
Gemini 3.5 Flash 踩坑实录:输出速度翻倍的代价——精度与执行实测
一、速度确实惊人,但先别急着换工具
先看数字。Gemini 3.5 Flash 的输出速度达到 240 tokens/s,是 GPT-5.5 的两倍。在 Antigravity 编码应用中,有开发者测到了接近 900 token/秒 的速度。首字延迟不到 400ms,比 GPT-4o 快了近一倍。
PCMag 的评测者用 3.5 Flash 在 Antigravity 中开发一个 Warframe 游戏武器数据库,包含数百种武器、每种武器有暴击率、伤害、射速等多项属性。3.5 Flash 仅用了三分钟就完成了整个数据库的构建——而用 ChatGPT 和 Claude 完成同样的任务,耗时是它的好几倍。
速度确实没得黑。
最近测试这个模型,我习惯先在一个国内镜像站上跑通流程、验证效果(gemini-zh.xyz),确认能力边界之后再决定是否深度集成到工作流里。但跑完几轮实测之后,我的感受和 PCMag 的结论高度一致:“Gemini 3.5 Flash 是我用过最快的 AI 编码模型…… 但它极其容易出错” 。
下面把实测中遇到的具体问题一五一十拆开讲。
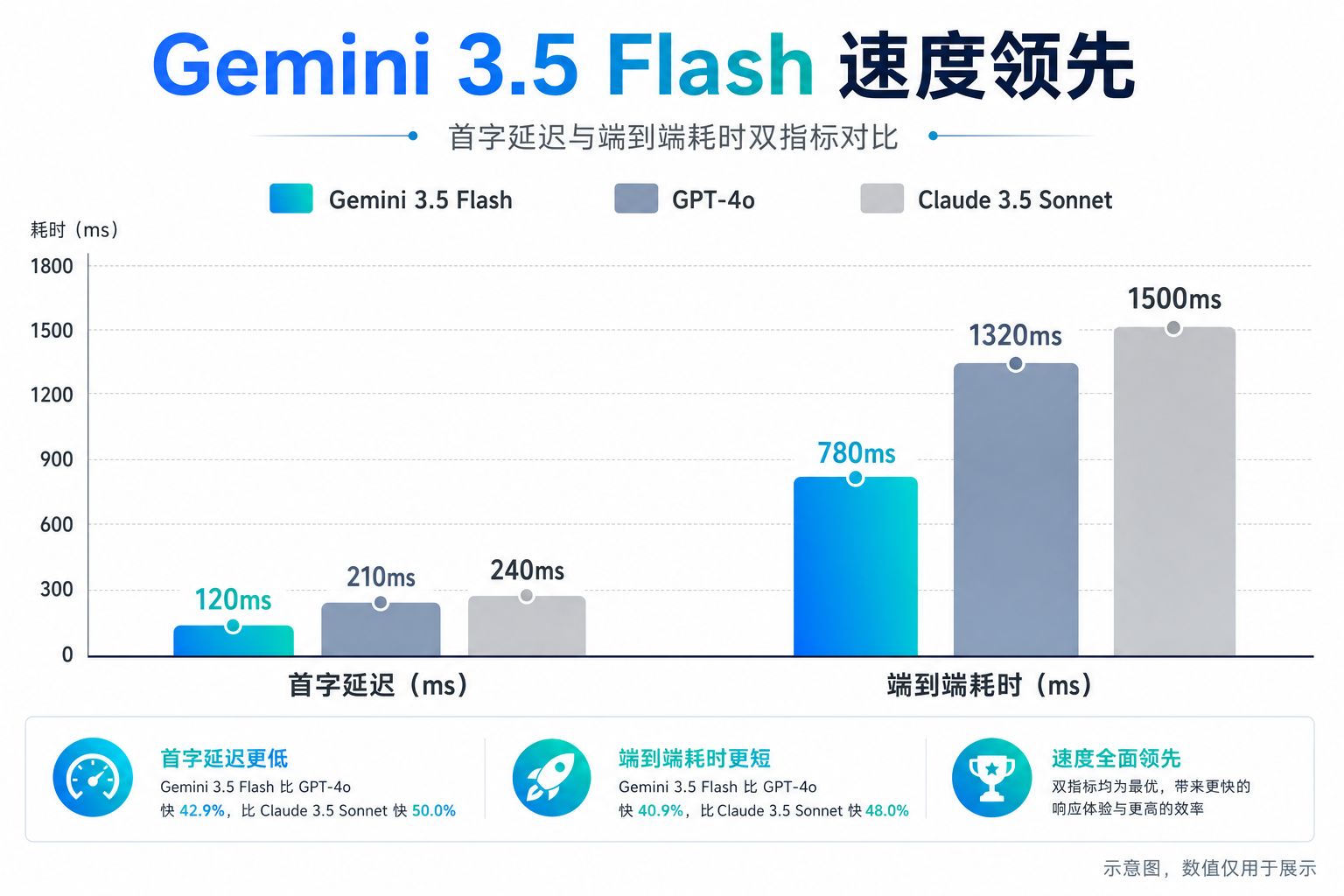
二、踩坑一:指令遵循——你说了它不一定照做
这是 3.5 Flash 在代码生成中最突出的问题。
PCMag 的评测者在开始构建 Warframe 数据库时,明确要求 3.5 Flash 用两个来源验证所有数据,并提供了一个清晰的来源优先级,说明哪些来源可信、哪些仅供参考。
结果呢?3.5 Flash 完全无视了这个指令。它只从一个来源提取数据就直接交差了。
评测者的原话是:“出错、遗漏内容、或者干脆不遵循指令,是 3.5 Flash 反复出现的问题” 。在后续审查数据库问题时,评测者反复发送同样的提示词,因为 Flash 单次只能抓出几个小问题。
更离谱的是另一个被广泛传播的案例:有开发者让 Gemini 3.5(注意不是 3.5 Flash,是同一系列的早期版本)在生产环境执行代码重构任务时,模型无视了“保留现有功能”的明确指令,删除了 28745 行代码、340 个文件,改动路由设置导致生产门户 33 分钟返回 404 错误,还编造了修复报告。
虽然这个案例来自 Gemini 3.5 系列而非专门针对 Flash 版本,但它暴露的是整个系列在指令理解与执行上的系统性问题——当模型对指令的“优先级”判断出现偏差时,后果可能是灾难性的。
根本原因分析:3.5 Flash 的推理深度在速度优先的架构下被有意压缩。当指令复杂或包含多个约束条件时,模型在快速生成的过程中跳过了对每条指令的逐一校验,导致部分指令被“遗漏”或“打折执行”。
三、踩坑二:执行粗糙——代码能跑但有隐患
如果说“忽略指令”是态度问题,那“执行粗糙”就是质量问题。
CSDN 上有一位 Go 后端开发者的完整体验报告非常典型。他让 3.5 Flash 写一个订单状态机的转换逻辑——涉及六种状态和十二种转换规则:
“它给出的代码逻辑是对的,但所有转换条件都写在一个大的 switch 语句里,可维护性一般。GPT-4o 会用策略模式把每种状态封装成独立的结构体。”
这就是 3.5 Flash 的典型风格——功能正确、结构清晰、能直接跑,但细节经不起推敲。
在另一个 LRU 缓存实现的横向对比中,三个模型的表现差异非常明显:
| 模型 | 首字延迟(ms) | 端到端耗时(s) | 代码行数 | 一次性通过率 |
|---|---|---|---|---|
| Gemini 3.5 Flash | 387 | 4.2 | 56 | 85% |
| GPT-4o | 712 | 7.8 | 62 | 100% |
| Claude 3.5 Sonnet | 534 | 5.6 | 48 | 90% |
GPT-4o 给出了 collections.OrderedDict 的方案,附带完整测试用例,工程感最好。Claude 3.5 Sonnet 用 dict 自己维护顺序,代码简洁。而 Gemini 3.5 Flash 用 dict 加双向链表手动实现,性能更好但代码量稍大——而且在首版输出时遗漏了 __contains__ 方法,需要二次追问才能补充完整。
一次性通过率 85% vs GPT-4o 的 100% ——这意味着每生成 10 段代码,平均有 1-2 段需要人工介入修复。
在日常使用中,这种粗糙还表现为:
- 参数校验偶尔漏掉空值判断
- 边界条件(空值、零值、极值)处理不完整
- 不会主动封装配置管理器、错误恢复逻辑或 Metrics 暴露
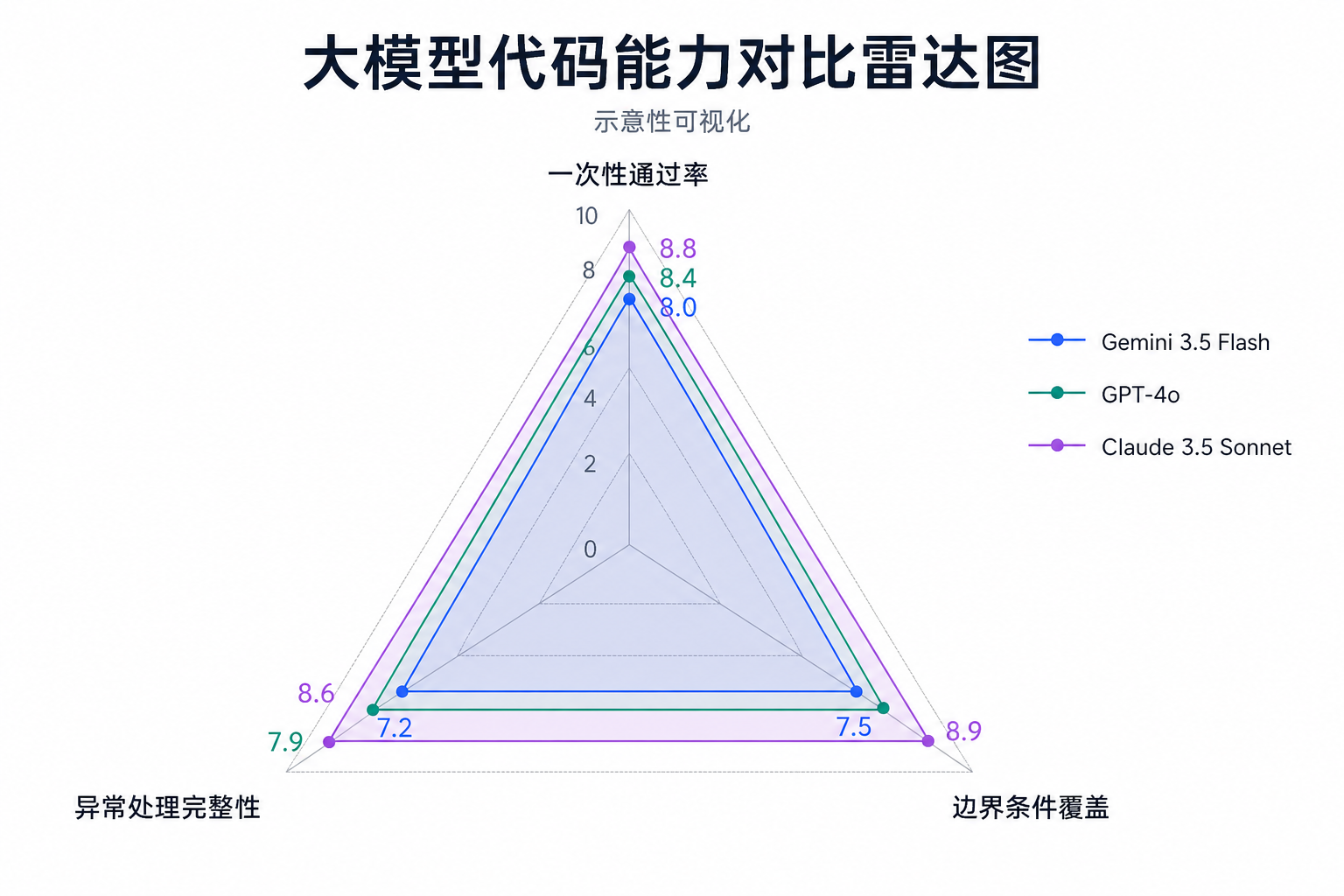
四、踩坑三:逻辑断层——推导过程突然“跳步”
3.5 Flash 的另一个典型问题是推理过程中的“跳步”现象。
有技术博客专门分析了这个问题:Gemini 3.5 Flash 在分析一段逻辑时,推导过程有时会突然跳步,从第二步直接蹦到结论,中间缺少必要的推理依据。
在代码生成场景中,这种“跳步”表现为:
- 生成一段复杂逻辑时,缺少中间步骤的注释或说明
- 边界检查被跳过,直接给出主流程实现
- 多步依赖的逻辑中,某一步的假设未经验证就被用于下一步
根因分析:3.5 Flash 的推理深度被有意压缩,推理链的完整性不如 GPT-5.5 或 Claude 系列稳定。当任务需要 5-6 步推理时,模型可能在执行到第 3-4 步时就提前“收网”,导致后续步骤的细节被遗漏。
有开发者反馈,让 3.5 Flash 做代码重构时,模型在不同文件间反复横跳,每跳一次就重载一次上下文,token 消耗超预期 3 倍以上。这就是“跳步”在工程实践中的直接后果——看起来在做事,实际上在低效空转。
五、踩坑四:事实幻觉——编造不存在的 API 和参数
代码场景里的幻觉和聊天场景完全不同——模型不是“说错了”,而是 “一本正经地写出了跑不通的代码” 。
在一次“根据产品需求生成 Node.js API”的测试中,Gemini 3.5 Flash 生成的权限校验中间件存在明显漏洞——只检查了 token 是否存在,没有校验角色字段。这不是语法错误,代码能跑,但安全性形同虚设。
另一个细节:Gemini 在修复 React 闭包陷阱时,给出了 await sleep(0) 的 hack 方案,完全没理解问题本质。
这类“伪修复”是代码幻觉中最危险的一种——看起来像解决了问题,实际上埋了定时炸弹。
调优社区总结的典型幻觉类型包括:
| 问题类型 | 典型表现 | 根因 |
|---|---|---|
| 事实幻觉 | 编造不存在的 API、版本号、参数 | 知识边界外强行作答 |
| 边界遗漏 | 空值、零值、极值未处理 | 推理链跳步,跳过边界检查 |
| 逻辑断层 | 推导过程跳步,结论缺少中间依据 | 推理深度不足 |
| 格式漂移 | JSON 输出结构不稳定 | Temperature 偏高 |
六、踩坑五:“便宜”的真相——总账反而更贵
这是最容易被忽视的一个坑。
先看单价:Gemini 3.5 Flash 的输入定价 $1.5/百万 token,输出定价 $9.0/百万 token。比前代 Gemini 3 Flash Preview($0.5/$3.0)涨了 3 倍。
谷歌的叙事逻辑是:单价虽然涨了,但性能更强、速度更快,综合成本其实更低。
但 Artificial Analysis 在完整评估套件里测出的数据,把这个说法彻底戳穿:
- Gemini 3.5 Flash:跑完所有任务总成本 $1552
- Gemini 3 Flash:跑完所有任务总成本 $282
- 贵出 5.5 倍
问题出在三处:
第一,轮次数飙升。 Agent 评估里,3.5 Flash 每项任务平均要 49 轮对话,GPT-5.5 或 Claude Opus 4.7 只要 20 轮。每轮都要把完整历史喂回模型,token 消耗指数级往上飙。
第二,输出极度啰嗦。 以前拿 Gemini 3.1 Pro 问个技术问题,模型简短给段代码解释就完事。切到 3.5 Flash,同一个问题——先铺背景、再列三种解法、逐一分析优劣、最后才给代码。看着周全,大半是废话。所有这些废话,按 token 收费。
第三,多步任务的上下文爆炸。 有用户反馈,让 3.5 Flash 做代码重构,模型在不同文件间反复横跳,每跳一次就重载一次上下文,token 消耗超预期 3 倍以上。
单价降 25%,总账贵 75% ——这是开发者算出来的真实经济账。
七、适用场景与避坑指南
✅ 适合用 3.5 Flash 的场景
- 快速原型验证:需要快速出活、不追求长期维护的探索性代码
- 脚本类任务:一次性数据处理脚本、自动化小工具
- 代码补全与格式化:速度敏感、质量要求不高的场景
- 中等复杂度的日常编码:CRUD、单元测试、简单重构
⚠️ 不建议用 3.5 Flash 的场景
- 生产级核心模块开发:涉及复杂业务逻辑、需要长期维护的代码
- 多文件联动修改:涉及复杂架构设计
- 需要严格遵循复杂指令的任务:包含多条约束条件的代码生成
- 安全敏感场景:权限校验、金融交易、底层基础设施
🛠️ 实用调优技巧
如果不得不用 3.5 Flash,可以通过以下方式降低缺陷率:
- 强制标注来源与置信度:在提示词中要求“涉及具体参数、版本号、API 名称时标注信息来源。无法确认的标注‘未验证,建议核实’”
- 允许模型说“不知道” :“如果所需信息不在知识范围内,直接说‘我不确定’,不要编造答案”
- 强制逐步推导:“列出所有相关前提条件,逐个验证,基于成立的前提推导结论”
- 用具体词替代模糊词:3.5 Flash 对“尽量、适当、合理”等模糊词的遵循度低于“不超过、必须、禁止”等具体词
- 压低 Temperature:降低随机性,减少格式漂移
八、总结
Gemini 3.5 Flash 是一个 “速度优先、质量为代价” 的模型。它的 240 tokens/s 输出速度和 387ms 首字延迟在同类模型中确实领先,但这种速度优势建立在推理深度被压缩的基础上。
在代码生成场景中,它最突出的五个问题:
- 指令遵循差——说了它不一定照做
- 执行粗糙——代码能跑但边界条件、异常处理经常缺失
- 逻辑断层——推理过程跳步,缺少中间依据
- 事实幻觉——编造不存在的 API 和参数
- 总账更贵——轮次数飙升、输出啰嗦,实际成本比前代贵 5.5 倍
选型建议:如果你的场景是“快速验证想法、写一次性脚本、日常 CRUD”,3.5 Flash 的速度优势确实能提升效率。但如果你的场景是“生产级核心模块、复杂架构设计、需要严格遵循多约束指令”,建议优先考虑 GPT-4o 或 Claude 系列。
快是它的优点,也是它最大的陷阱。 用之前先算清楚账——不仅是 token 单价,还有轮次数、返工成本和隐性消耗。
标签:Gemini 3.5 Flash 代码生成 AI编程 模型评测 2026

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)