
Kimi Code 突然能看视频了?视频理解能力超过 Codex 和 Claude
前两天我朋友问我一件事。他说他最近试了几个 AI coding 工具,突然发现 Kimi Code 看视频的能力变得特别强,强到他觉得有点不可思议。
他去查了一圈官方文档和更新日志,发现了一个很有意思的东西 —— 这背后不是某一个版本的魔法,而是一场三管齐下的 quietly stacked upgrade。

一、优化视频理解是框架层
你如果只看 kimi-code@0.18.0 这个最新版的 release note,headline 写的是 AgentSwarm 并发上限、web session 搜索、OAuth 登录流程这些东西。跟视频半毛钱关系都没有。
但如果你去翻 kimi-code 的源码,会发现一个被 release note 完全忽略的东西——框架层其实早就搭好了视频理解的通路。
ReadMediaFile 这个内置工具,在 packages/agent-core/src/tools/builtin/file/read-media.ts 里,负责做三件事:
-
1. 读取视频文件,base64 编码
-
2. 检查模型是否有
video_in能力,没有就直接报错退出 -
3. 把视频内容包装成
<video>tag +video_urlpart,塞进模型的 multimodal input
这个工具不是 K2.7 才有的。 它一直都在框架里。区别在于,之前没有人引导 agent 用它。
GitHub 上 PR [#816](javascript:😉 做的事情,就是在 read-media.md 的提示词里加了一句话:“分析视频文件时,优先使用 ReadMediaFile,不要自己写 Python 切帧。”
就这么一句话,改变了 agent 的默认行为路径。
你以为这是模型能力的升级。实际上这是框架层的一次 quietly stacked 推进——工具早就有了,缺的是一个 prompt 引导 agent 走对的路径。
模型给了能力,框架决定了你能不能用上。
二、K2.6 也有 ReadMediaFile,区别在哪?
这里有一个很多人会忽略的事实:K2.6 时代,ReadMediaFile 工具就已经在框架里了。
我去翻了 K2.6 的官方 quickstart 文档,里面明明就有:
-
•
Video Understanding Code Example -
•
Multimodal Tool Capability Example -
• 一个叫
watch_video_clip的工具,还支持start_time和end_time做片段分析
那为什么大家之前没什么感觉?
因为 K2.6 时代的视频能力,更像是一个"也支持"的备注,不是一个一等公民。
而 K2.7 Code 时代,框架层做了三件不一样的事:
第一件事,prompt 引导到位了。PR [#816](javascript:😉 在 read-media.md 和 read.md 里都加了提示词,告诉 agent:别自己切帧了,用内置工具。
第二件事,plumbing 修好了。6 月 10 号的 0.14.0 修复了图片输出丢失,6 月 12 号的 0.14.1 修复了音视频附件静默消失。之前你发了一个视频,agent 可能自己切帧然后丢掉了,现在至少会变成一个占位文本,然后把媒体重新挂回对话。
第三件事,产品叙事变了。README 把 Video input 从角落里搬到了核心的位置。

不过要澄清一点:ReadMediaFile 不是随便哪个模型都能用的。 源码里明确 gated on video_in capability,不支持视频输入的模型调用它会直接报错。所以框架提供了通路,但模型得有对应的能力。这两者缺一不可。
三、那些看不见的工程补课,决定了你的体感
很多时候,让你觉得"变强了"的,不是 benchmark 上的数字,而是那些 nobody cares 的 plumbing 修复。

-
• 6 月 10 号,
0.14.0:修复了Preserve image outputs from tools——之前工具返回的图片输出会丢,现在保留了。 -
• 6 月 12 号,
0.14.1:修复了Degrade unsupported audio/video to placeholder text and reattach tool result media——之前音视频附件如果模型不支持,会静默消失;现在至少会变成一个占位文本,然后把媒体重新挂回对话。
这串更新看起来不起眼,但体感影响巨大。
什么意思呢?想象一下,你之前给 Kimi Code 发了一段屏幕录制,想让它帮你还原一个 UI 交互。结果它看完了视频,返回的代码里缺少动画效果,因为你发给它的视频附件被静默丢弃了。你很崩溃。
现在?附件不会被丢了。工具返回的图片、音视频,至少会出现在对话里。
这类 plumbing 改善,用户体感往往比任何 benchmark 都重要。
四、为什么这件事对开发者有意义
好,我们来聊聊核心问题:视频理解进入 coding agent 的主路径,到底打开了哪些新场景?
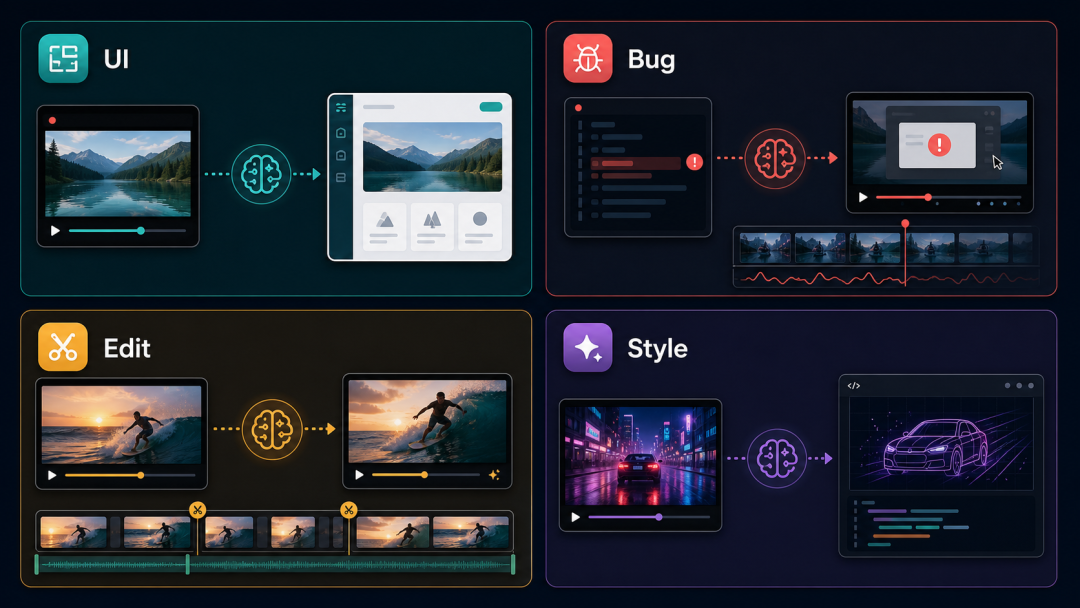
根据 Kimi Code 官方文档和 README,至少有三个方向值得注意:
第一个,UI 复刻。
把一个产品的 demo 录屏直接丢给 agent,让它还原前端交互和细节。以前你可能需要截十几张图、写几百字描述"这个按钮点击后有个下拉菜单,菜单里有三个选项,颜色分别是…"。现在?一段录屏就够了。
第二个,Bug 诊断。
你遇到一个偶发的界面 bug,复现过程很复杂。与其写长篇大论的文字说明,不如录一段 30 秒的视频——agent 先看现象,再读代码,再定位原因。
视频正在从"额外附件",变成一种更高带宽的需求输入。
什么意思呢?就是你描述一个动态行为、一个交互流程、一个时序问题的时候,视频的带宽远高于文字。以前你被迫用文字描述视频才能交给 AI,现在这个障碍消失了。
第三个,自动化剪辑和生成。
官方 README 里直接举了例子:把 reference clip 转成 LUT(调色预设)、把长视频压缩成短视频。这些任务横跨代码生成和媒体处理。
第四个,视频风格复刻——这可能是最性感的场景。
现在有很多视频是基于 HyperFrames、HTML + CSS 动画、Remotion 这类工具生成的。以前你要复现一个视频的风格,需要逐帧截图、手动调整参数、反复调试。现在?你把参考视频丢给 Kimi Code,让它看一遍动态效果,然后在本地用代码复现出来。
不是简单的 UI 还原,而是真正的视觉语言转译——动画节奏、转场方式、色彩搭配、粒子效果,甚至逐帧的细节。agent 看了视频之后,输出的不是文字描述,而是可执行的 Remotion 代码或者 HTML/CSS 动画。
这意味着什么?意味着"参考视频 -> 可执行代码"这个闭环,终于被打通了。
五、但先别急着下结论
这里有一个非常重要的冷静环节。
我检索了一圈 Claude Code、OpenAI Codex 的官方文档,发现一个有意思的现象:它们当前的公开路线,明显更偏"图像 / 截图 / 抽帧"。
Anthropic 的官方 Vision 文档,主标题和正文都围绕 images 展开。更关键的是,他们的 prompt guidance 里直接写到:你也可以让 Claude 分析视频,方法是把视频拆成 frames。
这几乎就是公开文档层面的明示:Claude 现阶段公开的视频分析标准路径,不是原生整段视频输入,而是 frame-based workflow。
OpenAI 那边也类似。他们的官方 cookbook 里有一篇示例叫 Processing and narrating a video with GPT-4.1-mini's visual capabilities,明确说模型 doesn’t take videos as input directly,做法是把整段视频变成 static frames。
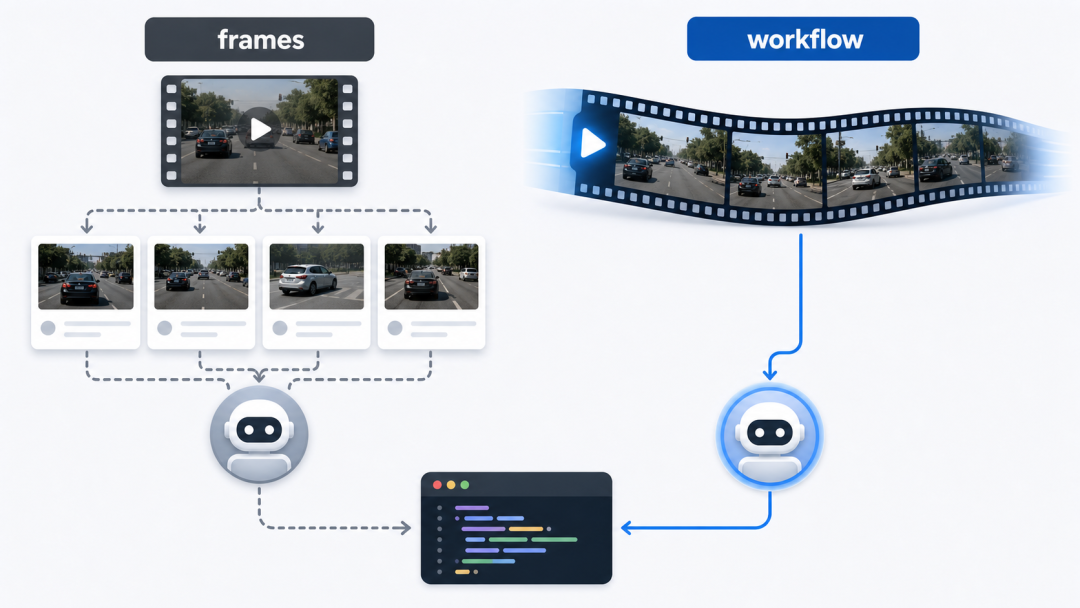
抽帧分析与产品级视频工作流的差异
所以你的主观体感上会觉得:
-
• Claude / Codex 更像"看一组静态证据"
-
• Kimi Code 更像"真的在看一段连续发生的事情"
但这不一定是代际差距,更可能是产品叙事和默认路径的差异。
而且,Kimi K2.7 Code 的文档自己也写了:视频 token 消耗取决于 keyframes 的数量与分辨率。 这说明它很可能也不是"把原始视频每一帧无差别全量喂进去",而是存在内部的关键帧采样机制。
我们只能稳妥地说:
-
• 在产品交互和 agent 工作流层面,Kimi 更像"直接理解视频"
-
• Claude / OpenAI 当前公开文档更明确地展示了"抽帧分析"路线
-
• 在底层实现层面,Kimi 也很可能存在内部采样、压缩、切片等机制,只是这些复杂度被产品封装掉了
公开路线不同,不代表底层架构完全不同。
六、所以,现在值得试一轮吗?
如果你的需求符合以下任一场景,值得一试:
-
• 你有屏幕录制或 demo clip,想让 AI 帮你还原前端交互
-
• 你有一个时序性的 bug,用文字描述起来很费劲
-
• 你想探索"视频 -> 代码 -> 视频"这个新路径的可能性
如果你只是想让它读代码、改代码、跑命令,那现有的能力已经够用了,视频理解不是你的主要需求。
工具的价值,取决于你拿它解决什么问题。
七、更大的图景
这件事放在更大的背景下看,其实是一个清晰的趋势:
多模态正在从"模型能做"走向"agent 默认路径"。
过去两年,我们看到了太多模型级别的突破——GPT-4V、Gemini、Claude Vision,都能看图、能看视频。但这些能力大多停留在"你可以上传一张图片"的层面。
Kimi Code 这次的推进方向不一样。它在做三件事:
-
1. 模型层:K2.7 Code 声明了
video_incapability,原生支持视频输入 -
2. 框架层:
ReadMediaFile工具封装了视频读取、base64 编码、上传逻辑,并通过 prompt 引导 agent 优先调用 -
3. 产品层:README 把
Video input写成核心卖点,让开发者直接可用
这三件事同时发生,才构成了你感受到的"视频理解突然变强"。
缺了任何一个环节都不行。模型有 video_in 但没有框架工具,agent 还是会自己切帧。框架有 ReadMediaFile 但模型不支持 video_in,工具直接报错。产品宣传到位但底层 plumbing 没修好,用户体验照样翻车。
这不是某一个模型的魔法。这是一场 quietly stacked 的三层协同推进。
而更大的问题是:当视频成为 coding agent 的一等输入模态之后,"描述一个需求"这件事本身,会被彻底改写。
以前你用文字描述交互流程,像在写说明书。以后你可能直接录一段屏,像在带新人看一遍。
带宽提升了,门槛就降低了。门槛降低了,参与者就变多了。

从文字说明到视频录屏的需求输入变化
这可能才是这件事最值得关注的地方。
延伸阅读 / 参考来源:
-
• MoonshotAI kimi-code releases: https://github.com/MoonshotAI/kimi-code/releases
-
• Kimi K2.7 Code 官方公告 (2026-06-16): https://forum.moonshot.ai/t/here-comes-kimi-k2-7-code-better-coding-with-more-efficiency/441
-
• Kimi K2.7 Code Quickstart Docs: https://platform.kimi.ai/docs/guide/kimi-k2-7-code-quickstart
-
• Kimi K2.6 Quickstart Docs: https://platform.kimi.ai/docs/guide/kimi-k2-6-quickstart
-
• PR [#816](javascript:😉 - Prefer ReadMediaFile for video analysis: https://github.com/MoonshotAI/kimi-code/pull/816
-
• ReadMediaFileTool source: https://github.com/MoonshotAI/kimi-code/blob/main/packages/agent-core/src/tools/builtin/file/read-media.ts
-
• Anthropic Vision Docs: https://docs.anthropic.com/en/docs/build-with-claude/vision
-
• OpenAI Video Understanding Cookbook: https://developers.openai.com/cookbook/examples/gpt_with_vision_for_video_understanding

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)