
Agent = LLM + Harness:用Python代码跑一遍就懂了
2026年很多Agent产品爆火了,从OpenClaw到Hermes,再到Codex、Workbuddy等,这些Agent突然闯入了我们的工作和生活中。人们都在谈Agent,那Agent到底是什么?NVIDIA GTC 台北2026中,黄仁勋给出了以下解释:Agent=LLM+Harness。谈一下我的理解,LLM相当于人类的大脑,Harness相当于人的四肢与感官,LLM提供思考能力,感官与四肢可以与现实进行互动。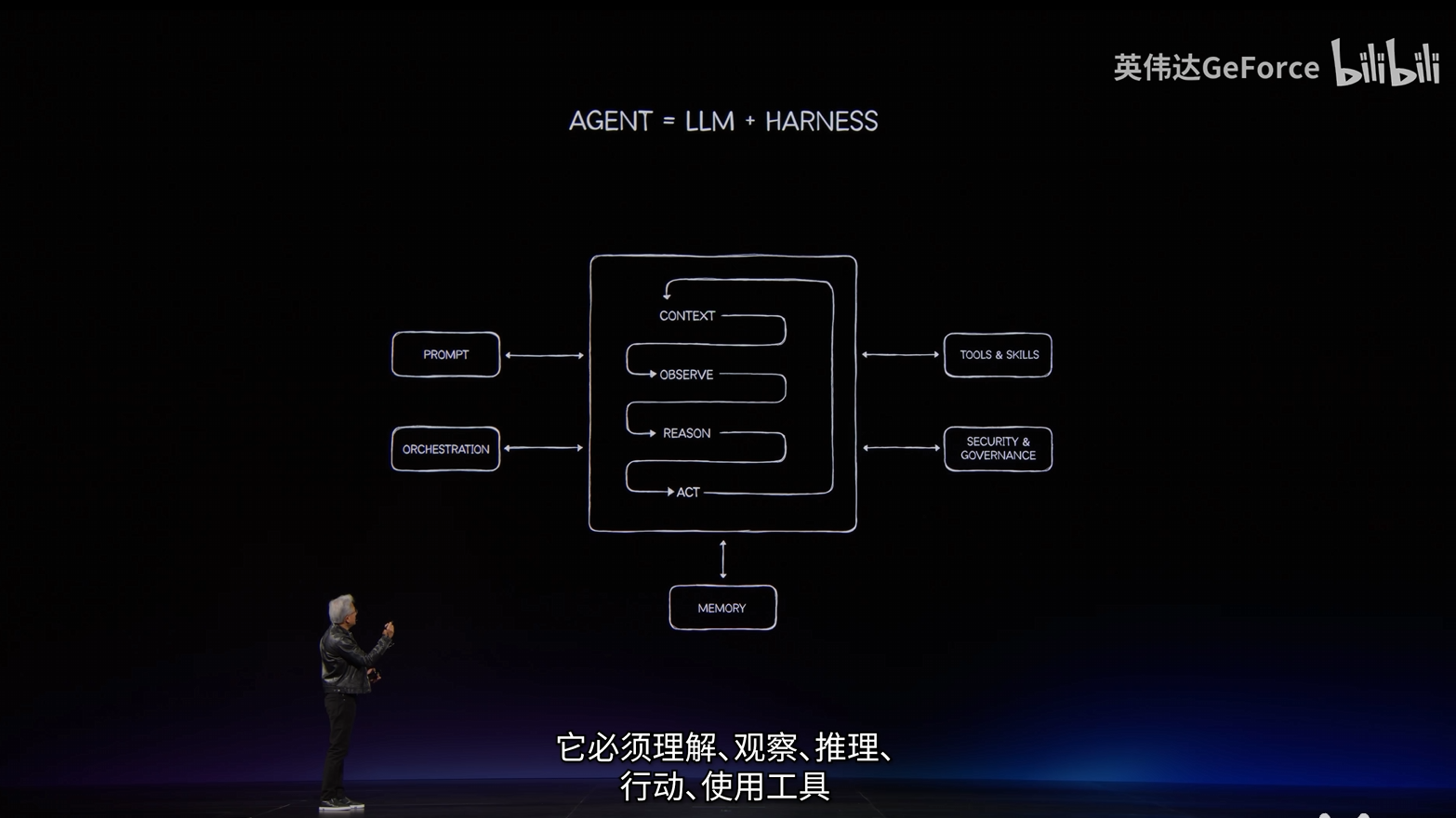
从定义来看,Agent能够感知环境、进行决策并执行行动以达成特定目标。有这么一个公式:Agent = LLM (大脑) + Planning (规划) + Tool use (执行) + Memory (记忆)。
相较于传统的软件,Agent更像是一个有自主性的员工,他可以理解用户的任务目标,制定计划、使用工具、根据情况调整、持续执行直到完成任务。
这里提一个实际的Agent任务例子,比如我让Agent帮我打车到公司,Agent会先分析这是一个使用APP的任务,拆解任务为:1. 找到打车软件 2. 输入目的地 3. 下单,然后模拟用户操作去完成下单,每次操作截图使用视觉模型分析当前页面及下一步要点击的位置,直到页面显示正在呼叫司机。
在这个例子中,LLM负责思考,Planning负责拆解任务,Tool Use负责完成具体操作,Memory负责记住用户的信息比如公司位置、打车平台偏好等。
ReAct模式:Reasoning + Act
提到Agent,不得不说ReAct模式,即Reasoning+Act,可以理解为边思考边行动。ReAct模式是常见的Agent推理执行模式,通常分为以下步骤:
- Thought(思考):LLM理解任务并拆解任务,判断下一步操作
- Action(行动):Harness使用工具完成相应的任务
- Observation(观察):程序将工具执行返回给LLM,LLM基于结果判断下一步
- Repeat(循环):重复1-3,直到LLM认为任务已完成并给出最终答案
对应前边我们提到的Agent=LLM+Harness,Agent能力上限不仅仅取决于LLM,还取决于Harness的设计,以及LLM+Harness这个套餐适配程度。之前看到一个观点,LLM厂商通常会对自家Harness做针对性优化,在这个背景下,原厂LLM+原厂Harness理论上会更稳定。
我写了一个Agent ReAct模式的代码,工具是计算器,用户提问内容是:“帮我算一下 6 * 5 + 六 等于多少,再计算这个结果乘以 2,最后告诉我答案”,源代码放到文末了,先看打印输出:
打印输出
=== 第 1 次调用 ===
[1] system
你是一个简洁的 Agent。需要计算时使用 calculator 工具。
[2] user
帮我算一下 6 * 5 + 六 等于多少,再计算这个结果乘以 2,最后告诉我答案
=== tools definitions ===
{
"type": "function",
"function": {
"name": "calculator",
"description": "用于执行简单数学计算",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "要计算的数学表达式,例如:2 + 3 * 4"
}
},
"required": [
"expression"
]
}
}
}
LLM 返回内容:先算第一个表达式:6 * 5 + 6
LLM 返回 tool call:
tool_call_id: call_00_guHDSVstflmqe6hru9rZ9277
name: calculator
arguments: {"expression": "6 * 5 + 6"}
LLM tool call 执行内容:
tool_call_id: call_00_guHDSVstflmqe6hru9rZ9277
name: calculator
arguments: {'expression': '6 * 5 + 6'}
tool 执行结果:36
=== 第 2 次调用 ===
[1] system
你是一个简洁的 Agent。需要计算时使用 calculator 工具。
[2] user
帮我算一下 6 * 5 + 六 等于多少,再计算这个结果乘以 2,最后告诉我答案
[3] assistant
先算第一个表达式:6 * 5 + 6
[4] tool
36
tool_call_id: call_00_guHDSVstflmqe6hru9rZ9277
=== tools definitions ===
<省略>
=== tools definitions ===
LLM 返回内容:再计算 36 × 2:
LLM 返回 tool call:
tool_call_id: call_00_dvhsq8Jk5Lm6504Afrg19236
name: calculator
arguments: {"expression": "36 * 2"}
LLM tool call 执行内容:
tool_call_id: call_00_dvhsq8Jk5Lm6504Afrg19236
name: calculator
arguments: {'expression': '36 * 2'}
tool 执行结果:72
=== 第 3 次调用 ===
[1] system
你是一个简洁的 Agent。需要计算时使用 calculator 工具。
[2] user
帮我算一下 6 * 5 + 六 等于多少,再计算这个结果乘以 2,最后告诉我答案
[3] assistant
先算第一个表达式:6 * 5 + 6
[4] tool
36
tool_call_id: call_00_guHDSVstflmqe6hru9rZ9277
[5] assistant
再计算 36 × 2:
[6] tool
72
tool_call_id: call_00_dvhsq8Jk5Lm6504Afrg19236
=== tools definitions ===
<省略>
=== tools definitions ===
LLM 返回内容:计算结果如下:
1. **6 × 5 + 6** = 30 + 6 = **36**
2. **36 × 2** = **72**
最终答案是 **72** ✅
============================================
最终结果: 计算结果如下:
3. **6 × 5 + 6** = 30 + 6 = **36**
4. **36 × 2** = **72**
最终答案是 **72** ✅
代码执行过程分析
在这个代码执行过程中,我们来分析一下:
- Thought阶段: LLM接收到用户的指令:"帮我算一下 6 * 5 + 六 等于多少,再计算这个结果乘以 2,最后告诉我答案"以及tool定义后,LLM判断需要执行计算,返回了第一个tool call
- Action阶段: 程序调用eval来执行tool call,生成结果
- Observation阶段:程序将结果追加到messages中,用于LLM后续思考
- Thought阶段:LLM读取上一轮Observation,发现任务未完成,返回第二个tool call
- Action阶段:程序调用eval来执行tool call,生成结果
- Observation阶段:程序将结果追加到messages中,用于LLM后续思考
- Final Answer阶段:LLM读取上一轮Observation,判断任务已完成,直接生成最终答案
最后
本文我们了解了Agent是什么以及它的工作原理,纸上得来终觉浅,真正上手后还能体会到Agent与LLM的不同。最后我来推荐几个用的还不错的Agent:
- Codex,推荐指数5星,拥有Computer Use、浏览器操作功能的桌面Agent,既可完成工作也可以编写代码,免费用户有额度,订阅用户经常会重置用量(好评)
- WorkBuddy,推荐指数4星半,腾讯家的桌面Agent,有免费额度可用,可以用于工作和生活中,容易上手,推荐所有人使用,是当前国内最热的Agent之一
- Github Copilot(程序开发),推荐指数4星半,有免费额度,作为IDE插件,代码补全很好用,也可以对代码提问
- Claude Code(程序开发),推荐指数4星,定位是开发者工具,编程领域强大,缺点是需要购买LLM、对普通办公用户不太友好。但是,如果你是开发者并已经订阅了Coding Plan,那它的推荐指数可以给到5星,Claude Code已经成为CLI编程Agent的标杆产品。
附源码
import os
import json
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
def calculator(expression: str) -> str:
try:
result = eval(expression, {"__builtins__": {}})
return str(result)
except Exception as e:
return f"计算失败:{e}"
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "用于执行简单数学计算",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "要计算的数学表达式,例如:2 + 3 * 4"
}
},
"required": ["expression"]
}
}
}
]
tool_map = {
"calculator": calculator
}
def print_messages(messages):
"""打印当前完整对话上下文"""
print("\n========== 当前 messages ==========")
for i, m in enumerate(messages, 1):
print(f"\n[{i}] role: {m.get('role') if isinstance(m, dict) else m.role}")
if isinstance(m, dict):
print(f"content: {m.get('content')}")
if m.get("tool_call_id"):
print(f"tool_call_id: {m.get('tool_call_id')}")
else:
print(f"content: {m.content}")
if m.tool_calls:
print("tool_calls:")
for tc in m.tool_calls:
print(f" id: {tc.id}")
print(f" name: {tc.function.name}")
print(f" arguments: {tc.function.arguments}")
print("===================================\n")
def dedupe_repeated_content(content: str) -> str:
normalized = content.strip()
if not normalized:
return content
if len(normalized) % 2 == 0:
first_half = normalized[: len(normalized) // 2].strip()
second_half = normalized[len(normalized) // 2 :].strip()
if first_half and first_half == second_half:
return first_half
lines = normalized.splitlines()
if len(lines) % 2 == 0:
half = len(lines) // 2
first_half_lines = [line.rstrip() for line in lines[:half]]
second_half_lines = [line.rstrip() for line in lines[half:]]
if first_half_lines == second_half_lines:
return "\n".join(first_half_lines).strip()
paragraphs = [p.strip() for p in normalized.split("\n\n") if p.strip()]
if len(paragraphs) % 2 == 0:
half = len(paragraphs) // 2
if paragraphs[:half] == paragraphs[half:]:
return "\n\n".join(paragraphs[:half])
return content
def build_full_prompt(messages, tools=None):
"""构建完整 prompt 文本,包含 messages 和 tools 定义"""
prompt_chunks = []
for i, m in enumerate(messages, 1):
if isinstance(m, dict):
role = m.get("role")
content = m.get("content", "")
else:
role = m.role
content = m.content
prompt_chunks.append(f"[{i}] {role}\n{content}")
if isinstance(m, dict) and m.get("tool_call_id"):
prompt_chunks.append(f"tool_call_id: {m['tool_call_id']}")
if tools:
prompt_chunks.append("\n=== tools definitions ===")
for tool in tools:
prompt_chunks.append(json.dumps(tool, ensure_ascii=False, indent=2))
return "\n".join(prompt_chunks)
def run_agent(user_input: str):
messages = [
{
"role": "system",
"content": "你是一个简洁的 Agent。需要计算时使用 calculator 工具。"
},
{
"role": "user",
"content": user_input
}
]
round_num = 1
while True:
print(f"\n=== 第 {round_num} 次调用 ===")
print(build_full_prompt(messages, tools=tools))
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=messages,
tools=tools,
tool_choice="auto"
)
# 提取调用返回的 token 统计信息,方便后续调试和成本分析
usage = getattr(response, "usage", None)
if usage is None and isinstance(response, dict):
usage = response.get("usage", {})
prompt_tokens = usage.get("prompt_tokens") if isinstance(usage, dict) else getattr(usage, "prompt_tokens", None)
completion_tokens = usage.get("completion_tokens") if isinstance(usage, dict) else getattr(usage, "completion_tokens", None)
total_tokens = usage.get("total_tokens") if isinstance(usage, dict) else getattr(usage, "total_tokens", None)
# print(f"本次调用 token 统计:输入={prompt_tokens},输出={completion_tokens},总计={total_tokens}")
# 解析 LLM 响应消息,并把重复输出内容去重后打印
msg = response.choices[0].message
deduped = dedupe_repeated_content(msg.content)
print(f"LLM 返回内容:{deduped}")
if msg.tool_calls:
print("LLM 返回 tool call:")
for tc in msg.tool_calls:
print(f" tool_call_id: {tc.id}")
print(f" name: {tc.function.name}")
print(f" arguments: {tc.function.arguments}")
messages.append(msg)
# 如果没有 tool call,则认为已经获得最终回答
if not msg.tool_calls:
return msg.content
# 处理每个 tool call:打印调用内容、执行工具、记录 Observation
for tool_call in msg.tool_calls:
tool_name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
print("LLM tool call 执行内容:")
print(f" tool_call_id: {tool_call.id}")
print(f" name: {tool_name}")
print(f" arguments: {args}")
result = tool_map[tool_name](**args)
print(f"tool 执行结果:{result}")
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
round_num += 1
if __name__ == "__main__":
answer = run_agent("帮我算一下 6 * 5 + 六 等于多少,再计算这个结果乘以 2,最后告诉我答案")
print("\n============================================")
print("最终结果: "+ answer)


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)