
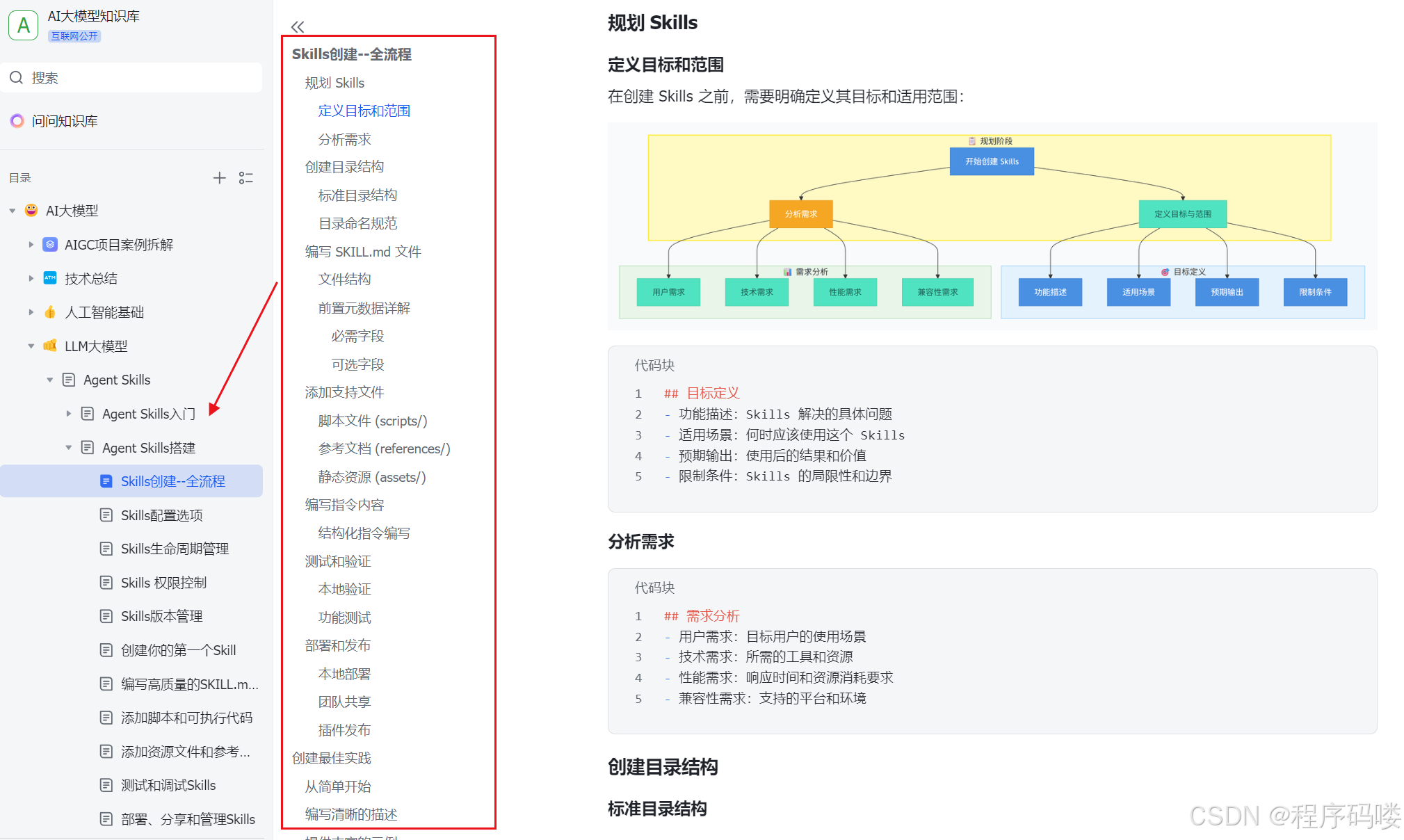
Codex 实战:用小项目验证核心能力
聊《Codex 实战:用小项目验证核心能力》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
最近面试了几个想转大模型应用开发的候选人,我发现一个普遍现象:很多人简历上堆满了各种 API 调用的 Demo,但一旦问到“如何让 AI 在复杂业务逻辑中保持稳定性”,就哑火了。其实,对于初级到中级的开发者来说,展示你对 AI 编程工具(如 OpenAI Codex)的深度掌握,远比单纯展示你会写多少个 Prompt 更有说服力。
今天我不打算讲那些虚无缥缈的概念,而是结合我最近重构的一个内部工具项目,聊聊如何用 Codex 完成一个从需求到可演示项目的完整闭环。这篇文章的核心目的很明确:教你如何利用 AI 辅助,快速产出高质量、可展示的作品集,从而在求职或内部晋升中拿到筹码。
目录
- Codex 的定位:不是复制粘贴工,是思维放大器
- 项目上下文理解:喂给 AI 正确的“背景”
- 代码修改流程:迭代优于一次性生成
- 测试与验证:AI 生成的代码必须经过考验
- 团队使用建议:建立规范比提升效率更重要
- 总结:把过程变成资产
Codex 的定位:不是复制粘贴工,是思维放大器
很多开发者对 Codex 的误解在于,把它当作一个自动补全插件(类似 Copilot)。当然,它确实能补全代码,但它的核心价值在于**上下文理解**和**架构建议**。
在我之前的项目中,我曾试图让 Codex 直接生成整个微服务模块,结果生成的代码充满了幻觉,依赖关系混乱。后来我调整了策略:将 Codex 视为一个“精通语法的初级高级工程师”。你负责定义接口、数据结构和边界条件,它负责填充实现细节和编写测试用例。
这种定位的转变,直接决定了你能利用它产出什么质量的代码。如果你只是扔给它一句“帮我写个用户注册接口”,你得到的只是一个平庸的代码片段;如果你告诉它“基于现有的 User 模型,添加一个邮箱验证字段,并处理并发写入冲突,请提供 SQLAlchemy 的实现和对应的单元测试”,你得到的就是一个可以直接放入简历的工程片段。
项目上下文理解:喂给 AI 正确的“背景”
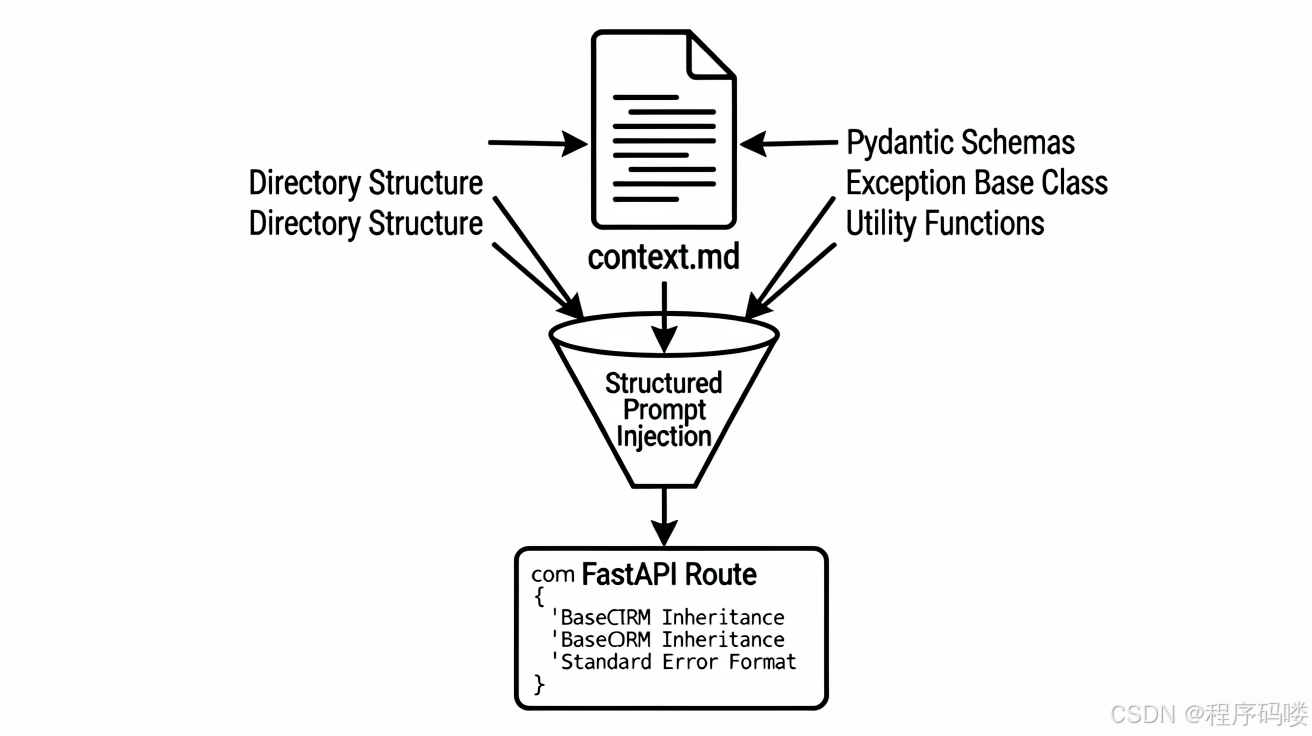
要让 Codex 写出符合项目规范的代码,首先要解决的是“上下文隔离”问题。很多时候,AI 生成的代码之所以不可用,是因为它不知道你的项目用了什么 ORM,什么错误处理规范,甚至是什么日志格式。
以我的示例项目——一个简单的任务管理 API 为例,我在接入 Codex 之前,先做了一个关键的准备工作:**构建项目知识库索引**。
我没有直接把整个仓库丢给 ChatGPT 对话框,而是整理了一份 `context.md` 文件,包含以下内容:
1. 项目的目录结构。
2. 核心的数据模型定义(Pydantic Schema)。
3. 统一的异常处理基类。
4. 现有的工具函数列表。
# 示例:在 prompt 中嵌入的关键约束
# 注意:这里不是让 AI 猜,而是强制它遵循现有规范
"""
Current Project Constraints:
1. Use FastAPI for routing.
2. All database models inherit from BaseORM.
3. Error responses must follow the standard format: {"code": 400, "message": "..."}
4. DO NOT introduce new dependencies unless absolutely necessary.
"""这样做的好处是,当后续让 Codex 生成新功能时,它能严格对齐团队规范。在简历展示中,你可以强调你设计了“结构化 Prompt 模板库”,这体现了你对工程化 AI 应用的思考,而不仅仅是会聊天。

代码修改流程:迭代优于一次性生成
在实际操作中,我几乎从不期待 Codex 一次性给出完美代码。我的流程是:**草稿 -> 审查 -> 修正 -> 测试**。
假设我们需要添加一个“批量更新任务状态”的功能。
**第一步:生成骨架**
我会先让 Codex 根据现有的单条更新接口,推断出批量更新的逻辑。
> “参考现有的 `update_task` 函数,编写一个 `bulk_update_tasks` 函数,接收 task_ids 列表,将它们的状态更新为 completed。请保证事务的一致性。”
**第二步:人工介入逻辑修正**
Codex 可能会忽略事务回滚的逻辑。我会手动检查生成的代码,发现它只写了普通的循环赋值,没有使用 `session.begin()` 或类似的事务控制。这时,我会再次输入:
> “刚才生成的代码缺少事务保护。如果中间某一条更新失败,其他已更新的数据需要回滚。请重写该方法,使用 SQLAlchemy 的 session 事务机制。”
**第三步:生成配套测试**
这是最关键的一步,也是最能体现你专业度的地方。很多开发者写完功能就不管了,但我要求 Codex 立即生成单元测试。
> “为 `bulk_update_tasks` 编写 pytest 单元测试,覆盖正常情况、部分 ID 不存在的情况、以及空列表输入。请使用 pytest-mock 模拟数据库会话。”
通过这种“生成-质疑-修正”的迭代过程,不仅代码质量大幅提升,你在面试时也能清晰地讲述你是如何通过 AI 解决边界条件的。
测试与验证:AI 生成的代码必须经过考验
Code Review 的重点不再是语法正确性,而是业务逻辑的完整性。我通常会跑一遍 Codex 生成的测试用例。有趣的是,Codex 生成的测试往往比我想象的更全面,比如它会考虑到数据库死锁的边缘情况。
但在实际项目中,我发现了一个坑:Codex 有时会过度 Mock,导致测试通过了,但集成到真实环境却报错。因此,我的建议是:**对于核心业务逻辑,尽量使用真实数据库容器进行集成测试,而不是完全依赖 Mock。**
在简历中,你可以这样描述这个环节:
> “利用 AI 辅助生成覆盖率高达 90% 的单元测试,并建立了‘AI 生成代码静态扫描 + 人工逻辑审查’的双重校验机制,确保引入的新功能无回归风险。”
团队使用建议:建立规范比提升效率更重要
如果你是小团队的 Tech Lead,不要指望全员立刻熟练使用 Codex。你需要制定明确的“红线”:
1. **禁止直接提交 AI 生成的未审查代码**。
2. **敏感数据脱敏**:严禁将公司核心算法或用户隐私数据粘贴到公共 AI 平台。
3. **Prompt 标准化**:团队内部共享一套高质量的 Prompt 模板,减少重复沟通成本。
对于个人开发者,我建议将 Codex 的使用经验沉淀为一套“最佳实践文档”。这不仅有助于团队协作,更是你作品集中的重要组成部分。例如,你可以开源一个小型的 CLI 工具,专门用于格式化发送给 AI 的上下文信息,这在求职时是一个非常亮眼的加分项。
总结:把过程变成资产
回顾这次实战,我们并没有做出什么惊天动地的创新,但通过合理利用 Codex,我们将一个原本需要两天完成的 CRUD 扩展工作压缩到了半天,并且附带了完整的测试套件。
更重要的是,在这个过程中,你积累了一手材料:
- 你是如何设计 Prompt 以获得最佳结果的?
- 你是如何发现并修复 AI 产生的潜在 Bug 的?
- 你是如何将 AI 生成的代码整合进现有架构的?
这些细节,才是面试官真正想听的。不要只展示结果,要展示你驾驭 AI 工具的能力。在这个时代,会用 AI 编程的人很多,但懂得如何验证、优化和控制 AI 输出的人,才是稀缺资源。
希望这篇复盘能帮你理清思路,下次面对 AI 辅助开发时,不再是被动的执行者,而是主动的控制者。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)