
OpenAI 新模型 GPT-5.5-Cyber 发布,安全测试超越 Claude Mythos 5
OpenAI 正进一步扩展其“Daybreak”网络安全计划,新增一款专为安全研究人员和防御者打造的专业AI模型。同时,Codex Security 也迎来了新功能升级,支持自动化的漏洞分析与修复。初步基准测试结果显示,该组合的表现已超越 Anthropic 的 Claude Mythos 5。
据 OpenAI 称,自今年 3 月发布以来,Codex Security 已分析了超过 3 万个代码库中的 3000 万次代码提交,并识别出 7 万个经人工审核确认已修复的问题。此外,还有超过 50 万份报告被系统自动判定为已解决。
尽管各类 AI 工具在发现新漏洞方面已展现出强大的能力,但在漏洞评估、修复以及安全补丁的部署环节仍存在明显短板。OpenAI 此次旨在通过推出专为该领域定制的工具来解决这一问题,从而减轻安全团队的工作负担。
更新后的 AI 代理现在能够进行深度的代码分析、审查变更、追踪攻击路径、生成安全报告,并为后续的人工审查准备定制化的修复补丁。该工具还支持整合漏洞赏金报告、安全公告和工单系统等外部数据源,其分析结果可直接集成到现有的漏洞管理系统中。
OpenAI 表示,GPT-5.5-Cyber 将仅向经过验证的防御者开放。为此,公司正与美国人工智能标准与创新中心(CAISI)、国家网络总监办公室(ONCD)以及科学与技术政策办公室(OSTP)等美国政府机构保持密切合作。
初步测试结果令人瞩目
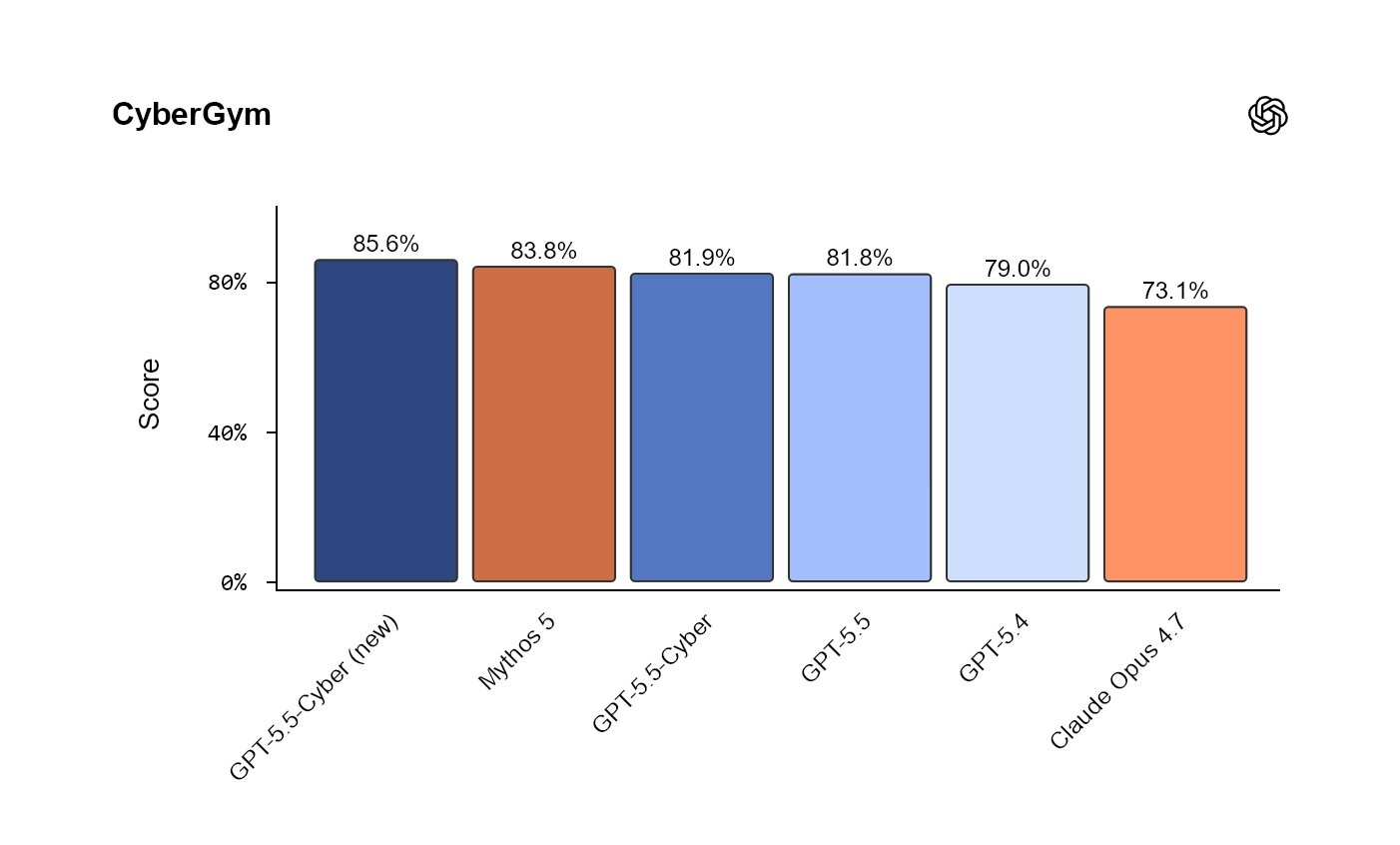
新系统的首批基准测试结果十分出色。在 OpenAI 自有的 CyberGym 基准测试中,GPT-5.5-Cyber 取得了 85.6% 的高分。作为对比,常规版 GPT-5.5 的得分为 81.8%,而 Anthropic 此前以 83.8% 的成绩领跑的 Claude Mythos 5,如今已被 OpenAI 重新超越。
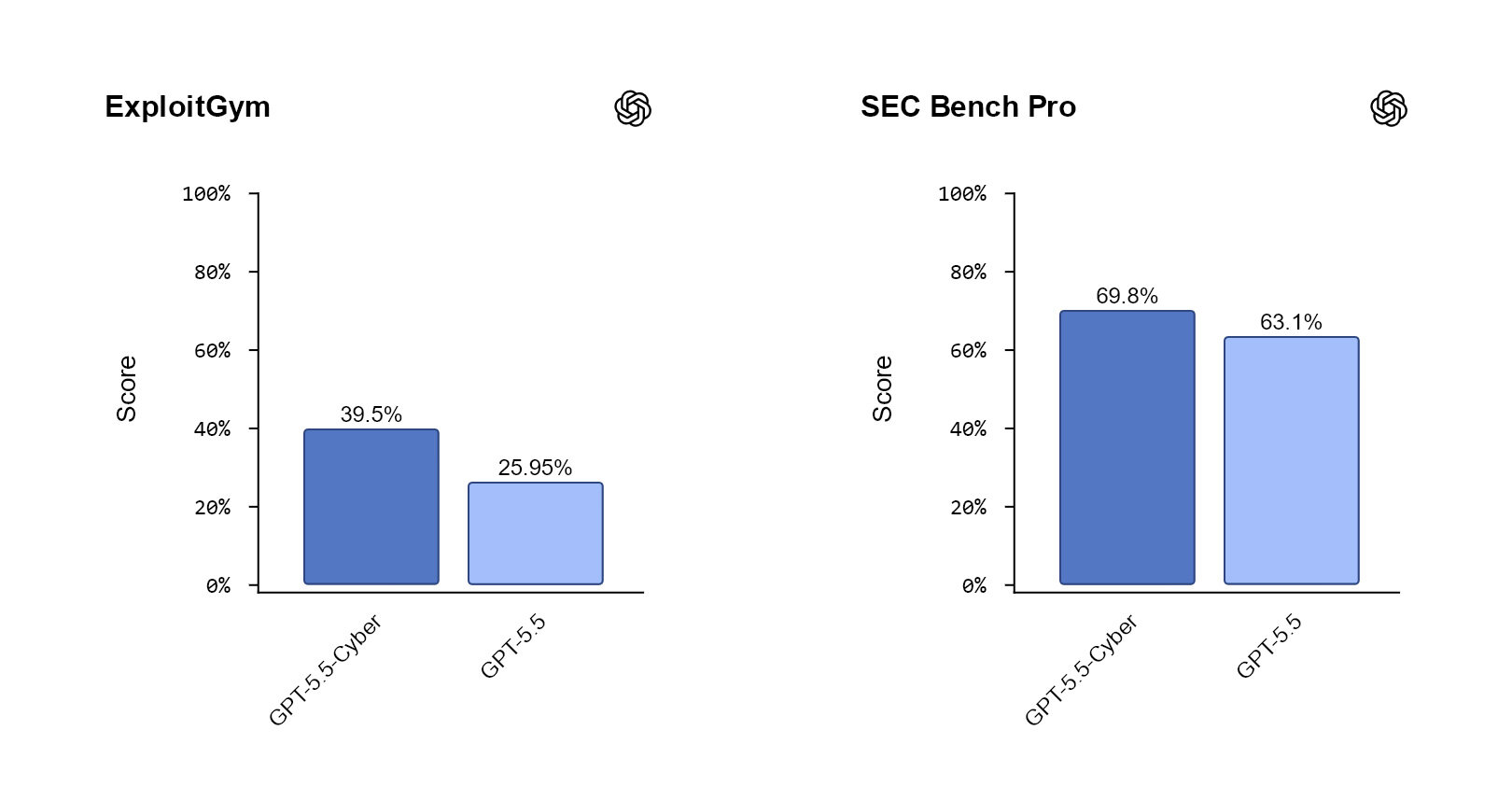
在 ExploitGym 测试中,差距更为显著:GPT-5.5-Cyber 得分达到 39.5%,而 GPT-5.5 仅为 25.95%。在 SEC-Bench Pro 测试中,该模型同样以 69.8% 的得分领先于得分 63.1% 的基础模型。
在 Anthropic 凭借 Claude Mythos 5 惊艳 AI 行业之后,竞争对手们现已走出观望状态并大幅追赶。OpenAI 与 Anthropic 在网络安全这一新赛道上的直接竞争正日益激烈。
此外,OpenAI 通过 Daybreak 网络安全合作伙伴计划,向安全厂商和服务提供商开放了其技术。首批合作伙伴包括埃森哲(Accenture)、阿卡迈(Akamai)、思科(Cisco)、Cloudflare、CrowdStrike、IBM、Palo Alto Networks、Proofpoint、SentinelOne、Wiz 和 Zscaler 等。这些企业可通过“可信访问”模式,将 GPT-5.5-Cyber 集成到其产品和服务中。
与此同时,OpenAI 联合 Trail of Bits、HackerOne 和 Calif 等机构发起了“Patch the Planet”倡议,旨在利用 AI 辅助分析与人类安全专家的结合,进一步加固关键开源基础设施的安全性。
OpenAI 还扩大了与澳大利亚、加拿大、法国、德国、日本和韩国等多国政府及机构的合作。欧盟网络安全局(ENISA)等欧洲机构也加入了这一合作网络。其核心目标始终是更好地保护关键基础设施和国家网络免受网络攻击的威胁。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)