
Codex如何无缝对接Ollama本地模型库
·
Codex如何无缝对接Ollama本地模型库
一、 添加自定义模型供应商
-
进入配置入口
打开Codex客户端,在CC Switch目的上方找到 “+” 号按钮,点击后选择 “部署” 选项。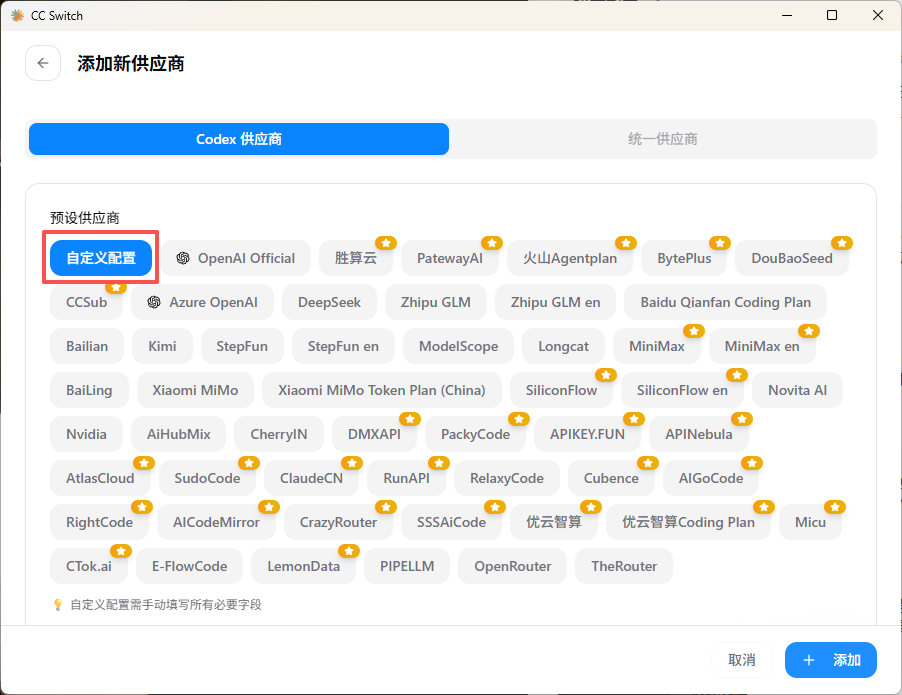
-
新建供应商
在部署页面点击 “添加新的供应商”。系统支持API对接和本地模型对接,此处我们选择第一个选项 “自定义配置”。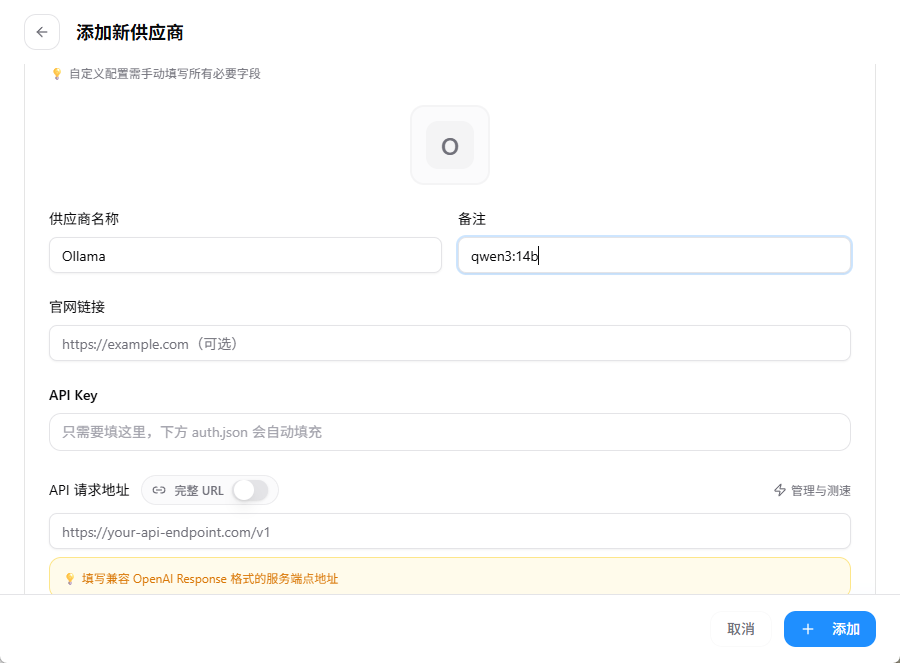
-
填写基础信息
- 模型供应商名称: 可自定义,例如输入
ollama。 - 备注信息: 用于区分模型,例如输入
qwen3:14b。 - 官网链接: 本地模型无需填写,留空即可。
- API Key: 本地模型不校验Key,可随意填写(如
123456)。
- 模型供应商名称: 可自定义,例如输入
⚠️ 关键配置: 请求地址必须填写Ollama的本地服务地址:
http://localhost:11434
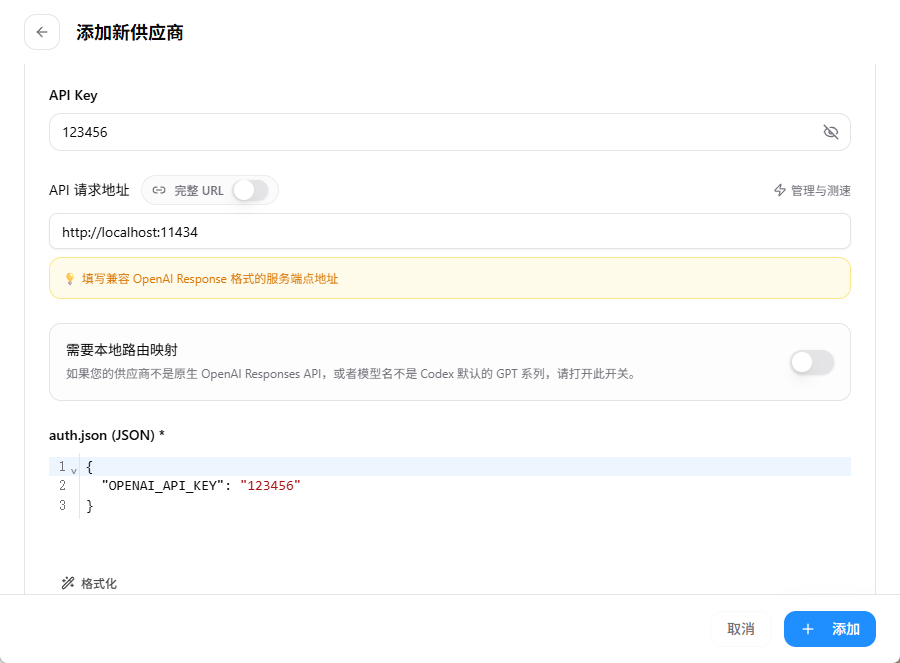
二、 模型映射与连接测试
-
获取本地模型列表
填写完请求地址后,向下滚动找到 “本地路由映射” 区域,点击获取模型。若本地Ollama服务正常运行,系统将自动拉取已下载的模型列表。
注:本文示例中成功获取了6个本地模型,表明连接正常。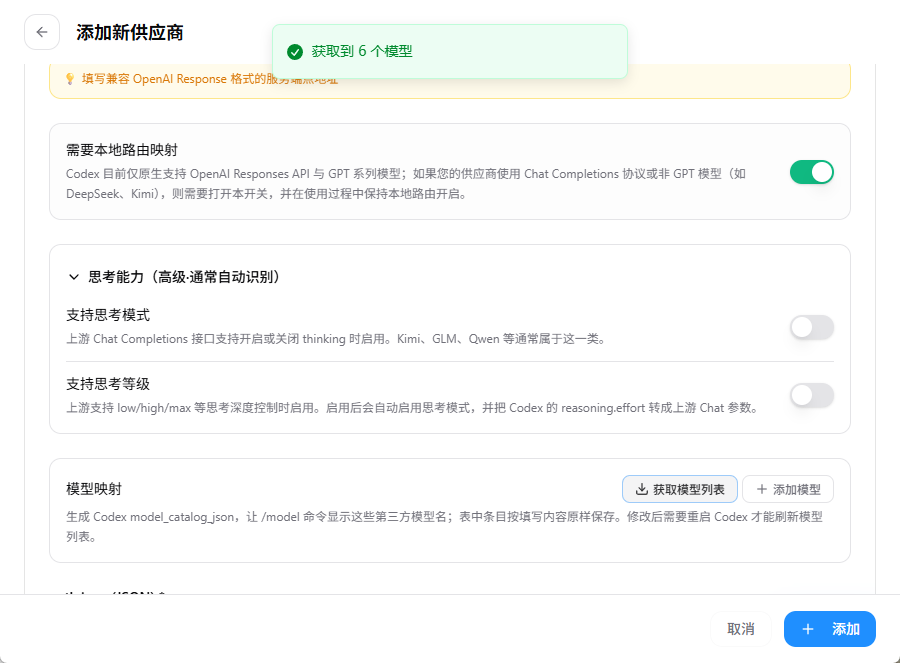
-
配置主模型映射
- 在主模型部分选择对应的本地模型。
- 模型映射字段需与Ollama中的模型标签严格一致,例如本文使用的
qwen3:14b。 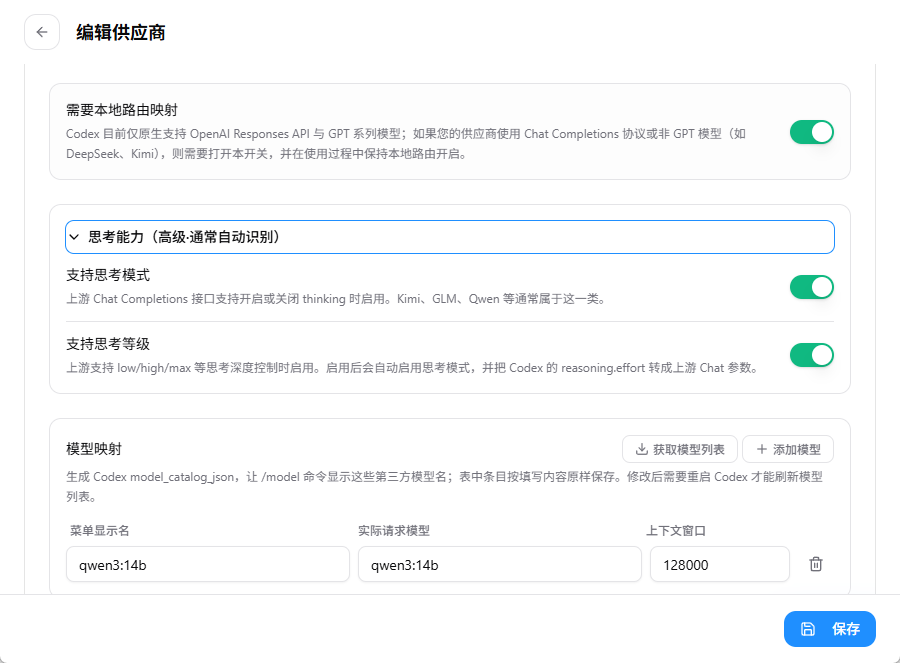
-
启用显示按钮
在指定位置勾选 “启用” 复选框,启用后该模型的快捷按钮将在主页显示,方便快速切换。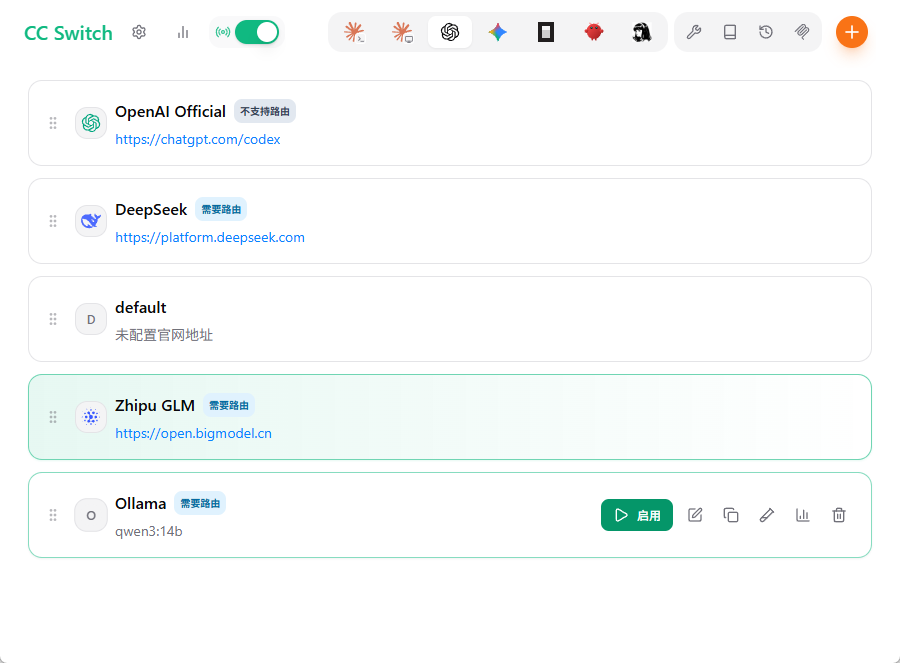
三、 开启路由功能(必做步骤)
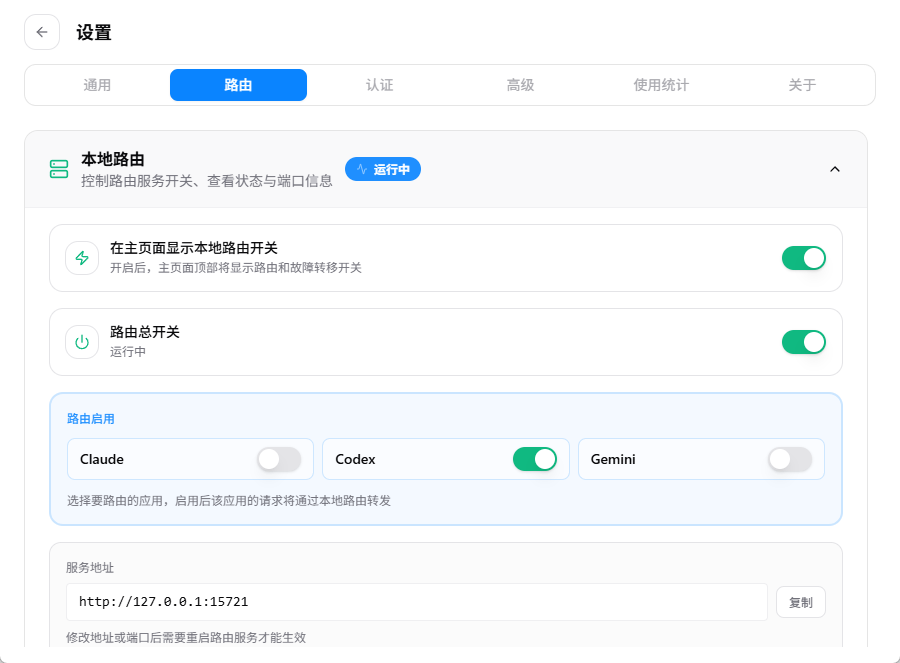
很多用户配置完供应商后发现无法调用,通常是因为忽略了路由开关的设置:
- 点击软件上方的 “设置” 按钮。
- 进入 “路由功能” 开关打开(默认关闭)。
- 同时开启 “路由总开关”,并确保主页上的本地路由开关处于激活状态。
四、 常见问题:首次调用无响应怎么办?
🔍 现象描述
在Codex对话框中输入“你好”没有任何反应,但再次发送“在吗”却能正常回复。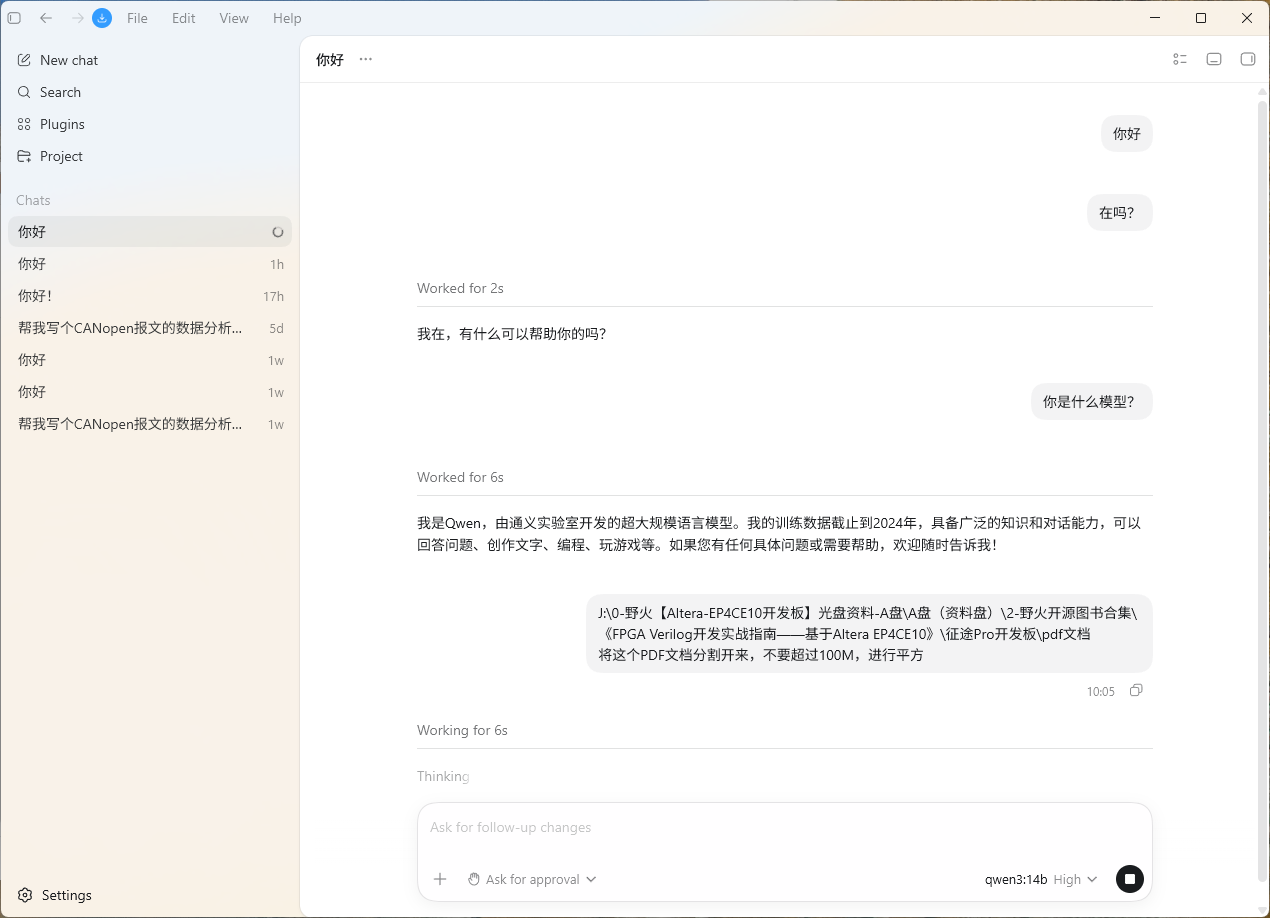
💡 原因分析
这并非配置错误,而是 模型冷启动加载机制 导致的:
- 首次调用时,Ollama需要将模型权重从硬盘加载到显存/内存中。
- 通过任务管理器可以观察到GPU占用率飙升,说明数据正在传输。
- 第二次调用时模型已在显存中就绪,因此响应迅速。
✅ 解决方案
- 耐心等待: 首次对话请给予10-30秒的加载时间(取决于模型大小和硬件性能)。
- 预热技巧: 可在正式使用前先发送一条简单消息触发加载。
- 保持活跃: Ollama默认会在空闲一段时间后卸载模型,频繁使用时可调整
OLLAMA_KEEP_ALIVE环境变量延长驻留时间。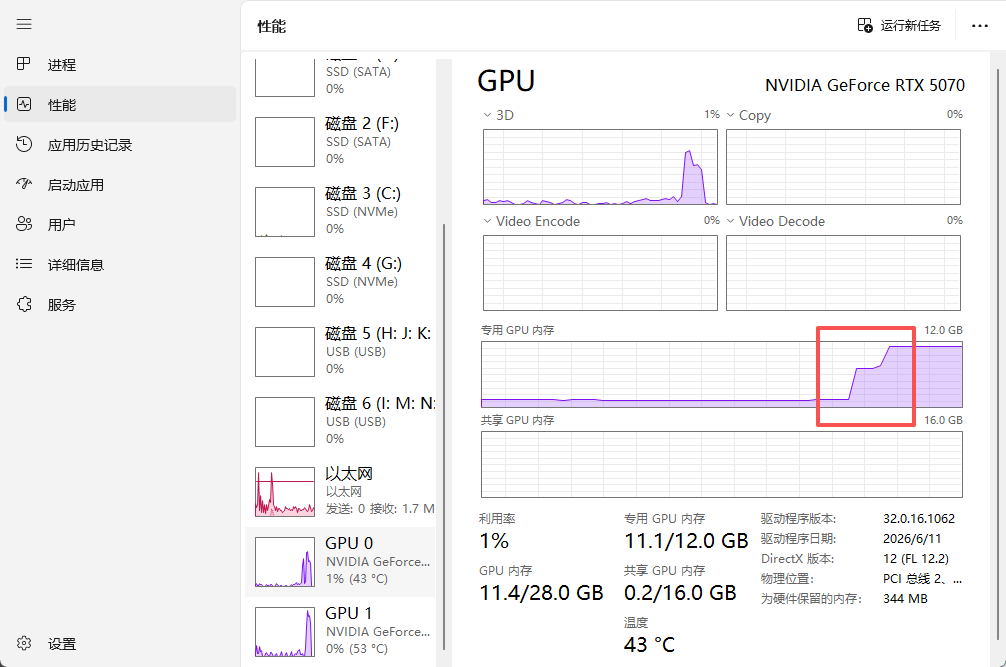
五、 总结
| 配置项 | 推荐值/说明 |
|---|---|
| 请求地址 | http://localhost:11434 |
| API Key | 任意值(如123456) |
| 模型映射 | 与Ollama模型名一致(如qwen3:14b) |
| 路由功能 | 必须手动开启 |
| 首次响应 | 等待模型加载至显存 |
通过以上步骤,即可实现Codex与本地Ollama模型的稳定对接。本地部署不仅响应速度快,还能完全掌控数据安全,是个人开发者和企业内网环境的理想选择。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)