
Codex 史诗级bug在后台疯狂写盘,我的 SSD 差点被它磨穿

这两天我在排查一个特别离谱的问题:Codex 用着用着,机器开始莫名其妙变卡,切会话慢、响应慢,甚至连我平时很稳定的系统盘都出现了持续写入异常。
一开始我还以为是项目太大、会话太多,结果一查才发现,罪魁祸首居然是 Codex 自己本地的 SQLite 日志库。
更夸张的是,这不是“偶发写一下”,而是持续高频写盘。
如果你也是高频跑 Codex、开流式输出、跑自动化任务,那这件事真的值得第一时间检查。
先说结论
我最后确认,问题点就在 ~/.codex/logs_2.sqlite。
这个文件在 TRACE 日志场景下会持续写入,而且写入行为不是静态的,而是带着 WAL 一起刷盘,久了以后,SSD 的写入量会非常吓人 。
我实际测下来,短短 15 秒内,MAX(id) 就增加了 2,978,TRACE 还占据了最多的日志量,处理前 WAL 已经到 46,601,352 字节 。
这基本就坐实了:不是电脑慢,是它在后台疯狂“磨盘”。
我是怎么发现的
最开始我注意到的是 Codex 的体感变化。
打开会话、切换任务、甚至一些原本很快的操作,开始变得有点拖沓。
这类问题最烦的地方就在于,它不会直接报错,也不会弹窗提醒你“我正在狠狠干盘”。
它就是安安静静在后台写日志,直到你某天突然发现 SSD 健康度和系统流畅度都开始不对劲。
我先去看了本地日志库,路径很明确:
~/.codex/logs_2.sqlite
然后我查了日志级别分布,TRACE 的占比明显偏高。
这就已经很可疑了,因为 TRACE 本身就意味着它会记录大量内部细节,写入量自然会很夸张 。
这个 bug 为什么危险
很多人第一反应会说:
“日志而已,能有多大影响?”
问题是,这次不是普通日志。
它的风险在于写入频率、写入粒度、以及 WAL 机制叠在一起,最后形成了明显的写放大。
你盯着主数据库文件大小,可能觉得没怎么涨。
但实际上,WAL 在持续写,底层 SSD 的 TBW 早就在悄悄消耗了 。image.jpg
这也是为什么这类问题很阴:
它不是一次性炸,而是持续消耗,等你意识到的时候,已经写掉一大截寿命了。
我的修复过程
我这次没有直接删库,而是按照“先备份、再止血、最后验证”的思路来处理。
这套流程比较稳,也方便后面回滚。
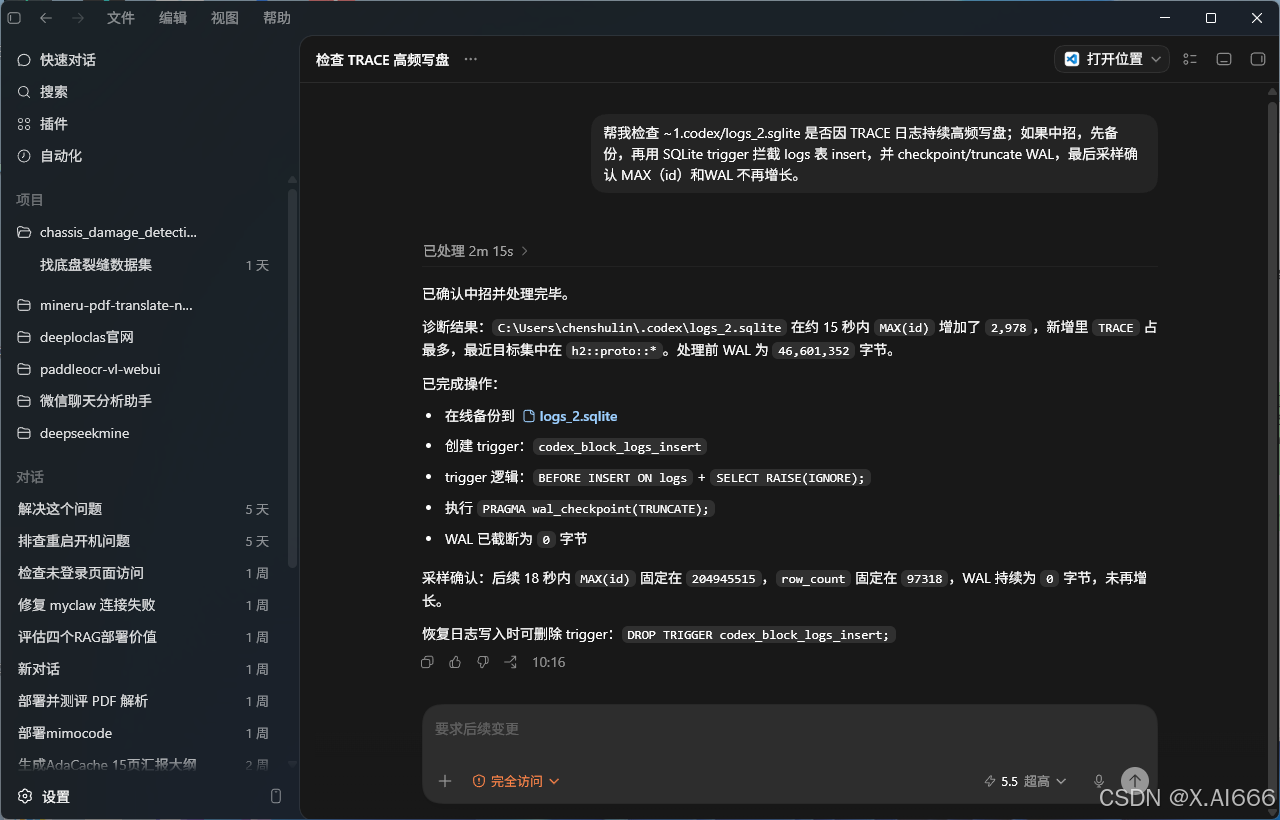
实际采样结果是,后续 18 秒内 MAX(id) 固定在 20,494,551,row_count 固定在 97,318,WAL 也持续保持 0 字节,没有再增长 。
这说明 trigger 确实把持续写盘拦住了,修复结果是成立的。
我踩过的坑
这次排查里我最大的一个坑,就是一开始太相信“文件大小”了。
看起来数据库没长多少,就误以为问题不大。
但真正的杀伤点不是主库文件大小,而是WAL + 高频写入。
所以如果你只是看目录大小,很容易低估真实写盘量 。
第二个坑是,我一开始还怀疑是不是别的会话或者插件导致的。
后来实际采样后发现,关键症状都集中在这个 SQLite 日志库上,基本可以排除大部分误判。
现在该怎么做
如果你现在也在高频用 Codex,我建议你一键用我这个命令修复
帮我检查 ~1.codex/logs_2.sglite 是否因 TRACE 日志持续高频写盘;如果中招,先备份,再用 SQLite trigger 拦截 logs 表 insert,并 checkpoint/truncate WAL,最后采样确认 MAX(id)和WAL 不再增长。
这个流程不复杂,但很实用。
至少在官方修复出来之前,它能先帮你把 SSD 保下来。
写在最后
说实话,这次我最大的感受就是:
AI 工具现在越来越强了,但本地工程实现如果出问题,照样能把用户硬盘写穿。
所以别只盯着模型效果,也要盯着它背后的日志、缓存、状态库。
很多“看起来只是个小 bug”的东西,最后都可能变成实打实的系统事故。
这次 Codex 的问题,对我来说就是一个很典型的提醒:
工具再智能,底层写盘失控,一样能把体验和硬盘一起搞崩。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

{kind=link}
所有评论(0)