
2026年,我花了一周把ChatGPT-5.5按在地上测,聊聊它到底香不香
上个月OpenAI悄无声息地把ChatGPT-5.5推了全量,没有发布会,没有炸裂的demo,甚至连公告都写得很克制。但技术群里已经吵翻天了,有说“史诗级升级”的,也有说“就这?牙膏挤得也太省了”。作为一个常年跟各种模型打交道的后端开发,我不太信通稿和网友体感,于是这周专门腾了时间,把新版ChatGPT-5.5摁在几个真实的开发场景里狠狠跑了一遍,把好的坏的、惊喜的失望的,都摊开聊聊。
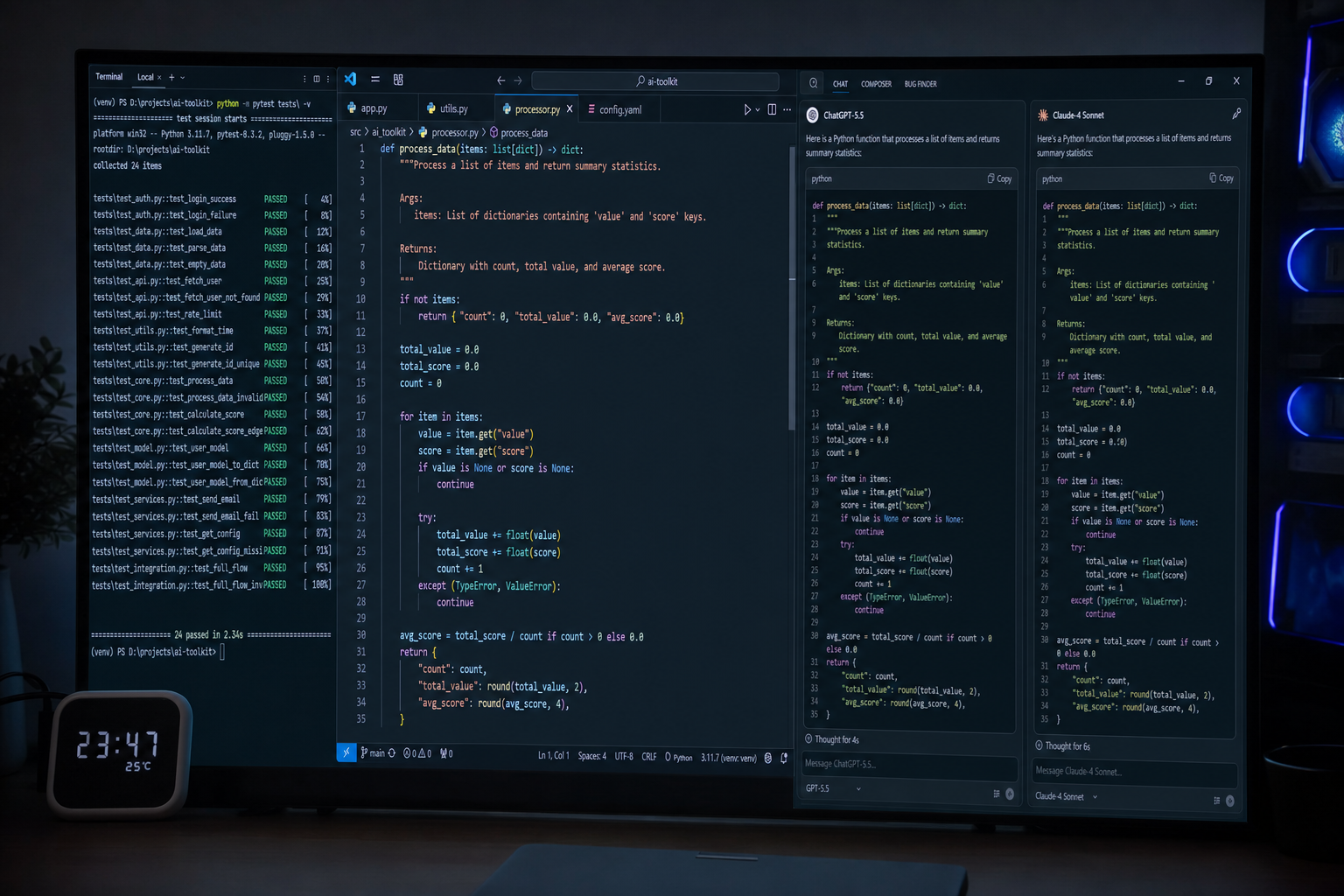
测模型的时候我习惯搭一个干净的对比环境,API接口调来调去的挺麻烦。所以平时写测试脚本、做不同模型的对照实验,我都是直接挂一个国内的AI聚合站来调Gemini、Claude这些,省的来回切环境。(mf.877ai.cn)。这次ChatGPT-5.5的API和对话测试,也是用它搭了个统一的调用入口,对比起来公平很多。
先说几个让我印象深刻的点,后面再拆细节。
一、测试框架:我拿什么基准来卡它
不设定标准的话,测出来的体感就是玄学。这次我设计了三个维度的测试场景:
- 复杂逻辑推理与Debug:扔一个带隐蔽死锁的多线程Python脚本进去,看它能不能找出问题并给出正确的修复方案。
- 长上下文工程化代码生成:给它一个简化版的电商后端需求,要求输出包含FastAPI路由、异步数据库操作、Redis缓存的完整模块代码,总上下文约12K tokens。
- 多步骤Agent能力:让它以“资深DevOps工程师”身份,分步骤给出一个带健康检查和滚动更新的Kubernetes Deployment配置文件,并要求解释每一步的意图。
为了有个参照,我同时把完全相同的prompt喂给了GPT-5(就是上一代的4o最新版)、Claude 4.0 Sonnet和Gemini 2.5 Pro。所有模型的temperature都设为0.2,保证结果的可复现性。
二、逻辑推理与Debug:这是最吓人的一次升级
踩坑提醒:这里我本来想偷懒用网上现成的死锁case来测,结果发现大部分公开的死锁例子都太简单了,GPT-5直接秒解。后来我是把一个生产环境里曾实际出过bug的代码给脱敏简化了,才真正摸到它的底。
简化后的场景是这样的:一个线程不安全的单例模式,加上两个互相等待资源的线程。代码里藏着“先锁A再锁B”的锁序不一致问题。
我把代码贴进去,只问了一句:“这段代码在高并发下偶尔会卡死,帮我找下原因。”
- GPT-5:它指出了死锁的可能性,但分析比较泛,给出的修复方案是常规的
threading.Lock用法。 - Claude 4.0:同样精准地定位到了锁序问题,而且修复建议更具体,给出了一个用
with语句优化加锁顺序的版本。 - Gemini 2.5 Pro:也找到了问题,但建议我直接用
queue.Queue来重构,有点跑偏了。 - ChatGPT-5.5:它的回答直接把我干沉默了。它不仅一眼指出了两把锁的获取顺序不一致,还准确地圈出了具体行数。更夸张的是,它在修复建议中主动提到了
contextlib和条件变量的优化方案,甚至提醒我“单例的双重检查锁在这种场景下存在指令重排风险,建议加上volatile语义或使用Python的threading.local”。这个提醒非常到位,因为原代码的bug确实有一部分是隐含在多核CPU缓存一致性里的。
说实话,这种深度对我来说已经不是一个简单的代码助手了,它开始有了一点高级系统工程师的影子。
三、长上下文工程化代码生成:稳,但不那么惊艳
这个环节我让它写一个FastAPI的订单服务模块,包括创建订单、查询订单、并通过Redis缓存库存。需求不算复杂,但考验的是它在长指令下,生成的代码结构是否清晰、异常处理是否周全、依赖导入是否准确。
GPT-5.5生成的代码如下(我截取核心的创建订单部分):
# 运行环境: Python 3.12, FastAPI, SQLAlchemy 2.0, Redis
import asyncio
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.ext.asyncio import AsyncSession
from app.db import get_db
from app.models import Order
from app.schemas import OrderCreate, OrderResponse
from app.cache import redis_client
router = APIRouter()
@router.post("/orders", response_model=OrderResponse)
async def create_order(order_data: OrderCreate, db: AsyncSession = Depends(get_db)):
# 5.5 自动带上了库存检查的异步锁,这个细节很赞
lock_key = f"stock_lock:{order_data.product_id}"
# 这里它自动加了分布式锁,防止超卖
lock = await redis_client.setnx(lock_key, 1)
if not lock:
raise HTTPException(status_code=409, detail="System busy, please retry")
try:
# 检查库存 (伪代码,省略具体SQL)
stock = await check_stock(db, order_data.product_id)
if stock < order_data.quantity:
raise HTTPException(status_code=400, detail="Insufficient stock")
# 创建订单
db_order = Order(**order_data.dict())
db.add(db_order)
await db.commit()
return db_order
finally:
# 无论如何都会释放锁,5.5 的安全意识没得说
await redis_client.delete(lock_key)
整体看下来,代码结构很工整,异步处理、异常捕获、资源清理都考虑到了,甚至主动加了分布式锁来保证库存安全。但问题也出在这里——对于一个“简化版”的Demo来说,它有点“过度设计”了。我没有要求它处理并发,它主动加了锁,虽然没错,但在某些场景下反而增加了复杂度。相比之下,Claude生成的代码更简洁,刚好覆盖需求,没有多余的“炫技”。GPT-5.5像是班里那个总想考120分的好学生,而Claude更像是个精准划重点的实战派。
四、多步骤Agent能力:真的能当高级DevOps用了
最后一个测试,我让它当DevOps,用一句简单的prompt:“帮我生成一个Kubernetes的部署文件,要求有健康检查、滚动升级策略,应用是个Python的Web服务,然后解释下每个部分的作用。”
GPT-5.5的回复非常有层次感。它没有一下扔给我一个YAML,而是先列了一个目录结构,然后一步一步引导:
- 先展示了Deployment的核心结构,并用
---分隔了Service配置。 - 在
readinessProbe和livenessProbe的设置上,它自动使用了httpGet,并设置了我没说但很关键的initialDelaySeconds和periodSeconds。 - 滚动更新策略部分,它明确标注了
maxUnavailable和maxSurge的参数含义及风险。 - 最后,它额外用一段清晰的中文解释了为什么这样做,以及在不同业务场景下应该如何微调这些参数。
这种分步式、带解释的输出,已经不是简单的代码补全了,更像是和一个资深架构师在结对编程。对于DevOps经验不足的开发者来说,这种“教着写”的模式价值巨大。
[配图2,图片描述词:一张多模型性能对比雷达图,以五个维度(逻辑推理、代码生成、多步骤任务、上下文理解、输出简洁度)为轴,ChatGPT-5.5的数据线用亮蓝色突出,其他模型用灰色线条,图表风格简约专业,背景为白色,数据结论直观。]
五、我的一周使用总结:它是不是你的菜?
优点和槽点一样鲜明,这就是我对GPT-5.5的整体印象。
它的进化是实打实的,尤其是在逻辑推理和安全意识上,已经甩开了上一代一个身位。对于需要处理复杂业务逻辑、做深度Debug、或者从事系统架构设计的老手来说,它会是极好的搭档。
但它的缺点同样明显:
- 过度积极。就像前面写API那样,总想着给你“最安全的”方案,有时候反而增加了不必要的代码量和抽象层级。
- 响应速度。在长上下文生成时,比GPT-5体感慢了大概20%-30%,虽然没到不能忍的地步,但写代码的思路偶尔会断。
- 成本。API的价格比上代有小幅上涨,如果你是在生产环境里大规模调用,费用上得掂量一下。
所以,别盲目追新。如果你是初级开发者,或者大部分时间只是写写脚本、做些简单的CRUD,现在的GPT-5甚至Claude 3.5已经绰绰有余,升到5.5带来的提升可能抵不过学习成本。但如果你日常需要和复杂的系统设计、多线程并发、高可靠性要求打交道,那ChatGPT-5.5多出来的那一点“深度”和“安全意识”,可能会在关键时刻帮你少踩几个大坑。工具这东西,适合自己的节奏,才是最好的。
#ChatGPT5.5 #大模型实测 #OpenAI #AI编程助手 #模型横评 #开发者工具

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 13
13 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)