
实战:用 Codex + Obsidian 搭建本地爆款选题库工作流
如何高效收集并分析社交媒体上的爆款内容,是每个内容创作者和运营团队的痛点。
传统的做法是手动复制粘贴,或者使用不稳定的爬虫工具。
然而,频繁的登录限制、验证码校验以及平台风控,让自动化爬取变得困难重重。
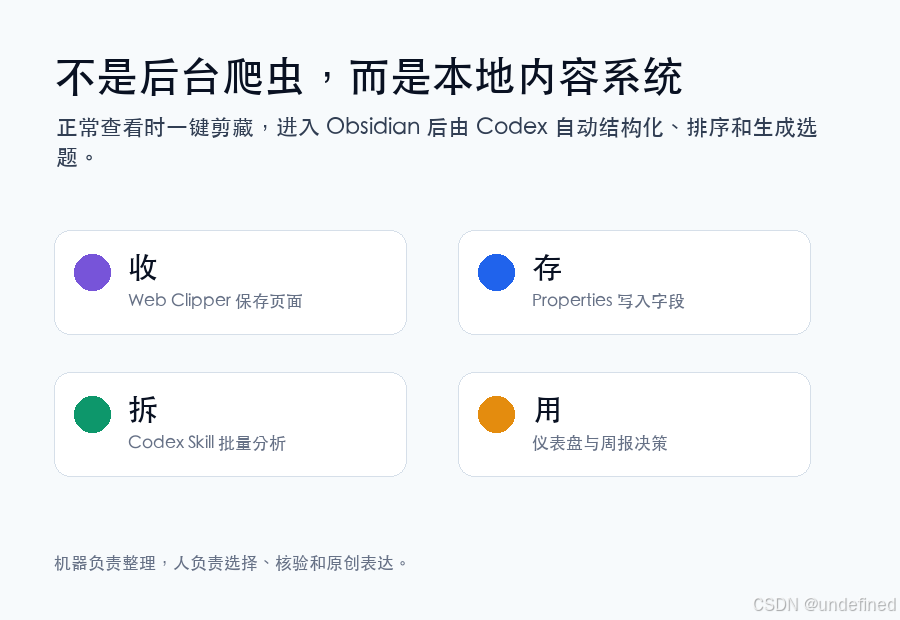
今天分享一套真正稳定、安全的闭环方案:Codex + Obsidian 本地爆款工作流。
这套方案的核心逻辑是:不在后台强行爬取数据,而是在你正常浏览网页时,利用 Obsidian 官方插件一键剪藏。
内容进入本地知识库后,再由 Codex 自动进行结构化拆解、计算爆款指数,并生成选题周报。
这套工作流不依赖任何违规接口,完全运行在你的本地环境,既保证了数据安全,又极具扩展性。
---
为什么选择 Codex + Obsidian?
在内容管理中,工具的分工非常关键。
Obsidian 负责安全存储。
通过网页剪藏,所有内容都会以 Markdown 格式保存在本地磁盘。
你可以利用 Obsidian 的 Properties(属性)功能,将标题、链接、互动数据等字段进行结构化管理。
Codex 负责智能执行。
它能直接读取你的本地 Vault(仓库),批量补全缺失字段、运行分析脚本,并根据历史数据自动生成选题建议。
两者的结合,打通了从“信息输入”到“选题输出”的完整闭环。

---
第一步:配置 Web Clipper 规范数据源
要建立高质量的选题库,首先要规范数据的录入格式。
我们使用 Obsidian 官方的 Web Clipper 浏览器扩展。
它支持自定义模板和变量,能够根据不同的网站自动提取关键字段。
针对爆款内容,我们可以设计一个专属的剪藏模板。
在 Web Clipper 中新建模板,并配置以下 YAML 属性:
---
title: "{{title}}"
source_url: "{{url}}"
collected_date: "{{date}}"
status: "待分析"
likes: 0
saves: 0
comments: 0
---设置触发规则,使其仅在目标平台页面激活。
当你浏览到有价值的内容时,点击 Clipper 插件,网页的核心文本和元数据就会被瞬间保存到本地的 10-爆款样本 文件夹中。
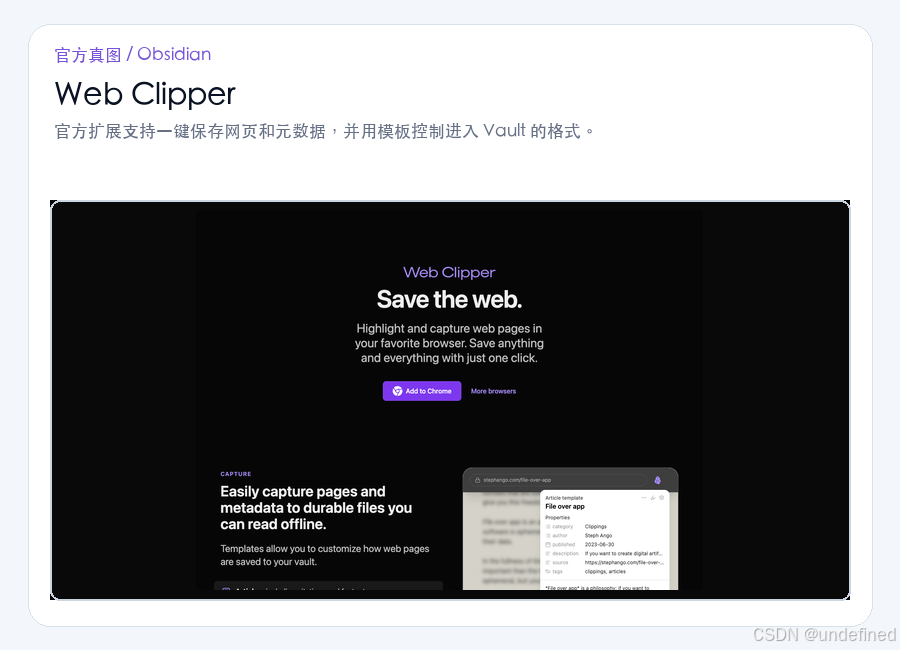

在实际操作中,建议人工顺手补充一下页面上的点赞、收藏和评论数。
虽然这一步看起来不够“全自动”,但它能彻底避开平台的反爬机制。
把最耗时的分类、拆解和分析工作留给 AI,是性价比最高的选择。
---
第二步:利用 Properties 构建结构化数据库
普通的收藏夹之所以会变成“内容坟场”,是因为缺乏结构化的检索维度。
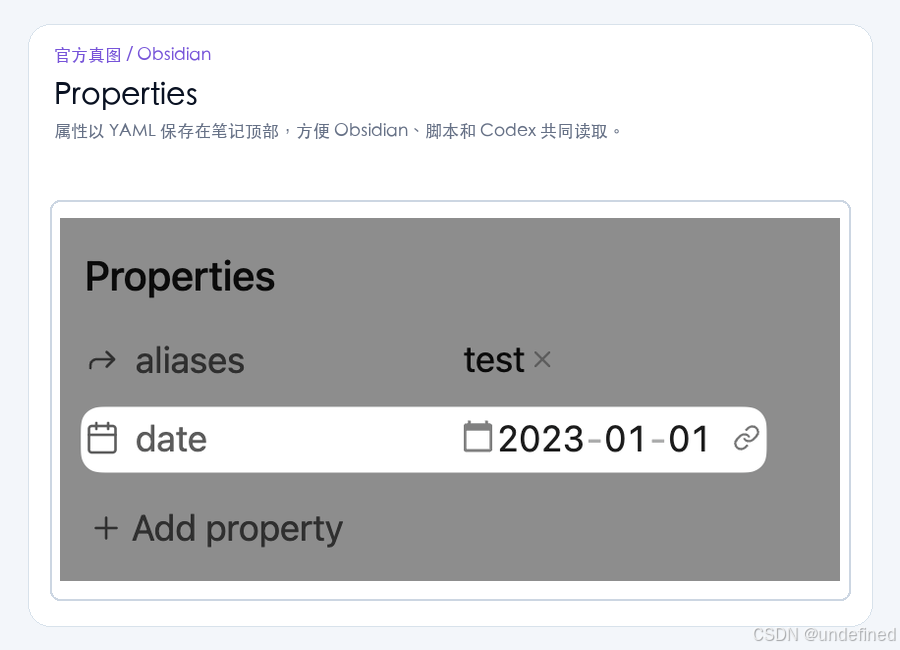
Obsidian 的 Properties 功能可以将笔记头部的 YAML 数据转化为可视化的属性字段。
在这套爆款库中,我们定义了以下核心字段:
topic:内容主题分类。hook_type:开头引入钩子的类型。structure:文章大纲结构。likes/saves/comments:互动数据。viral_score:内部爆款指数。status:处理状态(待分析/已分析)。
这些属性不仅方便我们日常筛选,也为后续 Codex 的批量处理提供了统一的数据接口。

---
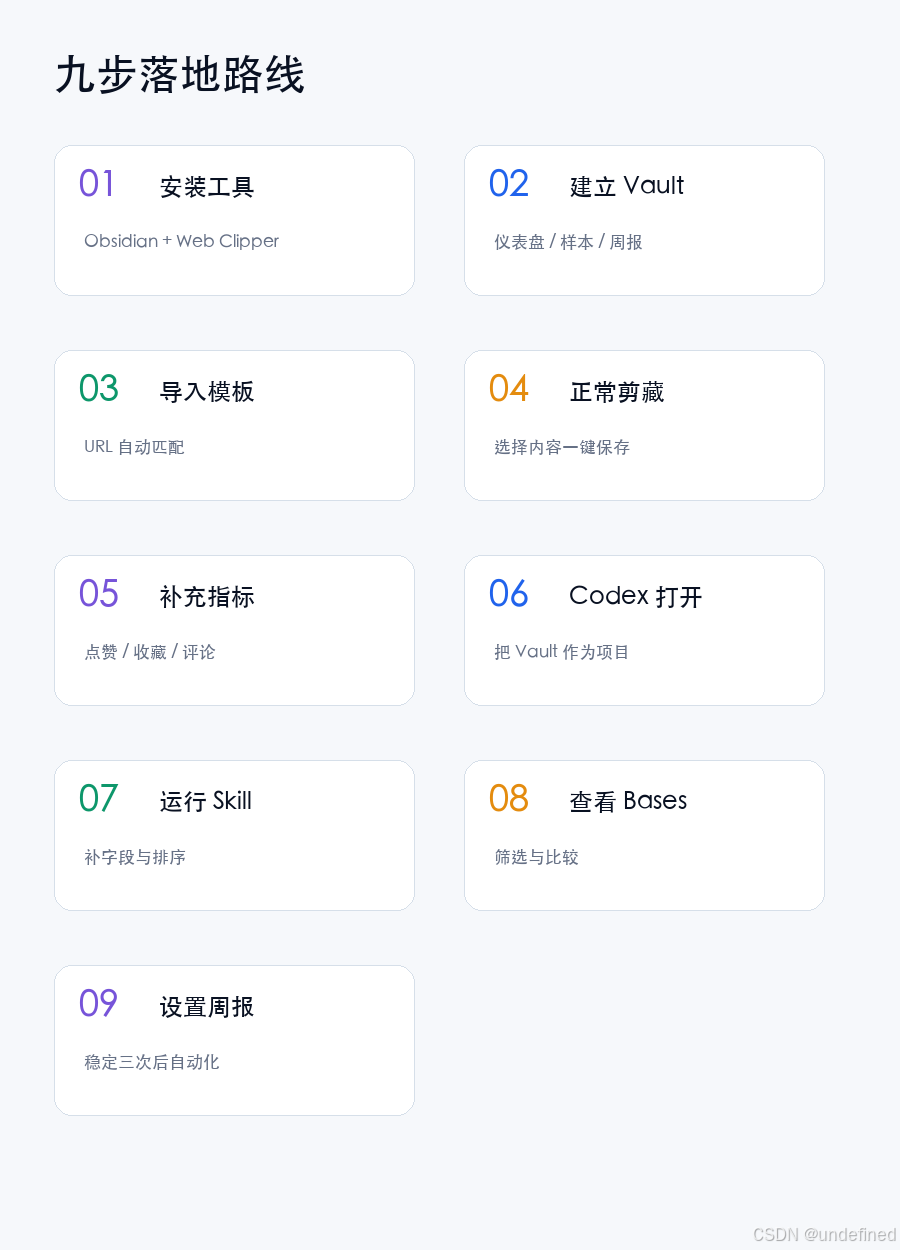
第三步:将 Obsidian 接入 Codex
打开 Codex 客户端,将你的 Obsidian Vault 文件夹作为项目导入。
此时,Codex 能够清晰地感知到你的本地目录结构:
├── 00-仪表盘
├── 10-爆款样本
├── 20-周报
├── 90-模板
└── .agents/skills
在运行分析任务前,我们需要为 Codex 配置底层的模型服务。
通常,这类 AI 编程与自动化工具支持多种登录方式。
除了常见的账号登录外,为了保证网络接入稳定性并进行精细的调用成本管理,我们通常会选择 API 登录方式。
在配置自定义 API 时,需要关注 API Key、Base URL 以及具体的模型名称。
本文使用 iThinkAPI 作为 OpenAI Compatible API 的演示环境。
你可以在 Codex 的模型服务配置中填写以下参数:


text
Base URL:https://token.ithinkai.cn/v1
API Key:YOUR_API_KEY
Model:以服务文档为准,最新模型 gpt-5.5、claude-opus-4-8、gpt-image-2 等可按文档查看;涉及图片生成时,以 0.05¥/图起、2k/4k 支持等服务文档说明为准。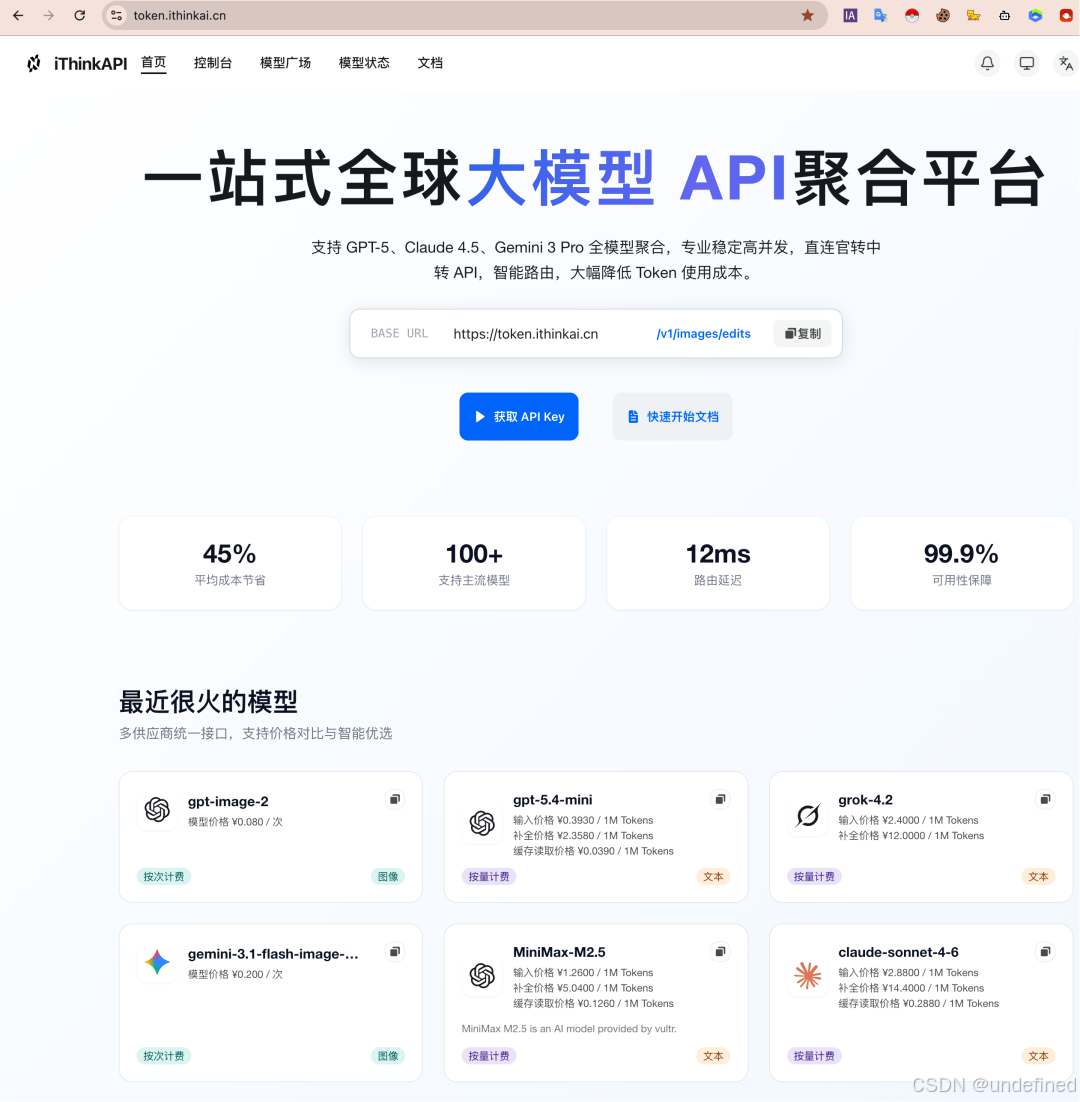
为了顺利完成配置,请按照以下步骤在管理后台进行操作:
第二步:挑选模型与确定分组
在进行模型配置前,我们需要进入模型广场。
利用 gpt、claude、image 等关键词筛选适合当前任务的模型。
根据不同的分析深度和处理速度,确认模型对应的分组或线路。
需要注意的是,同一个模型在不同分组下的调用质量、价格和可用状态可能存在差异,具体请以页面和服务文档为准。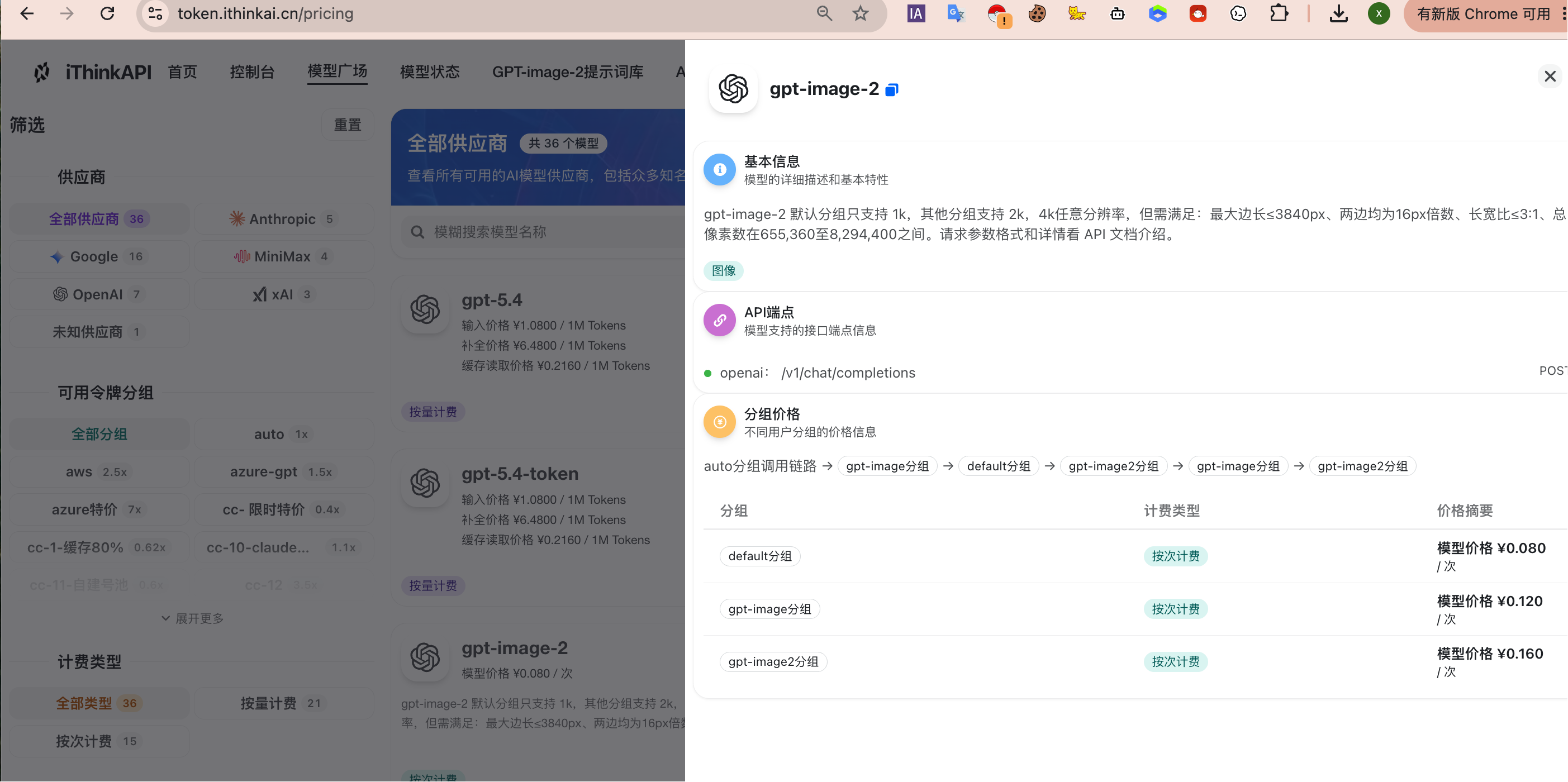
第三步:创建 API 令牌
确定模型后,进入控制台的令牌管理页面。
点击添加令牌,并将其绑定到上一步选中的模型分组。
如果不确定具体的模型限制,可以先不填写限制条件。
创建成功后,复制生成的 API Key。
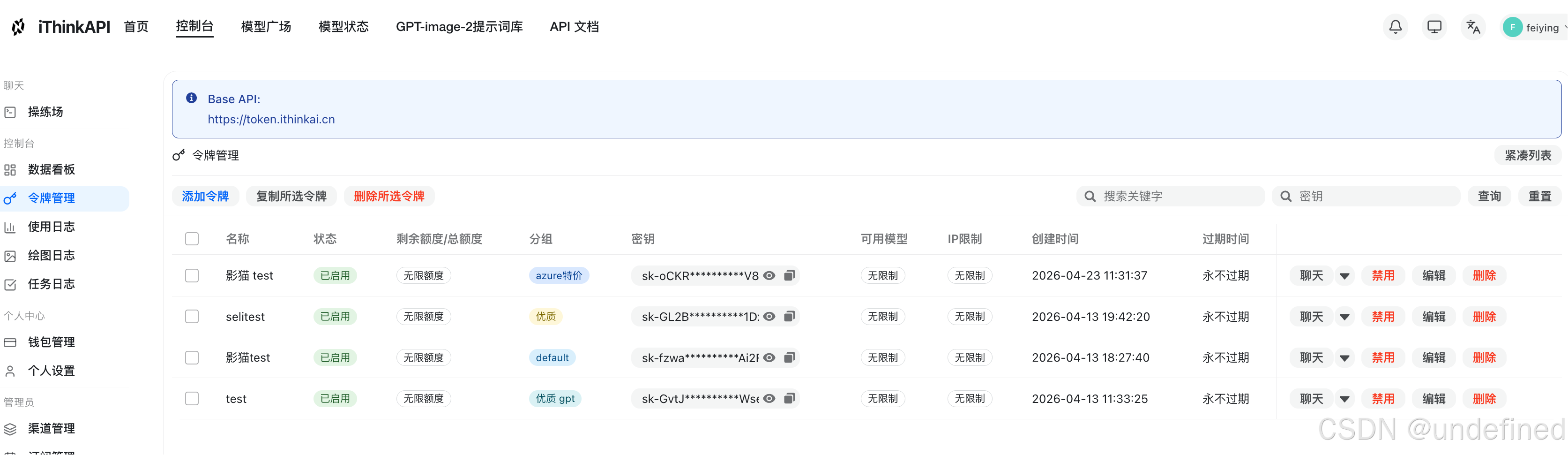
回到 Codex 的模型配置界面,填入对应的 API Key、Base URL 和 Model 名称,进行连接测试。
---
第四步:设计内部爆款指数算法
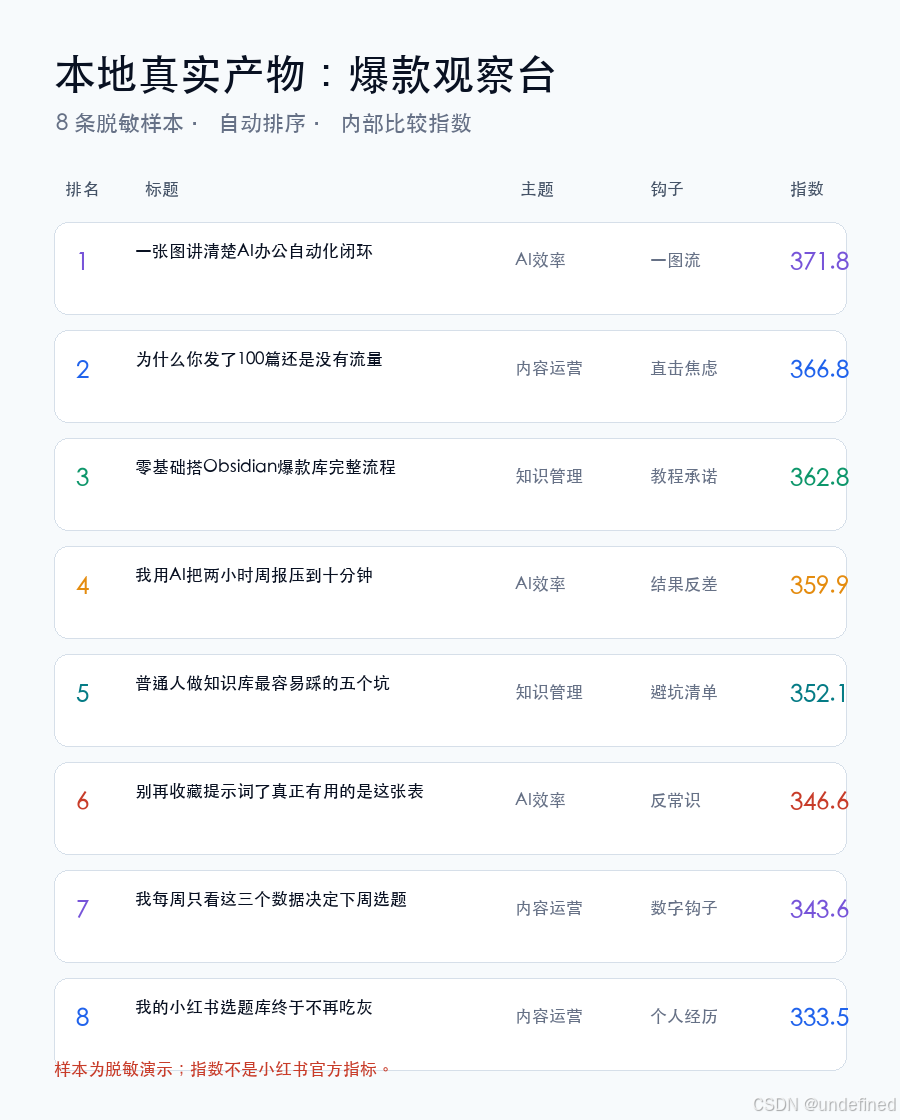
在分析样本时,我们不能只看单一的点赞数。
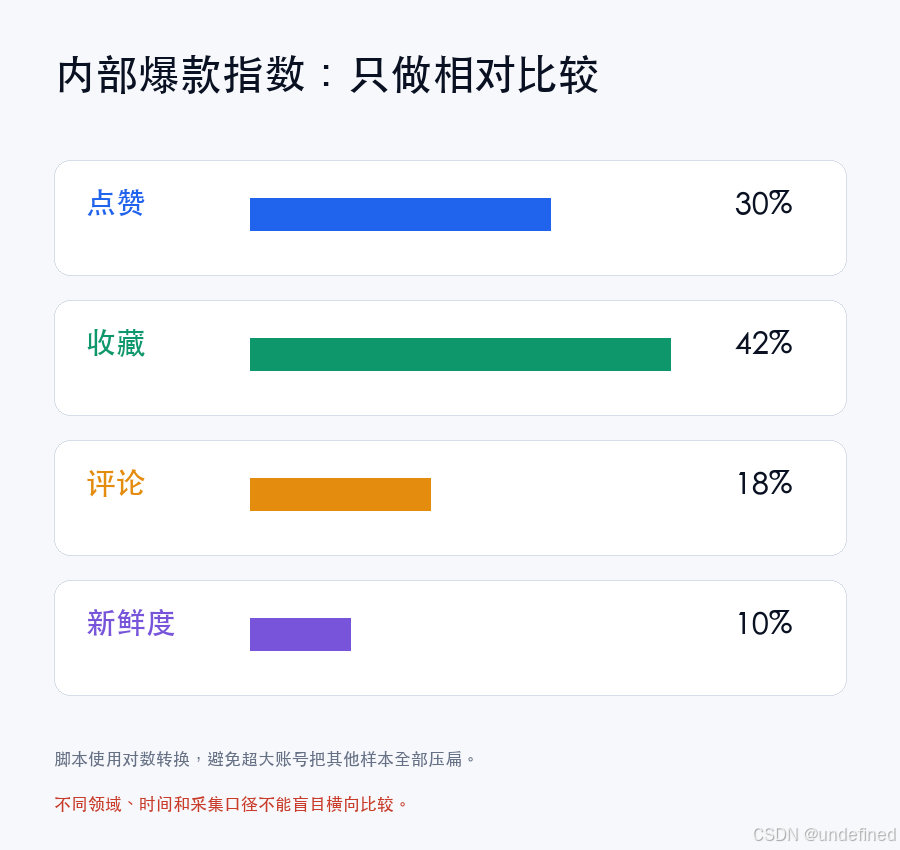
为了更客观地评估样本的参考价值,我们需要在本地计算一个“内部爆款指数”。
我们可以通过编写一个简单的计算公式,并让 Codex 批量执行:
$$\text{Viral Score} = (Saves \times 0.42) + (Likes \times 0.3) + (Comments \times 0.18) + (Freshness \times 0.1)$$
在这个公式中:
- 收藏数(Saves)赋予最高权重(42%),因为收藏代表了深度实用价值。
- 点赞数(Likes)权重设为 30%,代表即时认同感。
- 评论数(Comments)权重设为 18%,代表话题讨论度。
- 新鲜度(Freshness)占 10%,对近期发布的新内容给予适度加权。
为了避免头部大号的极端数据破坏整体分布,在实际脚本中,我们可以引导 Codex 使用对数转换(Log Scale)来平滑数据。
配置完成后,Codex 会自动扫描 10-爆款样本 文件夹,读取每篇笔记的互动数据,计算出指数并写回 Properties 中。
---
第五步:使用 Bases 呈现选题看板
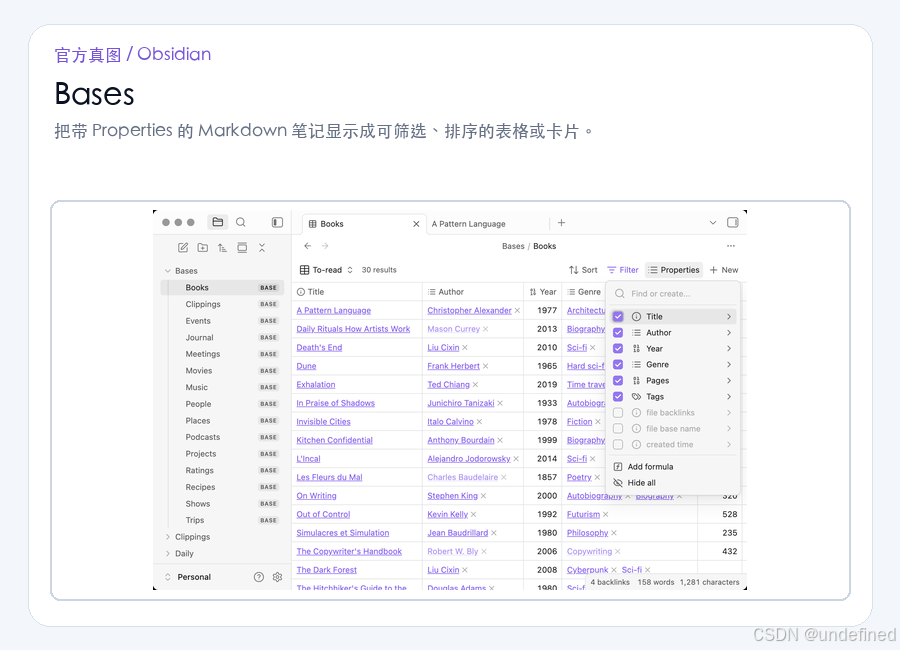
当本地笔记拥有了结构化的属性后,我们可以利用 Obsidian Bases 插件将它们聚合呈现。
Bases 可以将 Markdown 笔记渲染成类似于 Notion 的多维表格或看板。
你可以轻松实现以下筛选和排序:
- 按
viral_score降序排列,快速找出最值得拆解的黄金样本。 - 筛选
status为“待分析”的笔记,一键查阅新入库的内容。 - 按
topic分组,清晰查看各个细分领域的样本储备。
这种本地数据库的形式,既保留了 Markdown 的轻量和自主性,又获得了强大的数据组织能力。
---
第六步:将分析流程固化为 Codex Skill
为了让这套工作流能够长期稳定运行,我们需要将操作步骤固化为 Codex Skill。
在项目目录的 .agents/skills/xhs-trend-library/ 下创建 SKILL.md。
在其中明确定义 AI 的工作边界和执行逻辑:
# Skill: 爆款内容拆解与选题生成
## 运行限制
- 仅读取 Vault 本地已有笔记,严禁访问外部未授权链接。
- 补全属性时,若数据缺失必须标记,严禁编造任何互动指标。
- 生成选题时,必须结合用户自身的真实案例,严禁直接复制原作者的标题和正文。
## 执行步骤
1. 扫描 `10-爆款样本` 目录下 `status` 为 "待分析" 的文件。
2. 提取文本,分析其主题、开头钩子类型及大纲结构,并写入对应的 Properties。
3. 计算并更新 `viral_score`。
4. 将处理完的文件状态更新为 "已分析"。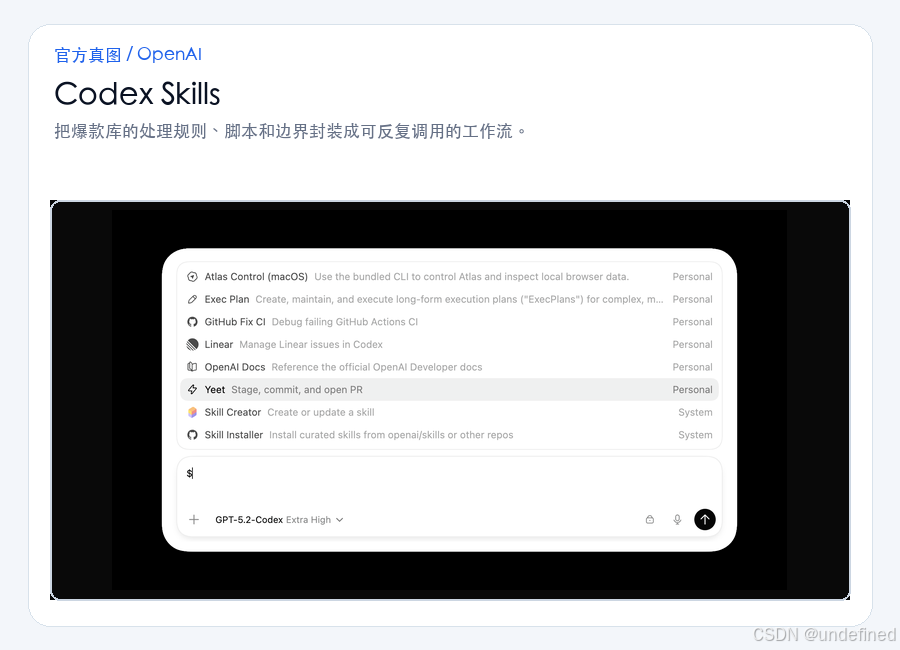

通过这种方式,你只需要在 Codex 中输入简单的指令,它就会严格按照 Skill 定义的规范去执行,避免了因提示词漂移导致的输出不稳定。
---
第七步:自动生成选题周报与复盘
当样本积累到一定量后,我们可以让 Codex 定期生成选题周报。
周报不仅会汇总本周新增的爆款趋势,还会深度拆解高频出现的开头钩子。

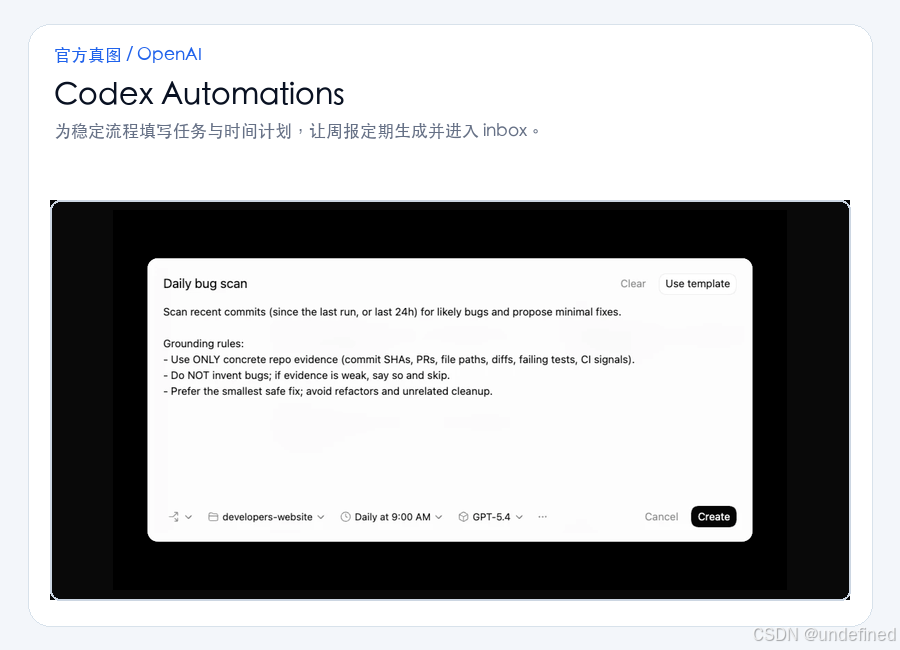
为了进一步释放生产力,我们还可以利用 Codex Automations 设置定时任务。
例如,设定每周五下午自动运行分析脚本,更新仪表盘并生成周报草稿。
需要注意的是,在运行本地 Automation 时,需要确保你的电脑处于开机状态,且 Codex 客户端正在运行。

---
实操避坑与使用建议
在搭建和运行这套系统的过程中,有几个关键点需要注意:
1. 明确筛选标准,不盲目追求高赞
并不是所有高赞内容都值得收录。建议优先保存以下四类样本:
- 收藏率极高的教程、工具清单或模板。
- 评论区讨论热烈、暴露出用户真实痛点的内容。
- 与你自身定位高度相关,且能用你自己的案例进行重写的话题。
- 结构清晰、逻辑可复用的框架。

对于纯情绪宣泄、时效性过强或无法核实事实的内容,建议直接忽略。
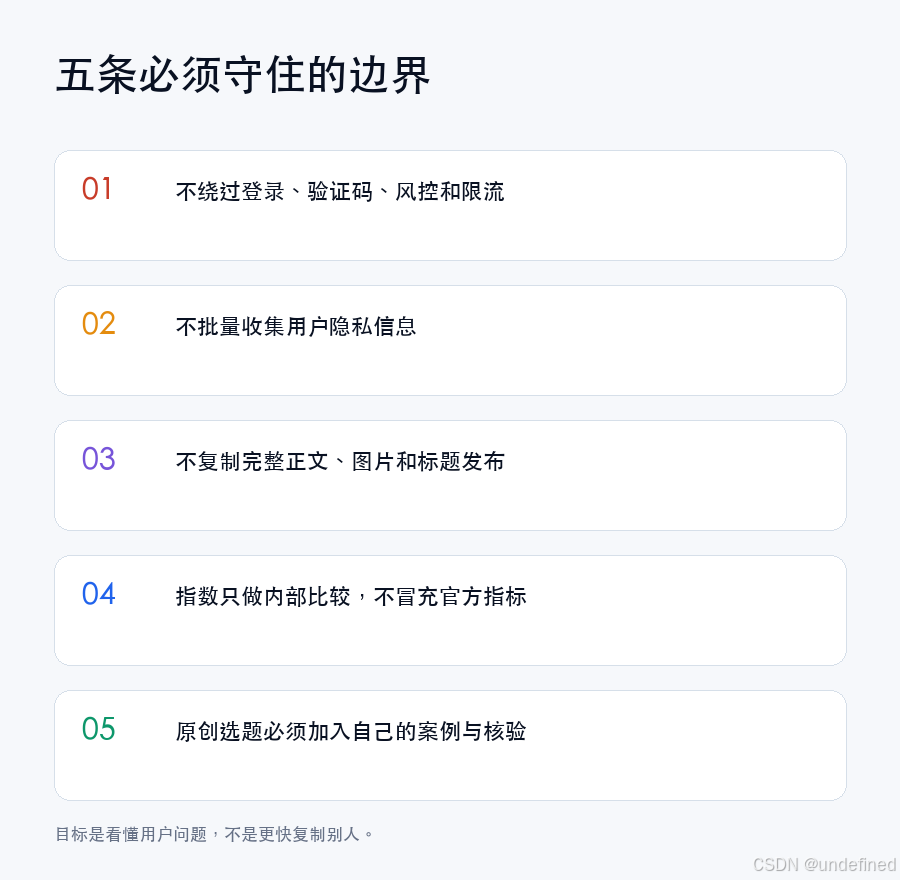
2. 守住合规与版权边界
在享受 AI 带来便利的同时,必须坚守合规底线:
- 绝不使用任何自动化爬虫去强行突破平台风控。
- 爆款库仅作为内部选题和结构参考,严禁直接洗稿或抄袭他人的原创图文。
- 在最终发布内容前,必须进行人工事实核查,并加入自己的真实见解。
---
写在最后
这套 Codex + Obsidian 工作流的真正价值,不在于追求“全自动抓取”的黑科技感。
而在于它帮你建立了一个本地的内容资产进化系统。
Web Clipper 负责精准输入,Obsidian 负责结构化沉淀,而 Codex 则通过强大的模型服务,将这些静态的数据转化为可执行的选题灵感。
把碎片化的收藏,变成有源之水。这才是内容创作者最坚实的生产力护城河。

参考资料:
1. Obsidian Web Clipper 官方文档:https://obsidian.md/clipper
2. Obsidian Properties 使用指南:https://help.obsidian.md/properties
3. OpenAI Codex Skills 开发者文档:https://developers.openai.com/codex/skills

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)