
Codex 会把磁盘给烧了?完整复盘来了!
这两天 Codex 圈子里有个说法挺吓人:
高强度用 Codex,尤其是长时间跑 Agent,~/.codex/logs_2.sqlite 可能会持续写盘。文件看起来只是几百 MB,SSD 实际写入量可能已经被拉高很多。
我一开始也觉得这事儿有点夸张,直到我顺手查了一下自己的机器。
~/.codex/logs_2.sqlite 约 823M
~/.codex/logs_2.sqlite-wal 约 38M
logs 表保留行数 61,418
TRACE 估算内容 70.6 MiB
15 秒内 MAX(id) 增加 10,364
保留行数变化 0
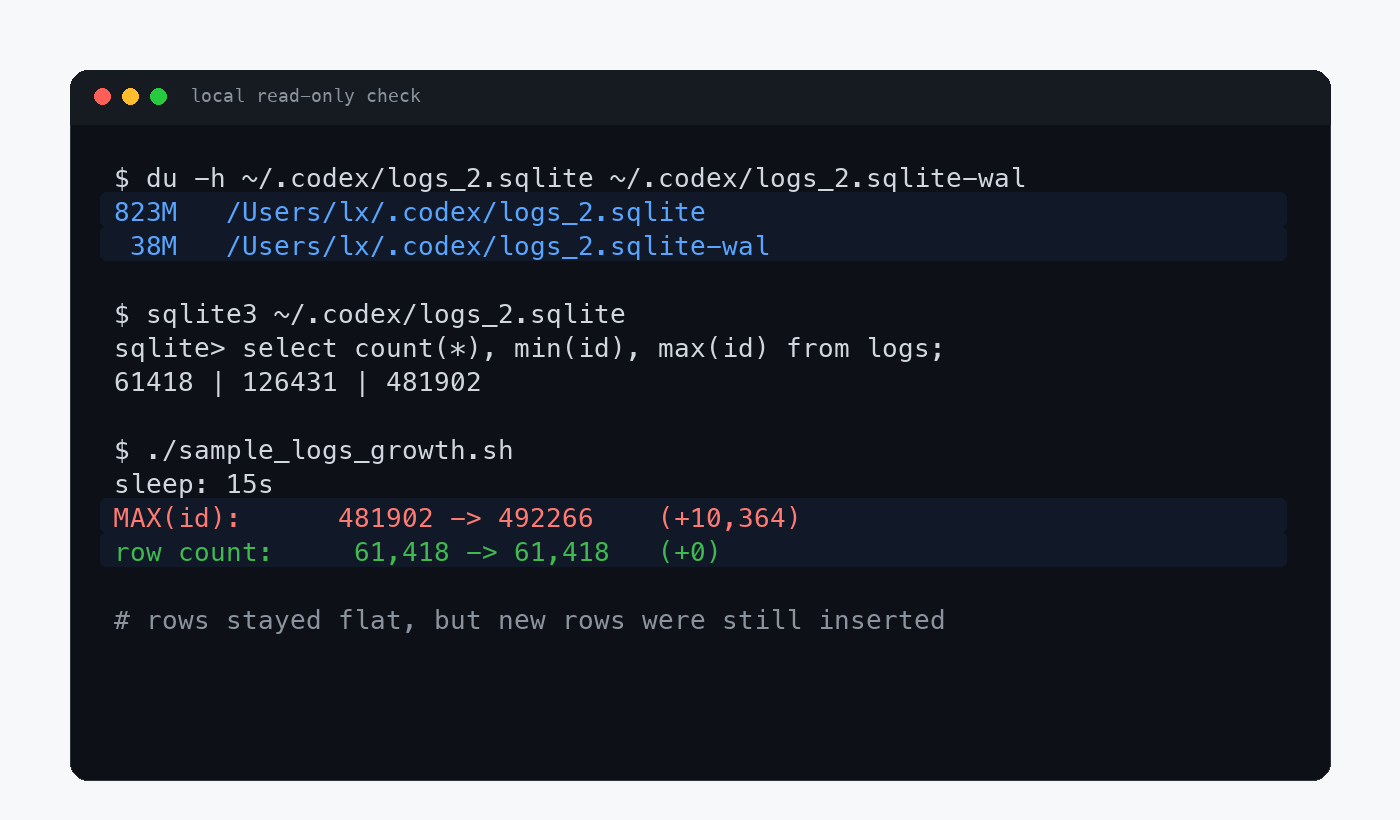
根据本机 ~/.codex/logs_2.sqlite 只读采样整理
大家注意一下最后两行的数据。
表里保留的行数没变,MAX(id) 却在 15 秒内涨了一万多。
简单讲,Codex 还在不停的写新日志,同时把旧日志替换。虽然你看数据库没怎么变大,但磁盘已经被反复写了一轮又一轮了。
不过从实际情况上来讲,实时写日志本身很正常,保留最近一段日志也正常。
但是这次麻烦的是,很多 TRACE 级别的小事件也被写进本地 SQLite 了,写完还会删旧记录。表面只保留几万行,底层磁盘一直在干活。
所以现在的问题不是日志行数没有增加,也不是日志在飙升,相反,现在的核心是:文件大小可能没怎么涨,SSD 写入量已经飙升了。
事情起因和经过
这不是一个单独网友的错觉。
2026 年 4 月 10 日,有用户在 OpenAI Codex 仓库提了 #17320。他观察到 Codex 在流式输出时,会持续往 ~/.codex/logs_2.sqlite-wal 写数据,写入速度达到 MB/s 级别。
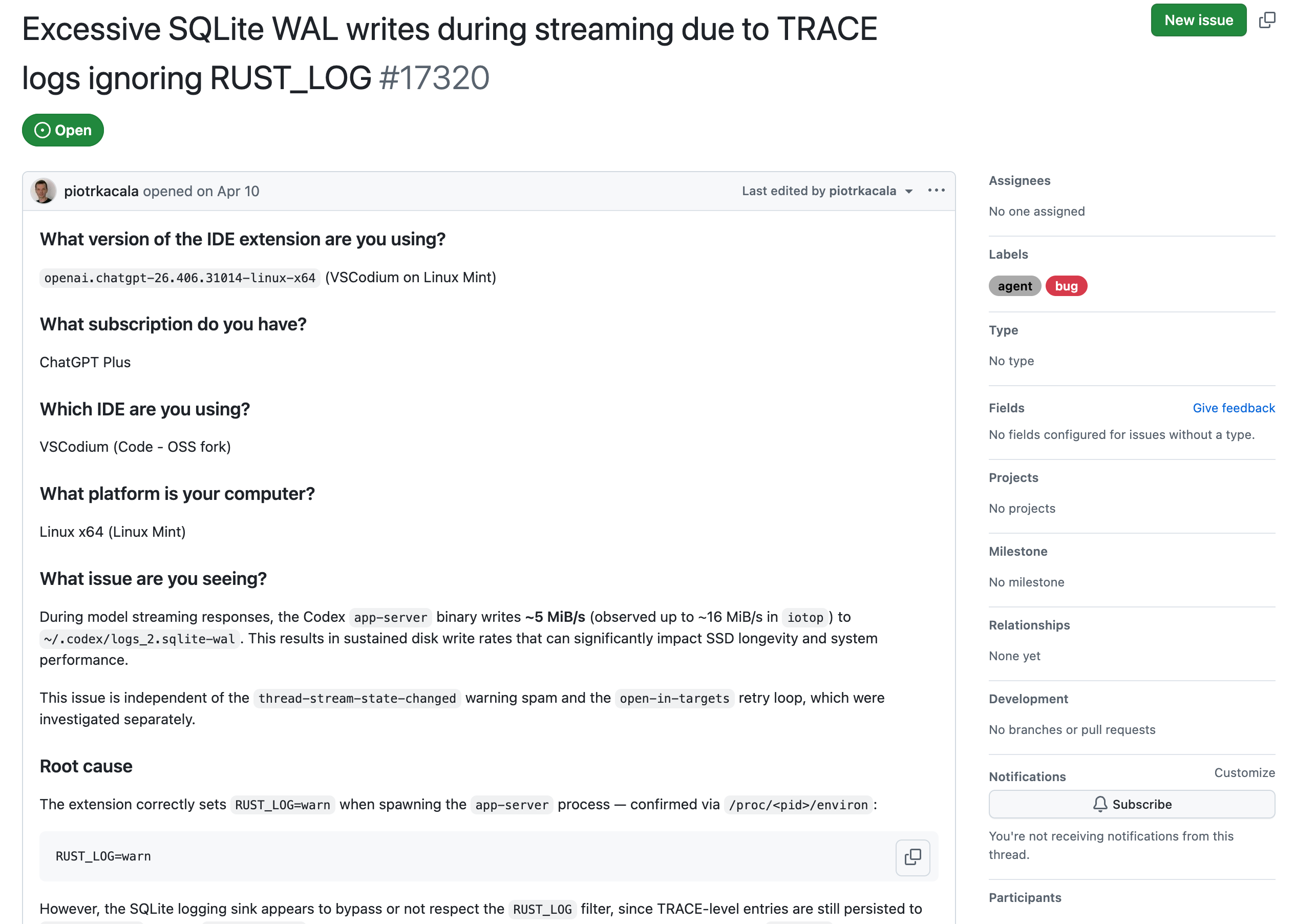
5 月到 6 月,类似报告开始变多。
有人遇到 WAL 文件长期增长,删了也不释放空间,因为老的 Codex 进程还握着已经删除的文件句柄。
也有人在 Codex Desktop 正常使用几分钟后,看到 logs_2.sqlite 和 WAL 快速膨胀,界面也开始变慢。
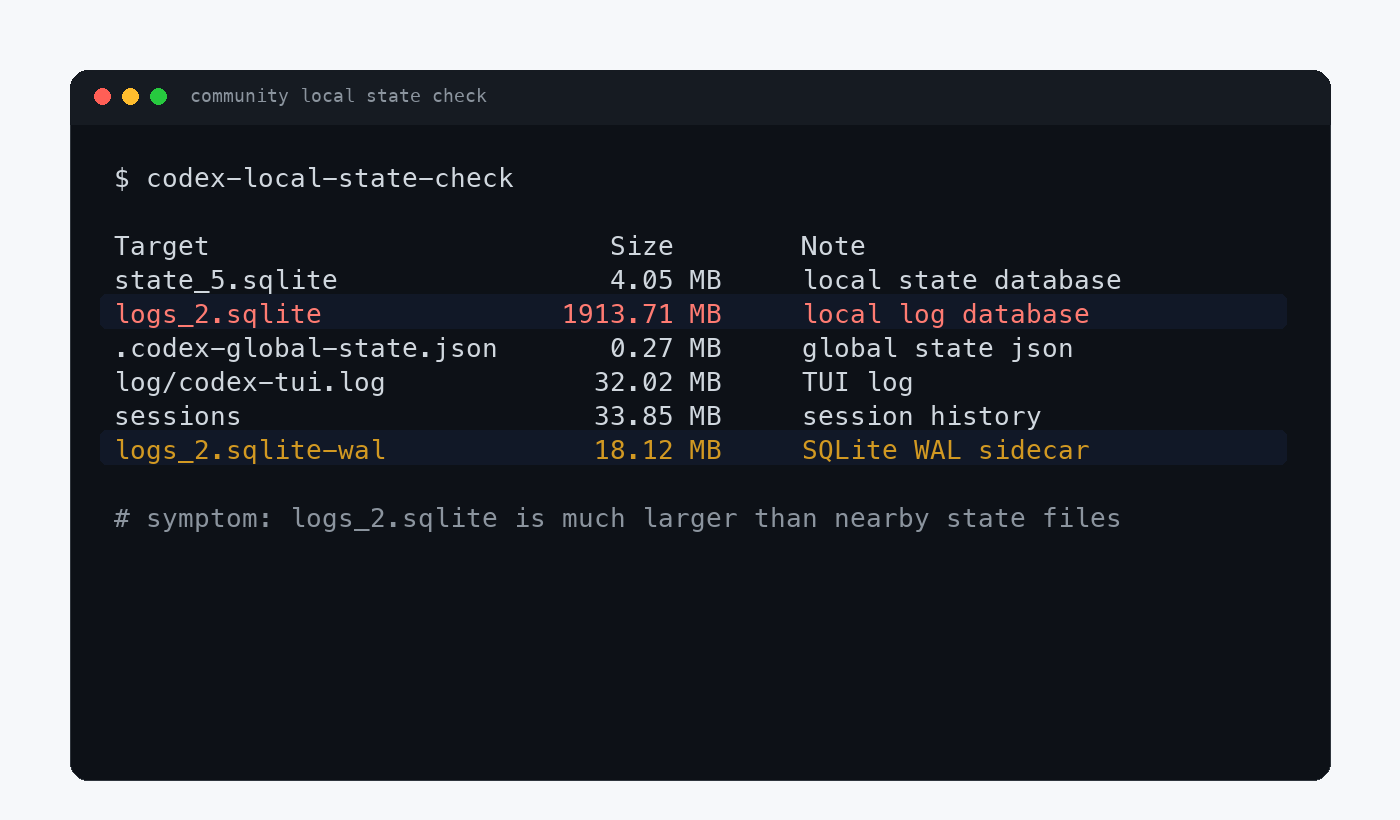
根据社区文章中的 Codex 本地状态检查截图整理
真正把事情推到台前的是 #28224。
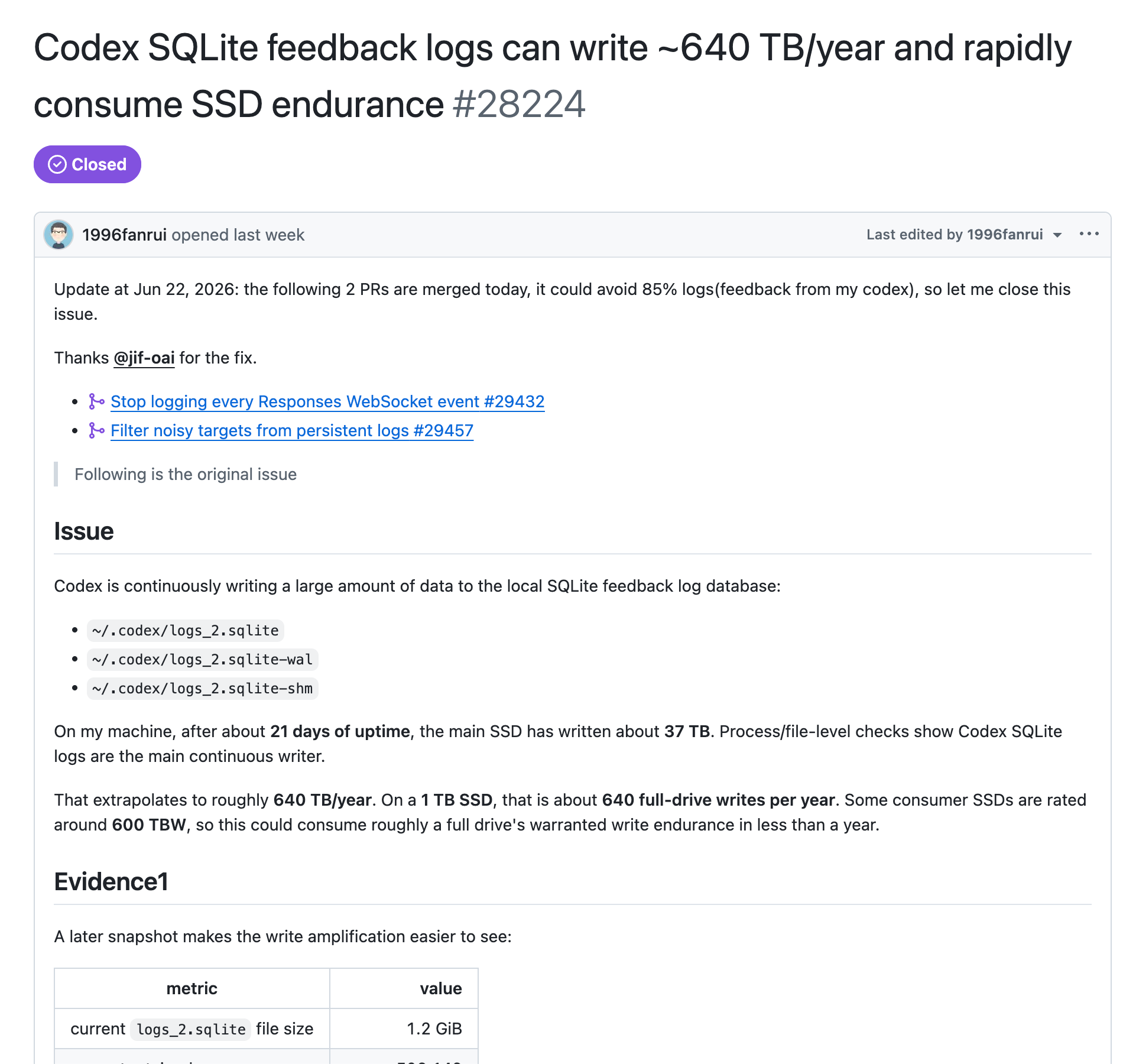
2026 年 6 月 14 日,有用户根据自己机器上的 SSD 写入量做了估算:21 天正常运行,主 SSD 写入约 37 TB。按这个速度折算,年化写入量接近 640 TB。
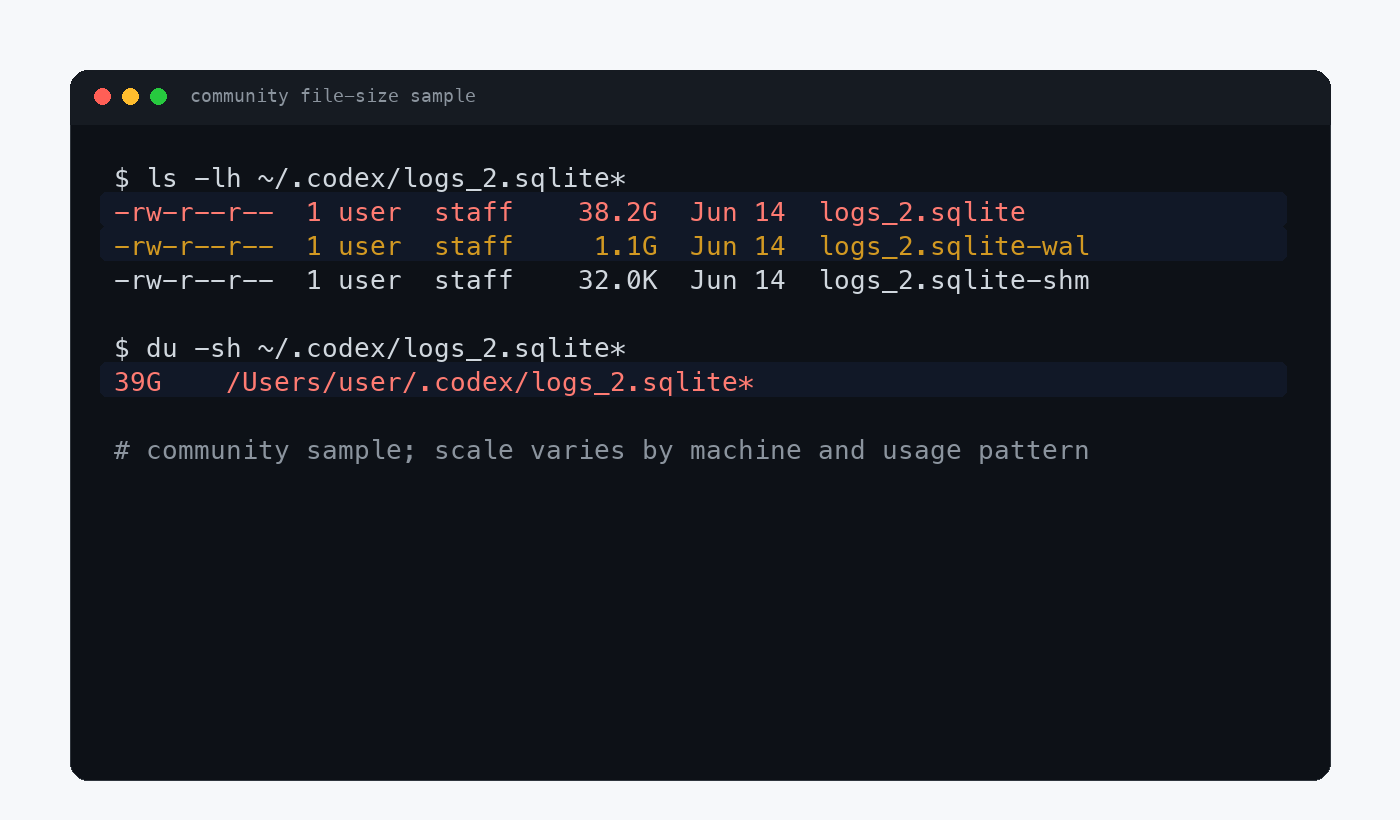
根据 X 讨论中的文件大小截图整理
这个数字只代表提出 issue 那台用户的机器,不代表每个人都会遇到同样规模。
但是他确实把问题直接抛出来了:
Codex 的本地诊断日志,在某些使用方式下确实可能持续写盘,甚至把 SSD 写入量堆到很夸张的位置。
风险最高的,是这几类一直在使用 Codex 的用户:
- 长时间开着 Codex Desktop;
- 经常跑
codex resume; - 让 Codex 做很长的流式(WebSocket 等)任务;
- 同时开多个 Codex / TUI / Desktop 进程;
- 机器用的是小容量 SSD、SD 卡、低耐久盘。
如果你一直隔一阵用一次 Codex ,或者你是 Codex 爱好者,并非 Codex 的深度用户来说,倒是还好。
但如果你把 Codex 当成你的兄弟,让它连续跑几个小时、几天不间断。
用 goal 或者 plan mode 给它上上强度的话,那你就得注意了。
问题现象
这次问题主要围绕三个文件:
~/.codex/logs_2.sqlite
~/.codex/logs_2.sqlite-wal
~/.codex/logs_2.sqlite-shm
这是 Codex 本地的 SQLite 日志库。
当 SQLite 开 WAL 模式后,写入通常先落到 -wal 文件里,再通过 checkpoint 合并回主库。
WAL 本身是正常机制。很多软件都这么用。
但是问题是 Codex 往里面记了太多不该写入的东西。
第一,流式返回里的成功事件也被记下来了。
模型正常输出一段文字、工具状态刷新一次、某个响应解析成功一次,都会成为日志。这样长任务一跑,每次调用之后的事件都会写入。
第二,之前很多 TRACE 日志会持久写到本地。
TRACE 是很细的排查日志,适合临时调试。如果你把它长期写进硬盘,尤其是写进 SQLite,就容易把写入量堆上去。
第三,它还会更新日志。
很多人看到表里只保留几万行,以为没啥大事儿。
但真实情况可能是:新日志一直插入,旧日志一直删除。导致最后的结果是日志一行没变,但是磁盘一直在写入。
这就是我本机采样看到的现象:15 秒内 MAX(id) 增加 10,364 行,但是表里总行数没有变。
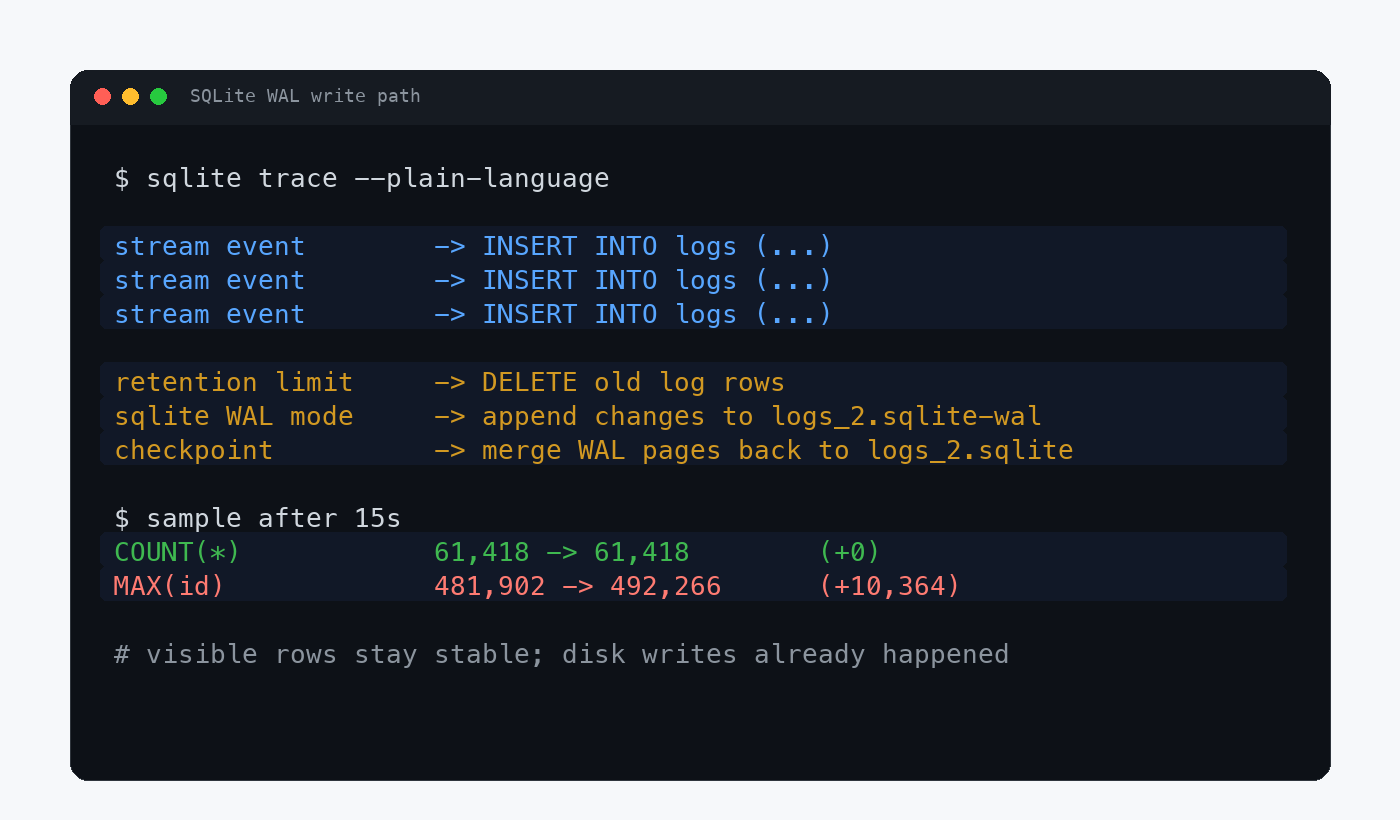
根据 OpenAI Codex issue / PR 和本机采样整理
OpenAI 怎么处理的
这里有个关键变化:OpenAI 已经修了这次最主要的写盘问题。
我在 2026 年 6 月 23 日核对了官方仓库状态。2026 年 6 月 22 日,OpenAI Codex 仓库合并了两个相关 PR,作者是仓库 collaborator jif-oai。
#29432 处理的是:停止记录每个 Responses WebSocket 事件。
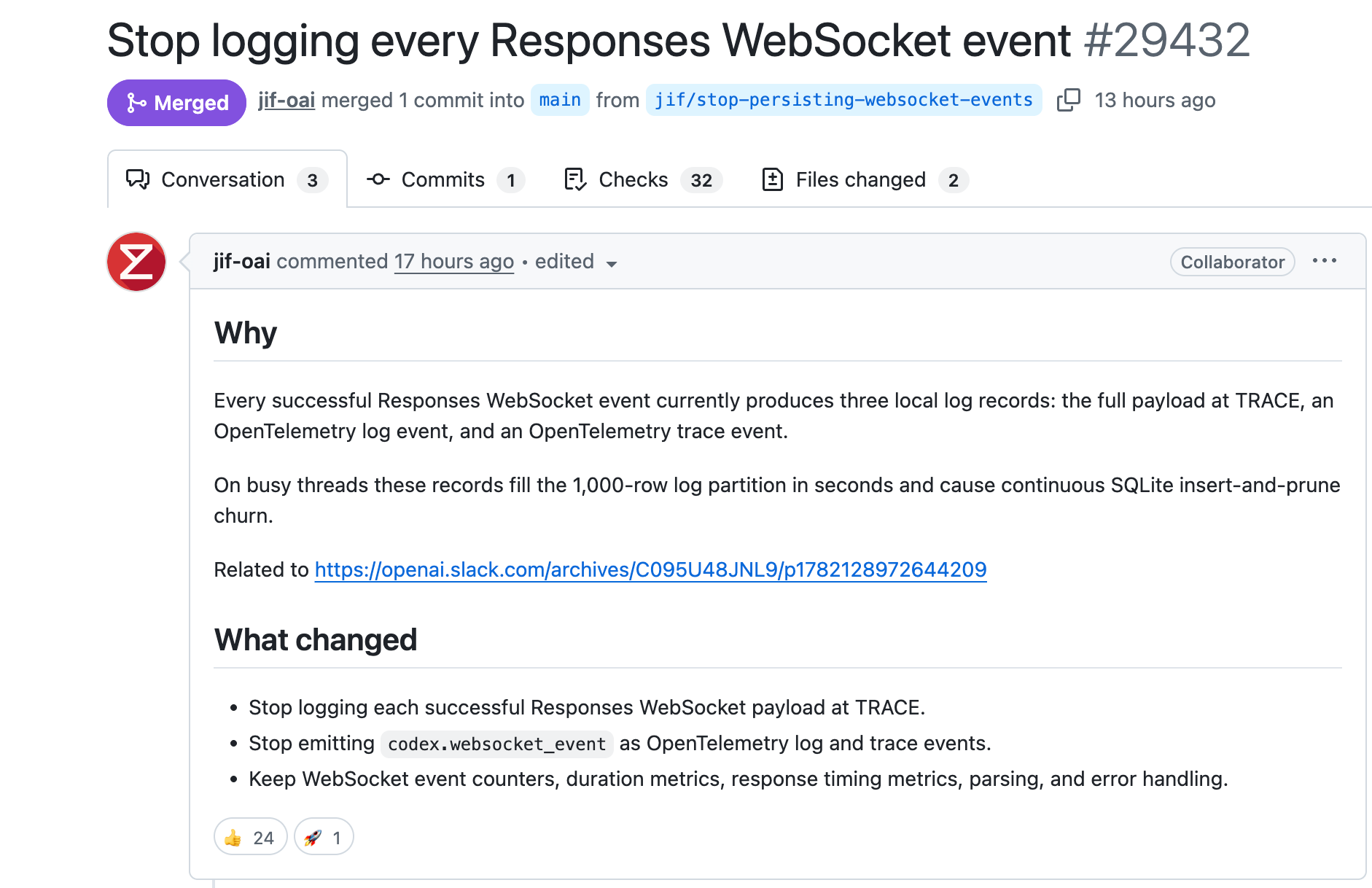
#29457 处理的是另一个方向:过滤本地日志里的高噪音来源。
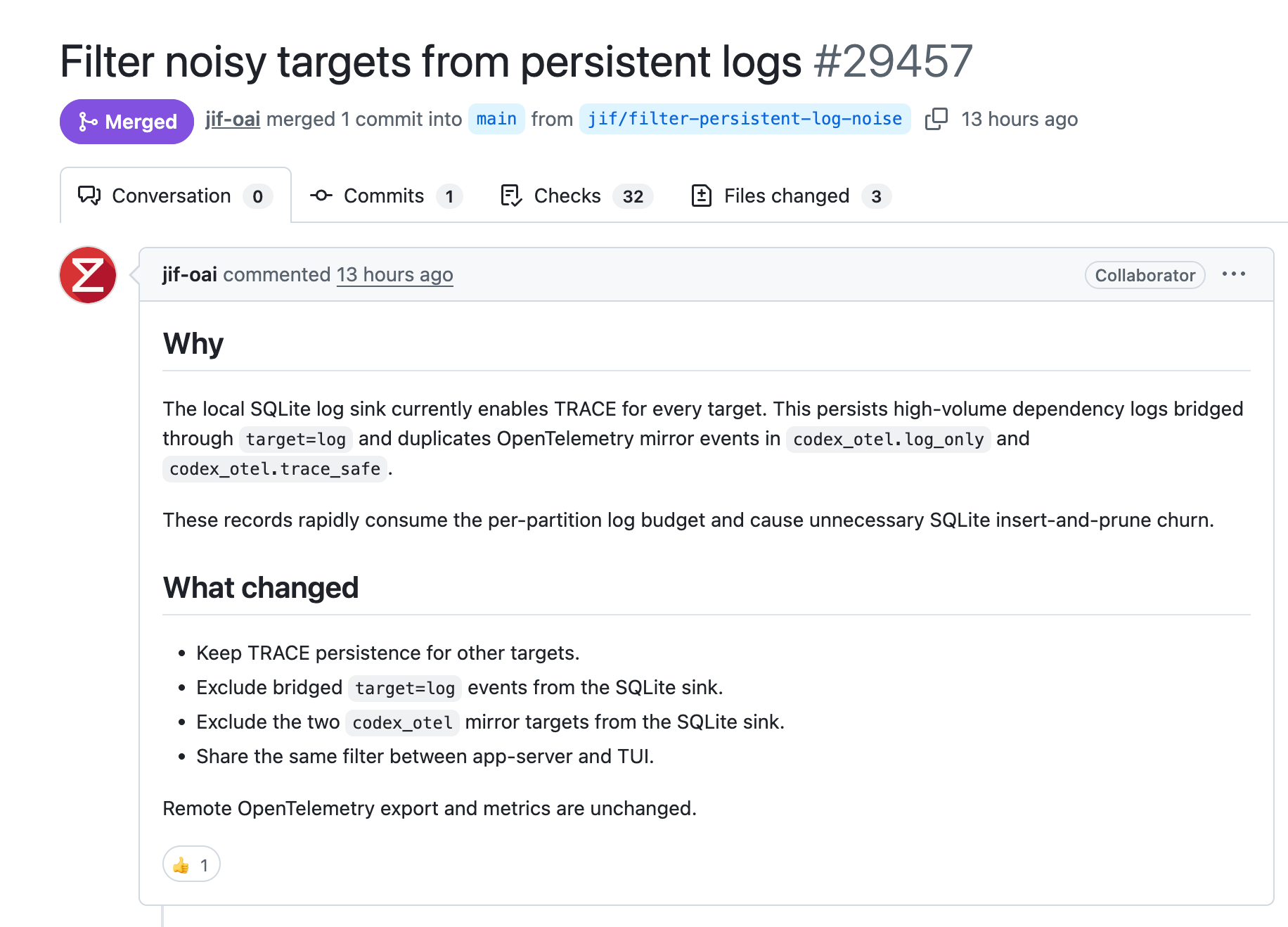
也就是那些频率很高、平时排查价值不大的日志,不再默认写进本地 SQLite。
这两个修复合并后,#28224 已经在 2026 年 6 月 22 日关闭。同一天,GitHub Releases 页面也出现了 rust-v0.142.0-alpha.11 和 rust-v0.142.0-alpha.12 两个 alpha 预发布 tag。
这里要跟大家说下:release 页面本身没有详细 changelog,所以只能把它当成“修复合并后出现的预发布版本”,不把它写成官方明确标注的修复公告。
到我核对时,#17320、#22444、#24275 这些相关 issue 仍然是 open 状态。它们还涉及 WAL 被老进程占住、删除后不释放空间、Desktop 日志库膨胀等问题。
所以目前比较准确的说法是:
最主要的高频 TRACE 写盘问题,官方已经合并修复。其它和 WAL 生命周期、老进程占用、健康提示有关的问题,还需要继续观察。
你现在该怎么做
普通用户先做一件事:升级 Codex。
尽量升级到包含 2026 年 6 月 22 日之后修复的版本。不同安装渠道的版本号可能不同,先看你自己的安装方式。
升级后再查本地文件。
省流版
如果你懒得自己敲命令,可以直接把下面这段丢给 AI:
请帮我只读排查本机 Codex 的 ~/.codex/logs_2.sqlite 是否仍在因为 TRACE 日志或流式事件持续高频写盘。
约束:
1. 只做只读诊断。
2. 不要删除文件,不要 VACUUM,不要 checkpoint/truncate,不要改 schema,不要创建 trigger,不要 kill 进程,不要升级或重装 Codex。
3. 所有 SQLite 查询都用只读 URI:db="file:$HOME/.codex/logs_2.sqlite?mode=ro"。
4. 如果 sqlite3、lsof 或数据库文件不存在,直接说明,不要猜。
5. 最后请输出:是否疑似中招、证据、风险等级、下一步建议。
请按下面顺序执行并解释结果:
第一步,确认文件大小:
```bash
du -h \
~/.codex/logs_2.sqlite \
~/.codex/logs_2.sqlite-wal \
~/.codex/logs_2.sqlite-shm 2>/dev/null
ls -lh ~/.codex/logs_2.sqlite* 2>/dev/null
```
第二步,只读检查 SQLite schema 和日志分布:
```bash
db="file:$HOME/.codex/logs_2.sqlite?mode=ro"
sqlite3 "$db" "PRAGMA table_info(logs);"
sqlite3 "$db" "
PRAGMA journal_mode;
PRAGMA wal_autocheckpoint;
SELECT COUNT(*) AS rows, MIN(id), MAX(id) FROM logs;
SELECT level, COUNT(*) AS rows, ROUND(SUM(estimated_bytes)/1024.0/1024.0, 1) AS mib
FROM logs
GROUP BY level
ORDER BY SUM(estimated_bytes) DESC;
"
```
第三步,做 15 秒短窗口采样:
```bash
db="file:$HOME/.codex/logs_2.sqlite?mode=ro"
before_id=$(sqlite3 "$db" "SELECT COALESCE(MAX(id),0) FROM logs;")
before_count=$(sqlite3 "$db" "SELECT COUNT(*) FROM logs;")
sleep 15
after_id=$(sqlite3 "$db" "SELECT COALESCE(MAX(id),0) FROM logs;")
after_count=$(sqlite3 "$db" "SELECT COUNT(*) FROM logs;")
echo "id_delta=$((after_id-before_id))"
echo "count_delta=$((after_count-before_count))"
```
第四步,查看是否有 Codex 进程占着数据库或 WAL:
```bash
lsof -nP \
~/.codex/logs_2.sqlite \
~/.codex/logs_2.sqlite-wal \
~/.codex/logs_2.sqlite-shm 2>/dev/null
```
判断标准:
- 如果 id_delta 很高,但 count_delta 很小或为 0,说明可能在持续插入又修剪旧日志。
- 如果 logs_2.sqlite-wal 持续变大,或者有老 Codex 进程占着 deleted WAL,要重点提示。
- 如果 id_delta 很低、WAL 不持续增长、只有当前 Codex 进程正常打开文件,就倾向于正常。
- 不要直接给我执行修复操作。需要修复时,只列出方案和风险,等我确认。
比如用了这段 prompt ,就检测到我的 codex 也中招了。

这是不是能说明我是 Codex 的重度用户?
手动版
如果你想手动排查一遍,也是可以的,下面是排查思路,你可以直接借鉴。
du -h \
~/.codex/logs_2.sqlite \
~/.codex/logs_2.sqlite-wal \
~/.codex/logs_2.sqlite-shm 2>/dev/null
ls -lh ~/.codex/logs_2.sqlite* 2>/dev/null
再用只读方式看 SQLite 里到底写了什么:
db="file:$HOME/.codex/logs_2.sqlite?mode=ro"
sqlite3 "$db" "
PRAGMA journal_mode;
PRAGMA wal_autocheckpoint;
SELECT COUNT(*) AS rows, MIN(id), MAX(id) FROM logs;
SELECT level, COUNT(*) AS rows, ROUND(SUM(estimated_bytes)/1024.0/1024.0, 1) AS mib
FROM logs
GROUP BY level
ORDER BY SUM(estimated_bytes) DESC;
"
这里用 mode=ro,意思是只读打开数据库。排查日志写盘问题时,尽量别让排查动作本身再去改数据库。
然后做一个短窗口采样:
db="file:$HOME/.codex/logs_2.sqlite?mode=ro"
before_id=$(sqlite3 "$db" "SELECT COALESCE(MAX(id),0) FROM logs;")
before_count=$(sqlite3 "$db" "SELECT COUNT(*) FROM logs;")
sleep 15
after_id=$(sqlite3 "$db" "SELECT COALESCE(MAX(id),0) FROM logs;")
after_count=$(sqlite3 "$db" "SELECT COUNT(*) FROM logs;")
echo "id_delta=$((after_id-before_id))"
echo "count_delta=$((after_count-before_count))"
如果升级后 id_delta 不再高速增长,WAL 也不再持续变大,就先别动数据库。
手动处理只适合两种情况:你还在旧版本上,或者升级后确认本机仍然在高速写入。
动手前先查有没有进程占着文件:
lsof -nP ~/.codex/logs_2.sqlite ~/.codex/logs_2.sqlite-wal ~/.codex/logs_2.sqlite-shm 2>/dev/null
如果有老 Codex 进程还在,先退出它。尤其是有进程握着 deleted WAL 时,你删文件也不一定马上释放空间。
然后备份:
backup_dir="$HOME/.codex/logs_backup_$(date +%Y%m%d_%H%M%S)"
mkdir -p "$backup_dir"
find "$HOME/.codex" -maxdepth 1 -name 'logs_2.sqlite*' -exec cp -p {} "$backup_dir"/ \;

根据社区 workaround 和 SQLite 清理建议整理
需要立刻止损时,社区里常见的临时方案是加一个 SQLite trigger,拦截 logs 表的新插入:
sqlite3 ~/.codex/logs_2.sqlite "
CREATE TRIGGER IF NOT EXISTS block_log_inserts
BEFORE INSERT ON logs
BEGIN
SELECT RAISE(IGNORE);
END;
PRAGMA wal_checkpoint(TRUNCATE);
"
想撤销的话:
sqlite3 ~/.codex/logs_2.sqlite "
DROP TRIGGER IF EXISTS block_log_inserts;
"
这个方案能临时止血,但它也会让 Codex 后续诊断日志不完整。真遇到问题要给官方反馈,日志可能少东西。
所以我的建议很简单:
先升级。升级后再查。确认还在写,再备份后临时拦截。
我的看法
随着 AI 编程工具越来越像常驻系统服务之后,我们不仅要会使用 Coding Agent 这辆跑车来拉客,你还得学会定期给它保养。
因为它会开本地 server,会连 WebSocket,会记会话,会写运行数据,会管理后台任务。
这些能力叠起来之后,一个日志策略失误,就可能变成系统级别的资源问题。
以前我们担心 AI 写代码出 bug,但现在还得顺手看一眼 AI 工具本身有没有写爆磁盘。
这不是说 Codex 不能用。我也还在用。
但重度用户要养成一个习惯:AI Agent 只要开始常驻,就要把它当成 AI Infrua 来看。
学会日常巡检。
对普通用户,它可能只是几百 MB 没多大用处的日志。
对重度用户,它可能真的关系到 SSD 寿命和系统稳定性。
虽然目前官方已经把主要 bug 改掉了,但是我们仍当保持清醒和警惕。
这就是我们能从这件事情中学到的教训。
参考来源:
- OpenAI Codex issue #17320
- OpenAI Codex issue #22444
- OpenAI Codex issue #24275
- OpenAI Codex issue #28224
- OpenAI Codex PR #29432
- OpenAI Codex PR #29457
- OpenAI Codex release 0.142.0-alpha.11
- OpenAI Codex release 0.142.0-alpha.12
- SQLite WAL 官方说明
- 腾讯云开发者社区:Codex 5.5 用着用着变笨?先看本地这几个文件
- SegmentFault:如何安全清理本地 Codex 对话历史?一个 CLI 工具的实现思路
- X 讨论:Codex 流式传输与本地日志写入提醒

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)