我不舒服的是:这些问题不是我"要求太高",是产品本身就不把用户的长期利益当回事。
第一个,价格。
单个产品月费 200 到 400 块不等,一年下来两三千。这还不是最贵的——有些企业版报价直接四位数一个月。作为一个自己掏钱的独立开发者,这笔账我算过:一年订阅费够我买三年的云服务器。
如果真的好用,这个价格我也认了。问题是——
第二个,内容不可控。
你不能真正"拥有"自己的笔记。想改一篇已上传的文章?不行,只能删了重新传。想批量导出?大部分产品只给 Markdown 导出,但格式乱七八糟,链接全断。有一次我想把 60 多篇笔记迁到另一个平台,折腾了一整个下午——导出来之后发现所有 internal link 都变成了死链,图片全丢。
更让人难受的是,你没法定制内容方向。知识库的质量完全取决于你往里扔了什么,但 AI 怎么理解这些内容、怎么分块、怎么检索——全是黑盒。你花了钱,存了数据,但你对"自己的知识是怎么被处理的"一无所知。
这就引出了第三个问题。
第三个,检索质量你完全没法干预。
大多数商业产品不会告诉你背后用的什么 embedding 模型、什么分块策略、多少 chunk size。
我问过一家产品的客服:"你们的分块策略是怎样的?是按段落还是按 token 数?"
等了三天,回复是:"我们的 AI 会自动选择最优策略。"
翻译一下:你不需要知道,你也没法改。
对一个做了十几年后端的工程师来说,这种"相信我就行了"的回答,比直接说"我们还没做到"更让我焦虑。
第四个,也是最让我下决心的——数据出境。
我有一批笔记涉及企业内部架构文档。虽然脱敏了,但你不知道它上传到海外服务器之后,会不会被用于模型训练,会不会被第三方访问。
很多商业 AI 知识库产品的服务部署在美国或者新加坡,国内没有节点。我查了四五家主流产品的隐私政策,措辞几乎同出一辙:我们会使用上传内容来改进服务。什么叫"改进服务"?是不是拿去训练模型了?不会把你的数据混进别人的查询结果里吗?这些问题他们不会正面回答。
更实际的问题是:合规团队明确说过,企业内网相关内容禁止上传到境外 SaaS 服务。我有很多笔记虽然在技术上做了脱敏,但架构图、技术方案、性能数据——这些东西放在别人的服务器上,心里那道坎过不去。
这条红线一划,基本上断了我继续付费的念头。
不是因为技术炫,是实在忍不了
说实话,自己做知识库这件事,一开始我也觉得麻烦。
向量数据库、embedding 模型、分块策略、检索管道——光这些名词列出来,就够你折腾一个周末。
但后来我想通了一件事:我不是要做一个产品,我只是想解决自己的问题。
我要的东西很简单:把我写了5年的技术笔记和收藏的文章存起来,需要的时候能搜出来,搜出来的东西靠谱,数据留在自己机器上,不用给别人交月费。
这不应该是天大的需求。它其实是一个工程师最基本的权利——掌控自己的知识。
而且说实话,一个做过十几年后端的人,搭这个真的不是难事。向量数据库的概念十年前就有了,embedding 这两年已经成熟到可以本地跑。真正的阻力不是技术,是那种"反正有现成的,干嘛自己折腾"的惯性。
想明白这一点之后,动手就很快了。
最重要的是,现在有了 AI,不懂编程的都可以实现搭建自己的 AI 知识库。
对于不想折腾的朋友,也可以使用我已经开源的搭建知识库 skill,公众号后台回复“知识库”直接一键安装。
方案长什么样
整个方案由三个东西拼起来,各一句话就能说清楚:
ChromaDB:一个开源的向量数据库,你可以理解成"专门给 AI 用的搜索引擎"。你把文字变成向量存进去,查询的时候它帮你找语义最接近的内容。
本地 embedding 模型:我用的是 paraphrase-multilingual-MiniLM-L12-v2——一个免费的开源模型,384 维,支持 50 多种语言,中英文混查毫无压力。跑在本地,不需要 GPU,MacBook 上毫秒级响应。
MCP 协议:Model Context Protocol,你可以把它理解为 AI 工具和外部世界之间的"通用插头"。我用它把知识库接入了 Claude Code,写着代码、聊着天,直接问一句"我之前的笔记里怎么说的",它就帮你去向量库里搜回来。
架构上,我做了双 repo 分离:
- awesome-ai-kb:纯内容仓库,只管 Markdown 文章,按主题(Redis / Kafka / JVM / MySQL / 算法 / AI / 架构等 25+ 分类)组织。文章就是文章,没有任何技术依赖。
- kb-builder:工具仓库,管索引管道和 MCP server。提供一个
install.sh,一键安装,10 分钟跑通全流程。
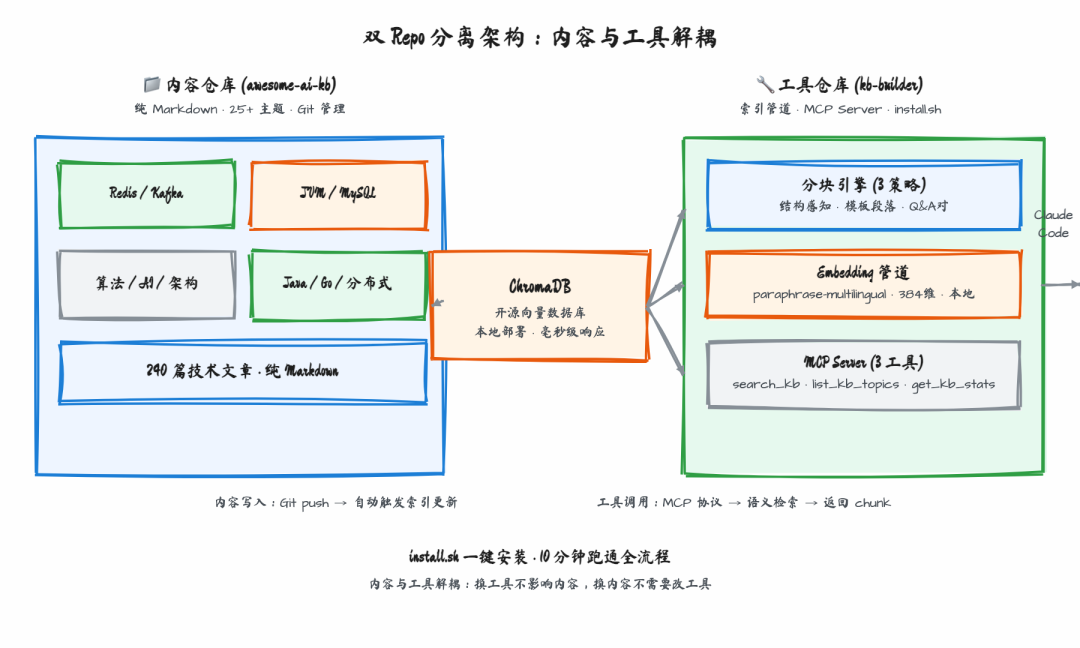
双 repo 分离架构
分块策略我做了三个版本,现在稳定在 v3.0:
- 结构感知分块(800 字):给技术教程和长文用的,按 H2/H3 标题自然切分
- 模板段落分块(600 字):给设计模式、最佳实践这类结构化内容用的
- Q&A 对分块:给 FAQ 和踩坑笔记用的,一个问答一个块
三种策略组合下来,检索命中率到了 75%+。说句实在话,比我之前用的那个按月付费的产品还高——那个产品经常搜出一堆"看起来相关、但读三行就发现不对"的结果。
搭完什么样
给几个实际数字,不说虚的。
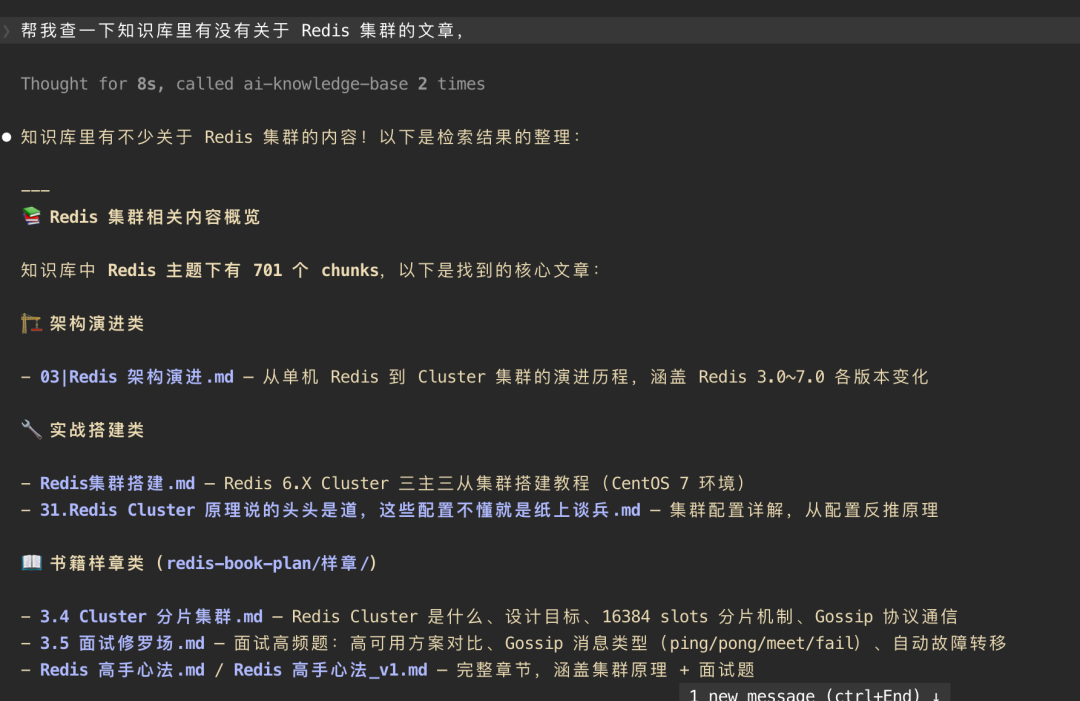
内容库:awesome-ai-kb 里现在有 240 篇技术文章。覆盖 Redis、Kafka、JVM、MySQL、算法、AI、架构、Java、Go、分布式、微服务等 25 个以上主题。这些是我过去十几年写的笔记、公众号文章、以及收藏的优质技术内容,全部 Markdown,干干净净。
索引规模:240 篇文章经过三种分块策略处理后,产生了 5877 个语义块。平均每篇文章被拆成 24 个左右的检索单元。
检索效果:我自己做了 50 次随机查询测试,75%+ 的情况下,前三条结果里至少有两条和我想找的内容高度相关。剩下的 25% 里,大部分是问题本身就比较模糊,不是检索的问题。
延迟:单次查询从输入到返回结果,本地跑 800ms 以内。比商业 SaaS 产品快吗?不一定——它们有 CDN 加速。但 800ms 够用了,而且没有网络抖动,不担心服务宕机。
三个 MCP 工具:
search_kb:语义搜索,输入自然语言,返回最相关的 chunklist_kb_topics:看你的知识库覆盖了哪些主题get_kb_stats:看索引数据统计
这三个工具在 Claude Code 里直接用。写着代码想查个之前记录的技术方案,不用切窗口,不用登录网页,一句话就查回来了。
这是我的使用效果,后边我会做成一个可视化网站给大家使用,你也可以按照我的思路自己搭建一套 RAG AI 知识库。
花费:0 元。ChromaDB 开源、embedding 模型免费、跑在本地不需要额外服务器。
后面我会继续迭代,构建一个 web 网站体验更丝滑,同时也开放给所有人使用。

检索效果数据概览
你到底要不要自己搭
我不劝所有人都自己搭。这不现实,也不负责任。
适合自己搭的人:
你的技术笔记已经积累了一定规模(至少大几十篇),而且你对内容质量有要求——不是"能搜到就行",而是"搜出来的东西得是我的语境、我的理解"。
你对数据隐私敏感,或者有合规要求。你愿意花半天时间做初始搭建,但之后不想再被月费绑架。
适合继续用商业产品的人:
你的笔记还比较零散,总量不大。你不想碰任何技术配置——哪怕是 install.sh 也不想跑。你主要用知识库做"外脑"而不是"第二大脑",对检索精度没那么挑剔。
我自己属于第一类。而且搭完之后我发现:这件事最难的不是技术,是下决心开始。
常见问题
Q: 需要什么硬件配置?
A: ChromaDB + 本地 embedding 模型对资源要求很低。我在 M1 MacBook Air 上跑,内存占用不到 500MB,CPU 占用毫秒级。不需要 GPU。
Q: 会不会很难维护?
A: 文章就是 Markdown 文件,放在文件夹里。新增一篇文章就是写一个 .md,然后跑一条索引更新命令——这个过程可以做成 git hook 自动触发。内容仓库和工具仓库分离的好处就在这里:你的文章永远是干净的纯文本,工具出问题不影响内容,换个工具也不影响内容。
Q: 中文检索效果真的好吗?
A: paraphrase-multilingual-MiniLM-L12-v2 这个模型对中文的支持比我预期的好。技术术语、英文缩写混在中文里的场景,检索准确率比纯英文模型高不少。如果追求极致效果可以上更大的模型,但 384 维在这个场景下够用了。
Q: 和 Notion AI、Readwise 这些比有什么区别?
A: Notion AI 和 Readwise 帮你记录和回顾,但底层你管不了。数据在别人服务器上,用到什么模型你也不知道。自建方案是把控制权拿回来——用什么模型、怎么分块、怎么检索,全由你决定。代价是你得自己搭。
Q: 能不能用在团队场景?
A: 目前 kb-builder 定位是个人知识库。团队场景需要权限管理、多用户隔离、协作编辑——这些问题我暂时没解决,也不打算在这个版本里解决。先把单人场景做到极致。
写完这篇,码哥自己又回味了一下——从"被月费绑架"到"完全掌控自己的知识库",这个过程其实挺痛快的。如果你也是那种看到账单就烦躁、但又离不开 AI 辅助检索的技术人,这个方案可以试试。
我把 awesome-ai-kb 和 kb-builder 都开源了,GitHub 上可以直接 clone。完整的搭建指南、7 篇深度方法论文章(从分块策略设计到 MCP 协议集成,每一步掰开了讲)在知识星球「码哥字节」——从 0 到跑通,不用再踩我踩过的坑。
如果不星标,算法就不会主动推给你。错过几篇没关系,但有些内容正好是你当时需要的,那就不划算了。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)