
29.多模态部署:VLM、语音、视频理解
多模态部署:VLM、语音、视频理解
《大模型知识与部署》系列 · No.29 / 35
适合人群:AI 工程师、应用架构师
阅读时间:约 25 分钟
写在前面
前面 28 篇我们讲的都是文本模型。这一篇要打开新的维度——多模态。
如果说 2023-2024 是 LLM 走向成熟的两年,那 2025-2026 就是多模态走向标配的两年:
- GPT-4o 端到端语音(2024)→ GPT-5 全模态(2025)
- Claude 3 视觉 → Claude 4 实时图像理解
- Gemini 1.5 长视频 → Gemini 2.5 视频生成
- Qwen-VL → Qwen3-VL → Qwen3-Omni
- DeepSeek-VL → DeepSeek-Vision3
多模态已经从"加分项"变成"必选项"。
如果你做过相关工作,下面这些问题应该不陌生:
- VLM(Vision Language Model)和普通 LLM 部署有什么区别?
- 怎么让 vLLM 跑视觉模型?
- 语音识别用 Whisper 还是 Paraformer?延迟怎么压?
- 视频理解(1 小时视频)实际能用吗?token 消耗多少?
- GPT-4o 那种实时语音对话怎么实现?
读完本文你将能:
- 区分 VLM、ASR、TTS、Video-LLM 各自的架构和部署难点
- 用 vLLM / SGLang 部署主流 VLM
- 搭建语音对话 pipeline(ASR + LLM + TTS)
- 处理视频理解的 token 爆炸问题
- 评估端到端多模态模型(如 GPT-4o-realtime)的工程成本
我们开始。
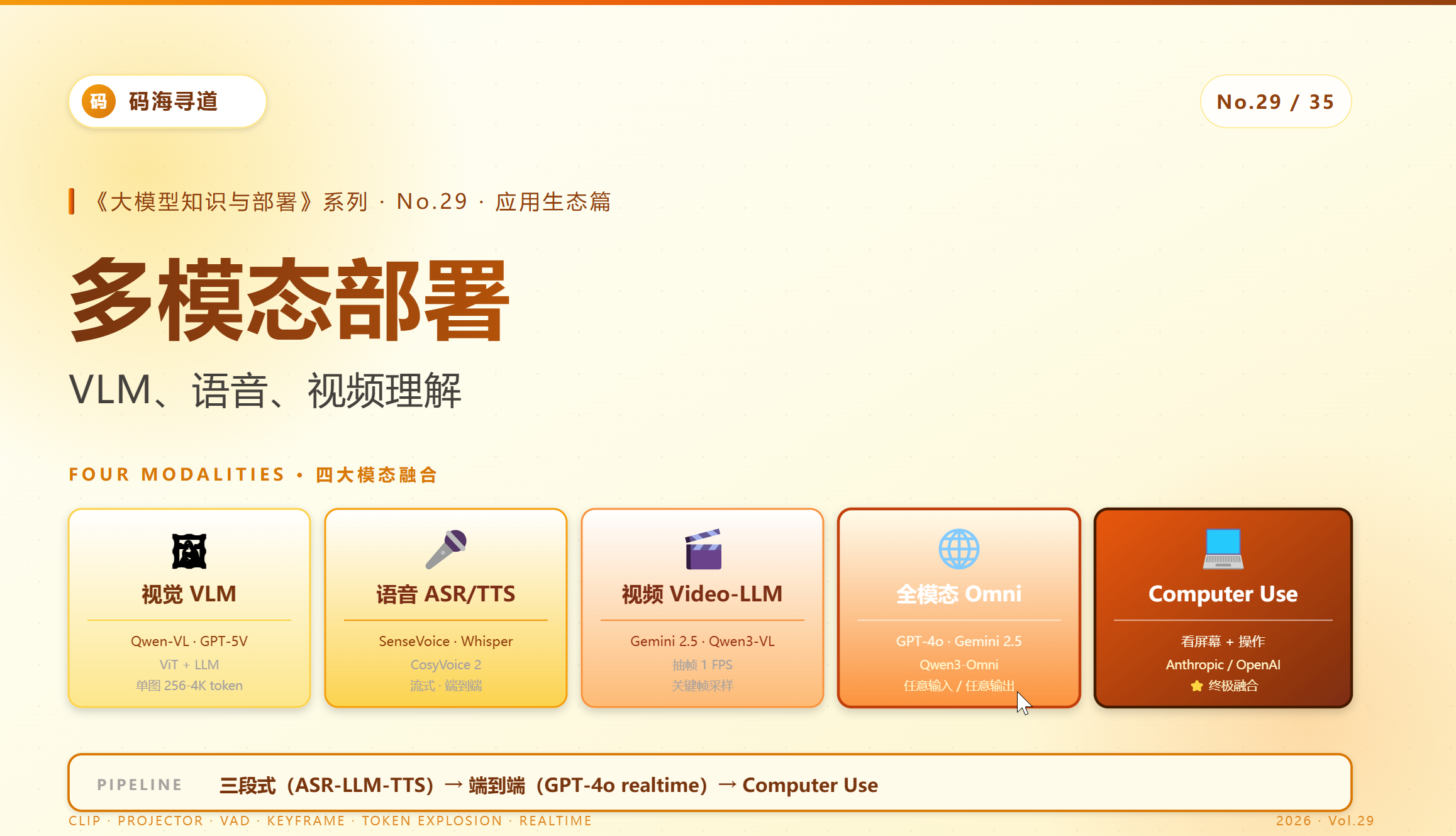
一、多模态的「四大场景」
1.1 应用版图
| 场景 | 形态 | 例子 |
|---|---|---|
| 图文理解 | 图 → 文 | OCR、图表分析、医学影像 |
| 图文生成 | 文 → 图 | DALL-E、Stable Diffusion、Midjourney |
| 语音对话 | 音 → 音 | 智能客服、AI 助理 |
| 视频理解 | 视频 → 文 | 视频摘要、监控分析、电商 |
| 全模态 | 任意 → 任意 | GPT-4o、Gemini 2.5、Qwen-Omni |
本篇聚焦理解类(输入多模态、输出文字)——这是 LLM 工程师最常做的。
1.2 多模态的工程挑战
1. 输入预处理重 ── 图像 / 音频 / 视频解码
2. Token 量爆炸 ── 1 张图 ≈ 几百-几千 token
3. 显存压力大 ── KV Cache 跟着膨胀
4. 推理框架支持参差 ── 不是所有都支持
5. 延迟难控 ── 多模态 prefill 慢
下面分模态深入。
二、视觉语言模型(VLM)
2.1 VLM 架构速通
主流 VLM 的架构都是 ViT + Projector + LLM:
图像
↓
ViT(视觉编码器)── 把图像切成 patch,每个 patch 一个 token
↓
Projector(投影层)── 把视觉 token 映射到 LLM 的 embedding 空间
↓
拼接 + 文本 token
↓
LLM(标准 Transformer)── 正常生成
关键认知:
从 LLM 视角看,图像就是「一段特殊的 token 序列」。
所以 LLM 的所有能力(in-context learning、Tool Use、推理)都能"白嫖"到多模态——这是 VLM 路线赢得行业认同的核心原因。
2.2 主流 VLM 横评(2026.05)
| 模型 | 视觉能力 | 部署友好度 | 价格 / 开源 |
|---|---|---|---|
| Claude Opus 4.7 | ⭐⭐⭐⭐⭐ | API | $15/M |
| GPT-5 Vision | ⭐⭐⭐⭐⭐ | API | $10/M |
| Gemini 2.5 Pro | ⭐⭐⭐⭐⭐ | API | $2.5/M |
| Qwen3-VL-72B | ⭐⭐⭐⭐ | 开源 ⭐ | Apache 2.0 |
| Qwen2.5-VL-32B | ⭐⭐⭐⭐ | 开源(vLLM ✓) | Apache 2.0 |
| InternVL3 | ⭐⭐⭐⭐ | 开源 | MIT |
| DeepSeek-VL3 | ⭐⭐⭐ | 开源 | MIT |
| Llama 4 Vision | ⭐⭐⭐⭐ | 开源 | Llama 协议 |
| MiniCPM-V 4.0 | ⭐⭐⭐ | 开源 + 端侧 | Apache 2.0 |
中文场景:Qwen3-VL 是当之无愧的开源王者。
2.3 视觉 Token 消耗
这是部署 VLM 时最常踩的坑——图像 token 远超想象:
| 模型 | 单张图 Token 数(典型) |
|---|---|
| GPT-4o (high detail) | 765 |
| Claude 4 | ~1500 |
| Gemini 2.5 | ~1000 |
| Qwen2.5-VL(动态分辨率) | 256 - 4000+ |
| InternVL3 | 256 - 2000+ |
举例:
用户上传 10 张 4K 图片,问"分析这些图"
token 消耗:~30,000 token(光是视觉部分)
如果还有几段长 prompt + RAG 上下文 → 上下文很快爆炸
优化建议:
- 主动指定较低分辨率(API 大都支持)
- 业务允许的话先压缩图片
- 监控每次请求的视觉 token 数
2.4 用 vLLM 部署 VLM
vLLM 0.6+ 全面支持主流 VLM:
# 部署 Qwen2.5-VL-32B
vllm serve Qwen/Qwen2.5-VL-32B-Instruct \
--tensor-parallel-size 4 \
--max-model-len 32768 \
--gpu-memory-utilization 0.92 \
--limit-mm-per-prompt image=10 \ # 单 prompt 最多 10 张图
--port 8000
关键参数:
--limit-mm-per-prompt:限制多模态输入数量- 别的参数和 LLM 部署一致
调用:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-32B-Instruct",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "这张图里有什么?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
)
完全 OpenAI Vision 兼容协议(第 19 篇讲过)。
2.5 VLM 部署的 5 个坑
坑 1:图片预处理不一致
症状:训练用 1024×1024 但推理传 4K,效果异常。
对策:
- 看模型的
image_size配置 - 客户端预处理统一
坑 2:批处理的尴尬
VLM 的 batch 不像 LLM 友好——不同图片预处理时间差异巨大。
对策:
- 客户端把图缩到固定尺寸
- 服务端用 vLLM 自动批处理
坑 3:显存涨幅超预期
VLM 显存 ≈ LLM 显存 × 1.3(ViT + Projector + 图像 KV)。
对策:
- KV Cache 量化
- 限制并发图片数
坑 4:长视频 / 长 PDF
PDF 转图 100 页 = 100 张图 ≈ 几万 token 一次性来。
对策:
- 分批处理(每次 5-10 页)
- 优先用文本提取(OCR + 文字模型)
坑 5:中英文 OCR 不均衡
很多开源 VLM 英文 OCR 强,中文一般。
对策:
- 中文场景优先 Qwen-VL / InternVL
- 重要场景接 PaddleOCR 等专门工具补强
三、语音模型:ASR + TTS
3.1 语音对话的标准 Pipeline
用户说话 ──→ ASR(语音→文字)
↓
LLM 推理
↓
TTS(文字→语音) ──→ 播放
这是 2024 年大多数"语音助手"的实现方式——三段式。但有明显问题:
- 延迟累加(每段 200-500ms,总计 1-2s)
- 不能处理情感、语调、打断
- 不能做"嗯嗯"等填充音
2024 末 OpenAI 推出 GPT-4o realtime,开创了端到端语音模型新范式。
3.2 ASR(Automatic Speech Recognition)
主流 ASR:
| 模型 | 准确率 | 速度 | 开源 |
|---|---|---|---|
| Whisper-large-v3 | 中文 96%、英文 99% | 慢 | MIT |
| Whisper-turbo | 中文 95%、英文 98% | 快 8× | MIT |
| Paraformer(达摩院) | 中文 97% | 快 | 开源 |
| SenseVoice(FunAudioLLM) | 中文 97%,情感识别 | 快 | 开源 |
| GPT-4o transcribe | 99%+ | API | $0.006/min |
实战推荐:
- 中文:SenseVoice 或 Paraformer
- 多语言:Whisper-turbo
- 极致质量:GPT-4o API
部署 SenseVoice
from funasr import AutoModel
model = AutoModel(
model="iic/SenseVoiceSmall",
trust_remote_code=True,
device="cuda:0",
)
result = model.generate(
input="audio.wav",
cache={},
language="auto", # 自动识别语言
use_itn=True, # 自动标点 + 数字归一化
)
print(result[0]["text"])
实测延迟(5 秒音频):~120ms(流式可降到 ~50ms)。
3.3 TTS(Text-to-Speech)
主流 TTS:
| 模型 | 自然度 | 中文 | 速度 |
|---|---|---|---|
| CosyVoice 2(阿里) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 中 |
| ChatTTS | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 快 |
| F5-TTS | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 中 |
| GPT-4o speech | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | API |
| ElevenLabs | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API |
当下开源王者:CosyVoice 2——支持 zero-shot 声音克隆、多语言、情感控制。
from cosyvoice.cli.cosyvoice import CosyVoice2
model = CosyVoice2("pretrained_models/CosyVoice2-0.5B")
# Zero-shot 声音克隆
audio = model.inference_zero_shot(
"你好,欢迎使用语音助手",
"这是一段参考音频",
"ref_audio.wav"
)
3.4 端到端语音对话(GPT-4o 式)
GPT-4o realtime 不走 ASR-LLM-TTS 三段式,而是直接 audio in → audio out:
音频输入 → audio tokens → 同一个 Transformer → audio tokens → 音频输出
优势:
- 延迟超低(< 320ms)
- 保留情感、语调
- 可被打断
- 听得懂"嗯"、"啊"等填充音
开源跟进:
- Qwen3-Omni:阿里 2026 推出,全模态 + 端到端
- GLM-4-Voice:智谱端到端语音
- Step-Audio:阶跃星辰
部署 Qwen3-Omni
vllm serve Qwen/Qwen3-Omni-7B \
--tensor-parallel-size 2 \
--enable-audio-output \ # 启用音频输出
--max-model-len 16384
调用流式:
# WebSocket 实时双向音频流
# 客户端持续推送 audio chunk
# 服务端持续返回 audio chunk
实测延迟:300-500ms(接近 GPT-4o)。
3.5 语音业务的工程化
完整语音助手架构:
浏览器/移动端
↓ WebRTC / WebSocket
语音网关(FastAPI + WebSocket)
├── VAD(语音活动检测,判断说没说话)
├── ASR(流式)
├── LLM(vLLM + 流式输出)
└── TTS(流式合成)
↓
返回音频流
关键技术点:
- VAD:用 Silero VAD 等模型识别说话开始/结束
- 流式 ASR:边录边识别,不等说完
- 流式 TTS:LLM 边输出文字边合成语音
- 打断处理:用户说话时立即停 TTS
四、视频理解
4.1 视频的 Token 灾难
视频 = 一系列图像帧。
1 分钟视频(30 FPS)= 1800 帧
每帧 ~500 token = 90 万 token
完了,连 1M 上下文都装不下。
所以视频理解必须抽帧 / 压缩。
4.2 主流抽帧策略
| 策略 | 思路 | 适合 |
|---|---|---|
| 固定帧率 | 每秒 1 帧 / 每秒 0.5 帧 | 一般场景 |
| 关键帧 | 检测场景切换抽 | 影视、教学 |
| 语义采样 | 用小模型判断"重要" | 监控 |
| 均匀采样 | 等间隔抽固定数量 | 长视频概览 |
实操推荐:
- 短视频(< 1 分钟):1 FPS
- 中等视频(1-30 分钟):0.5 FPS 或固定 100 帧
- 长视频(> 30 分钟):固定 200 帧均匀抽
4.3 主流 Video-LLM
| 模型 | 视频能力 | 备注 |
|---|---|---|
| Gemini 2.5 Pro | ⭐⭐⭐⭐⭐ | 业界最强 |
| GPT-5 Video | ⭐⭐⭐⭐⭐ | 接近 Gemini |
| Qwen3-VL(视频模式) | ⭐⭐⭐⭐ | 开源 |
| InternVideo2.5 | ⭐⭐⭐⭐ | 开源 |
| MiniCPM-V(视频版) | ⭐⭐⭐ | 端侧 |
4.4 部署示例
# 用 Qwen2.5-VL 处理视频
from qwen_vl_utils import process_vision_info
messages = [{
"role": "user",
"content": [
{"type": "video", "video": "path/to/video.mp4", "fps": 1.0},
{"type": "text", "text": "总结这个视频的内容"}
]
}]
# qwen_vl_utils 自动抽帧并转 token
image_inputs, video_inputs = process_vision_info(messages)
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-32B-Instruct",
messages=messages,
)
4.5 视频业务场景
| 场景 | 推荐方案 |
|---|---|
| 短视频内容审核 | 抽帧 5 张 → VLM |
| 视频摘要 | 抽 30-50 帧 → Gemini |
| 监控异常检测 | VAD + 关键帧 → VLM |
| 视频问答 | RAG over 视频帧 |
| 直播实时字幕 | 流式 ASR |
五、统一多模态:未来已来
5.1 全模态模型
2025-2026 的明星:
| 模型 | 输入 | 输出 |
|---|---|---|
| GPT-5 / o3 | 文 / 图 / 音 / 视 | 文 / 音 / 图 |
| Gemini 2.5 | 文 / 图 / 音 / 视 / 代码 | 文 / 图 / 音 / 视 |
| Claude 4.7 | 文 / 图 / 音 | 文 / 音 |
| Qwen3-Omni | 文 / 图 / 音 / 视 | 文 / 音 |
关键认知:
未来的「LLM」会消失——只有「多模态基础模型」。
5.2 一个统一模型 vs 多个专用模型
| 维度 | 统一模型 | 多专用模型组合 |
|---|---|---|
| 部署复杂度 | 低 | 高 |
| 资源消耗 | 中 | 高 |
| 模态间一致性 | 高 | 低 |
| 单模态极致质量 | 中 | 高 |
| 成本 | 中 | 中 |
结论:业务简单用统一,业务专业用专用。混合也很常见。
5.3 Computer Use 与 Browser Use
2024 末 Anthropic 推出 Computer Use——让 Claude 直接看屏幕 + 操作鼠标键盘。
LLM 看屏幕截图(VLM 能力)
↓
理解界面
↓
决定操作(click x,y / type "hello")
↓
执行
↓
看新截图
↓
...
这是多模态 + Tool Use + Agent 的终极组合,让 LLM 能用任何 GUI 软件。
主流方案:
- Anthropic Computer Use
- OpenAI Operator(2025)
- 开源 Browser-use / Skyvern
部署复杂度极高——需要虚拟机 + 屏幕截图 + 输入控制 + 安全沙箱。
六、生产实战:多模态客服 Demo
把前面的技术整合,做一个生产级多模态客服:
用户上传:图片(产品照) + 语音(描述问题)
↓
ASR 识别语音
↓
VLM 分析图片(识别产品 + 缺陷)
↓
RAG 检索:产品手册 + 历史工单
↓
LLM 生成回复 + 解决方案
↓
TTS 转语音回复
完整代码骨架:
async def multimodal_customer_service(audio: bytes, image: bytes):
# 1. ASR
text = await asr_model.transcribe(audio)
# 2. VLM 分析图片
image_analysis = await vlm.analyze(image, prompt="识别产品和问题")
# 3. RAG
docs = await rag.search(f"{text} {image_analysis}")
# 4. LLM 生成
response = await llm.generate(
system="你是客服专家",
messages=[{"role": "user", "content": f"""
用户语音问题:{text}
图片分析:{image_analysis}
相关文档:{docs}
"""}],
)
# 5. TTS
audio_response = await tts.synthesize(response)
return {
"text_response": response,
"audio_response": audio_response,
"image_analysis": image_analysis,
}
资源预估
跑这套服务需要:
| 组件 | 资源 |
|---|---|
| ASR (SenseVoice) | 1 × T4 GPU |
| VLM (Qwen2.5-VL-32B) | 1 × H100 |
| LLM (Qwen3-32B) | 1 × H100 |
| TTS (CosyVoice) | 1 × T4 |
| RAG (向量库 + embedding) | 单独 CPU 节点 |
| 合计 | 2 × H100 + 2 × T4 |
月 TCO:约 ¥120K。
七、避坑 + 下一篇预告
7.1 6 大避坑
坑 1:图片 token 失控
对策:监控每请求 token 数,对超出的请求自动降采样。
坑 2:长视频默认抽帧太多
对策:业务侧主动设抽帧数(如最多 50 帧)。
坑 3:音频文件格式杂
对策:客户端统一转 PCM 16kHz mono。
坑 4:语音延迟超预期
对策:
- 用流式 ASR / TTS
- 优化 LLM prefill 速度
- 用端到端语音模型(GPT-4o-realtime / Qwen3-Omni)
坑 5:多模态 RAG 检索效果差
对策:
- 用专门的多模态 embedding(如 CLIP / Visualized BGE)
- 图像和文本各自索引 + 融合排序
坑 6:评估方法不对
对策:
- 文本任务:BLEU / ROUGE / GPT-4 as judge
- 视觉任务:MMBench / MMMU / 自建业务评测集
- 语音任务:WER(识别)/ MOS(合成)
7.2 下一篇预告
- 第 30 篇:Prompt 工程方法论 —— 应用生态篇收官。前面 4 篇讲了"用什么技术",最后一篇讲"怎么让 LLM 更好地理解你"。
- 之后进入前沿与思考篇(第 31-35 篇)——MoE、推理模型、端侧、开源闭源博弈、安全。
结语:多模态是 LLM 工程的「下一波」
读完本文你应该明白:
- VLM 本质是 ViT + Projector + LLM——可以用 vLLM 部署
- 图像 token 远超想象——监控每请求 token 数
- 语音三段式(ASR-LLM-TTS)是主流,端到端是未来
- 视频必须抽帧——1 FPS 是甜蜜点
- GPT-4o / Gemini 2.5 / Qwen3-Omni 开启全模态新时代
- Computer Use 是多模态 + Tool Use + Agent 的终极融合
下一篇我们继续:
- 第 30 篇:Prompt 工程方法论 —— 让 LLM 真正听懂你想要什么。
我们下篇见。
📮 关于「码海寻道」
这里是一个聚焦 AI 工程化、大模型部署、后端架构实战的技术专栏。
写最一线的踩坑经验,做最务实的技术拆解。如果这篇文章对你有启发,欢迎点赞、转发、关注。我们下篇见。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)