
字节食堂结账,我跟同事炫“我 CLAUDE.md 写了三十条规则“,阿姨扫码枪一停:“写三十条它就听三十条?你咋不写‘每天给我转账一百万‘呢。“
继续来个段子。
前几天在字节食堂排队结账,我端着餐盘跟同事显摆:我那个 CLAUDE.md 现在写得叫一个全,项目约定、代码规范、踩过的坑,三十多条规则码得整整齐齐。Claude 这下总该老老实实照着干了吧,我这叫把丑话说在前头。
同事还没搭腔,给我扫码的食堂阿姨把扫码枪往台子上一搁,"嘀"的一声响完,幽幽来了一句:“写三十条它就听三十条?那你咋不写一条’每天给我转账一百万’呢。字儿是你写的,听不听可不是你说了算啊。”
我举着手机愣在原地,码都忘了扫。
那一刻我突然意识到,我对CLAUDE.md 这个东西的理解,从一开始就是错的。我一直以为它是一份"合同",只要我把条款白纸黑字写进去,Claude 签收了就等于生效,每一条都会照办。
但真相是,CLAUDE.md更像是我贴在工位上的一排便利贴,而不是一份有强制力的合同。贴得越多,真正被看进眼里的越少,很多条它扫一眼就滑过去了。写进去 ≠ 被遵守,这中间隔着一整套机制。
这就是 Claude Code 用深了之后绕不开的一件事,CLAUDE.md 的维护。
它不是"想到啥规则就往里加",而是"在模型有限的注意力预算里,怎么只放那些真正会被执行的规则,并且有办法验证它到底听没听"。
今天这一篇,我把"为什么规则写得越全反而越不听话"这件事,从机制到实操全部拆开讲。
一、先认清 CLAUDE.md 的身份:它是"常驻",不是"按需"
要把维护这件事讲清楚,得先把 CLAUDE.md 的加载机制摆正,不然后面全是空谈。
最关键的一句话:CLAUDE.md 是会话一启动就被注入上下文、并且每一轮对话都保留在那里的。 它不是你需要的时候才去读,是从头到尾常驻。这一点和 skill 正好相反。skill 走的是渐进式披露,平时只把名字和描述放进上下文,真正命中某个场景才加载正文,所以你装一堆 skill 也不太占每轮的预算。CLAUDE.md 没有这个机制,你写多少,模型每一轮就得带着多少。
我用做 AlgoMooc 这个算法可视化网站的经历举个实在的例子。这个项目我维护了大半年,CLAUDE.md 一度涨到 600 多行,把题解动画的规范、CDN 部署流程、渲染优化的约定、各种踩过的坑全堆了进去。涨到这个体量之后,我开始明显感觉到两件坏事。第一,每轮对话光这一个文件就吃掉小两万 token,一次会话几十轮下来,重复读它的开销很可观。第二,也是更要命的,里面真正每天用得上的可能就二三十行,剩下五百多行全是低频内容,把那二三十行也一起淹了。
这里要补一个很多人不知道的细节,它直接影响你对成本的判断。CLAUDE.md 其实分四层,从高到低是:企业级、用户全局(~/.claude/CLAUDE.md,对你所有项目生效)、项目级(./CLAUDE.md,跟着仓库走)、本地级(./CLAUDE.local.md,只对当前项目生效且不进版本控制)。这四层不是覆盖关系,是全部串联进上下文。也就是说你在全局写了一堆、项目里又写了一堆,它们是叠加在一起常驻的,不是谁替换谁。算成本的时候,得把这几层加起来算。
唯一不常驻的是子目录里的 CLAUDE.md。它走懒加载,只有当 Claude 真的去读那个子目录里的文件时才会被加载进来。这个特性后面讲分层的时候是个好工具,先记住这个区别:项目根的常驻,子目录的按需。
这里还有一个很少人注意、但直接关系到长会话稳定性的机制,得专门点一下:自动压缩(auto-compact)的时候,CLAUDE.md 的命运是分裂的。会话开太长触发压缩,上下文会被裁剪重组,但项目根的 CLAUDE.md 会被从磁盘重新读一遍、重新注入回去,所以它不会因为压缩而丢失,压缩后照样常驻。可子目录那些懒加载进来的 CLAUDE.md 不享受这个待遇,压缩之后它们不会自动重注入,得等 Claude 下次再读那个目录的文件时才会重新加载。这个差别的实际后果是:长会话里,你写在项目根的约定一直稳,写在子目录里的约定可能在某次压缩之后就悄悄失效了一段时间。所以越是要在长会话里全程生效的硬约定,越要往项目根放,别图清爽全塞进子目录。
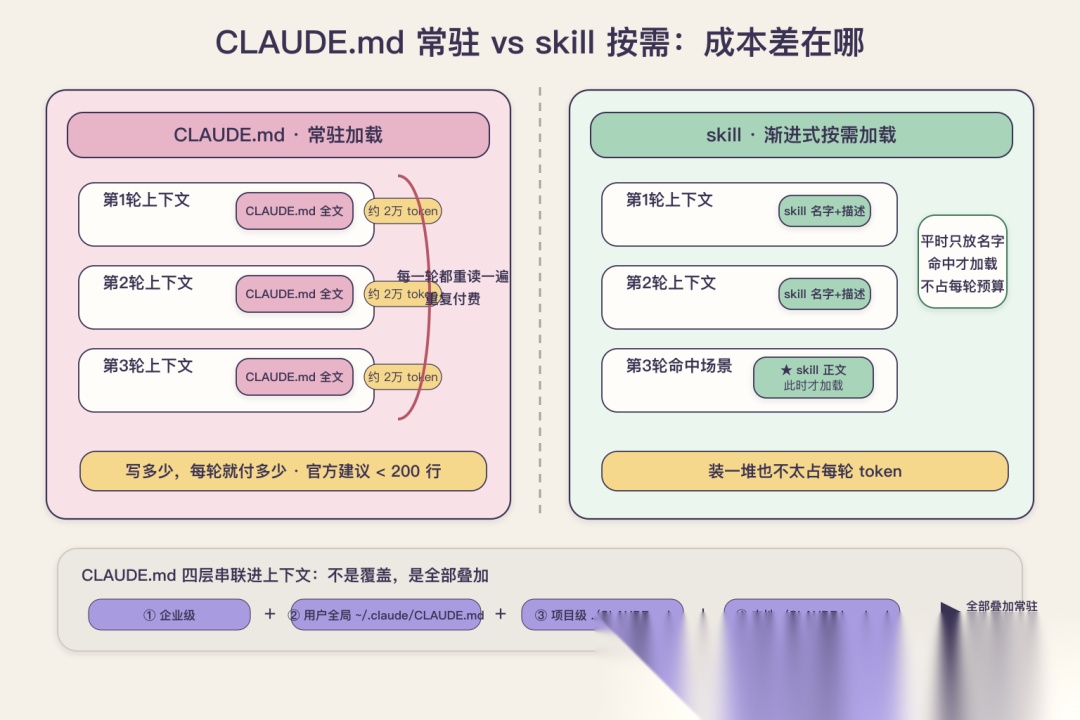
CLAUDE.md 是「常驻」,skill 是「按需」:每轮都要付的费
二、为什么白纸黑字写了,模型还是不听
搞清楚常驻这件事,下一个问题就自然冒出来了:既然每轮都在上下文里,为什么写了的规则还是会被无视?
答案是稀释。CLAUDE.md 加载进来之后,是作为一条用户消息待在上下文里的,它要和这一轮对话里的所有东西,你的提问、读进来的代码、工具返回的结果,一起争夺模型的注意力。它不是写在系统提示里的铁律,本质上只是一条优先级正常的建议。当这个文件很短、规则很具体的时候,模型基本都能照顾到;可一旦它涨到几百行,规则之间互相挤占,重要的那几条就被埋进噪声里,模型对靠后、靠中间那些内容的实际利用率会明显下降。官方自己给的经验值是:CLAUDE.md 最好控制在 200 行以内,超过这个数,模型很可能会忽略掉其中一半的规则。
我在 AlgoMooc 上栽过一个特别典型的跟头。我写过一条规则:"题解动画的 HTML 必须先在本地渲染验证通过,再提交。"这条很重要,因为动画渲染失败是这个项目最常见的事故。但我把它埋在了 CLAUDE.md 第 80 行左右,夹在一大段关于目录结构和命名约定的描述中间。结果就是,Claude 三次里有两次直接跳过它,生成完动画连渲染都没验证就提交了,我上线才发现一片空白,粗算下来遵守率也就三成上下。同一条规则,措辞没变,我把它从那段描述里拎出来,单独成行,前面加上"提交前必须执行"的祈使口气,再探几次,基本每次都守了,遵守率从三成提到了八九成。这件事让我明白,规则失不失效,很多时候不在内容,在它有没有被淹没。
这里还有个位置上的讲究值得说。一份长文档里,开头和结尾的内容,模型的注意力天然更高,最容易被忽略的恰恰是夹在正中间那一大段。我那条渲染验证规则栽在第 80 行,就是栽在了这个"中间地带"。所以同样一条规则,你把它放在文件最前面那几条,和埋在第八十行、第一百五十行,实际遵守率是有明显差别的。维护 CLAUDE.md 的时候,把最不能被忽略的几条规则顶到最前面,是个几乎零成本、收益却很直接的动作,很多人却从来没排过序,只是按写入时间一条条往后堆。
从这个坑里能总结出几个让规则失效的常见写法。第一,文件太长,整体稀释,这是根因。第二,把规则混在大段叙述里,而不是单独成行、加粗或者用列表拎出来,模型容易扫过去。第三,把规则写成描述句而不是祈使句。"我们倾向于在提交前跑测试"这种软描述,远不如"提交前必须运行 npm test"来得有约束力。第四,一条规则里塞了好几个要求,模型往往只执行最前面那个,后面几个要求要拆成独立的条目,别挤在一句话里。
还有最后一招,是当某条规则你怎么调写法都还是不听的时候用的。要知道 CLAUDE.md 终究只是建议,不是强制。官方的兜底办法有两个:轻一点的,给这条规则前面加上 IMPORTANT 或者 YOU MUST 这种强调词,能再抢回一些注意力;重一点的,干脆别指望 CLAUDE.md 了,把它改成一个 PreToolUse Hook。Hook 是真正的强制执行,每次都会跑,不依赖模型的"自觉"。我那条动画渲染验证的规则,最后就是改成了提交前自动跑渲染检查的 hook 才彻底根治的。这里我要给一个旗帜鲜明的判断:凡是"绝对不能错"的硬约束,别赌 CLAUDE.md 的遵守度,直接上 Hook。CLAUDE.md 适合放约定和倾向,不适合放红线。
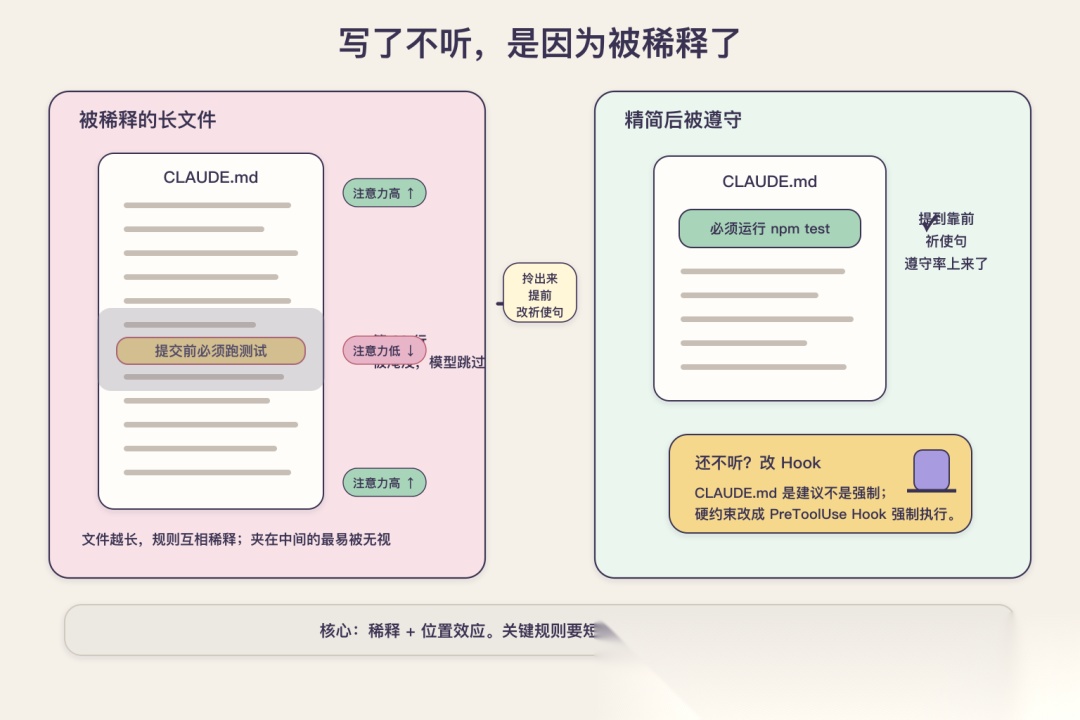
规则为什么不被遵守:长文件把关键规则「稀释」了
三、那到底什么该写进 CLAUDE.md,什么不该
既然每一行都是常驻成本、写多了还会互相稀释,那 CLAUDE.md 就不该是个无脑往里堆的仓库。判断一条信息该不该进,我用三个条件卡,必须同时满足:高频、稳定、跨会话且模型推断不出来。
高频,指的是这条信息几乎每次干活都用得上。比如这个项目用什么包管理器、核心命令是什么、代码风格的硬性约定。这种东西放进常驻区是划算的,因为它的使用频率撑得起每轮重读的成本。反过来,那种几个月才碰一次的冷门流程,放进去就是纯亏。
稳定,指的是它不会三天两头变。项目的长期约定、架构层面的铁律,适合写进去。而那些这个迭代才临时定、下个迭代就改的东西,写进去很快就会过期,反倒变成误导模型的脏数据。
跨会话且推断不出来,这条最容易被忽略。CLAUDE.md 的价值,在于补上模型从代码里读不出来的信息。你的命名规范,模型扫一眼代码就能学会,不用你写;但"我们为什么不用某个库""这个模块的历史包袱是什么"这种藏在决策背后、代码里看不出来的东西,才是 CLAUDE.md 真正该承载的。官方有句话说得很直白:不要在 CLAUDE.md 里写代码已经清楚表达的东西,因为 Claude 自己会读代码。
照着这三个条件,反过来就能列出哪些东西不该进 CLAUDE.md:一次性的临时任务说明,写进对话就行;能从代码直接推断的风格细节;几个月一遇的低频流程,这种更适合做成 skill,需要的时候才加载;还有大段的背景知识科普,那应该拆出去用 @import 引用,或者放进 references。
我拿 AlgoMooc 的 CLAUDE.md 做过一次彻底的体检,按这三条筛了一遍,600 多行砍到了 130 行左右。砍掉的大头是两类:一类是我早期一股脑写进去的、其实从代码就能看出来的命名和结构约定;另一类是那种"某次踩坑后随手记的、之后再没复现过"的低频笔记。砍完之后最直接的变化,是那几条我天天要用的核心约定,遵守率肉眼可见地变好了,因为它们终于不被几百行噪声压着了。换句话说,删掉那四百多行低价值内容,受益的不是被删的部分,而是留下来的那一百三十行,它们拿回了本该属于自己的注意力。这件事的代价也得说清楚:筛选是要花时间的,你得一条条问自己这玩意儿到底高不高频、稳不稳定,半个小时跑不掉。但这笔时间花得值,它换来的是后面每一轮对话的注意力质量。
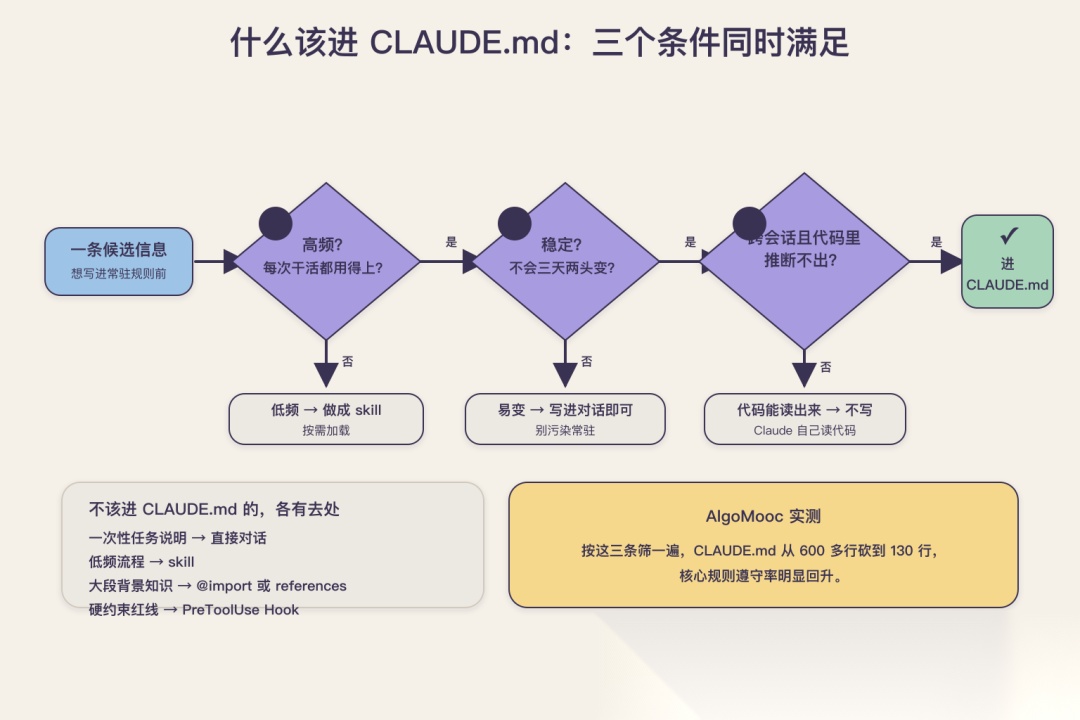
什么该进 CLAUDE.md:高频 + 稳定 + 跨会话且推断不出
四、分层和 @import:别把所有东西堆在一个文件里
就算筛得很干净,一个稍微复杂点的项目,该常驻的东西也未必塞得进一个清爽的文件。这时候要靠分层和 @import 把结构撑开。
先说分层。前面提过 CLAUDE.md 有四层,这个层级不只是加载顺序,更是一种职责划分。你个人的偏好,比如"回复用中文"“我习惯用 pnpm”,应该写进用户全局的 ~/.claude/CLAUDE.md,这样它对你所有项目都生效,而且不会污染团队仓库。团队共享的项目约定,写进项目级的 ./CLAUDE.md,跟着 git 走,所有人共用。只对你自己、且不该进版本控制的东西,比如你本地的某个临时路径,写进 ./CLAUDE.local.md。把这三层分清楚,最直接的好处是项目切换时不串味:你从 AlgoMooc 切到另一个项目,全局那层跟着你走,但 AlgoMooc 项目级的那些约定不会跑到新项目里捣乱。
再说 @import。当某一块内容(比如一份详细的 Git 工作流说明)太长,直接写进 CLAUDE.md 会把主文件撑爆,可以把它拆成单独的文件,在 CLAUDE.md 里用 @docs/git-workflow.md 这样一行引用进来。这里有几个细节要记准,免得用错。第一,被 @import 进来的文件,仍然是会话启动时就展开、常驻加载的,它不会因为你用了 import 就变成按需,所以 import 只是帮你拆分文件、让主文件更清爽,并不能帮你省 token。第二,import 的相对路径是相对于包含它的那个文件,不是相对于工作目录。第三,import 有递归深度上限,最深 4 层,A 引 B、B 引 C、C 引 D 还行,再往下第 5 层就不加载了,别套太深。
还有一个进阶工具值得知道:子目录的 CLAUDE.md 和带路径条件的规则文件。前面说过子目录 CLAUDE.md 是懒加载的,只有 Claude 读到那个目录的文件时才会被加载进来。这意味着你可以把某个模块特有的约定,放进那个模块目录下的 CLAUDE.md,平时它不占常驻预算,只有真正在那个模块里干活时才生效。AlgoMooc 里动画渲染那一坨很专门的约定,我后来就是从主 CLAUDE.md 挪进了 animations/ 子目录下,主文件清爽了,那些约定该生效的时候照样生效。
比子目录 CLAUDE.md 更精细的一招,是 .claude/rules/ 目录加路径条件。你可以在这个目录下放规则文件,给它配一个 paths 字段,指定它只在 Claude 读到匹配某个路径模式的文件时才加载。不带 paths 的规则等同于常驻,带了 paths 的就变成按文件类型条件触发。比如我可以让一条"只针对动画 HTML 的渲染规范"只在 Claude 碰 animations/ 下的 .html 文件时才进上下文,平时它一点预算都不占。这套机制本质上是把 skill 那种"按需加载"的思路,下放到了规则这一层,是给大型项目精细控制常驻预算的利器。
顺带提一个查状态的小工具:/memory 命令。它会列出当前会话实际加载了哪些 CLAUDE.md、CLAUDE.local.md 和规则文件,点进去还能直接编辑。每次你怀疑"到底哪些文件被加载了""我这条规则到底在不在上下文里"的时候,跑一下 /memory 就清楚了,比你瞎猜强。
这套分层工具很强,但它有个边界要提醒:如果你的项目很小、就那么几个文件,根本用不着分层和子目录,强行拆反而是给自己增加维护负担,一个百来行的 CLAUDE.md 足够了。分层是给复杂项目用的,不是越分越高级。
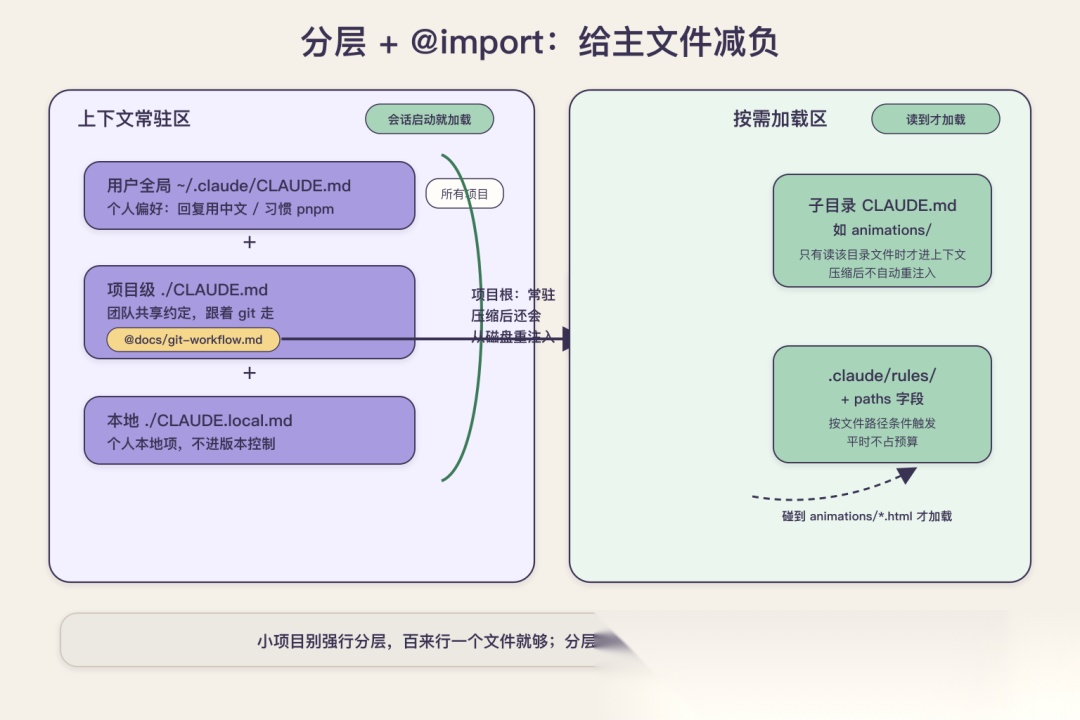
分层与 @import:别把所有东西堆在一个文件里
五、最少人做、却最该做的一步:验证规则真的被遵守
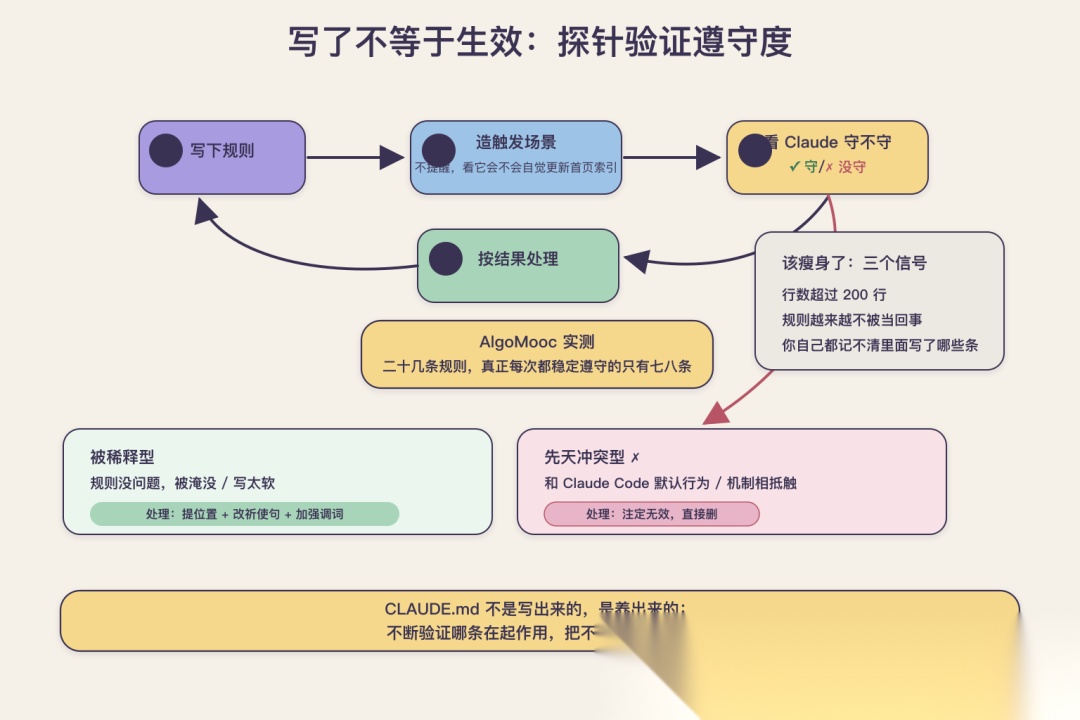
前面四节讲的都是"怎么写",但整套方法论里最关键、也最少有人做的,其实是写完之后的验证。绝大多数人写完 CLAUDE.md 就默认它生效了,从不回头检查。而面试官那句"你测过吗",戳的正是这个空白。
CLAUDE.md 是建议不是强制,所以"写了"和"被遵守"之间永远有个缝。验证遵守度的办法,我自己常用的是探针测试,思路很简单:针对你最在意的那几条规则,故意制造一个会触发它的场景,然后看 Claude 到底守不守。比如你写了"提交前必须跑测试",那你就让它做一个会涉及提交的改动,看它有没有自觉地先跑测试。把每条核心规则都这么探一遍,哪条被无视,一目了然。
举个我在 AlgoMooc 上真探过的具体例子。我 CLAUDE.md 里有一条"新增题解动画后,必须更新首页的题目索引"。我就直接给 Claude 一个任务,让它加一道新题的动画,然后什么都不提醒,看它做完会不会主动去更新索引。第一轮探,它做完动画就停了,索引压根没碰。我把这条规则从第一百多行提到了文件靠前、单独成段、加上"务必"两个字,第二轮再探,它就记得更新了。这种"造场景、看反应、再调整"的探针,比你盯着 CLAUDE.md 干读有用得多,因为干读永远发现不了哪条会被实际无视。
探的时候还要分清规则不被遵守的两种原因,因为对应的处理完全不同。一种是"被稀释型",规则本身没问题,就是被淹没了或者写得太软,这种靠提位置、改祈使句、加强调词就能救回来。另一种是"先天冲突型",你写的规则和 Claude Code 本身的默认行为或机制相抵触,比如你非要让它用某种它根本不支持的方式干活,这种无论你怎么改写法都没用,得认清它注定无效,直接删掉,别在上面浪费精力。把这两种分开,你的精简才不会瞎使劲。
我在 AlgoMooc 上认真做过一轮这种探针,结果挺扎心:当时 CLAUDE.md 里大大小小列了二十几条,我一条条探下来,真正每次都被稳定遵守的,也就七八条。剩下的要么是被几百行噪声稀释了,要么是写成了模糊的描述句,还有几条压根和 Claude Code 本身的默认行为有冲突,属于注定无效。这个结果直接推着我做了三件事:把被稀释的核心规则拎出来、提到文件靠前的位置并改成祈使句;把那条最硬的渲染验证规则从 CLAUDE.md 挪进了 Hook;把那些注定无效和早就过期的,直接删掉。
这就引出维护的最后一环:定期精简。怎么判断你的 CLAUDE.md 该瘦身了?给几个我自己用的信号。一是行数,超过 200 行就该警惕,开始有规则被忽略的风险了。二是遵守率,如果你发现某些写过的规则 Claude 越来越不当回事,往往不是模型变笨了,是文件涨太长把它们稀释了。三是一个很朴素的信号:当你自己都记不清 CLAUDE.md 里到底写了哪些条的时候,它一定已经太长了,该坐下来砍一轮了。精简不是一次性的活,是跟着项目一起长期做的事。一句话收尾这套方法:CLAUDE.md 不是写出来的,是养出来的,而养的核心动作,就是不断验证哪条真在起作用,把不起作用的清掉。
验证规则真被遵守:探针测试 + 定期精简的闭环
六、面试怎么答 CLAUDE.md 维护这道题
如果面试官问"你怎么维护 CLAUDE.md"“CLAUDE.md 和 skill、Hook 怎么分工”“为什么写了 Claude 不听”,按下面四步答,能把这道题接得又稳又显手感。
先点出常驻成本(20 秒): “CLAUDE.md 是会话启动就注入、每轮都常驻上下文的,不像 skill 那样按需加载。所以它不是越全越好,写多少每轮就付多少 token,官方建议控制在 200 行以内,超了模型可能忽略一半规则。”
再讲为什么不听(30 秒): “因为它是作为一条普通用户消息进上下文的,是建议不是强制,会和代码、对话一起争注意力。文件一长,规则互相稀释,靠中间靠后的就被无视了。改法是把核心规则拎到靠前、单独成行、用祈使句,必要时加 IMPORTANT 强调。”
然后讲分工(30 秒): “我按三个条件决定什么进 CLAUDE.md:高频、稳定、跨会话且代码里推断不出来。低频流程做成 skill,按需加载不占常驻预算;绝对不能错的硬约束做成 PreToolUse Hook,强制执行不靠自觉。CLAUDE.md 只放约定和倾向,不放红线。”
最后亮验证意识(20 秒): “最关键的是写完要验证。我会用探针测试,故意触发每条规则看 Claude 守不守,把没生效的要么改写法、要么提位置、要么删掉。我自己项目里探过一轮,二十几条里真正稳定生效的就七八条。CLAUDE.md 是养出来的,不是写出来的。”
能把第四步这个"验证遵守度"答出来,面试官立刻知道你是真用过、真较过劲的,不是装了个工具就来面工程岗。
写在最后
这一篇,本质上是想扭转一个很普遍的错觉:以为 CLAUDE.md 写进去就等于生效。
它不是。CLAUDE.md 是常驻成本,每一行都在每轮对话里重复付费;它是建议不是强制,会被稀释、会被无视;它需要分层来撑结构、需要 @import 来拆文件、需要 Hook 来兜硬约束,更需要你写完之后真的去验证哪条在起作用。把它当成一个要长期养护的活物,而不是一份写完就锁进抽屉的备忘录,你的 Claude Code 才会真的按你的意图干活。
我自己最深的体会是:维护 CLAUDE.md 这件事,考验的根本不是你会不会写 Markdown,而是你有没有"上下文是有成本的、注意力是会被稀释的"这层意识。有了这层意识,你对 skill、Hook、记忆这些机制的取舍才会都顺起来,因为它们解决的是同一个问题的不同切面:什么常驻、什么按需、什么强制。想清楚这三个词怎么分配,你就真的会用 Claude Code 了,而不只是装了它。说到底,工具给你的自由度越高,怎么把它驯服成贴合你工作流的样子,就越是真功夫。这道面试题真正考的,正是这份把工具驯服的功夫。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)