
【CVPR26-纪荣嵘-厦门大学】PixDLM:面向无人机推理分割的双路径多模态大语言模型
文章:PixDLM: A Dual-Path Multimodal Language Model for UAV Reasoning Segmentation
代码:https://github.com/XIEFOX/PixDLM
单位:厦门大学
一、问题背景
无人机视觉在低空监控、搜救、智能巡检、自主导航等场景价值极高,但无人机推理分割一直存在三大核心痛点:
-
视角特殊:倾斜视角+高空视角,几何畸变严重,现有地面/卫星视角模型不适用
-
尺度极端:超高清画面里充斥大量小目标(车辆、行人、设施仅占数十像素),传统MLLM压缩token会丢失细节
-
任务复杂:需要同时做空间/属性/场景三类推理,而非简单识别物体,现有数据集缺少思维链标注
当前行业缺少专用无人机推理分割数据集,也没有适配无人机特性的像素级多模态模型,导致真实场景下推理与分割精度严重不足。
为此,本文正式定义UAV Reasoning Segmentation任务,并将其拆分为三大推理维度:
-
空间推理:位置、相对关系、遮挡判断
-
属性推理:外观、状态、特征差异
-
场景推理:环境意图、功能用途、任务导向语义
同时构建DRSeg基准数据集:1万张超高清无人机图+思维链QA标注,覆盖城市、公园、住宅区、工业区、滨水区,含昼夜、多高度、大量小目标。
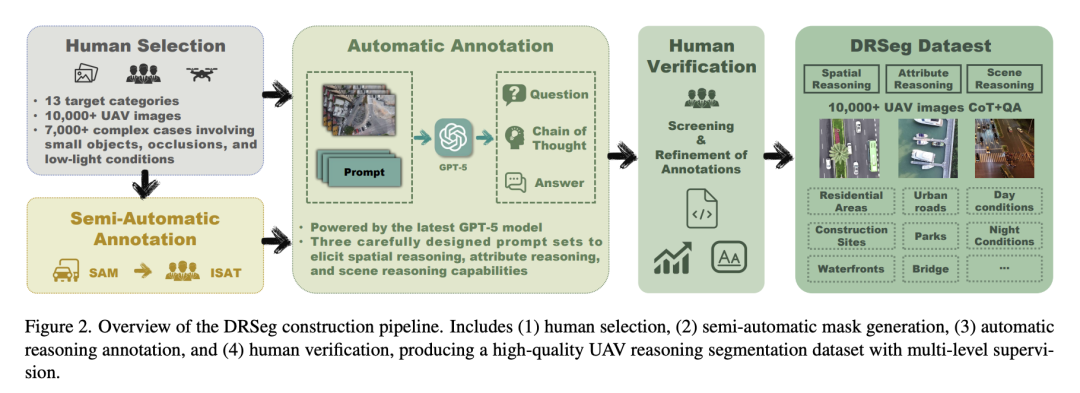

二、方法创新(核心详解)
PixDLM是双路径像素级多模态大模型,专为无人机推理分割设计,核心创新有三点:
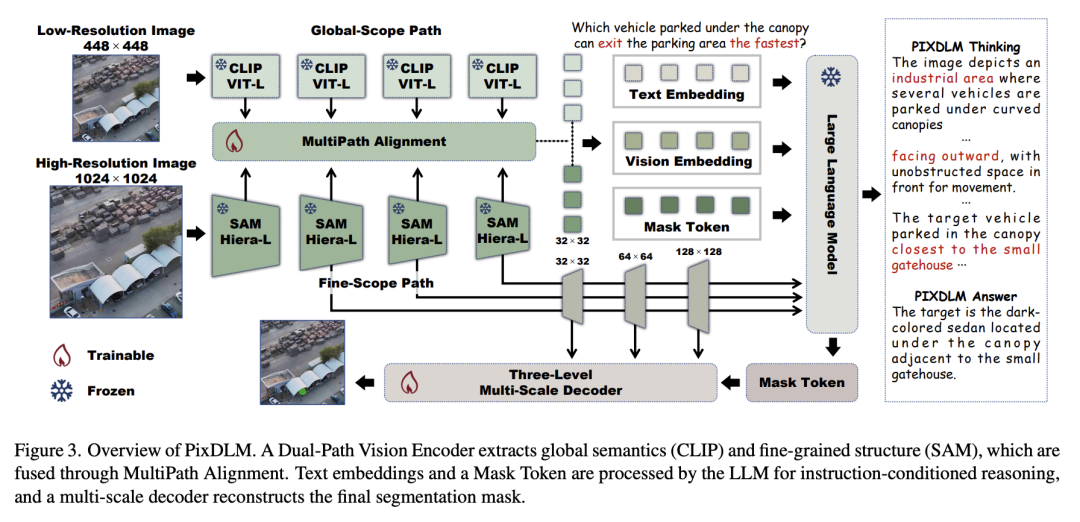
1. 双路径视觉编码器(Dual-Path Vision Encoder)
同时解决“全局语义推理”和“细粒度小目标分割”矛盾:
-
全局路径(Global-Scope Path):448×448低分辨率,用CLIP提取长程上下文,支撑复杂推理
-
细粒度路径(Fine-Scope Path):1024×1024高分辨率,用SAM编码器保留边界、小目标、结构细节
2. 多路径对齐(MultiPath Alignment)
不只是简单融合,而是三阶段隐层融合+输出层融合:
-
把SAM高分辨率特征逐级注入CLIP语义路径
-
门控残差融合,自适应控制细节注入强度
-
最优方向:SAM→CLIP(高分辨率结构引导低分辨率语义)
3. 分层推理解码器(Hierarchical Reasoning Decoder)
解决LLM掩码token空间精度不足问题:
-
三层多尺度解码器,从粗到精逐步 refine 掩码
-
掩码调制视觉特征,聚焦高置信度区域
-
融合多尺度中间掩码,输出精准像素级分割结果
整体流程
-
双路径提取全局语义+高分辨率结构
-
多路径对齐融合特征
-
LLM+掩码token做跨模态推理
-
分层解码器输出最终分割掩码
三、实验结果
实验在DRSeg基准上进行,用gIoU/cIoU评估,对比SOTA模型:
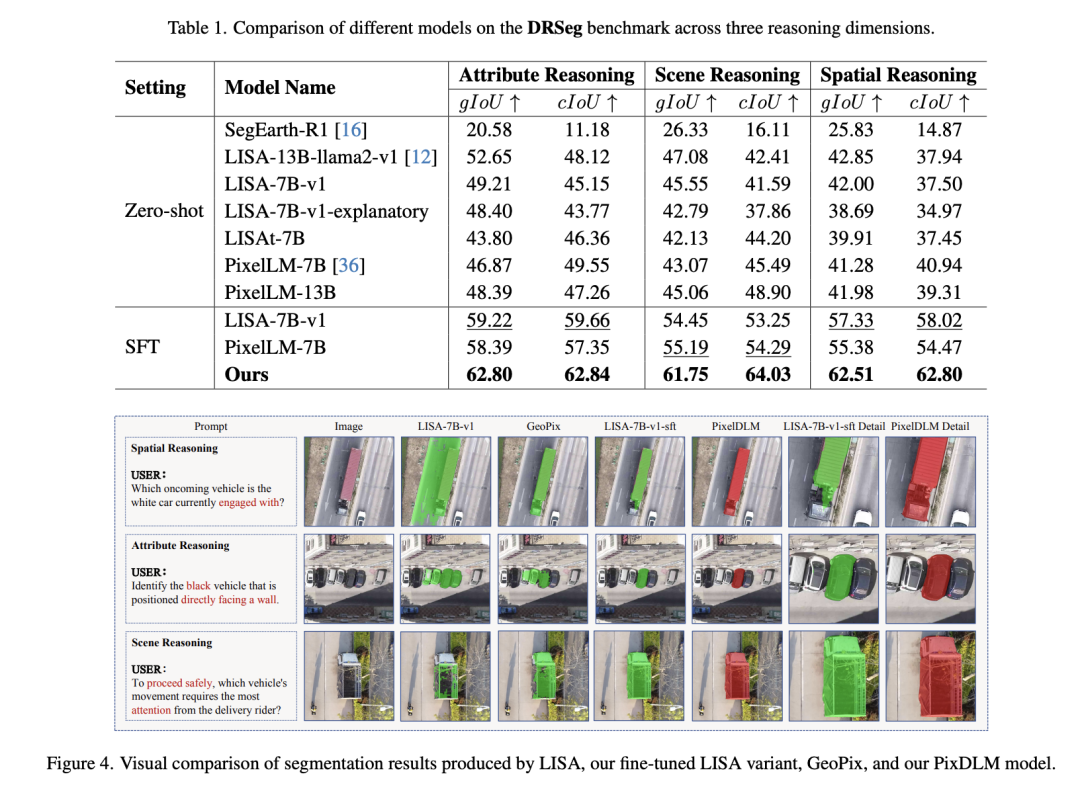
1. 整体性能
-
零样本:现有模型普遍偏低,证明无人机任务迁移困难
-
微调后:PixDLM全面超越LISA、PixelLM等基线
-
-
属性推理:62.80% / 62.84%
-
场景推理:61.75% / 64.03%
-
空间推理:62.51% / 62.80%
-
2. 消融实验关键结论
-
思维链(CoT)监督:带来最大增益,尤其场景推理
-
完整四层对齐:比单段融合提升显著
-
三层解码器:比两层/单层精度大幅上涨,平均gIoU达62.35%
3. 泛化能力
在标准指代表情分割(RefCOCO/+/g)上同样达到SOTA水平,证明双路径架构通用性强。
四、优势与局限
核心优势
-
首次定义无人机推理分割任务并构建大规模高质量基准DRSeg
-
双路径设计完美适配无人机:倾斜视角、超高清、极端尺度、密集小目标
-
推理+分割一体化,支持自然语言自由指令
-
轻量高效:仅~4.19M可训练参数,单图推理约1.12s
-
泛化强:无人机任务SOTA,通用指代表情分割也领先
局限
-
单图仅标注一个目标,暂不支持多目标同时推理分割
-
极端暗光/严重模糊场景仍有提升空间
-
依赖SAM与CLIP预训练权重,端到端训练成本较高
五、一句话总结
PixDLM提出双路径视觉编码+多路径对齐+分层推理解码架构,搭配全新DRSeg基准,彻底解决无人机视角下推理分割的小目标丢失、视角畸变、语义推理弱三大难题,成为无人机视觉理解的强力基线模型。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)