
OpenAI推出“修补地球“项目,以AI维护开源供应链安全

今天,OpenAI发布Daybreak(破晓)网络安全计划,一口气甩出三张牌:满血版GPT-5.5-Cyber、更新版Codex Security、以及一个听起来就很燃的项目——Patch the Planet(修补地球)。
前两张牌是能力,第三张牌是命题。

Patch the Planet要解决的问题,不是"怎么发现漏洞"——这件事AI已经做得足够快了。它要解决的是:发现漏洞之后,怎么让修复真正落地。
GPT-5.5-Cyber
为修复而生的最强网安模型
此次发布的核心,是GPT-5.5-Cyber完整版。这不是一个"更会聊天"的GPT,而是一个面向高级授权网络安全工作的专用模型——更懂漏洞复现、利用链分析、补丁辅助和长程安全任务。
GPT-5.5-Cyber的跑分数据相当亮眼。在衡量AI能否复现已知漏洞的CyberGym基准测试中,GPT-5.5-Cyber单模型评估达到85.6%,大幅超越GPT-5.5的81.8%。它甚至超过了竞争对手Anthropic的Mythos 5,刷新了GPT系列模型在该测试中的得分纪录。
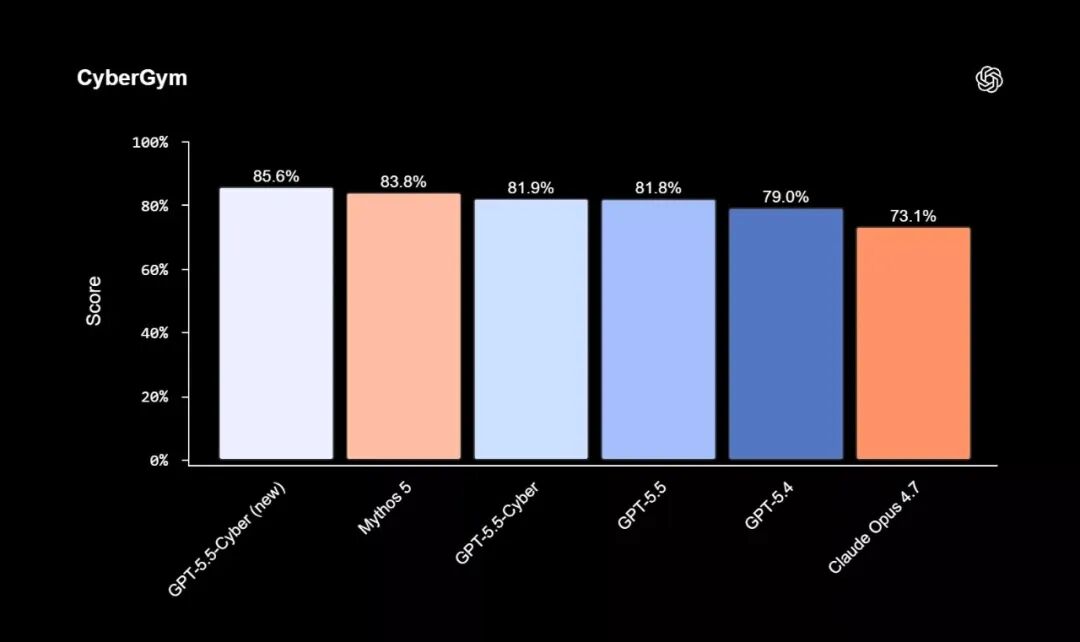
在另外两个高难度真实安全基准上,GPT-5.5-Cyber同样表现惊人:
-
ExploitGym(考验能否将漏洞转化为可执行的攻击代码):GPT-5.5-Cyber得分39.5%,GPT-5.5仅为25.95%
-
SEC-bench Pro(评估长期漏洞挖掘和概念验证能力):GPT-5.5-Cyber得分69.8%,GPT-5.5为63.1%
三项基准,满血Cyber版全面碾压通用版GPT-5.5。
但OpenAI没有把跑分当终点。他们反复强调:基准只是故事的一部分,真正重要的是模型能不能找到真实漏洞、区分可操作问题和噪声,并帮助防守方安全落地修复。
Codex Security
塞进每个开发者手边的"AI安全工程师"
如果说GPT-5.5-Cyber是Daybreak计划中最锋利的矛,那Codex Security插件就是递到每个开发者手边的那面盾。
OpenAI把Codex Security直接整合进了Codex的工作流里——开箱即用的漏洞扫描、威胁建模、攻击路径追踪、补丁自动生成,一条龙。它的逻辑很简单:在每个程序员身边,塞一个安全工程师。
开发者可以运行深度扫描或审查近期变更,生成包含严重性评估、受影响代码位置、验证证据及修复指南的完整报告,还能追踪攻击路径、构建威胁模型、验证发现结果,并直接生成针对代码库的补丁供人工审查。更关键的是,它不仅能修复现有系统中的漏洞,还能自动防止新漏洞进入生产环境。
自今年3月以研究预览形式上线以来,Codex Security交出了一份相当惊人的成绩单——已扫描超过3000万次代码提交,覆盖超过3万个代码库。其中,人工审核确认修复的发现超过7万个,系统自动判定修复的超过50万个。

这就是AI时代"补漏洞"必须达到的规模:以前是人海战术,现在是机器速度。
修补地球,先修Bug
Patch the Planet背后,是OpenAI对网络安全范式的一个判断:瓶颈已经从"发现漏洞"转移到了"修复漏洞"。
然而,就在OpenAI高调发布"修补地球"的同时,Codex却被曝出了一个令人尴尬的"史诗级"Bug。
有开发者发现,Codex在执行长时间运行时,会以极高的频率向本地SQLite数据库持续写入诊断日志。连续运行21天,硬盘承受了约37TB的写入量,年化预估高达640TB,足以在一年内写废一块消费级SSD。
问题根源是一项日志配置默认以全局TRACE级别运行,记录了一切细碎事件,加上数据库频繁循环写入带来的放大效应,实际磁盘损耗远超正常水平。
好在官方及时发现问题并进行修复。OpenAI研究员Vaibhav (VB) Srivastav回应称,问题已随最新版Codex一同发布修复补丁,并提醒所有用户"务必通过npm或bash安装脚本将Codex升级到最新版本"。
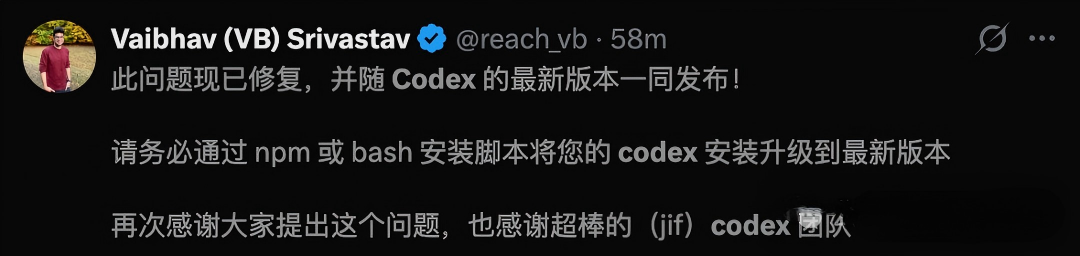
Bug是修好了,但回过头来看,一边抛出"修补地球"的安全愿景,另一边自家工具爆出"烧穿硬盘"的Bug——这或许正是AI安全时代最真实的写照:技术在飞速前进,但完美依然在路上。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 1
1 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)