
AWM-Fuse:基于全局与局部文本感知的恶劣天气多模态图像融合
AWM-Fuse: Multi-Modality Image Fusion for Adverse Weather via Global and Local Text Perception
作者:Xilai Li, Huichun Liu, Xiaosong Li*, Tao Ye, Zhenyu Kuang, Huafeng Li
单位:佛山大学、中国矿业大学(北京)、昆明理工大学
期刊:IEEE TIP, 2026
DOI:10.1109/TIP.2026.3690324
代码:https://github.com/Feecuin/AWM-Fuse
1. 全文概述与创新点
多模态图像融合(MMIF),其目的是把红外和可见光这两种信息结合起来,在恶劣天气状况下,让那些已经退化的视觉内容得以恢复,进而呈现出更为清晰的场景表征。已有的相关方法,虽然试着引入文本信息,可是却欠缺对文本内容进行有效的分类、充分的利用。AWM-Fuse 采用具有共享参数的统一框架来处理多种退化情况:全局模块依靠 BLIP 所生成的描述来掌握整体场景、主要的退化类型,局部模块依据 ChatGPT 所生成的细节描述,将重点放在具体的退化效果上以便恢复细节,同时利用文本对融合图像的生成加以约束,引导网络去学习更具意义的视觉特征。作者另外还建立了规模较大的文本基准 AWMM-Text。
- 统一的全/局文本感知框架:研发了 AWM-Fuse,该模型在统一的共享权重架构里,同步运用全局、局部文本感知能力,以此来应对雨、雾、雪等多种不同类型的退化情况。
- 双层文本感知模块:引导特征提取工作从宏观跟微观这两个方面来进行,在关注泛化能力的同时注重高保真融合(其中 GTPM 具有稳定全局感知的作用,LTPM 能够强化局部细节恢复)。
- VLM 驱动的损失函数:借助 CLIP 具备的图文匹配能力,把融合之后的结果同「干净图像」的文本描述于共享空间里进行对齐,以此提高跨天气情况下的鲁棒性、适应性。
- AWMM-Text 基准:最初出现的是一个大规模文本基准,该基准能够针对恶劣天气下的多模态图像对给出有着「全局 + 局部」特点的配对标注。
2. 核心方法
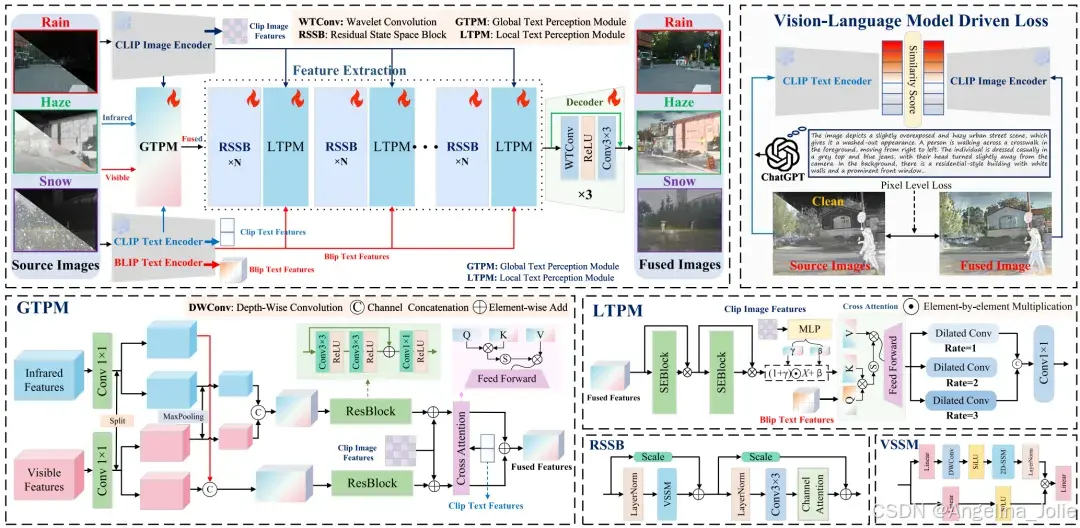
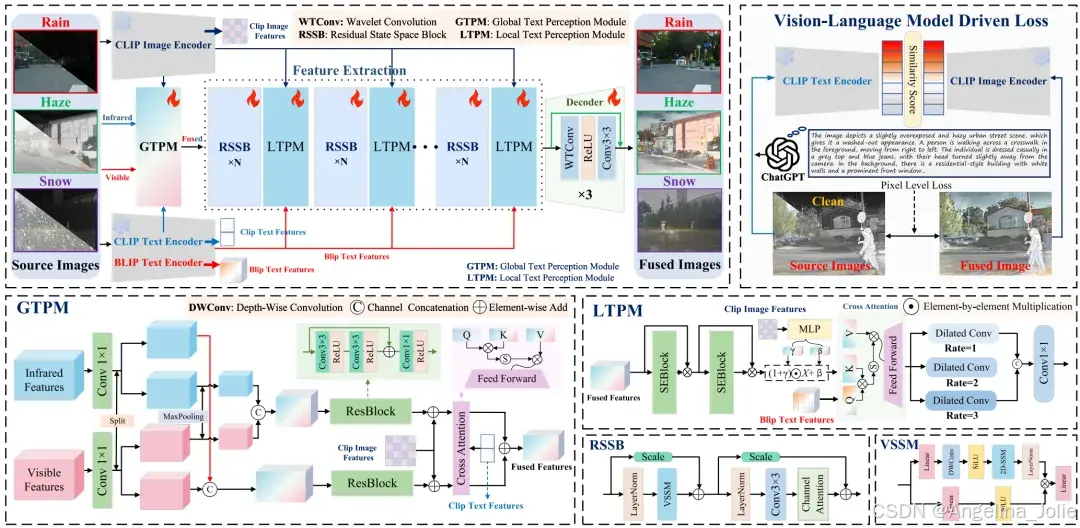
该框架把多尺度文本建模当作核心内容,有着四个主要构成部分,分别是全局文本感知模块也就是 GTPM、残差状态空间块即 RSSB、局部文本感知模块也就是 LTPM,还有基于小波卷积即 WTConv 的解码器。文本在全局、局部这两个方面进入到视觉融合过程里,借助语义一致性监督来抑制融合过程当中的语义漂移现象。
▍全局文本感知模块 GTPM
以利用 BLIP 生成的描述作为文本输入,并且融合 CLIP 编码的源图特征。红外、可见光特征经过 1×1 卷积对通道进行扩展之后,被划分成左右两个部分来进行多尺度融合,其中左半部分直接进行拼接,右半部分先进行最大池化操作然后再拼接,以此同时捕捉细粒度的细节内容、更大范围的上下文信息。文本特征作为 Query,图像特征作为 Key/Value,借助交叉注意力来自适应定位文本对应的图像区域,从而提供稳定的场景级先验。
▍局部文本感知模块 LTPM
在 RSSB 之后,利用 ChatGPT 生成的目标属性、运动状态、局部退化的细节描述会着重关注显著区域。融合特征会先通过两层 SEBlock 来强化局部表征,之后运用 MLP 将 CLIP 图像特征投影到融合特征语义空间进行缩放和偏置调制。接着,与 BLIP 编码的细节文本进行交叉注意力操作,再使用具有三种膨胀率的膨胀卷积提取多尺度特征并拼接输出,以此来达成精细的细节恢复。
▍VLM 驱动损失与总损失
把融合之后所得到的结果传送到 CLIP 图像编码器当中,同时把「干净多模态图像」的相关描述传送到文本编码器里面,借助余弦相似度来衡量图文内容的一致性,进而得到 VLM 驱动损失 LVLM。此外引入像素级损失:颜色一致性 LColor、L1 损失 LL1、结构相似度损失 LSSIM。总损失为四者之和:LTotal= LVLM+ LColor+ LL1+ LSSIM。
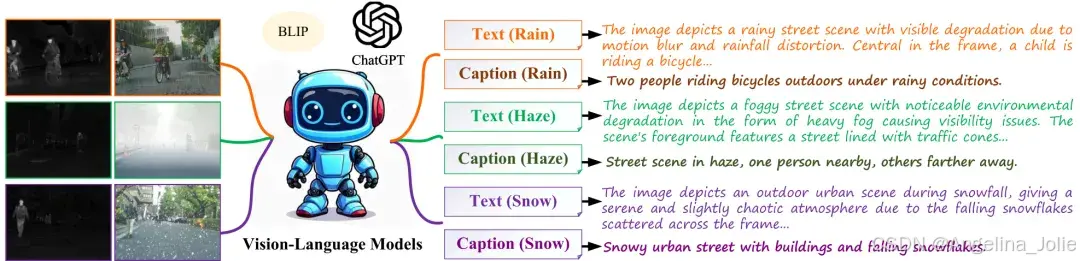
▍AWMM-Text 基准
针对退化与干净这两种设定下的图像对,给出「全局描述 + 局部细节描述」这样的配对标注。其中细节描述是由 ChatGPT-4 生成然后截断,以此来适配 CLIP 文本编码器,而全局描述则是由 BLIP 生成。总共为 8500 对恶劣天气图像、它们对应的干净图像生成文本,并且采用分层随机抽样的方式,对大概 30% 的文本进行人工审核,按照明确的通过或者拒绝规则,筛除掉那些不可观测、存在误描述、漏检关键目标、格式不符合要求或者过于泛化的文本。
实验
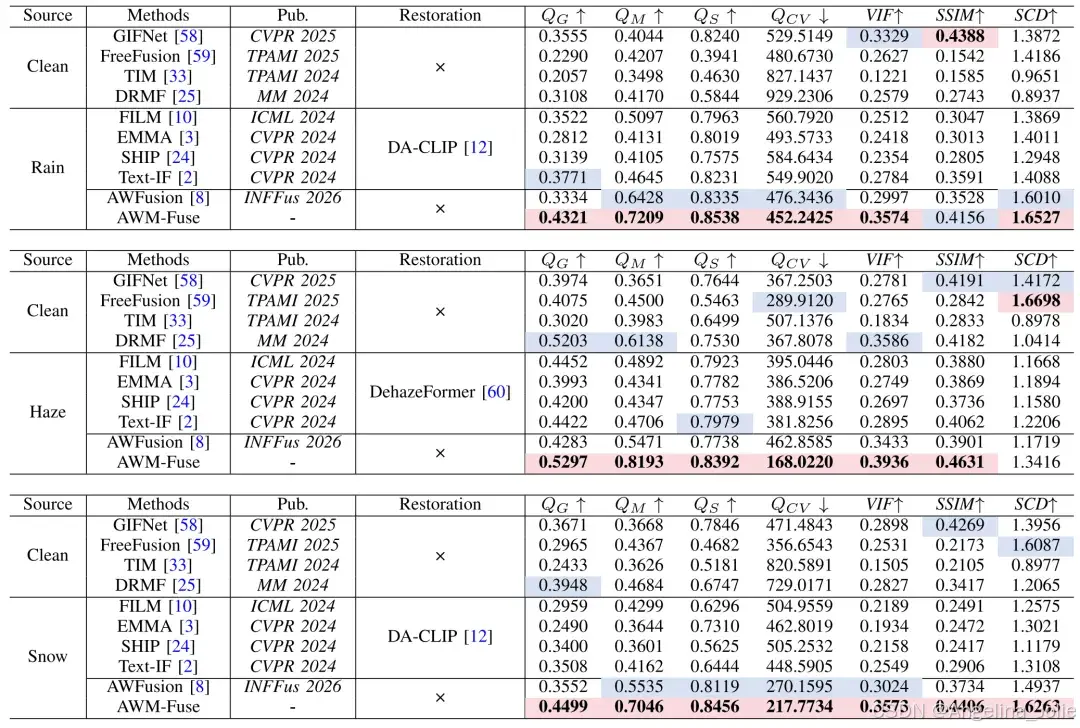
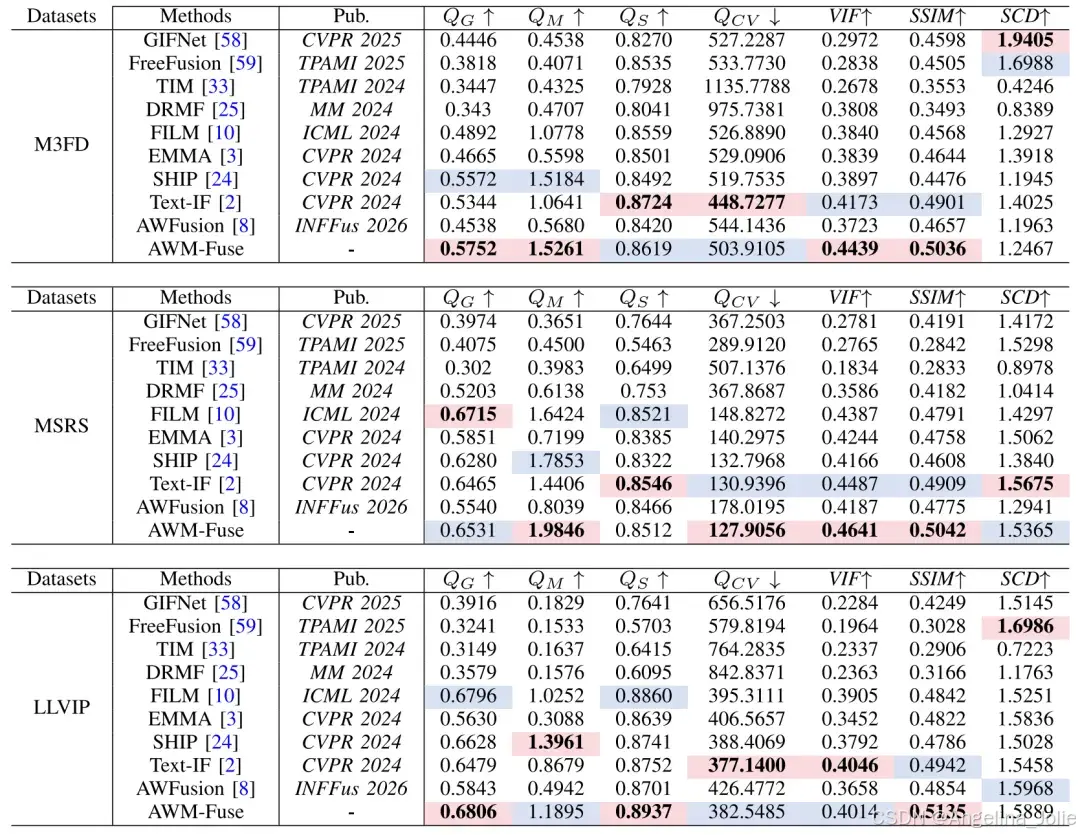
在 AWMM-100k 数据集上展开评测工作(其中雨、雾、雪天气各自随机选取 50 对样本),将其与 9 种 SOTA 方法相互比较,涉及标准 IVIF、文本引导融合、面向复杂/恶劣场景这三类基线。在进行训练的时候,从三类天气里分别选取 700 张图片,按照「雨→雾→雪」这样固定的循环方式组成 2100 对,之后把这些图片裁剪成 160×160 的规格,运用 Adam 优化器,设置初始学习率为 1×10⁻³,训练超过 300 轮。采用 QG、QM、QS、QCV、SCD、VIF、SSIM 共 7 项客观指标。
恶劣天气下的融合
在定性方面,AWM-Fuse 在去除图像退化、保持颜色保真、提取多模态信息这些方面有着比较突出的表现。通过差异图可以看出,它能够保留大部分场景特征,就算是面对干净图像时,也能维持高质量的融合效果。从定量角度来看,在三类天气导致图像退化的情况下,这种方法在全部 7 项指标里的排名都处于前两位,比在雨/雪场景中表现不错的 AWFusion 还要优异,特别是在图像质量、颜色恢复这两方面表现更为出色。



标准数据集与下游任务
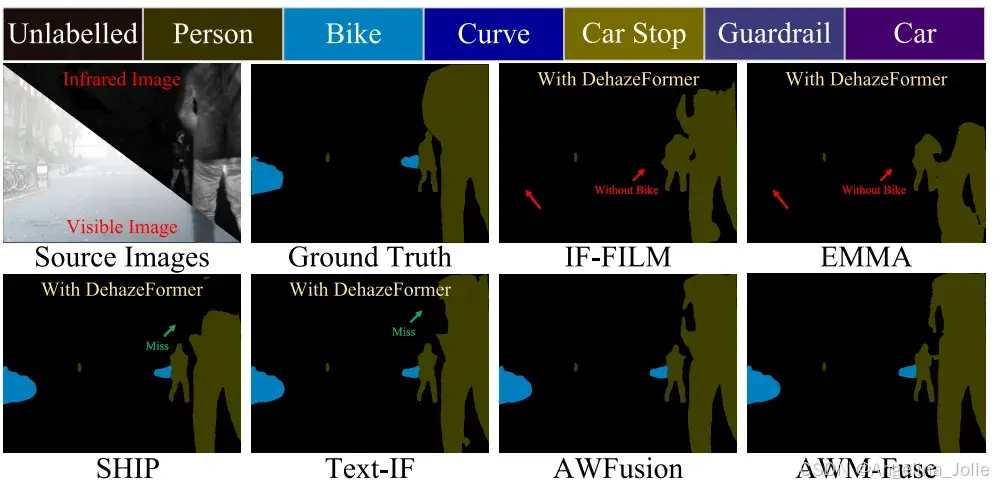
于 M3FD、MSRS、LLVIP 这三个无退化标准数据集之上(相关数据呈现在表 2 当中),本方法的多项指标相较于多数基线表现更为出色,这意味着其于无退化场景之中依旧具备较强的融合能力。在下游任务里面,运用 BANet 进行语义分割工作、借助 YOLOv7 进行检测:语义分割方面(具体内容列于表 3)获取了各类别的最高 IoU、最高 mIoU,目标检测方面(相关数据展示于表 4)取得了最高的检测精度。



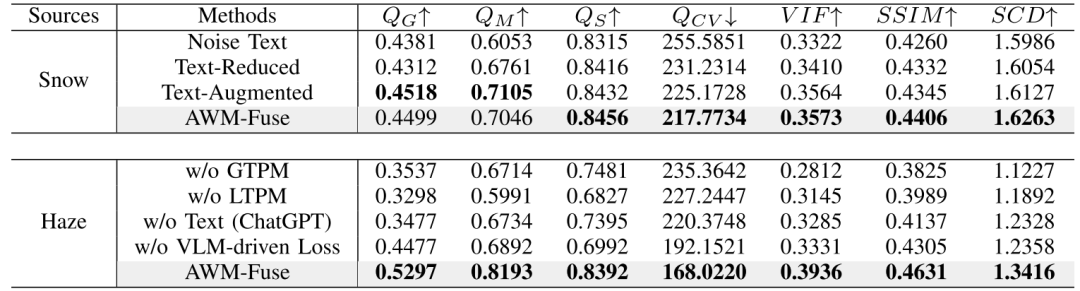
消融与鲁棒性
文本消融包括噪声文本、错误场景文本、文本削减、文本冗余,其显示出错误引导的文本致使性能下降最为严重;削减文本会降低 QS、QM;冗余文本虽提升 QS、QM却损害 QCV、VIF。当出现完全错误提示时,雨、雾、雪的平均指标都有了一定程度的下降,其中雨的平均指标下降了约 7.66%,雾的平均指标下降了 37.81%,雪的平均指标下降了 14.16%,在这当中雾天所受影响相对较大,不过模型没有崩溃,依旧能保留关键目标——这说明文本主要起辅助引导作用,融合内容仍然由红外与可见光特征主导。GTPM 与 LTPM 的消融实验表明二者具有互补性:GTPM 能够让全局感知、策略选择保持稳定(VIF、SCD),LTPM 则能够改进局部结构与细节(QM、QS),结合后效果最佳。



总结
本文反映了一种面向恶劣天气的多模态图像融合方法,即 AWM-Fuse。该方法借助 ChatGPT 的图生文能力,为退化的源图生成细节方面的描述,同时运用 BLIP 生成关于全局的描述,并且设计了全局、局部文本感知模块来对这些描述加以利用。此外,提出了 VLM 驱动损失,以在 CLIP 空间实现图文特征的对齐。还建立了大规模文本基准 AWMM-Text。通过在恶劣天气、干净场景、下游任务上展开的大量实验,验证了此方法的有效性。
作者还指出了存在的局限之处,即运用 VLM 提取特征会产生额外的计算开销,在输入为 480×640 的情况下,其 FLOPs 达到 1145.5G、参数为 137.29M,这里面 LTPM 是主要的开销来源,后续会对计算效率予以优化。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)