
ICLR 2026|医疗多模态大模型的“显微镜”:开启无需标注的视觉推理新范式
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者|蒋政,阿里巴巴达摩院实习生
摘要:
医疗多模态大模型在处理复杂临床任务时展现出巨大潜力。然而,现有的模型大多遵循纯文本推理的范式,无法将逻辑推理与视觉证据进行有效关联。这种局限性不仅削弱了模型在细粒度视觉分析任务中的表现,还在安全至上的临床应用场景中引入了视觉幻觉的风险。
为此,我们提出了一个基于智能体强化学习的医疗视觉推理框架,实现了无需人工中间标注的视觉推理学习。通过“熵引导的视觉重定位”和“基于共识的贡献分配”这两大机制,它能够像临床医生一样,在推理过程中自主调用视觉工具对关键区域进行精准定位和验证。实验结果表明,它在多个医疗视觉问答基准测试中均达到了当前最先进的性能。通过让模型自主学习视觉探索与证据定位,它显著提升了模型在临床部署中所必需的稳健性和透明度,为加速医疗人工智能的应用奠定了基础。
论文链接:https://openreview.net/pdf?id=cK35kNVm5r
研究问题及挑战
多模态大模型已在计算机辅助诊断、医学影像报告生成等临床任务中得到应用。然而,这些模型通常采用纯文本推理范式,即模型的推理过程完全在文本域内完成,这种技术范式存在以下显著缺陷:
其一,缺乏对视觉证据的细粒度定位与交互分析能力。在处理需要精确定位微小病灶、比较组织密度、或解读血流动力学等临床任务时,由于无法与图像进行主动交互(例如缩放、选取感兴趣区域等),其从医学影像中提取关键信息的能力受到严重制约,导致分析的深度和准确性不足。
其二,存在引发“视觉幻觉”或“语言捷径”的技术风险。模型可能仅依据其在训练数据中学到的文本先验知识生成结论,而忽略甚至错误解读了影像中的关键视觉信息。这种推理与证据的脱节,在对安全性有严苛要求的医疗应用中,构成了不可接受的技术风险,严重影响了模型的可靠性。

为克服上述缺陷,一种理想的技术路径是使模型模拟人类临床专家的诊断行为,即在推理过程中动态地与影像交互,通过主动的视觉操作来形成并验证诊断假设。然而,现有的通用大模型在医疗场景下零样本视觉定位能力普遍较弱,难以在复杂的医学影像中自主发现关键特征。若要引导模型学习此类定位能力,则需要为其中间的视觉操作提供大规模的监督数据。而在医疗领域,获取此类由领域专家完成的精确标注成本极其高昂,不具备实际的可行性和可扩展性。
因此,我们提出了一种全新的技术方案,能够在无需任何中间步骤人工标注的前提下,使医疗多模态大模型自主学会进行主动的视觉探索与证据定位,从而实现更可靠、更透明的视觉推理。
核心贡献
本研究的主要贡献包括如下:
-
无标注医学视觉推理框架: 我们提出一个完整的、端到端的强化学习框架,能够在没有中间步骤人工标注的情况下,教会医疗多模态大模型将文本推理与视觉工具操作相结合。
-
熵引导的视觉重定位机制 (EVR):我们提出了一种新颖的、由模型内在不确定性驱动的高效探索策略。它将模型在生成工具参数时的预测熵作为信号,在模型最不确定的决策点触发并行的视觉搜索,从而将有限的探索预算战略性地用于解决关键的定位不确定性问题。
-
基于共识的贡献分配机制 (CCA):一种创新的自监督贡献分配方法。它通过聚合多条不同但均成功的推理路径中的视觉操作,动态地生成一个高置信度的共识区域作为伪标签。该伪标签为评估和奖励中间的视觉操作提供了细粒度的、完全由数据驱动的监督信号。
-
探索与利用的协同自监督闭环:它的核心是EVR(先验探索器)和CCA(后验监督器)的无缝协同。EVR负责高效地提出问题(生成多样化的视觉假设),CCA负责有根据地给出答案(从结果中提炼出最优策略)。二者共同构成了一个不依赖外部标注的、自我完善的学习循环,为训练可靠、可解释的医疗AI提供了全新的范式。
研究方法
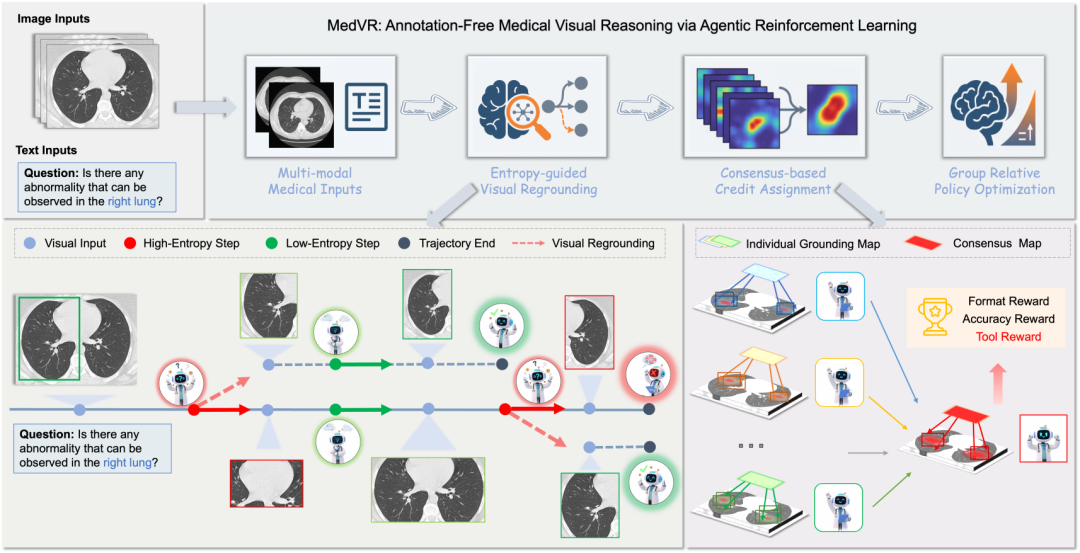
(一)智能体强化学习框架
我们将它的训练过程建模为一个策略优化问题:
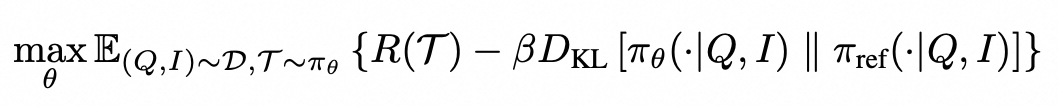
与传统模型生成单一文本块不同,本方案的智能体通过交错生成文本思考和调用视觉工具来动态构建推理轨迹。本方案聚焦缩放(Zoom-in)这一核心视觉操作,当模型完整生成一个包含精确坐标的缩放命令时,一个外部工具会被触发执行相应的图像裁剪操作。新获取的局部视觉信息被编码为特殊标记,并整合回智能体的上下文中,用于指导后续的推理和行动。此过程循环进行,直至模型生成最终答案。
在没有细粒度步骤监督的情况下,我们设计了一个复合终端奖励函数来评估整个轨迹的质量,主要包括正确性奖励、格式奖励和工具调用奖励:
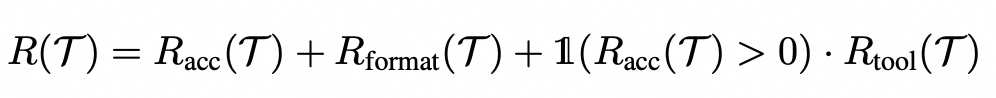
(二)熵引导的视觉重定位(EVR)
在生成视觉操作命令时,我们利用模型自身对工具参数预测的不确定性,引导其在关键步骤分支探索,从而高效发现合适的定位区域。具体来说,在模型生成命令的坐标参数时,我们实时监控其输出token的熵。熵值越高,代表模型对选择哪个具体区域越不确定。t时刻熵的计算公式如下:
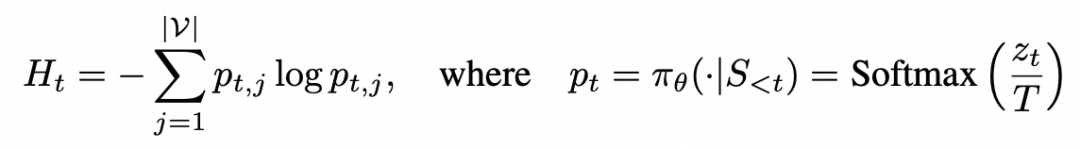
在序列起始阶段,我们统计初始部分token的平均熵作为基线,在生成视觉操作相关token时,计算对应的平均熵,从而获取熵增量。若熵增量显著为正,表明模型对当前工具参数较为不确定,是触发分支探索的合适时机。这种基于不确定性的树状探索,比盲目随机采样更加高效,为后续CCA提供了高质量的候选轨迹。
(三)基于共识的贡献分配(CCA)
在缺乏真实ROI标注的情况下,我们进一步利用多条成功轨迹之间的共识,构造伪标签,奖励那些与共识策略一致的轨迹。我们首先从EVR生成的多条推理轨迹中,筛选出所有最终答案正确的成功轨迹。然后,将每条成功轨迹中所有图像操作的边界框合并,形成其视觉印记。接着,通过多数投票规则将所有成功轨迹的视觉印记叠加,得到最终的共识掩码。最后,利用共识掩码,我们为每条成功轨迹计算其工具使用奖励。奖励的大小取决于该轨迹的视觉印记与共识掩码的对齐程度(通过IoU衡量):
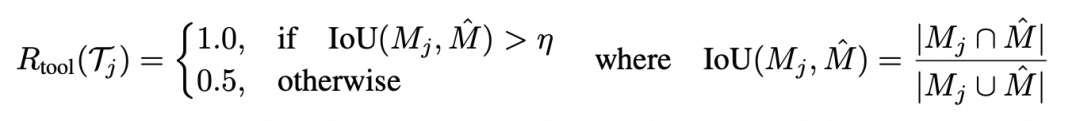
实验结果
在多个公开的医疗视觉问答基准测试中,它均取得了最佳的性能,并在OOD场景下也展现出极强的泛化性:
通过使模型的推理过程透明化、可验证,让最终用户能够清晰地看到AI是如何通过定位和分析关键影像区域得出结论的。这种基于视觉证据的推理模式极大地增强了模型的准确性、可靠性和可解释性。

未来展望
-
从“纯文本RL”迈向“多模态Agentic RL”:现有的DeepSeek-R1类工作主要验证了文本逻辑推理的 Scaling Law。它将其扩展到了医学影像交互式视觉智能体领域,证明了RL同样可以驱动模型学会复杂的工具使用和视觉逻辑对齐。
-
临床决策支持(CDSS)的透明化:它提供的推理路径具有极高的可解释性,这正是AI临床部署的关键前提。目前新框架主要使用了Zoom-in工具,未来可以扩展到多模态检索、3D影像切片选择、测量计算等更复杂的临床工具,并将其集成到医生工作站中,辅助放射科医生进行二次确认。
-
弥合通用与医疗垂直领域的鸿沟:它证明了无需大规模冷启动标注,仅通过精巧的RL框架设计,也能在医疗垂直领域实现超越大参数量通用模型的专业表现。未来可以进一步探索如何利用大规模无标注医疗影像库,通过自发性的视觉探索来持续进化模型性能。
往期精彩文章推荐
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者直播回放!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)