
AI 编程总返工?给 AI 立 6 层规矩搞定(附 CLAUDE.md / .cursorrules 模板)
一句话结论:你能让 AI 干多大的活,取决于你给它立了多少规矩。 模型再强(GPT、Claude),工具再好(Cursor、Claude Code、Copilot),它都猜不到你项目里那些约定——把这套约定显式喂给它,就是上下文工程(Context Engineering)。
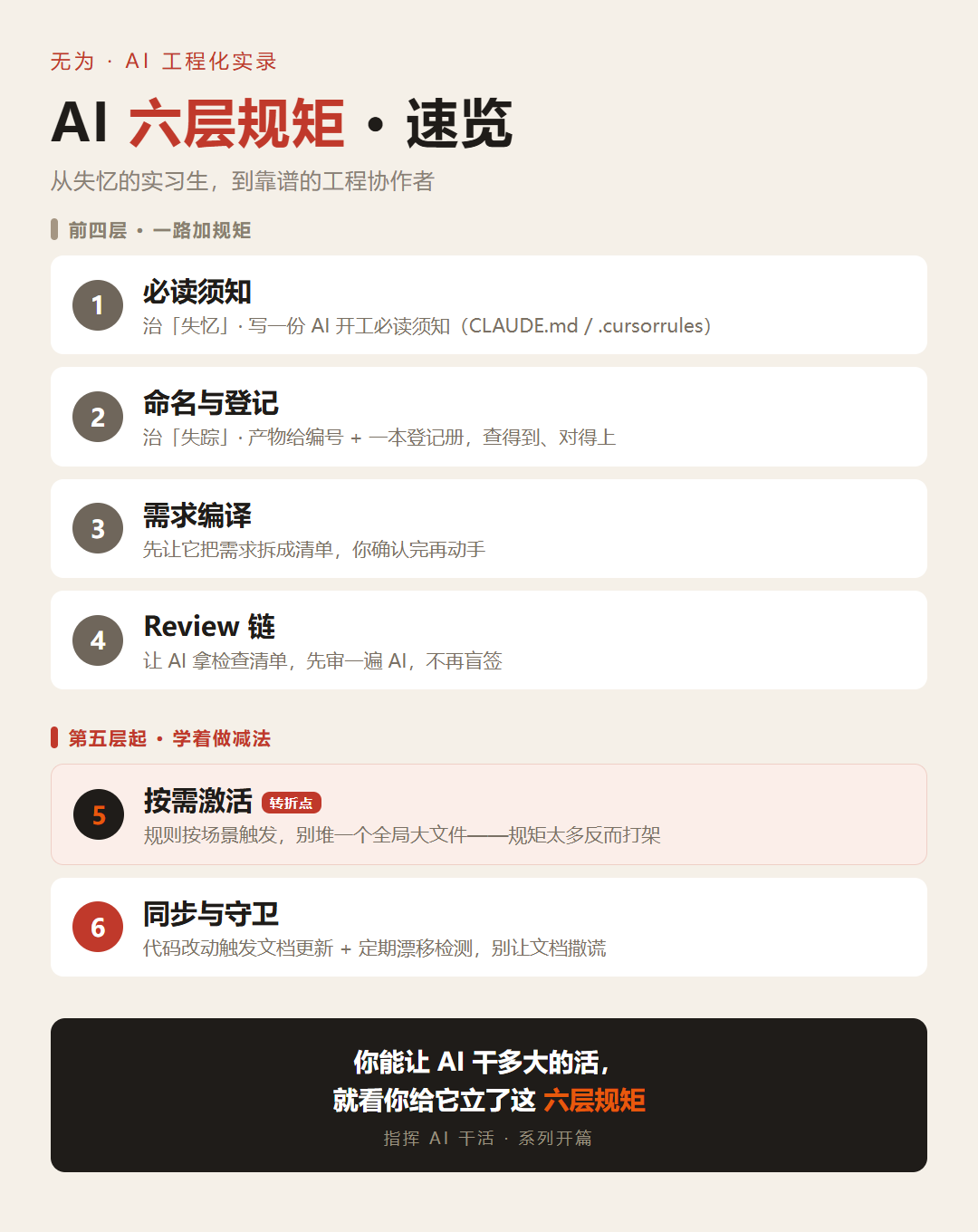
下面这 6 层规矩,是我在一个真实项目里前后三周半、先踩坑后补出来的。先看总览,再逐层给落地做法:
| # | 层 | 解决的问题 | 落地做法 | 对应工具机制 |
|---|---|---|---|---|
| ① | 必读须知 | 新会话「失忆」 | 项目约定写成开工必读文件,自动加载 | CLAUDE.md / .cursorrules / AGENTS.md |
| ② | 命名与登记 | 产物「失踪」 | 产物命名规范 + 一份索引/登记册 | 约定 + docs/registry.md |
| ③ | 需求编译 | 理解偏差导致返工 | 先让它输出需求清单/方案,确认后再写 | Plan 模式 / spec-first |
| ④ | Review 链 | 盲签大 diff | 落地前让 AI 拿清单先审一遍 AI | review 子代理 / pre-commit |
| ⑤ | 按需激活 | 规则膨胀、互相打架 | 规则按场景触发,不堆全局大文件 | .cursor/rules/*.mdc + globs |
| ⑥ | 同步与守卫 | 代码与文档漂移 | 代码改动驱动文档更新 + 漂移检测 | docs-as-code + hooks / CI |
适用范围:项目级(而非个人偏好级)的协作约定,Cursor、Claude Code、Copilot 等通用。下面每层都给能直接抄的例子。
背景:它越能干,我越累
先说为什么需要这套东西。你早就过了"让它补两行"的阶段,现在是一句话写功能、跨文件改、甚至开 agent 丢一串任务。它接得住,但越放手,下面三个坑越常见:
-
失忆:新会话一开,项目的命名、分层、依赖注入约定全忘光,凭它自己的习惯来。上周纠正过的,这周原样再犯。
-
盲签:改个小功能顺手动了五个文件、三百多行。你清楚该逐行看,但实际扫两眼就点了「接受」,风险悄悄签进去。
-
失踪:它上个月写的某份设计文档,叫啥、放哪了?聊天记录里翻十分钟也找不着。
根因只有一个:它不知道你项目的隐性约定,而这些约定从来不在模型权重里。解决方式不是换更强的模型,而是把约定显式化、结构化地喂给它——这就是上下文工程要干的事。
6 层规矩,逐层拆
声明:这 6 层不是设计出来的,是按我"撞墙"的顺序排的。前四层一路在"加"规矩,第五层开始反过来"减"。
① 必读须知 —— 治"失忆"
问题:新会话对项目零认知,技术栈、命名、分层全靠蒙,蒙出来的代码处处返工。
做法:把项目最要紧的约定写成一份开工必读文件,让工具在每个会话自动加载——Cursor 用 .cursorrules / .cursor/rules,Claude Code 用 CLAUDE.md,跨工具可用 AGENTS.md。
# 项目须知(AI 开工前必读) ## 技术栈 TypeScript + React 18 + Fastify + PostgreSQL(Prisma) ## 命名 - 组件 PascalCase,函数 camelCase,常量 UPPER_SNAKE - 文件名 kebab-case;类型定义统一放 `types/` ## 分层 - controller 只做编排与参数校验 - 业务逻辑进 service;数据访问进 repository - 禁止在 controller 里直接写 SQL / 调 ORM ## 红线 - 不要改 `legacy/` 目录(待迁移) - 金额一律用 Decimal,禁用 float
效果:新会话读一遍就上道,不用每次从头交代。注意——这份文件要短、要稳定,否则就会埋下第 ⑤ 层的雷。
② 命名与登记 —— 治"失踪"
问题:AI 产出的文档、脚本、设计稿越堆越多,没命名规矩也没台账,几个月后想复用却找不到、对不上。
做法:给产物定命名规范,再维护一份索引(登记册),每份有编号、有归属、可检索。
docs/ ├── registry.md # 索引:编号 | 标题 | 类型 | 关联模块 | 日期 ├── design/INF-001-导出权限设计.md └── design/INF-002-对账任务方案.md
把"生成产物时顺手登记"写进第 ① 层的须知里,AI 产出时就会自动补登记,不再是一笔糊涂账。
③ 需求编译 —— 把返工从"运行期"挪到"编译期"
问题:你说"帮我加个导出",它二话不说写两百行,跑起来才发现——导的是全部字段,你要的是按权限过滤。白干。
做法:口头需求别让它直接上手,先让它把需求拆成一份你能 review 的清单/方案(plan),确认后再写。Cursor 的 Plan、Claude Code 的计划模式都能干这事。
理解偏差在它动手前就暴露,相当于把返工从"运行期"挪到了"编译期"——编译期报错永远比线上回滚便宜。一个简单的 plan 提示约定:
任何超过单文件的改动,先输出: 1) 你的理解(一句话) 2) 改动文件清单 3) 关键决策点与取舍 我确认后你再动手。
④ Review 链 —— 让 AI 先审一遍 AI
问题:一次 diff 五个文件、三百行,逐行 review 看不过来,只能凭感觉点「接受」。
做法:落地前,让 AI 拿一份检查清单先审自己写的代码——Claude Code 可以挂一个 review 子代理 / 自定义命令,Cursor 可以用专门的 review prompt,再配 pre-commit 兜底。
# review checklist(让 AI 自审,输出存疑点而非"看起来没问题") - 是否动了须知里的红线(legacy/、金额类型)? - 有无未处理的错误分支 / 静默 catch? - 有无重复实现已有 util? - 新增依赖是否必要、是否在白名单? - 输出:仅列出"需要人确认"的 N 处,附文件:行号
我不再盲签三百行,只盯它标出来的几处,漏的问题明显少了。
转折点:前四层一路在"加"规矩。但加到一定程度会反噬——第 ⑤ 层开始,要学着"减"。
⑤ 按需激活 —— 规则膨胀,它反而不听
问题:越怕它忘,越往规则文件里堆,从 30 行堆到 120 行。结果堆得越长,它该犯的错照样犯。
排查发现:不是它没读,是被一大坨规矩淹了,而且规则之间会打架。比如同时写:
1. 函数不超过 50 行 2. 所有异常必须就地处理
函数写到 49 行刚好要加异常处理,是截断还是接着写?两条都在抢优先级,它哪条都执行不好。再叠加每次全量塞进上下文,还白烧 token。
做法:把"一个全局大文件"拆成"按场景触发的小规则"。Cursor 的 .cursor/rules/*.mdc 支持用 frontmatter 的 globs 做按需加载:
--- description: 测试规范 globs: **/*.test.ts,**/*.spec.ts alwaysApply: false --- - 用 Vitest,断言必须覆盖副作用,不允许只断言不抛错 - mock 外部依赖,禁止真实网络请求
--- description: 接口契约 globs: api/**,src/routes/** alwaysApply: false --- - 出入参一律 zod 校验;错误用统一 AppError - 响应结构遵循 `docs/api-contract.md`
核心须知(alwaysApply: true)砍回 30 行出头,其余按文件类型/任务命中才加载。省下的 6~8k token 是次要的,关键是规则不打架了,该生效的那条才真生效。
立规矩本是为了让它听话,可堆太多它一条都听不进去。治理的转折点:从"加"到"该减则减"。
⑥ 同步与守卫 —— 别让文档跟着代码一起撒谎
问题:过了半年,让它照项目文档改东西,全改错了——文档停在三个月前,代码翻新过好几轮,它捧着张过期地图带路。
做法:让代码反过来驱动文档(docs-as-code):
-
用 Claude Code 的 hooks / Git pre-commit,在相关代码改动时触发对应文档的更新提示;
-
加一道漂移检测放进 CI:定期比对"代码现状 vs 文档声明",对不上就报警。
# CI 里的一个最小漂移检测思路(伪代码) # 比对 OpenAPI 实际生成结果与提交的 api-contract.md,不一致则 fail generate-openapi > /tmp/now.json diff <(normalize /tmp/now.json) <(normalize docs/api-contract.snapshot.json) \ || echo "::error:: 接口文档已漂移,请同步 docs/api-contract.md"
这么一来,AI 读到的永远是项目当下的样子,不是半年前的老黄历。
落地之后:三宗罪复诊
| 当初的坑 | 现在 |
|---|---|
| 失忆 | 开新会话丢一句"读须知",它就上道 |
| 盲签 | 它先自审、标出存疑点,我只盯那几处 |
| 失踪 | 产物有编号、进了登记册,几个月后照样可查 |
但别想太美:六层搭完不是一劳永逸。项目往前走,新规矩还会冒出来,老规矩过时了要主动删,偶尔还是会被它坑一次——只是擦屁股的频率低多了。该你拍板的地方一个都省不掉;它省下的,是来回返工、反复纠正的力气。
一张速查表 + 写在最后
| # | 层 | 一句话怎么做 |
|---|---|---|
| ① | 必读须知 | 写一份开工必读 CLAUDE.md / .cursorrules,要短要稳 |
| ② | 命名与登记 | 产物命名规范 + registry.md 索引 |
| ③ | 需求编译 | 先出 plan/清单,确认后再写 |
| ④ | Review 链 | AI 拿 checklist 先审 AI,只看存疑点 |
| ⑤ | 按需激活 | 用 globs 按场景加载,别堆全局大文件 |
| ⑥ | 同步与守卫 | 代码驱动文档 + CI 漂移检测 |
这套东西在我这儿管用,但这是一张地图,不是能照抄的作业——每层怎么落地,得看你自己项目的栈和约束。我会把每一层单独展开写(含更完整的模板和踩坑细节),从第一层到第六层。
如果对你有帮助,点个赞 / 收藏,方便回头对着改。也想听听:你现在大概卡在第几层? 评论区聊聊,呼声最高那层我下一篇先写。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)