
最新!百度PP-OCRv6:86.2%检测精度、仅6.8%幻觉率,3450万参数小模型打赢GPT-5.5和Gemini-3.1-Pro
这两天翻到百度PaddlePaddle团队刚放出来的PP-OCRv6论文
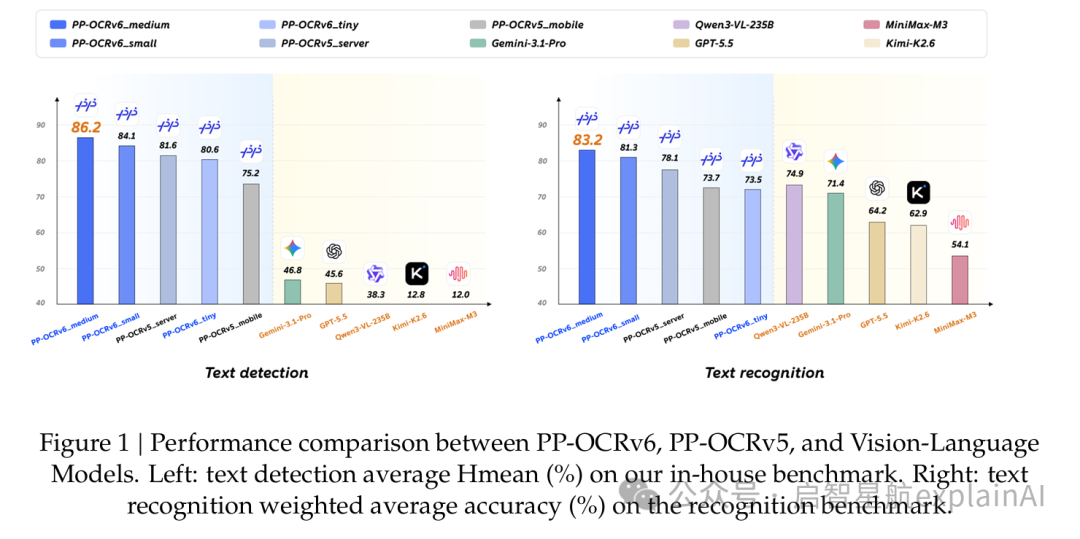
一个medium型号3450万参数的轻量级OCR模型,在他们的内部基准测试里,文本检测Hmean干到了86.2%,文本识别准确率干到了83.2%。
对比组是什么人呢,GPT-5.5、Gemini-3.1-Pro、Qwen3-VL-235B。
都是千亿甚至万亿参数的视觉大模型。
结果呢,检测方面Gemini-3.1-Pro只有50.2%,GPT-5.5只有32.6%,Qwen3-VL-235B只有32.3%。识别方面Qwen3-VL-235B是74.9%,GPT-5.5只有64.2%。
全方位被一个3450万参数的小模型吊打。
而且是数量级的差距。
先别急着喊「卧槽」。我知道你现在心里有一堆问号。
这数据靠谱吗,是不是百度自己出的基准所以偏向自己家模型。小模型赢了大模型,赢在什么地方,是赢在某个特定场景还是全面超越。还有最关键的,它到底是怎么做到的。
先说结论,PP-OCRv6能赢,靠的不是什么玄学,也不是数据作弊,而是扎扎实实的架构创新加上高质量训练数据。这事儿最有意思的地方在于,它在大模型狂飙突进的今天,给了所有做垂直领域算法的人一针强心剂。
大模型很强,但不是万能的。
好的专用模型,在它的主场里,依然可以把通用大模型打得找不着北。
先聊聊数据,这个基准测试是百度自己做的,用的是他们的内部数据集,不是公开数据集。
但如果稍微了解一点OCR这个领域,你就会知道,PP-OCR系列一直是开源OCR里的标杆。从v1做到v6,每一代都有实打实的进步,不是那种靠营销吹出来的东西。
而且这篇论文里的数据维度非常全,不只是报一个总分。我挑三个最有说服力的维度跟你说。
第一个维度,检测精度。
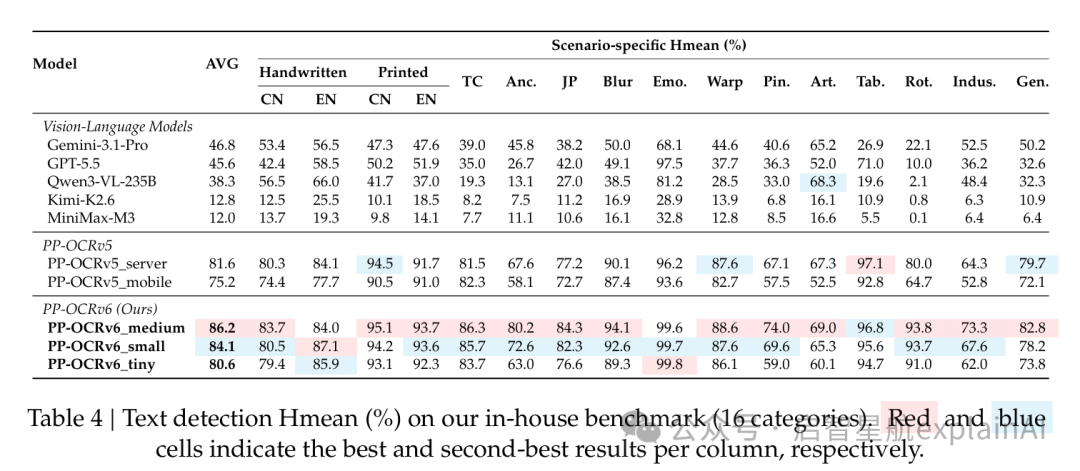
论文里的检测基准有16个类别,从手写体、印刷体、繁体中文、日文、模糊、表情、扭曲、艺术字、表格、旋转、工业字符到通用场景,覆盖得非常全。PP-OCRv6_medium的平均Hmean是86.2%,比上一代的PP-OCRv5_server还高了4.6个百分点。
大模型这边表现最好的是Gemini-3.1-Pro,50.2%。
差了36个百分点。
这已经不是「稍逊一筹」的级别了,这是代差。
第二个维度,识别准确率。
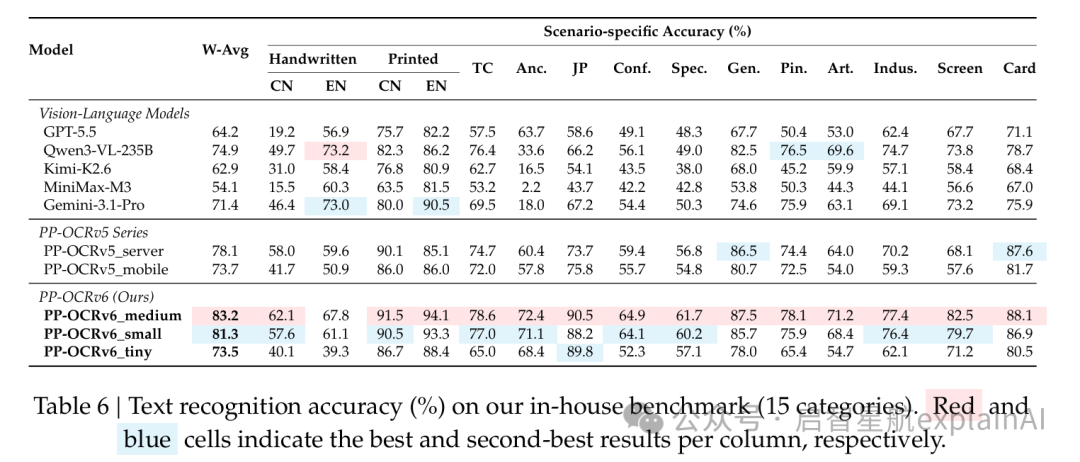
识别基准有15个类别,PP-OCRv6_medium的加权平均准确率是83.2%,比PP-OCRv5_server高了5.1个百分点。大模型这边表现最好的是Qwen3-VL-235B,74.9%,还是差了8个多百分点。
第三个维度,也是我觉得最关键的,幻觉率。
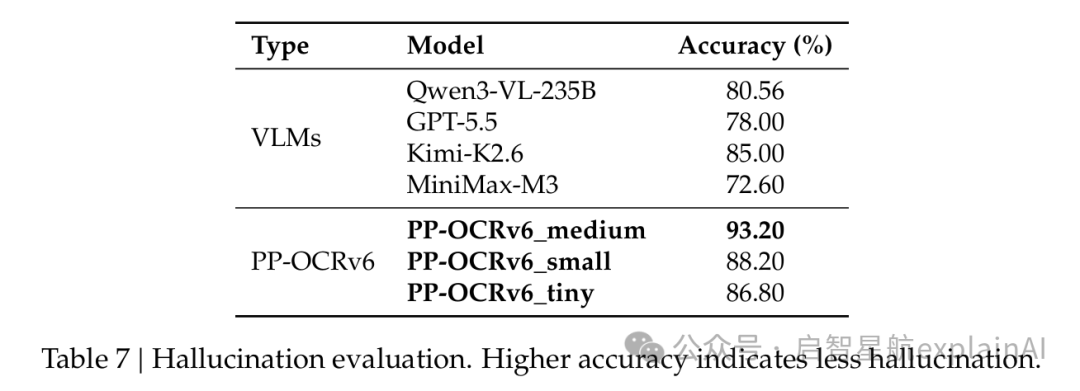
什么叫幻觉呢,就是图里根本没有这段文字,大模型自己脑补出来了。这个在OCR里是致命的,尤其是金融、医疗、法律这些对数据准确性要求极高的场景。
论文专门做了一个幻觉基准测试,准确率越高说明幻觉越少。PP-OCRv6_medium是93.2%,大模型这边表现最好的Kimi-K2.6是85.0%,Qwen3-VL-235B是80.56%,GPT-5.5是78.0%。
差了十几个百分点。
为什么差距这么大,说穿了也简单。PP-OCRv6用的是CTC加NRTR的解码架构,输出是从视觉特征里来的,看到什么输出什么。大模型用的是自回归生成,它会根据语言模型的常识去「猜」后面的内容,猜着猜着就编出来了。
在需要绝对准确的场景里,这一个特性就足以让你放弃大模型。
这三个维度的数字摆在这里,说明小模型在专用任务上,确实可以比大模型强,而且强不少。
那问题就来了,它到底是怎么做到的。
3450万参数,放在今天的AI语境里,跟「玩具」差不多。GPT-5.5有多少参数没人知道,但大家普遍估计在万亿级别。差了三个数量级。
凭什么一个玩具级别的模型,能在一个正经任务上把万亿级的大模型按在地上打。
答案,藏在LCNetV4里。
LCNetV4是PP-OCRv6的核心骨干网络。
你可以把它理解成整个OCR系统的「大脑」。不管是检测(找出图里文字在哪)还是识别(认出文字是什么),都要先经过这个骨干网络提取特征。
这一代最大的变化就是,PP-OCRv5用了两套骨干,server端一套叫PPHGNetV2,mobile端一套叫LCNetV3。到了v6,统一成了一套LCNetV4。
一套骨干,同时干检测和识别两件事。
听起来好像只是工程优化,其实不是。统一骨干背后,是一整套设计哲学的变化。
在说LCNetV4之前,我得先跟你聊聊MetaFormer。
可能很多朋友听到这个词有点懵。MetaFormer不是某个具体的模型,而是一种架构设计的范式。
什么叫范式呢,就是「大家都认同这么做效果好」的一种设计思路。
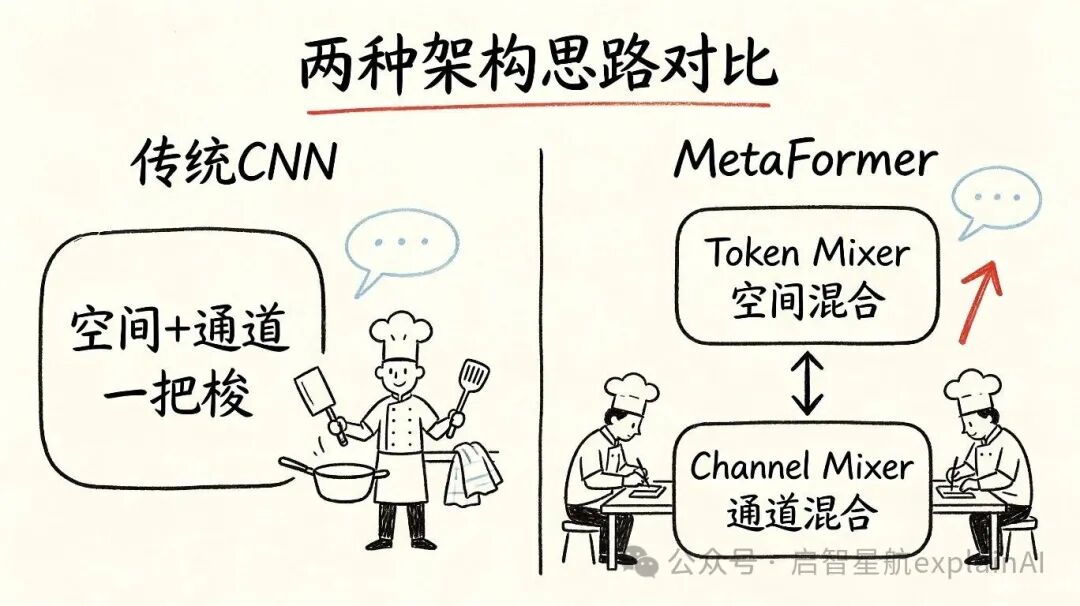
在MetaFormer出来之前,轻量级CNN的设计思路基本是MobileNet那一套。一个卷积块里,先做深度卷积,再做通道注意力,再做点卷积,一把梭。空间信息的混合和通道信息的混合,是揉在一个块里完成的。
MetaFormer说,不对,应该把这两件事分开做。
先做Token Mixer,也就是空间维度的特征混合,让每个像素点跟周围的像素点充分交流。然后再做Channel Mixer,也就是通道维度的特征变换,让每个位置的不同通道之间充分交流。
一个管空间,一个管通道。
分开做,各自优化。
为什么分开做反而更好呢,你可以这么理解。以前的设计像一个厨师又切菜又炒菜又洗碗又上菜,一个人干所有活,忙不过来就只能凑活。MetaFormer的设计是有专门切菜的,有专门炒菜的,有专门传菜的,分工明确,每个人把自己那点事干到最好。
效率自然就上去了。
LCNetV4就是按照这个思路设计的。每个LCNetV4 Block里,先过一层RepDWConv做空间混合,这就是Token Mixer。然后再过两个1×1卷积中间夹一个GELU激活,做通道混合,这就是Channel Mixer。
两边各管各的,互不干扰。
这跟PP-OCRv5的LCNetV3有啥区别呢,论文里Table 1列得很清楚。LCNetV3是MobileNet风格,LCNetV4是MetaFormer风格。LCNetV3的通道交互是单个1×1卷积加残差,LCNetV4是「扩张→激活→压缩」的双通道混合器。LCNetV3的空间混合是普通DWConv,LCNetV4是三分支的RepDWConv。
那个RepDWConv,就是今天要讲的第二个重点。
也是我觉得整篇论文里最「卧槽」的设计。
结构重参数化。
这个词听着很学术,其实道理特别简单。
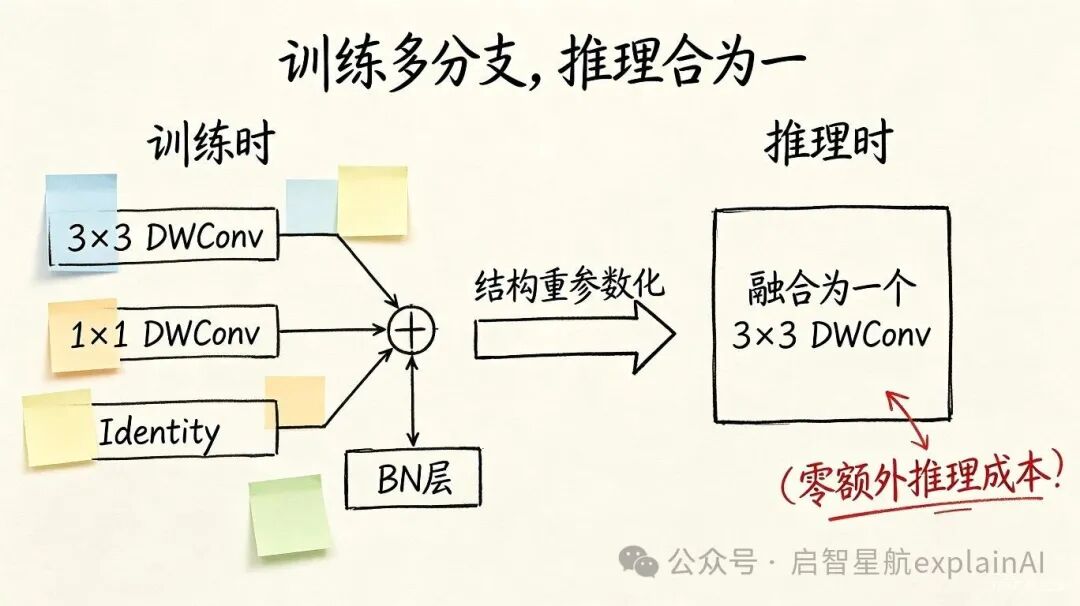
训练的时候,我搞一套复杂的、多分支的网络结构,让模型的表达能力强一点,容易训练一点。等到推理的时候,我用数学方法把这些分支「合并」成一个单一的卷积层。
结果就是,推理的时候模型复杂度一点没增加,速度一点没变慢,但精度提上去了。
相当于你考试前请了三个家教分别给你辅导,考试的时候你一个人上,答题水平比请一个家教的时候还高,但你还是一个人在答题,速度没变。
这不是「免费的午餐」吗。
LCNetV4里的RepDWConv就是这么干的。训练的时候,它有三个并行的分支,一个3×3的深度卷积,一个1×1的深度卷积,还有一个带BN的直连分支。三个分支的输出加在一起,再过一个共享的BN层。
听着就很复杂对不对,计算量也肯定不小。
但是别慌,推理的时候不是这样的。
推理的时候,通过结构重参数化,这三个分支可以合并成一个单独的3×3深度卷积。怎么合并呢,1×1的卷积核可以给周围补零补成3×3的,identity分支也可以转换成一个特殊的3×3卷积核。然后三个卷积核的权重加起来,偏置加起来,就变成了一个卷积。
数学上完全等价。
但结构上,从三个分支变成了一个卷积。
所以你看,推理的时候,它就是一个普普通通的3×3深度卷积,跟以前没有任何区别,速度一模一样。但因为训练的时候有三个分支在「同时学习」,相当于做了隐式的模型集成,学到的特征更好。
精度就这么上去了。而且零额外推理成本。
这才是做工程的人该想的事情。不是一味堆参数堆算力,而是在架构层面动脑子,用数学技巧「偷」来精度。
当然,这个技巧不是随便在哪都能用的。论文里也说了,重参数化只用到了空间维度的DWConv上,没有用到通道维度的1×1卷积上。为什么呢,因为1×1卷积本身已经是每FLOP参数效率最高的了,每个参数都在做跨通道交互,而且它没有空间维度,多分支增强带来的收益微乎其微。
不是什么都能重参数化,得用对地方。
这也是为什么我说LCNetV4的设计很「精致」。它不是把所有最新的技术堆上去就完事了,而是每个组件都想清楚了为什么加、加在哪、带来什么收益、代价是什么。
说到这,你可能会觉得,PP-OCRv6不就是换了个骨干网络吗,其他部分呢。
别急,骨干是核心,但它不是全部。
一个OCR系统,检测和识别两头都得硬。
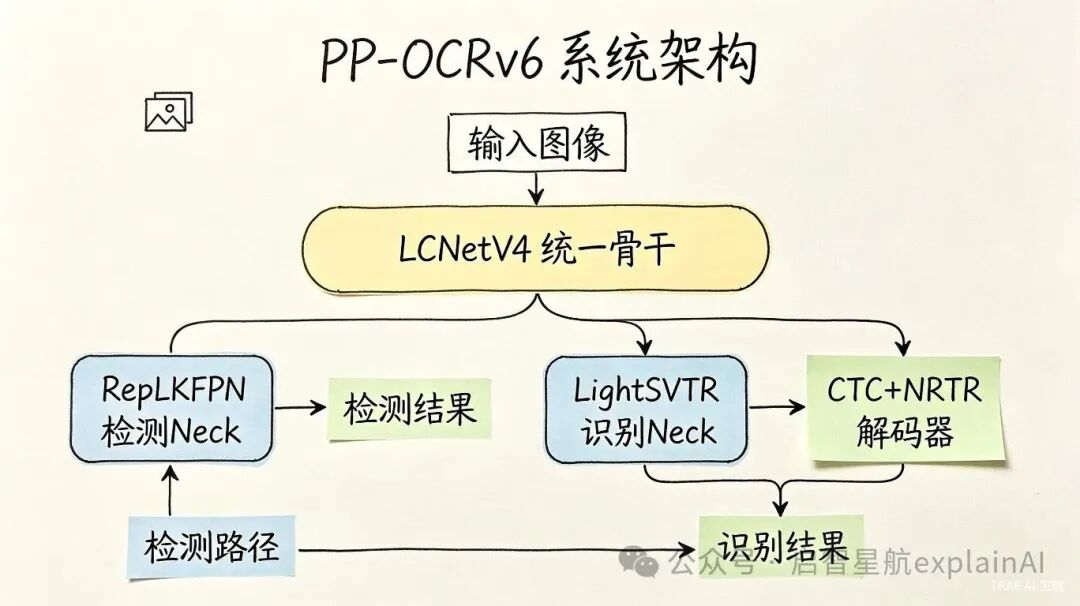
PP-OCRv6的检测部分,用的是RepLKFPN。
什么叫FPN呢,简单说就是特征金字塔网络,用来把不同尺度的特征融合在一起,这样不管文字是大是小都能检测到。PP-OCRv6的FPN用了深度可分离的大核设计,也就是RepLKFPN。
识别部分呢,用的是Encoder With LightSVTR。
SVTR是PP-OCRv3就开始用的一个识别Neck,核心是用局部-全局注意力来提取序列特征。v6版本把它做了轻量化,把原来的拼接式跳跃连接改成了加性跳跃连接,还加了一层1×7的DWConv做局部上下文。
更轻,更快,效果还更好。
然后是解码器,PP-OCRv6用的是CTC加NRTR的双解码器。
CTC是比较传统的序列解码方式,优点是快、稳、不容易瞎编。NRTR是基于注意力的解码,优点是能更好地处理上下文关系。两个一起用,各取所长。
这也是为什么PP-OCRv6的幻觉率比大模型低这么多的原因之一。它的输出是从图像中来的,不是从语言模型里编出来的。
你看,从头到脚,从骨干到Neck到解码器,每一个地方都有改进。
不是单点突破,是全面升级。
但你要是问我最核心的是什么,我还是会说是LCNetV4。因为它是地基,地基打好了,上面盖什么都稳。而且最难得的是,这一套骨干同时服务检测和识别两个任务,一套代码,两份收益。
工程上的优雅,有时候比算法上的创新更打动人。
说到这,技术层面的东西聊得差不多了。我知道有些朋友可能会问,说的这么热闹,实际用起来速度怎么样,能不能部署到端侧,支持多少种语言。
这些论文里也都有数据。
速度方面,论文测了好几种硬件,NVIDIA A100、V100、Intel Xeon CPU、Apple M4,后端也测了PaddlePaddle、ONNXRuntime、TensorRT、OpenVINO好几种。
我挑最有代表性的Intel Xeon CPU上的OpenVINO数据跟你说。因为大多数人做部署,CPU还是最常用的。
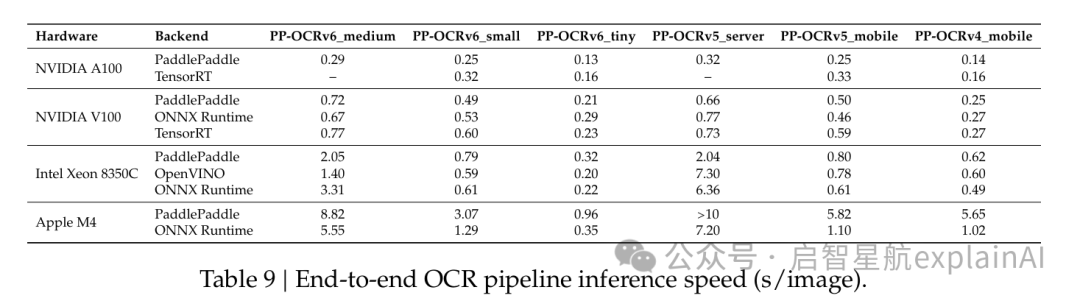
PP-OCRv6_tiny,0.20秒一张图。
PP-OCRv6_small,0.59秒一张图。
PP-OCRv6_medium,1.40秒一张图。
作为对比,PP-OCRv5_server在同样的配置下是7.30秒一张。
快了5倍还多。
而且你别忘了,v6_medium的精度比v5_server还高。
又快又准。
tiny型号0.2秒一张是什么概念呢,一秒钟5张,做实时视频流的OCR都够了。而且这还是在Intel Xeon CPU上,如果是端侧的ARM芯片,配合专门的NPU,速度还能更快。
除了速度,鲁棒性也很重要。论文专门测了分辨率鲁棒性,就是把输入图缩放到不同大小,看模型能不能稳定输出。PP-OCRv6_medium的平均Hmean是86.67%,变异系数只有5.19%。PP-OCRv5_server是79.98%,变异系数8.02%。
变异系数越小,说明模型在不同分辨率下越稳定。
v6明显更稳。
还有一个数据挺让我意外的,就是PP-OCRv6支持50种语言。我印象里上一代好像支持的语言没这么多。数字屏、点阵字、轮胎字符这些工业场景的特殊文字,也都专门做了优化。
这些细节加在一起,你就能明白为什么我说PP-OCRv6不是实验室里的玩具,是真的可以用在生产环境里的东西。
不知道你有没有这种感觉,这两年大模型的势头太猛了,猛到让人觉得「以后什么任务都是大模型的」。专用模型还有没有必要做,小模型还有没有未来,很多做算法的朋友心里都打鼓。
PP-OCRv6这篇论文,我觉得给出了一个非常明确的答案。
有必要。有未来。
而且不是那种「苟延残喘」的未来,是可以在自己的主场里,把大模型按在地上打的未来。
为什么呢,我想了想,大概有这么几个原因。
第一个,大模型是「通才」,通才的问题就是什么都会一点,但什么都不是最顶尖的。你把万亿参数摊到无数个任务上,分到OCR这一个任务上的注意力,可能真的不如一个几千万参数的专用模型多。
第二个,大模型的自回归生成方式,天然就有幻觉问题。在需要绝对准确的场景里,幻觉是不可接受的。而专用的OCR模型,输出是从视觉特征直接来的,看到什么就是什么,不会瞎编。
第三个,也是最现实的,成本。大模型推理太贵了,跑一次几毛钱几块钱。PP-OCRv6_tiny在CPU上0.2秒一张,一张的成本几分钱甚至几厘钱。差了两个数量级都不止。如果你的业务一天要跑几百万张图,这个成本差距是天文数字。
第四个,部署。大模型几百G的权重,普通服务器都塞不下,更别说端侧了。PP-OCRv6_tiny才1.5M参数,手机、嵌入式设备、甚至物联网芯片上都能跑。
不是说大模型不好。大模型有大模型的战场,通用问答、多轮对话、创意生成、零样本学习,这些都是大模型的天下。你让PP-OCRv6去写文案做PPT,它肯定干不过GPT。
但在OCR这个垂直领域,在精度、速度、成本、部署灵活性这些维度上,专用模型就是有不可替代的优势。
尺有所短,寸有所长。
我觉得未来的AI生态,不会是「一个大模型包打天下」,而是「大模型做大脑,专用小模型做手脚」。通用大模型负责理解意图、调度任务、整合信息,各个领域的专用小模型负责把具体的事干好、干快、干准。
各有所长,协同工作。
这才是健康的生态。
如果你对文档解析、OCR、多模态模型这些方向感兴趣,也欢迎来群里一起交流。 扫码即可加入


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)