
Claude和Codex怎么做私域社群SOP?欢迎语、标签和跟进表一次梳理清楚
Claude和Codex怎么做私域社群SOP,真正要解决的不是“能不能让 AI 写几段文字”,而是把一个重复、琐碎、容易出错的业务流程拆成可检查的步骤。私域社群运营场景里,最常见的问题是资料散、要求多、版本来回改,人手一忙就容易漏项。
这篇文章按真实工作流来讲:先明确交付物,再分清 Claude 和 Codex 各自适合做什么,最后用 API 管理后台里的密钥、用量和一键接入信息,把模型能力接到自己的工具或脚本里。全文不追求夸张的全自动,而是让新手能照着跑通一条稳定流程。
适合阅读的人群:私域运营、社群管理员、课程顾问和本地服务商家。如果你现在已经有一堆资料、表格、聊天记录或文档,却不知道怎么让 AI 真正进入工作流,可以先从本文的步骤做一个小样板。
文中示例里的 API Key 统一使用 sk-xxxxxxxx 占位。真实密钥只应在自己的后台和本地配置里使用,不要截图公开,也不要写进文章、代码仓库或聊天记录。
文章目录
- 这个场景真正要自动化的是什么
- Claude 更适合负责哪些内容理解工作
- Codex 更适合处理哪些批量整理任务
- 接入模型前,后台信息应该怎么准备
- 从一份样例跑通到批量复用的操作步骤
- 发布、交付或团队使用前怎么做质量检查
1、这个场景真正要自动化的是什么
新人进群、用户分层、活动提醒和成交跟进都靠手动复制,团队人数一多就容易漏跟。很多人第一次尝试时,会直接让 AI “帮我全部做好”,结果往往得到一份看似完整、但很难直接交付的内容。更稳的方式,是先定义清楚中间结果,再让 AI 分段参与。
先把最终交付物拆成中间结果
在私域社群运营里,建议先把目标拆成这些结果:社群欢迎语、用户标签规则、跟进节奏表、常见问题回复库和复盘模板。每一项都应该能单独打开、单独检查、单独修改。这样即使某一步生成得不够好,也不会影响整个流程。
不要一次性把所有资料都塞给模型
如果资料来自聊天记录、表格、PDF、历史文档和截图,先做一次筛选。删除过期信息、重复段落和明显无关内容,再让模型参与整理。资料越干净,后面的结果越稳定。
用一份真实样例先跑通
不要先追求批量处理几十份材料。先拿一份真实样例跑通,从输入、整理、输出到人工审核都走一遍。等这条链路稳定后,再复制到更多资料上。
后台概览:先确认账号状态、可用入口和当前后台信息,再开始配置本地工具
2、Claude 更适合负责哪些内容理解工作
Claude 更适合放在“理解和表达”环节。它的价值不是替你做所有决定,而是把复杂资料整理成更清楚的结构,帮助你发现遗漏、重复和表达不一致的地方。
让 Claude 先做资料清洗
可以先让 Claude 对原始资料做归类、摘要和缺失信息标记。比如在私域社群运营里,它可以先把材料分成背景、目标、限制、执行步骤、风险和待确认问题几类。
示例指令可以这样写:
请基于下面的用户来源和购买阶段,整理一套社群SOP,包含欢迎语、三天跟进、七天转化和沉默用户唤醒。
请不要编造资料里没有出现的信息;不确定的地方单独放到“需要人工确认”里。让 Claude 重写成更适合业务沟通的表达
很多原始资料像流水账,不适合直接交付。Claude 可以把长段落改成更清楚的标题、短句和步骤说明。它适合帮助你把“我知道这件事”变成“别人一看就知道要怎么做”。
保留人工判断的位置
只要涉及金额、承诺、客户名称、合同条款、岗位评价、对外口径等内容,都不要完全交给模型决定。Claude 可以提示风险,但最终判断仍应由熟悉业务的人确认。
3、Codex 更适合处理哪些批量整理任务
Codex 更适合放在“文件、表格、脚本和批量处理”环节。它可以帮助你把资料整理成固定格式,也可以辅助生成检查脚本、目录结构、模板文件和批量处理流程。
让 Codex 输出固定字段
建议每次都让 Codex 输出固定字段,而不是一段自由发挥的长文。以私域社群运营为例,可以固定为:编号、来源、任务说明、输出内容、待确认问题、负责人、完成状态。字段固定之后,后面才方便复制、筛选和复用。
让 Codex 做批量检查
把话术库整理成结构化表格,生成导入模板和每日跟进清单。这些任务的共同点是规则明确、重复度高、适合用脚本或结构化文件来处理。相比手动复制粘贴,Codex 更适合帮你把这些小动作连起来。
先生成草稿,再进入正式文件
不要一开始就要求生成最终成品。更稳的流程是:先生成 Markdown、表格或 JSON 草稿,人工确认字段和结构没有问题,再导入正式文档、系统或协作平台。
API 密钥页面:按任务或项目管理调用凭证,真实密钥不要公开展示
4、接入模型前,后台信息应该怎么准备
无论你用的是 Codex、Claude Code、脚本、低代码平台还是内部工具,只要需要调用模型,都离不开三类信息:调用凭证、模型名称和工具配置片段。新手最容易出错的地方,就是把这些信息手动抄错。
先确认密钥对应的用途
不要把测试用途、正式用途和团队共用用途混在同一个 Key 里。建议按业务场景分别创建和管理。这样后面查看用量、定位问题、控制成本都会更清楚。
优先复制后台给出的配置片段
如果后台提供“使用密钥”或“一键接入”这类入口,优先从这里复制配置。它通常已经把变量名、模型示例和调用入口整理好,比凭记忆手写更稳。
根据工具类型选择接入方式
Claude Code、Codex、SDK、命令行脚本和自建工具需要的配置形式可能不同。不要把一个工具的配置片段直接拿去填另一个工具。先确认当前工具需要的是环境变量、配置文件,还是代码里的参数。
使用密钥弹窗:按工具类型复制配置片段,减少手动填写错误
5、从一份样例跑通到批量复用的操作步骤
下面给一条适合新手照着做的流程。重点不是一次性做得很炫,而是让每一步都能检查、能回退、能复用。
第一步:准备一份真实资料
先选择一份你真的要处理的材料。可以是一份客户需求、一个产品表格、一组聊天记录、一份门店运营资料或一个项目文档。真实资料会更快暴露流程问题。
第二步:让 Claude 生成第一版结构
把资料交给 Claude,让它先做内容理解:提炼目标、归类信息、指出缺失项,并生成第一版结构。你要重点检查它有没有编造事实、有没有漏掉关键限制。
第三步:让 Codex 整理成固定格式
把确认后的结构交给 Codex,让它整理成表格、Markdown、JSON 或脚本输入。这里的目标是让结果可复制、可批量处理,而不是只生成一段漂亮文字。
第四步:接入后台配置并跑最小请求
如果需要让本地工具调用模型,先打开后台的密钥和一键接入入口,把配置复制到正确位置。第一次只跑一个很小的请求,确认能拿到稳定输出,再扩大任务范围。
一键接入页面:对照后台配置,把模型调用接入 Codex 或自己的自动化工具
第五步:记录可复用模板
把这次用到的提示词、字段模板、检查清单和配置方式保存下来。下一次处理同类任务时,只需要替换资料,不必重新摸索整个流程。
6、发布、交付或团队使用前怎么做质量检查
AI 参与流程后,最容易被忽视的是质量检查。看起来已经生成了很多内容,但只要关键事实错了、文件漏了、字段对不上,最后还是会返工。
检查内容是否能被业务直接使用
重点检查这些点:话术是否像真人表达、用户标签是否过细、转化动作是否过于生硬、复盘指标是否能落到表格。不要只看字数和格式,真正重要的是结果能不能进入下一步工作。
检查后台用量和任务归属
如果团队多人共用模型能力,建议定期查看用量记录。不同项目、不同任务最好能区分开,避免后面不知道是谁在调用、哪类任务消耗最高。
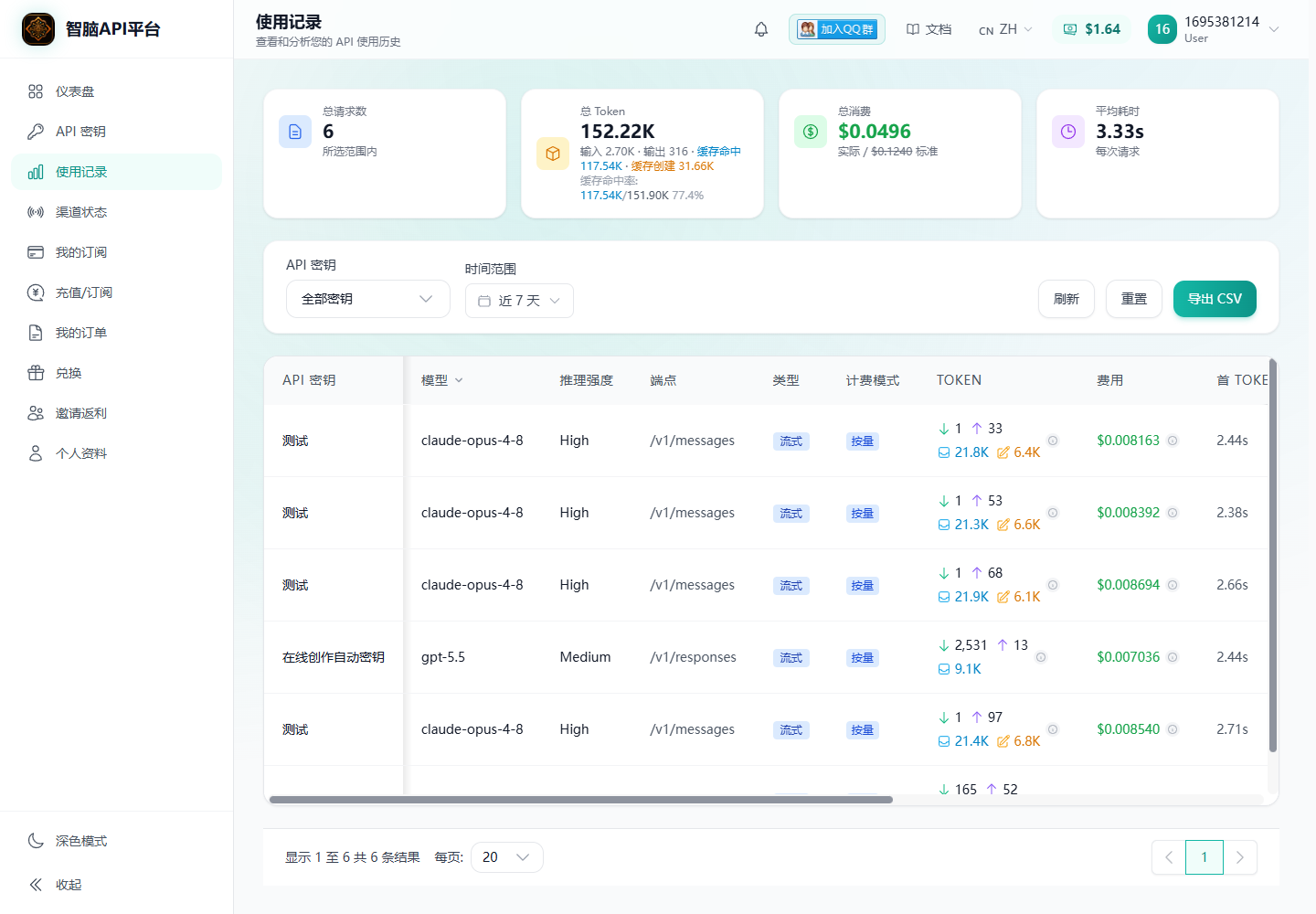
用量记录页面:通过调用记录复盘任务成本和使用情况,方便后续优化
检查是否适合批量放大
当一份样例跑通后,再判断是否适合批量处理。适合放大的流程通常具备三个特点:输入格式相对稳定、输出字段固定、人工审核点清楚。只要这三点还不稳定,就先不要急着全量自动化。
建立团队可复用的版本记录
如果这套流程会给团队长期使用,建议把每次调整都记录下来:这次改了哪个提示词、替换了哪个模型、调整了哪些字段、哪些结果被人工退回。很多自动化流程真正变稳定,不是因为第一版提示词写得完美,而是因为每次使用后都能沉淀问题。下次再处理同类任务时,团队不需要重新争论流程,只要沿用已经验证过的模板,再根据新资料做小范围调整。
给新手保留一条手动兜底路径
再成熟的流程也不要完全取消手动兜底。比如保留原始资料、保留中间草稿、保留人工确认清单,出现不确定结果时可以退回上一步。这样做看起来多了一点步骤,但能避免因为一次错误输出影响整批内容。尤其在私域社群运营这种会被团队或客户继续使用的场景里,稳定比炫技更重要。
最后总结一下:在私域社群运营里,Claude 更适合处理理解、归纳和表达,Codex 更适合处理文件、表格、脚本和批量检查。先跑通一份真实样例,再保存模板逐步复用,会比一开始追求全自动更稳。教程文档参考:https://my.feishu.cn/wiki/NIgLwuuj1ibzJIkLGM0cgVNinzg

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)