
2026 大模型横评实测:GPT-5.5 vs DeepSeek-V4-Pro vs GLM-5.2 vs Claude-Opus-4.8 同题对决,Claude 裁判打分结果出乎意料
目录
一、为什么要做这次对比
平时你用 AI,是不是打开一个模型 → 提问 → 看一眼答案 → 就信了?
实际上,同一个问题丢给不同的大模型,答案的差距可能比你想的大得多。GPT-5.5 可能给你极简版,DeepSeek 可能写得温情脉脉,GLM 可能句句带画面感,Claude 可能附上修辞注释教你"怎么写更好"。
这次我用 Tabbit 浏览器国际版 做了一次系统性的横向对比:四款 2026 年公认的顶流大模型,同一道题,同一套评分标准,由 Claude Opus 4.8 担任裁判——包括评它自己。
二、测试环境与工具
| 项目 | 说明 |
|---|---|
| 测试平台 | Tabbit 浏览器国际版(美团出品,集成 10+ 主流大模型) |
| 测试日期 | 2026 年 6 月 22 日 |
| 参赛模型 | GPT-5.5 / DeepSeek-V4-Pro / GLM-5.2 / Claude-Opus-4.8 |
| 裁判模型 | Claude-Opus-4.8(对所有模型进行统一评分,含自评) |
| 评分维度 | 字数控制、比喻生动度、受众区分度、可复用性 |
关于 Tabbit:这是一款由美团推出的 AI 浏览器,核心能力是 多模型同屏回答——你输入一个问题,它可以同时发给多个大模型,答案并排展示,还支持指定一个模型对所有回答进行对比分析。
三、测试题目
题目本身不难,但设计的巧妙之处在于:它要求模型针对不同受众切换表达方式——这正是检验语言能力、共情能力和"会不会说人话"的好方法。
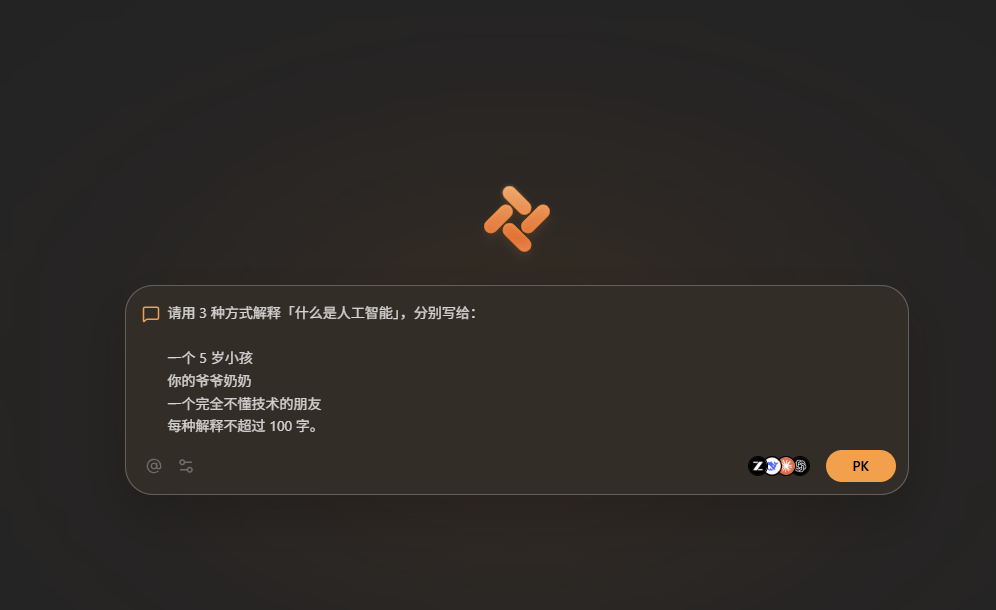
请用 3 种方式解释「什么是人工智能」:
1. 说给 5 岁小孩听
2. 说给爷爷奶奶听
3. 说给完全不懂技术的朋友听
每种解释不超过 100 字。
这道题的深层考察点:
- 受众感知力:能否准确判断不同人群的认知水平和用语习惯
- 语言适配力:能否在 5 岁 / 70 岁 / 30 岁之间无缝切换
- 字数控制力:100 字以内是否真正做到了精炼
- 创意与准确性的平衡:简化不等于失真
四、四模型回答概览
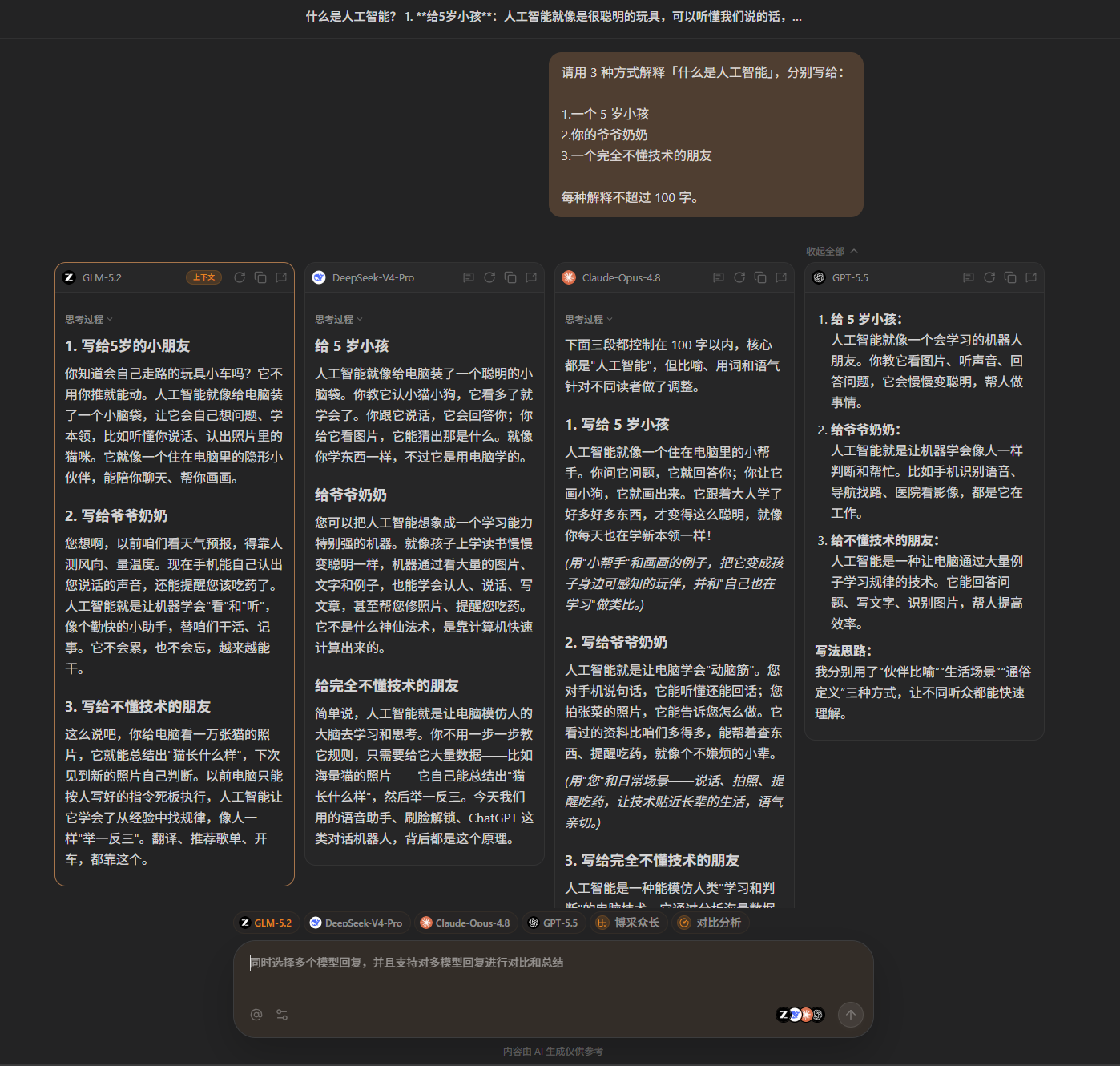
四份答案全部完成了任务,没有偏离题目要求。一个有趣的发现是:四个模型不约而同地使用了"猫的照片"作为解释机器学习的核心案例——它几乎成了 AI 科普的通用锚点。
但在细节上,差距远比预想的大。以下让 Claude 来逐一分析。
五、Claude Opus 4.8 裁判分析(全文)
注意:以下分析由 Claude Opus 4.8 独立生成,未做任何人工修改。Claude 在分析中对自己同样给出了客观评析。
5.1 四模型的共同点
四个模型在核心策略上高度一致:
- 核心比喻统一:都用了"从大量例子/数据中学习的聪明伙伴"来通俗化 AI 概念
- 受众分层清晰:给孩子的回答用"玩伴 / 小帮手"比喻;给长辈的回答使用"您"并引入生活场景(语音助手、提醒吃药);给朋友的回答采用"数据找规律"的轻量技术定义
- "猫的照片"成为通用教材:多个模型不约而同地用它来解释机器学习中"从样本中学习特征"的基本原理
这说明四款模型在 AI 科普的"正确姿势"上已形成默契。真正的分水岭在细节。
5.2 逐模型评析
GPT-5.5
定位:极简稳妥派
优点:
- 三段字数均在 40~45 字,远低于 100 字限制,留下了近一倍的余量
- 「伙伴比喻 → 生活场景 → 通俗定义」的三层定位逻辑清晰,没有跳跃感
- 整体风格干净利落,没有冗余修饰
不足:
- 比喻选择偏朴实,缺乏记忆点
- 给长辈段的措辞偏书面(如"判断"“识别语音”),亲切度明显不如另外三家
- 画面感较弱,读完后不太能留下印象
适合场景:你需要一个绝对安全、不出错、不超限的标准答案时,GPT-5.5 是最稳的选择。
DeepSeek-V4-Pro
定位:温暖走心派
优点:
- 语气在四个模型中最温暖,例子非常具体——“修照片”“提醒吃药”,贴近真实生活
- 「不是什么神仙法术,是靠计算机算出来的」这个表达精准击中了长辈群体对 AI 的认知顾虑(“这东西是不是有点邪乎”),消解感很强
- 朋友段的"举一反三"概念表述准确
不足:
- 朋友段篇幅偏满,接近甚至可能触碰 100 字上限,在严格审题场景下构成超字数风险
- 回答中出现了具体商业产品名,虽然增加了贴近感,但也引入了品牌依赖——产品一旦改名或下架,这段回答就过时了
- 「模仿人的大脑」是常见但轻微的简化——神经网络只是受大脑结构启发,并非真正意义上的"模仿大脑"
适合场景:长辈段的情感表达最到位,发家族群或解释给上了年纪的家人时,DeepSeek 的文字最容易被接受。
GLM-5.2
定位:画面感最强派
优点:
- 开场钩子在四个模型中表现最出色——「会自己走路的玩具小车」让孩子瞬间有画面,「您想啊,以前看天气预报得靠人测风向」用对比手法激活长辈的生活记忆
- 口语化引导词(“这么说吧”“您想啊”)让三段回答读起来像面对面聊天,而不是在念稿
- 核心概念表述准确,没有因为口语化而牺牲准确性
不足:
- 篇幅在 80~92 字之间,整体偏满,留给读者的"呼吸感"较少
- 给孩子段的"总结本领"措辞对 5 岁略抽象(不过如果由大人转述可以弥补)
适合场景:需要直接念出来给人听的场景——口语化程度最高,转述成本最低,最适合当"脚本"使用。
Claude-Opus-4.8
定位:均衡贴心派 · 综合最佳
优点:
- 主体三段均控制在 70~75 字,留下了约 25% 的余量空间,既不浪费也不紧张
- 每段回答后附加了括号内的修辞注释,明确标注了该段的写作策略,并有一个清晰的递进框架:玩伴 → 生活帮手 → 数据学习工具。这个设计对"想学习怎么写"的用户价值最大
- 「不嫌烦的小辈」「您拍张菜的照片,它能告诉您怎么做」——既有情感温度,又给出了具体可操作的例子,准确且不生硬
- 受众区分在四模型中最精细,“长辈段不是简单降低难度,而是换一个切入角度”
不足:
- 附注和导语增加了整体阅读量。如果你只想要三段成品直接取用,会觉得略微啰嗦(但附注本身不算入 100 字限制,不影响题目合规)
适合场景:你是内容创作者或需要**学习"如何针对不同受众改写"**的人——Claude 的回答就是一份现成的改写教程模板。
5.3 维度雷达对比
| 评估维度 | GPT-5.5 | DeepSeek-V4-Pro | GLM-5.2 | Claude-Opus-4.8 |
|---|---|---|---|---|
| 字数余量 | ⭐⭐⭐ 最优(40~45字) | ⭐ 偏满(近上限) | ⭐⭐ 适中(80~92字) | ⭐⭐⭐ 充足(70~75字) |
| 比喻生动度 | ⭐⭐ 朴实 | ⭐⭐⭐ 温暖具体 | ⭐⭐⭐ 钩子最强 | ⭐⭐⭐ 均衡贴心 |
| 受众区分度 | ⭐⭐ 偏书面 | ⭐⭐⭐ 长辈段最暖 | ⭐⭐⭐ 最像对话 | ⭐⭐⭐ 层层递进 |
| 可复用性 | ⭐⭐ 标准答案 | ⭐⭐ 可用但含品牌名 | ⭐⭐ 口语化不易套用 | ⭐⭐⭐ 附修辞注释模板 |
| 综合排名 | ④ | ③ | ② | ① |
排名逻辑:Claude 在四维度中三个领先、一个并列领先,综合得分稳居第一。GLM 凭借最强的画面感和口语化能力拿下第二,DeepSeek 的长辈段情感分拉高了总分,GPT-5.5 的极简策略在"不出错"这个维度上是满分的,但在"出彩"维度上相对薄弱。
5.4 场景化推荐
不同使用场景下,最合适的模型是不同的。没有绝对的"最强",只有最适合当前任务的"最优解"。
| 你的使用场景 | 推荐模型 | 核心理由 |
|---|---|---|
| 🗣️ 直接念给三类人听 | GLM-5.2 | 口语化最强,像面对面聊天,转述成本为零 |
| 📝 学习「怎么针对受众改写」 | Claude-Opus-4.8 | 附带逐段修辞注释,可直接当改写模板复用 |
| ✅ 只要极简、不出错 | GPT-5.5 | 远超字数限制,没有任何越界风险 |
| 👴 单独给长辈解释 | DeepSeek-V4-Pro | 情感表达最温暖,"不是神仙法术"消解顾虑 |
六、实测启示:为什么不要再只用一个 AI
这次实测给我最大的感受不是"哪个模型更好"——而是:
1. 同一道题,四个模型的"人格"完全不同
- GPT-5.5 像一个追求效率的产品经理,干净利落但少点温度
- DeepSeek 像一个关心你的邻居大哥,例子贴地气、情感到位
- GLM 像一个会讲故事的朋友,一开口就有画面
- Claude 像一个既会写又会教的写作教练,不仅写出好答案,还告诉你为什么好
2. 多模型交叉验证的价值远超单个模型
单看任何一个模型的回答,你都会觉得"挺好的"。只有把它们放在一起对比,你才会发现:
- 原来给老人解释 AI,可以用"不是神仙法术"来消解顾虑(DeepSeek)
- 原来给小孩解释 AI,说"会自己走路的小车"比说"智能助手"更有效(GLM)
- 原来给朋友解释 AI,附上一个句式注释能让他们也学会怎么讲给别人听(Claude)
单个模型给你的是答案,多模型对比给你的是视角。
3. Tabbit 把"多模型对比"这件事的效率拉满了
在 Tabbit 出现之前,做一次同等质量的横向对比至少需要:
- 分别打开 4 个模型的网页或客户端
- 逐个粘贴同一道题
- 等所有模型输出完毕
- 手动复制到文档中对比
- 自己写分析(或者再开一个模型做分析)
现在在 Tabbit 里:一次输入,四屏同显,再点一下"生成对比分析",裁判报告就出来了。 这个效率提升对内容创作者、技术选型者、以及任何需要"多看一眼"的 AI 用户来说,都是质的改变。
七、总结与推荐
核心结论
| 结论 | 说明 |
|---|---|
| 总体最佳 | Claude-Opus-4.8(均衡性 + 可复用性领先) |
| 最佳口语 | GLM-5.2(画面感 + 代入感最强) |
| 最佳情感 | DeepSeek-V4-Pro(长辈沟通场景首选) |
| 最佳极简 | GPT-5.5(不出错、不超限、永远安全) |
| 最佳工具 | Tabbit 浏览器国际版(多模型同屏 + 自动横评) |
给你的建议
不管是做内容、写代码、还是日常办公,永远不要只信一个 AI 的答案。不同模型对同一个问题的理解角度可能完全不同,交叉验证才能帮你找到真正合适的那一个。
实测环境:Tabbit 浏览器国际版 | 2026 年 6 月 22 日
测试模型:GPT-5.5 / DeepSeek-V4-Pro / GLM-5.2 / Claude-Opus-4.8
裁判模型:Claude-Opus-4.8
本文由作者基于 Tabbit 实测结果撰写,Claude Opus 4.8 对比分析部分为模型自动生成。文中观点仅供参考,模型能力随版本迭代可能发生变化。
如需转载,请注明出处。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)