
LangGraph核心揭秘:LLM如何实现“想一步、停一步、判断一步“的智能决策?
上一篇我们把 LangChain Memory 模块拆了个底朝天,搞清楚了截断、总结、检索三种记忆方案各自的适用场景。这一篇我们进入 LangGraph 的核心地带——它的底层执行引擎。
你有没有想过:为什么同样是调用 LLM,用了 LangGraph 之后,AI 就能「想一步、停一步、判断一步」?就能在工具调用和 LLM 推理之间来回切换,还不会乱套?
答案就藏在它的状态机设计里。
01 先说说 LangChain 的老问题
LangChain 的早期架构是线性的——Chain。
用户输入 → PromptTemplate → LLM → OutputParser → 输出
这个模型干净利落,但有个致命弱点:控制流是固定的。
一旦你想实现「如果 LLM 觉得需要查数据库就查,不需要就跳过」,或者「出错了重试三次」,你会发现原来的 Chain 根本放不下这些逻辑。要么把判断逻辑硬编码在节点里,要么用 Python 的 if/else 在外层手动管流程——乱成一锅粥。
现实中的 Agent 场景根本不是线性的:
- 调工具 → 看结果 → 决定调下一个还是直接回答
- 生成草稿 → 自我审查 → 不行就重写
- 多轮对话 → 根据意图走不同分支
这些都需要带状态的循环控制流。这正是 LangGraph 解决的核心问题。
02 状态机是什么:用最简单的例子解释
状态机(State Machine)不是什么新概念。你手机的蓝牙就是个状态机:
[关闭] --打开--> [扫描中] --发现设备--> [配对中] --成功--> [已连接]
|
--失败--> [扫描中]
三个核心要素:
┌─────────────────────────────────────────────┐
│ 状态机三要素 │
├──────────┬──────────────────────────────────┤
│ State │ 当前的数据快照(系统处于什么情况)│
│ Node │ 执行动作,并更新 State │
│ Edge │ 决定下一步去哪个 Node │
└──────────┴──────────────────────────────────┘
LangGraph 就是把这套机制套在了 LLM 上:
- State = 对话历史 + 工具结果 + 中间变量
- Node = LLM 调用 / 工具执行 / 业务逻辑
- Edge = 普通跳转 / 条件分支(Conditional Edge)
03 StateGraph 执行引擎:它的心脏长什么样
打开 LangGraph 的源码(Python 版 langgraph/graph/state.py,JS 版同理),你会看到 StateGraph 类维护了几个核心数据结构:
┌──────────────────────────────────────────────────┐
│ StateGraph 内部 │
├─────────────────┬────────────────────────────────┤
│ nodes │ Map<名称, 函数> │
│ edges │ Map<from, to[]> │
│ conditional_ │ Map<from, (state)=>节点名> │
│ edges │ │
│ channels/ │ 每个状态字段的 Reducer │
│ schema │ │
└─────────────────┴────────────────────────────────┘
当你调用 graph.compile() 时,它做了什么?
compile() 阶段
│
├─ 验证图结构(有没有孤立节点?有没有到 END 的路径?)
├─ 构建邻接表(预计算每个节点的后继)
├─ 初始化 Channels(每个状态字段注册 Reducer)
└─ 返回 CompiledGraph(可以 invoke/stream)
compile() 本质上是把你「描述的图」变成「可执行的调度器」。
04 一次完整执行:从 invoke 到节点运行的全流程
来看最简单的例子,一个单节点 LLM Agent:
importStateGraphSTARTENDfrom"@langchain/langgraph"importAnnotationfrom"@langchain/langgraph"importChatOpenAIfrom"@langchain/openai"importHumanMessagefrom"@langchain/core/messages"// 1. 定义状态结构constAgentStateAnnotationRootmessagesAnnotationHumanMessagereducer(prev, next) =>default() =>// 2. 初始化 LLMconstnewChatOpenAImodel"gpt-4o-mini"// 3. 定义节点函数asyncfunctioncallLLMstate: typeof AgentState.Stateconstawaitinvokemessagesreturnmessages// 4. 构建图constnewStateGraphAgentStateaddNode"llm"addEdgeSTART"llm"addEdge"llm"ENDcompile// 5. 运行constawaitinvokemessagesnewHumanMessage"你好,介绍一下自己"
执行流程逐步拆解:
graph.invoke({ messages: [...] })
│
▼
1. 初始化 State
messages = [HumanMessage("你好...")]
│
▼
2. 调度器从 START 出发
→ 找到边:START → "llm"
│
▼
3. 执行节点 "llm"
callLLM(state) 被调用
→ llm.invoke(messages)
→ 返回 { messages: [AIMessage("我是...")] }
│
▼
4. 合并状态(Reducer)
新 messages = [...旧, AIMessage("我是...")]
│
▼
5. 调度器检查下一步
→ "llm" 的边指向 END
→ 执行结束
│
▼
6. 返回最终 State
05 Reducer:状态更新的核心机制
这是很多人没搞清楚的地方。
节点函数返回的不是「新 State」,而是「State 的更新片段」。LangGraph 用 Reducer 把旧状态和更新片段合并。
// 三种常见 Reducer 写法// 方式1:用内置 messagesStateReducer(追加消息)constState1AnnotationRootmessagesAnnotationBaseMessagereducer(prev, next) =>// 方式2:覆盖(最新值覆盖旧值)constState2AnnotationRootstepAnnotationnumberreducer(_, next) =>// 直接替换// 方式3:累加计数constState3AnnotationRootcallCountAnnotationnumberreducer(prev, next) =>default() =>0
Reducer 的执行时机:
节点返回 { key: value }
│
▼
对每个 key,找到对应 Reducer
newState[key] = reducer(oldState[key], value)
│
▼
生成新 State 快照
(旧 State 不变,不可变数据结构)
关键点:State 是不可变的。 每次节点执行都产生一个新的 State 快照,旧快照被保留(这是 Checkpoint 能实现的基础,后面讲)。
06 图的调度器:它怎么决定下一步去哪
这是 LangGraph 最有意思的部分——调度器(Scheduler)。
调度器本质上是一个事件循环:
while 当前节点 != END:
1. 执行当前节点 node(state) → partial_update
2. 用 Reducer 合并状态 → new_state
3. 查询当前节点的出边
- 普通边:直接去下一个节点
- 条件边:调用路由函数 router(new_state) → 返回节点名
4. 把下一个节点加入执行队列
5. 取队列头 → 重复
条件边(Conditional Edge)长这样:
importStateGraphSTARTENDfrom"@langchain/langgraph"// 路由函数:根据 state 返回下一个节点名functionrouteAfterLLMstate: typeof AgentState.Statestringconstmessagesmessageslength1// 如果 LLM 想调工具if"tool_calls"intool_callslengthreturn"tools"// → 去工具节点returnEND// → 直接结束constnewStateGraphAgentStateaddNode"llm"addNode"tools"addEdgeSTART"llm"addConditionalEdges"llm"tools"tools"// 映射:路由函数返回值 → 节点名ENDENDaddEdge"tools""llm"// 工具执行完回到 LLMcompile
执行路径示意:
START → llm → [判断] → 需要工具?
Yes → tools → llm → [判断] → 不需要了?
Yes → END
No → END
这就是 ReAct Agent 的本质:一个带条件边的循环图。
07 并行执行:Fan-out / Fan-in 模式
LangGraph 支持一个节点连到多个后继节点,实现并行执行。
// Fan-out:一个节点触发多个并行节点constnewStateGraphAgentStateaddNode"start"addNode"search_web"// 并行addNode"search_db"// 并行addNode"merge"// 合并addEdgeSTART"start"addEdge"start""search_web"// 同时出发addEdge"start""search_db"addEdge"search_web""merge"// 都完成后汇聚addEdge"search_db""merge"addEdge"merge"ENDcompile
调度器处理并行的方式:
start 节点执行完毕
│
├──→ search_web(加入执行队列)
└──→ search_db(加入执行队列)
执行队列:[search_web, search_db]
同时调度(异步并发执行)
两者都完成后:
merge 节点的所有前驱都就绪 → merge 入队
│
▼
merge 执行 → END
这个 Fan-out/Fan-in 模式,是并行搜索、多 Agent 协作的基础。
08 编译产物:CompiledGraph 里藏了什么
compile() 返回的 CompiledGraph 暴露了四个主要接口:
interfaceCompiledGraph// 同步执行,返回最终 StateinvokeinputStateRunnableConfigPromiseState// 流式执行,每个节点完成后 yield 一次streaminputStateRunnableConfigAsyncGeneratorRecordstringState// 可视化图结构(调试用)getGraphDrawableGraph// 获取当前状态(需要 Checkpointer)getStateconfigRunnableConfigPromiseStateSnapshot
stream() 的输出格式:
forawaitconstofstream// chunk 是一个对象:{ 节点名: 该节点产生的状态更新 }// 例如:// { llm: { messages: [AIMessage(...)] } }// { tools: { messages: [ToolMessage(...)] } }consolelog
这就是为什么前端能实现「打字机效果」——每个节点完成,前端就能收到一次更新。
总结
这篇我们从底层拆解了 LangGraph 把 LLM 变成状态机的核心机制:
- StateGraph 三要素:State 存数据、Node 执行动作、Edge 决定走向,缺一不可
- Reducer 是关键:节点返回的是「更新片段」而非「完整新状态」,Reducer 负责合并,State 始终不可变
- 调度器是心脏:本质是一个事件循环,条件边让它能根据运行时状态动态决策
- compile() 的意义:把声明式的图描述变成可执行的调度引擎,做结构验证和邻接表预计算
- 并行靠 Fan-out:多条出边同时触发,Fan-in 等待所有前驱完成,调度器自动处理同步
- stream() 是流式基础:每个节点完成即 yield,这是打字机效果和实时反馈的技术支撑
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
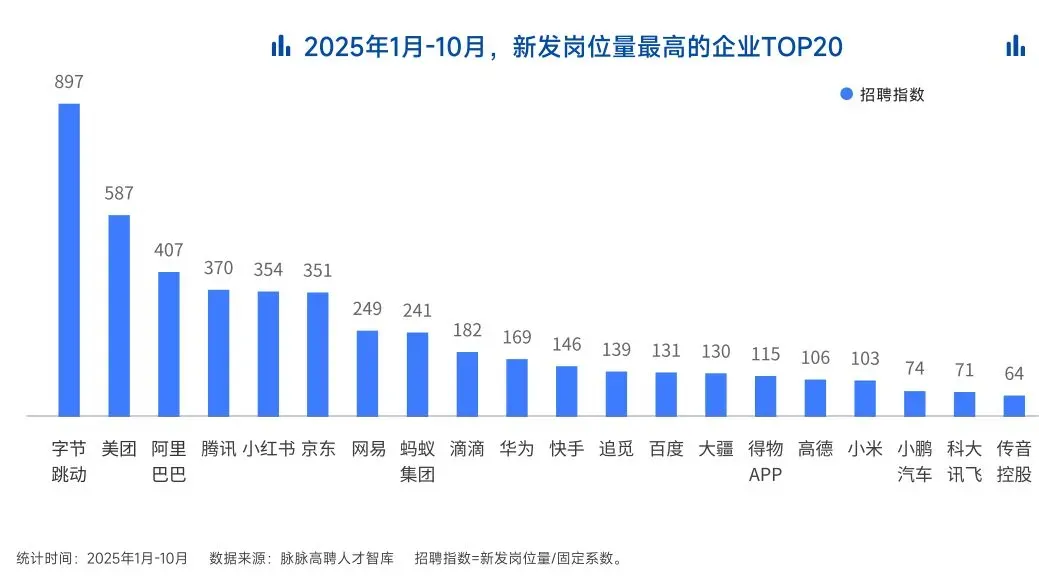
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)