
美国人说DeepSeek不行,但看了测评细节,我觉得他们在害怕
“中国最强AI模型,落后美国8个月。”
五一当天,这句话像一颗深水炸弹,在国内科技圈炸开了。
消息源头是美国商务部旗下的国家标准与技术研究院(NIST),具体执行单位是它下属的AI标准与创新中心——简称CAISI。他们花了大量精力,对DeepSeek V4 Pro做了一次全方位体检,最后给出了一个让很多人心里咯噔一下的结论:中国最好的开源模型,大概相当于美国8个月前的水平。
8个月。不是一个模糊的形容词,是一个精确的数字。精确到让人觉得这背后一定有一套严密的计算。精确到国内一些媒体转载时,标题直接写成了“中国AI被官方认证落后”。
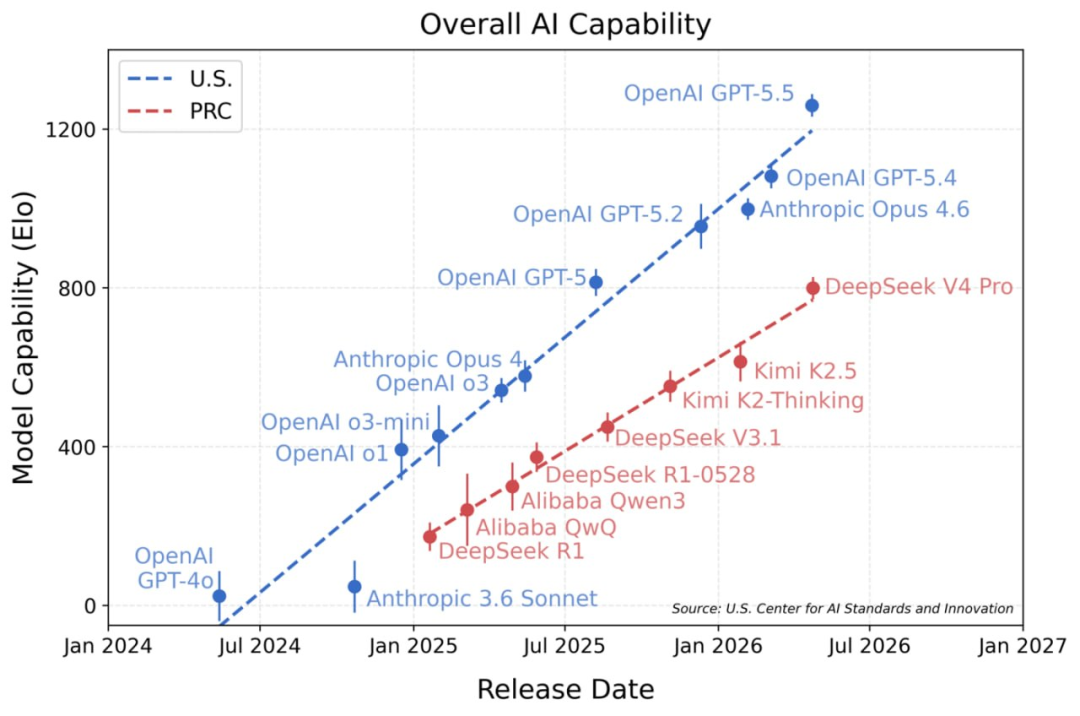
但有意思的是,如果你把这份长达112页的英文原版报告从头到尾啃一遍,你会发现一个很魔幻的事实——报告里几乎所有能证明DeepSeek“很强”的数据,都被那份总结摘要刻意淡化了。而所有能证明“差距在拉大”的图表,都被放在了最显眼的位置。
这不是一份评测报告。这是一场精心设计的叙事。
今天我想做一件事:把这份报告掰开揉碎了,逐页逐项地看看那些美国人自己测出来的数字,到底在说什么。不是转述他们的结论,而是让数据自己说话。
一份来自美国商务部的“成绩单”,到底写了什么?
先还原最基本的事实。CAISI是美国商务部下属机构NIST的一部分。NIST全称国家标准与技术研究院,是给美国联邦政府制定技术标准、做第三方认证的机构。你可以把它理解成“美国科技界的裁判员”——它不仅制定规则,还拥有最终解释权。
这次CAISI对DeepSeek V4 Pro的评估,横跨五大领域、九项基准测试。分别是网络安全、软件工程、自然科学、抽象推理和数学。选的都是业内公认的硬核指标,不是那种“看图说话”的幼儿园题目。
报告给出了三个核心结论。
第一,承认DeepSeek V4 Pro是CAISI迄今评估过的最强中国AI模型,在开源阵营中是当之无愧的新旗舰。
第二,在CAISI自建的能力坐标系里,DeepSeek的IRT-Estimated Elo得分大约是800分。作为对比,GPT-5.5是1260分,Claude Opus 4.6是999分,而GPT-5.4 mini是749分。CAISI据此推断,DeepSeek V4 Pro的实际能力更接近美国8个月前发布的GPT-5水平,而非DeepSeek官方报告中声称的“与Opus 4.6和GPT-5.4相近”——后两者的发布时间大约只有2个月前。
第三,承认DeepSeek在成本端有显著优势。在跟GPT-5.4 mini的七项跨基准对比中,DeepSeek在其中五项上成本更低,最高便宜了53%。
这三个结论放在一起,其实已经构成了一个非常有意思的张力:能力上有差距,但差距并非不可逾越;成本上有优势,而且优势是结构性的。如果是一份纯粹的学术评估报告,这会是一个相当正面的结论。
但CAISI在报告里加了一张图。就是这张图,引爆了后续所有的争议。
那张图,和藏在图里的叙事技巧
报告里有一张中美AI模型能力差距的趋势图。横轴是时间,纵轴是能力差距,曲线上翘,暗示从大约半年前开始,差距非但没有缩小,反而在拉大。
这张图被国内媒体广泛引用,配文通常是“中国AI差距被拉大”或者“追赶之路仍然漫长”。但有一个细节,几乎没有人提——这张图上的能力差距数据,主要来自CAISI自己设计的非公开基准测试。而这些测试的具体题目、评分标准、数据来源,全部不对外公开。
换句话说,CAISI用自己出的题、自己定的评分标准、自己画的坐标系,得出了一条“差距扩大曲线”,然后把它包装成客观事实。
这公平吗?我们先不急着下结论。因为“非公开基准”这件事本身,是有正当理由的。
“闭卷考试”的两面性
很多AI行业的老兵都记得一段不太光彩的历史。
大概在2023年前后,行业内爆出过多起“数据污染”丑闻。一些AI公司在训练模型的时候,会把公开测试集的题目和答案混进训练数据里。结果就是,模型在那些公开基准测试上分数虚高,但一到实际应用场景就原形毕露。这种行为俗称“刷榜”——本质上就是考试作弊。
为了杜绝这种事,真正严谨的评测机构必须启用从未公开过的题目。CAISI这次采用的两个核心测试集——ARC-AGI-2的半私有数据集和CAISI自研的PortBench软件工程测试平台——都属于这种“闭卷考试”。ARC-AGI-2是著名AI研究员Francois Chollet设计的抽象推理测试,专门用来评估AI是否具备接近人类的通用智能能力,在业内地位极高。PortBench则是一个模拟真实软件开发场景的工程测试平台,题目设计更贴近工业实践。
从防作弊的角度说,这是对的。不做闭卷考试,你就不知道考生的真实水平。
但问题来了:当出题人、考官、评分人都是同一队人的时候,你凭什么让外界相信这场考试没有偏向性?
这不是阴谋论。这是所有第三方评估都绕不开的信任问题。一个美国联邦机构,用自己设计的非公开题目,去测试一个中国竞争对手的模型,然后宣布对方落后8个月——即使这个结论是真的,它也很难完全洗脱“裁判兼运动员”的嫌疑。
尤其当你看到具体科目的分数对比时,这种疑虑会进一步加深。
逐科拆解:差距到底在哪里?
好,现在我们把九门科目的分数摊在桌面上,一科一科地看。
数学。 这是AI能力的硬通货。DeepSeek在三项数学基准测试上表现堪称惊艳。OTIS-AIME-2025拿到了97%,PUMaC 2024拿到了96%,SMT 2025同样是96%。这三个数字意味着什么?意味着在纯数学推理上,DeepSeek V4 Pro几乎已经追平了全球最顶尖的水平。连CAISI自己都在报告里承认,数学是DeepSeek最强的领域,没有之一。
自然科学。 GPQA-Diamond是博士级科学推理能力的黄金标准测试。DeepSeek拿到了90%,而Claude Opus 4.6是91%。就差了1个百分点。在FrontierScience这个更前沿的科学知识测试上,DeepSeek反倒比Opus 4.6高出了2个百分点。两科综合来看,数学和自然科学这两个硬核领域,DeepSeek跟美国最顶尖模型之间的差距,几乎可以忽略不计。
代码和软件工程。 SWE-Bench Verified是目前最权威的GitHub真实Bug修复测试。DeepSeek拿到了74%,GPT-5.5是81%。差距存在,差不多7个百分点。不算小,但绝对在同一数量级内。有能力完成真实世界的编程调试任务,这一点是确定的。
读到这里,你可能会想:如果数学接近满分、自然科学几乎持平、代码只差7个点,那“落后8个月”的结论是怎么算出来的?
答案在接下来的两科里。
网络安全。 CAISI用了一个叫CTF-Archive-Diamond的测试集。CTF是Capture The Flag的缩写,是网络安全领域的实战攻防竞赛题目。GPT-5.5在这个测试上拿到了71%,DeepSeek V4 Pro只拿到了32%。差了整整39个百分点。
抽象推理与软件工程(CAISI自研)。 PortBench是CAISI自己研发的软件工程评估平台。GPT-5.5拿到了78%,DeepSeek V4 Pro是44%。差了34个百分点。ARC-AGI-2半私有集是抽象推理能力的极限测试,GPT-5.5是79%,DeepSeek是46%。差了33个百分点。
把这两组数字放在一起,你就明白“8个月”这个结论的数学来源了。它不是来自数学(接近满分)、不是来自自然科学(几乎持平)、不是来自代码(差7个点)——它是来自网络安全和自研工程测试这两个DeepSeek大幅落后的科目。而这两个科目的平均分差,恰好把总分差拉到了一个可以被换算成“8个月”的位置上。
这不代表结论一定有问题。任何综合评估都有权对弱势科目赋予相应的权重。但有意思的是,在公开第三方基准测试中,DeepSeek的差距远没有这么大。斯坦福大学2026 AI Index报告综合多项数据后得出的结论是,中美模型在公开竞技场榜单上的综合性能差距已经缩小到约2.7%。独立评测机构Artificial Analysis持续追踪的数据也显示,差距保持稳定,并未扩大。
一边是2.7%,一边是8个月。同一批模型,结论的差异大到像是两个平行宇宙。
成本维度:被故意压低的那一半故事
CAISI报告里有一个部分,在绝大多数中文媒体的转载中被跳过了。但它可能是整份报告中最重要的信息。
成本效益分析。
CAISI做了一件很有价值的事:以GPT-5.4 mini——美国目前公认最具性价比的模型——作为参照系,对DeepSeek V4 Pro七项任务成本进行了逐项对比。
结果如下:七项测试,五项更便宜,偏差幅度在便宜53%到贵41%之间。
这个结论跟我们之前几篇文章反复讨论的DeepSeek定价策略不谋而合。V4系列缓存命中最低到2分5厘每百万token,这个价格本身就是结构性的,不是促销期的昙花一现。
在成本这个维度上,DeepSeek不是“稍微便宜一点”,而是用对手几分之一甚至几十分之一的成本,完成了能力差距只有几个百分点(某些科目甚至反超)的任务。
美国科技媒体The Decoder的一位分析师在看到CAISI报告后写了一段话,大意是:在实际部署场景中,一旦跨过了某个能力门槛,“够用且便宜”往往比“最强却最贵”更有吸引力。绝大多数企业的AI应用不需要攻克IMO竞赛题,不需要破解最难的CTF靶场。它们需要的是稳定、准确、成本可控地完成日常任务。
这就是为什么成本的维度不能只是被放在报告的角落里一笔带过。它是“综合竞争力”的一个核心组件,而非附加题。当CAISI选择性地弱化成本优势、放大能力差距时,这份报告的“客观性”就值得打上一个问号。
谁在定义“领先”的标准?
聊到这里,必须触及一个更根本性的问题。
在传统科技竞争中,“领先”和“落后”是相对清晰的。芯片制程,3纳米领先5纳米,光刻机精度,数字不会骗人。航天技术,能登陆月球领先不能登陆,轨道精度可以精确到小数点后。
但AI不一样。
AI能力的评估,本质上是没有全球统一标准的。OpenAI有自己的评测体系,Anthropic有自己的评测框架,Google用另一套指标,DeepSeek也发布自己的技术报告。每一家都说自己的模型在某些方面最强,但没有一个公认的“国际AI奥委会”来制定统一的比赛规则。
CAISI的角色,在这个背景下就显得格外微妙。它既是美国联邦机构,又是标准制定者,同时还是评测执行者。它选择哪些基准入库、哪些排除在外,权重如何分配,最终结论如何表述——这其中的每一个环节,都蕴含着叙事上的可操作空间。
我不是在说CAISI的数据造假。没有证据表明这一点。但“选择性地呈现真实数据”和“造假”,在影响公众认知这件事上,效果几乎是一样的。
举个例子。如果一份评测报告,把数学和自然科学放在第一位、成本效率放在第二位、非公开基准放在第三位,结论大概率会变成“中美差距正在快速收窄”。但如果你把非公开基准放在第一位、网络安全放在第二位、在图表上刻意隐去成本维度的对比——结论就是我们在5月1日看到的那个。
同样的数据,不同的叙事框架,截然相反的故事。
追赶8个月,到底意味着什么?
现在,我们退一步。假设CAISI的结论完全正确——DeepSeek V4 Pro确实落后美国最前沿水平大约8个月。这个问题严不严重?
我的答案是:取决于你在乎什么。
如果你在乎的是“谁在绝对前沿探索上跑得更快”,那这8个月确实是一个需要严肃对待的信号。意味着在网络安全、抽象推理等特定领域,中国AI仍然存在硬差距,这不是靠便宜就能弥补的。这些差距如果持续存在,可能在未来的关键应用场景中构成实质性的短板。
但如果你在乎的是“谁能把技术更快变成产品、更广泛地部署到千行百业中去”,那这个“8个月”的含义就会发生微妙的变化。
历史上有很多类似的例子。1970年代,苏联在航天领域多个指标上领先美国——第一颗人造卫星、第一次载人航天、第一次太空行走——但最终输掉了太空竞赛。为什么?因为美国用更低的成本实现了更频繁的发射,用工程效率碾压了单点突破。
今天的AI竞赛正在进入一个类似的阶段。赛道规则正在从“谁能发布最强实验室模型”转向“谁的工程体系能在可控成本下维持前沿性能”。这不再是一场百米冲刺,这开始变成一场马拉松。
最后
中国人有句老话,“他山之石,可以攻玉”。
CAISI的这份报告,无论它带着多少叙事上的主观色彩,有一点是无可辩驳的:它指出了一些真实存在的短板。网络安全差39个百分点,自研工程测试差34个百分点,抽象推理差33个百分点——这些数字不会因为出题人的身份就自动失效。它们是摆在台面上的挑战,是下一步必须啃下来的硬骨头。
但同样重要的是,不要让一份由竞争对手制作的“体检报告”定义你对自己的认知。当一个美国联邦机构告诉你“你落后8个月”的时候,你该做的不是照单全收然后自我怀疑,而是把这份报告跟斯坦福的AI Index对照着看,跟Artificial Analysis的数据交叉验证,然后在自己的实际应用场景中重新校准。
世界上可能只有一种真正的“落后”——不是分数低,而是别人说什么你就信什么。
从4月24日V4发布到现在,DeepSeek几乎是以每周一次的频率在出牌:降价、延期、多模态识图上线、连续霸榜。它在用行动说一句话——你可以定义我,但拦不住我。
这份CAISI报告,说白了,是一面镜子。它照出了一些还没有擦干净的地方,但也照出了另一个事实:当对手开始用112页深度评估来论证“你只落后八个月”的时候,本身就说明了——你已经近到让他们觉得有必要做这份报告了。
毕竟,没人在乎一个被远远甩在身后的追赶者。只有当追赶者的呼吸已经喷到了后颈上,领跑者才会回头看一眼,然后大声告诉所有人:“他还差得远呢。”
笑吧。
这一回,笑的不是账单上的零,不是鲸鱼睁眼的那一刻。笑的是——他们慌了,而你看到了。
关联阅读:
DeepSeek说好了5月5日结束的2.5折,刚刚又续了一个月

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)