
我做了全球首个会「自进化」「自微调」的 Code Agent :momo Code(V1.0.0)[特殊字符]
我做了全球首个会「自进化」「自微调」的 Code Agent :momo Code(V1.0.0)🤔
我做了全球首个 完全开源免费、会「自进化」「自微调」的 Code Agent
我把它命名为 MOMO CODE 。
" MOMO 代表了 每一个身处 AI 时代,心怀热爱、坚持微光,想要躬身创造价值的普通人。"
官网:https://momozi.cc
开源地址:https://github.com/momozi1996/momo-code
MOMO CODE:不只是代码Agent,它会「自进化」+ 「自微调」,它会自己变强。
一、为什么 Code Agent 需要"进化"?
过去半年,我高频使用了市面上许多 Code Agent 工具产品
——Claude Code、Codex、Hermes Agent、Kimi code、Cursor……
它们都很强,尤其是CC 和 Codex, 但有一个共同的问题:
模型是静态的。你教它一次,它记住了;你纠正它十次,它可能还会犯第十一次。
就像一个从不记笔记的学生。每次对话都是从零开始,昨天的经验今天全忘。
🤔 我一直在想:如果 Code Agent 能像人一样——从每次交互中学习、积累经验、持续进化——会怎样?
更进一步,每次的交互、每一轮对话,如果能吸纳为模型自我微调的养料——又会怎样?
于是我做了 MOMO CODE, 会「自进化」+ 「自微调」。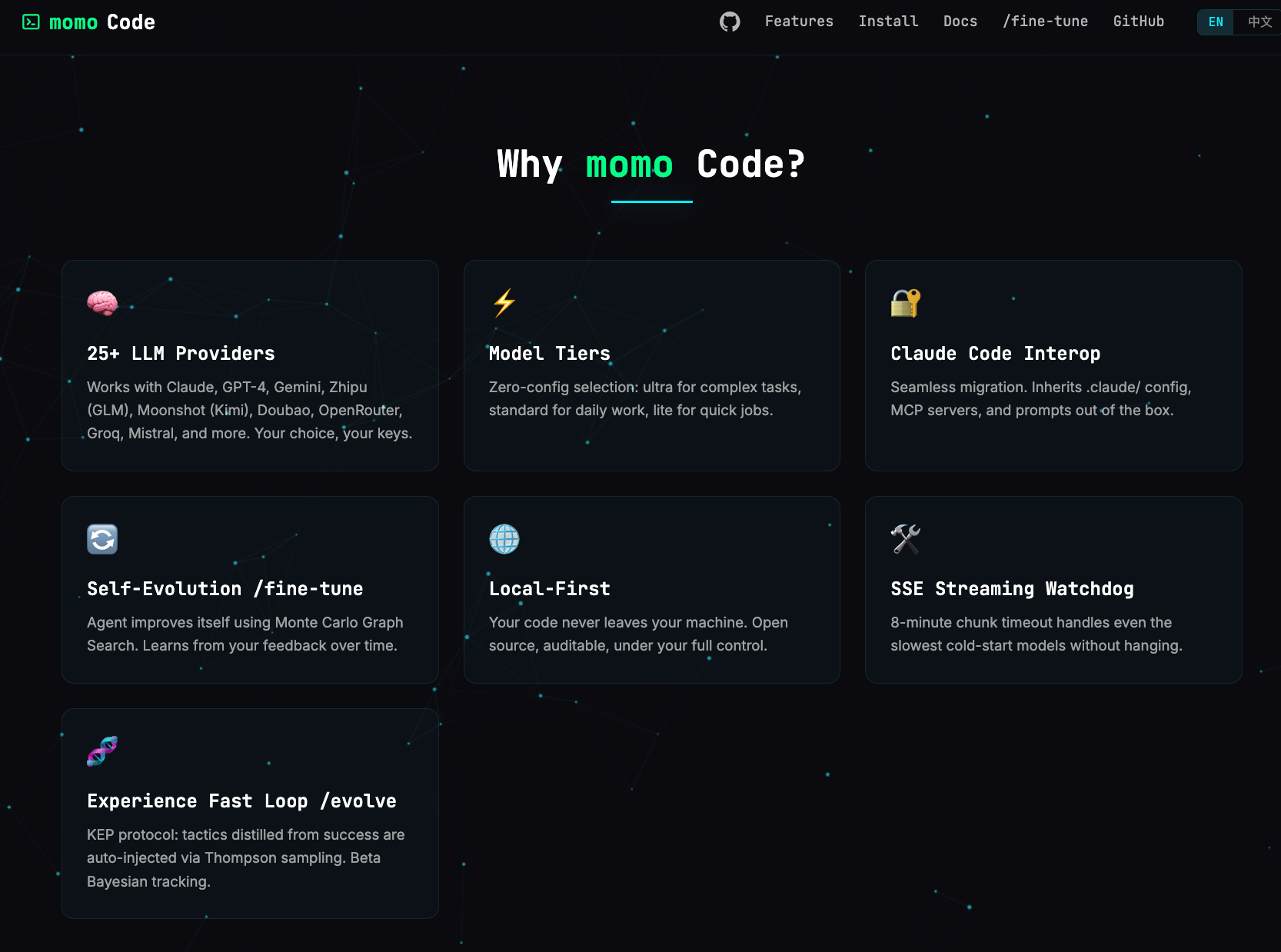
二、MOMO CODE 是什么?
一句话:MOMO CODE 是一个完全开源的、会自进化、会自微调的 AI 编程Agent 产品。
🔥 MOMO CODE 🔥 V1.0.0版本
它基于Opencode框架而衍生,创新增加了 【自进化】 /evolve 和 【自微调】/fine-tune 模块
- 支持 25+ 大模型(DeepSeek、智谱 GLM、Moonshot Kimi、豆包、MiniMax、Claude、GPT-4、Gemini、……)。
- 支持自定义 OpenAI协议类 API,接入任意模型。
- 核心差异:每次会话后自动积累经验,通过 /evolve 快环和 /fine-tune 慢环持续自我进化。
开源地址:https://github.com/momozi1996/momo-code
官网:https://momozi.cc
三、【自进化+自微调】双速进化:让它真正"越用越聪明"
这是 MOMO CODE 最核心的设计。
我叫它 “Two-Speed Evolution”——双速进化。
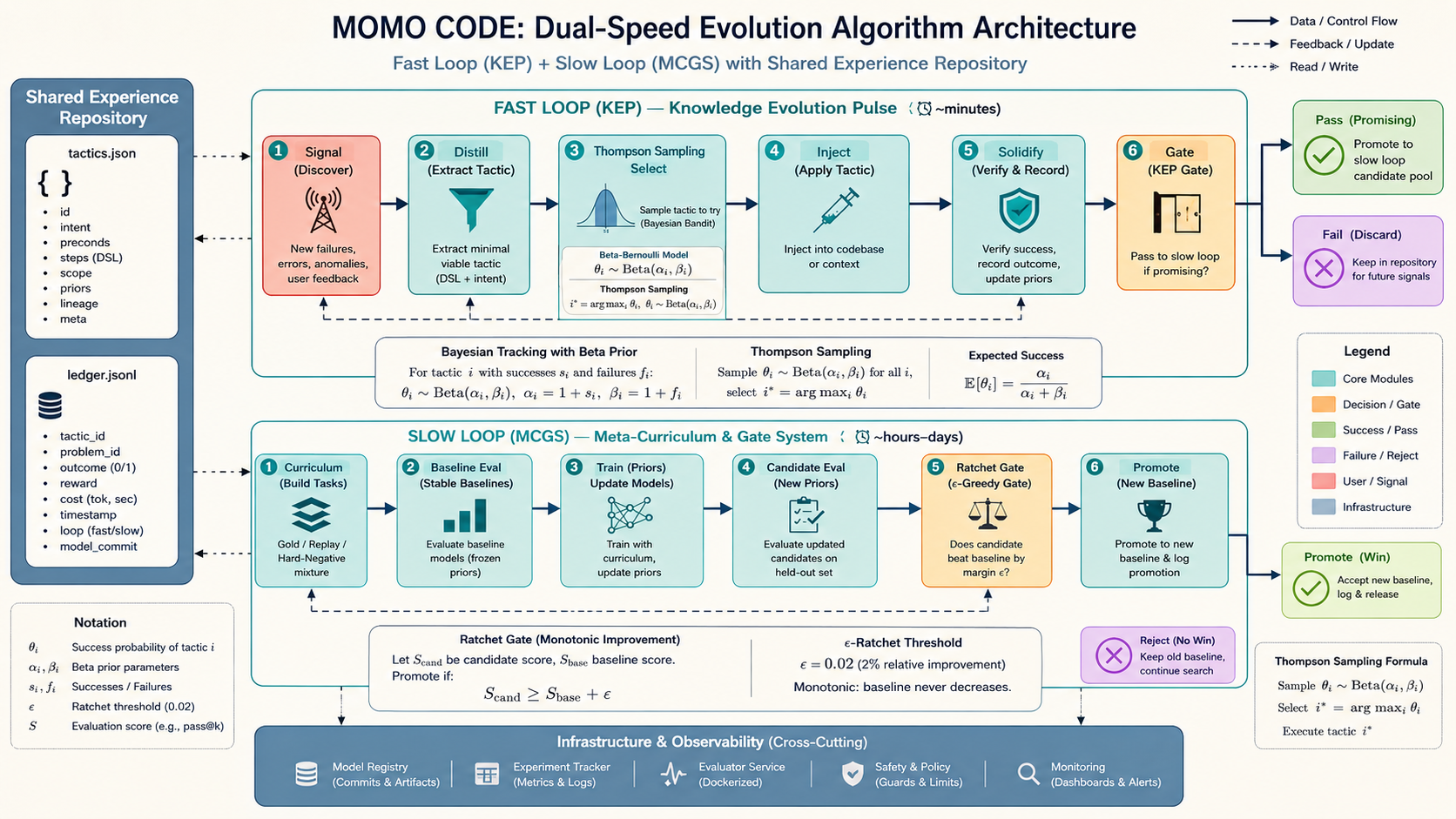
灵感来自生物学:细菌有快速适应(应激反应)和长期进化(自然选择),两个时间尺度并行。
我也给 MOMO CODE 设计了两条进化回路:
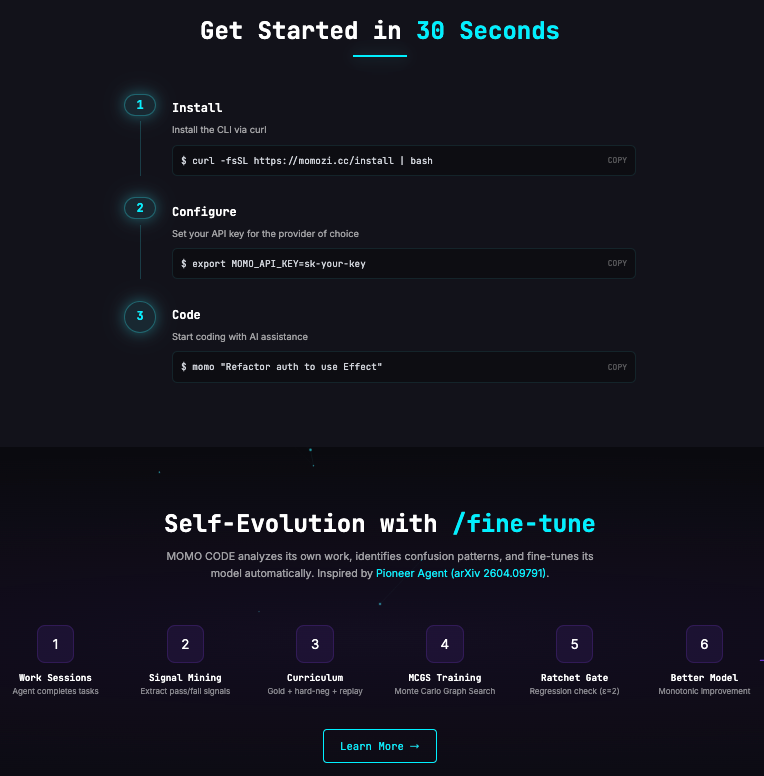
01 🔥 快环 /evolve —— 【自进化】秒级经验积累
每次你完成一个任务,MOMO CODE 会观察整个过程中的信号:
- 测试通过了?✅ 记一笔
- 编辑被你接受了?✅ 记一笔
- 编译报错了?❌ 记一笔
- 你手动纠正了它?❌ 记一笔
当同一个模式出现 3 次以上(比如"bash 命令成功了"),系统会自动 提炼出一条经验策略(tactic)。
下次你做类似任务时,这些策略会通过 Thompson 采样(一种贝叶斯方法,兼顾"用已知最好的方法"和"给新方法尝试机会")自动注入到系统提示里。
打个比方:就像新手医生第一次做某种手术,失败了;第三次成功了,前辈就会提醒"下次注意这个步骤"。MOMO CODE 的 /evolve 就是这个"前辈",而且不需要人工干预。
02 🧬 慢环 /fine-tune ——【自微调】 周期性能力跃迁
快环解决的是"经验记忆"。慢环解决的是"能力升级"。
当积累的经验足够多时,/fine-tune 会触发一个 完整的训练管线:
课程合成(Curriculum)→ 基线评估(Baseline)→ 训练(Train)→ 候选评估(Candidate)→ 棘轮门控(Ratchet Gate)→ 晋升(Promote)
每一步都有严格的数学保证:
-课程合成:
默认驱动器是 Priors(贝叶斯先验更新),纯 CPU、秒级完成、不依赖任何外部系统。如果你需要真正的 LoRA 微调,也可以接入 PEFT/Transformers。
四、算法架构:Bayesian + Thompson + Ratchet
进化算法基于三个核心数学工具:
-
Beta(α, β) 贝叶斯追踪
每条策略维护一个 Beta 分布。α = 1 + wins,β = 1 + losses。胜率 = α / (α + β)。
这不是静态计数——每次有新数据,整个后验概率分布都会更新。 -
Thompson 采样
选择策略时,从每条策略的 Beta 分布中随机采样一个值,按采样值排序选取前 6 条注入。
这样做的好处是:高胜率策略通常会被选中,但新策略(数据少、方差大)也有机会被"抽中"尝试。自然平衡了"利用"和"探索"。 -
Ratchet Gate(棘轮门控)
PASS iff candidate.passAt1 >= baseline.passAt1 - 0.02 AND #regressions == 0
即:新模型必须至少和旧模型一样好(允许 2pp 噪声),且不能有任何倒退。这个名字来源于机械棘轮——只能单向转动。
五、系统架构:四层 + 25+ 模型
MOMO CODE 采用四层架构:
四层架构
六、一个完整的进化 Demo
你可以 5 分钟跑完整个进化流程:
终端里实际运行效果:
(1)安装: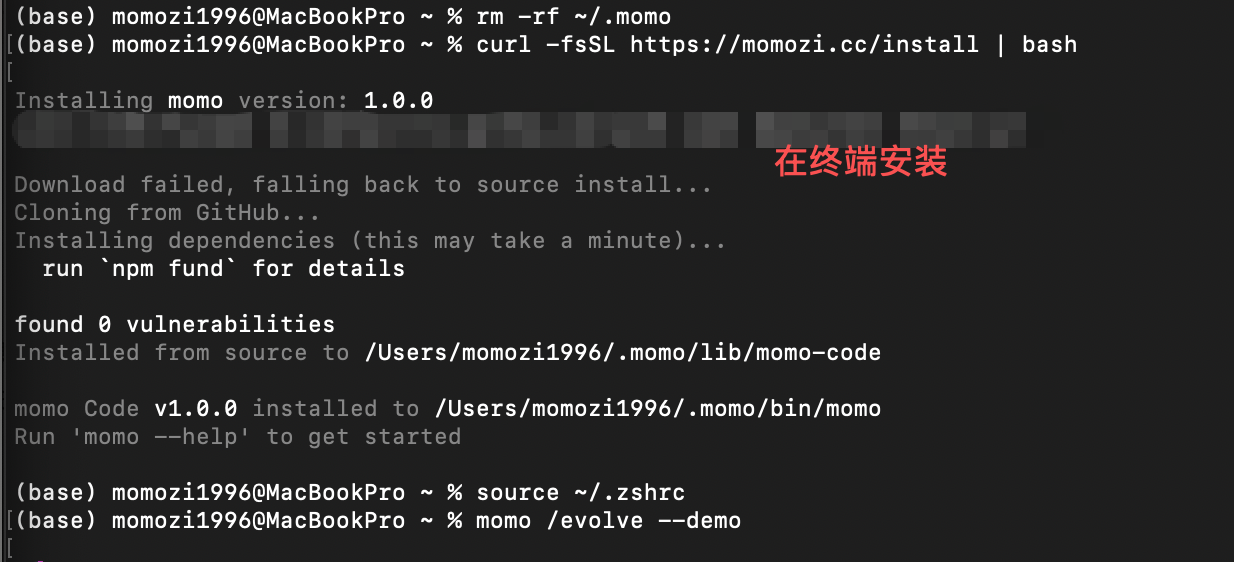
(2)🔥 快环 /evolve —— 【自进化】秒级经验积累
% momo /evolve 相关
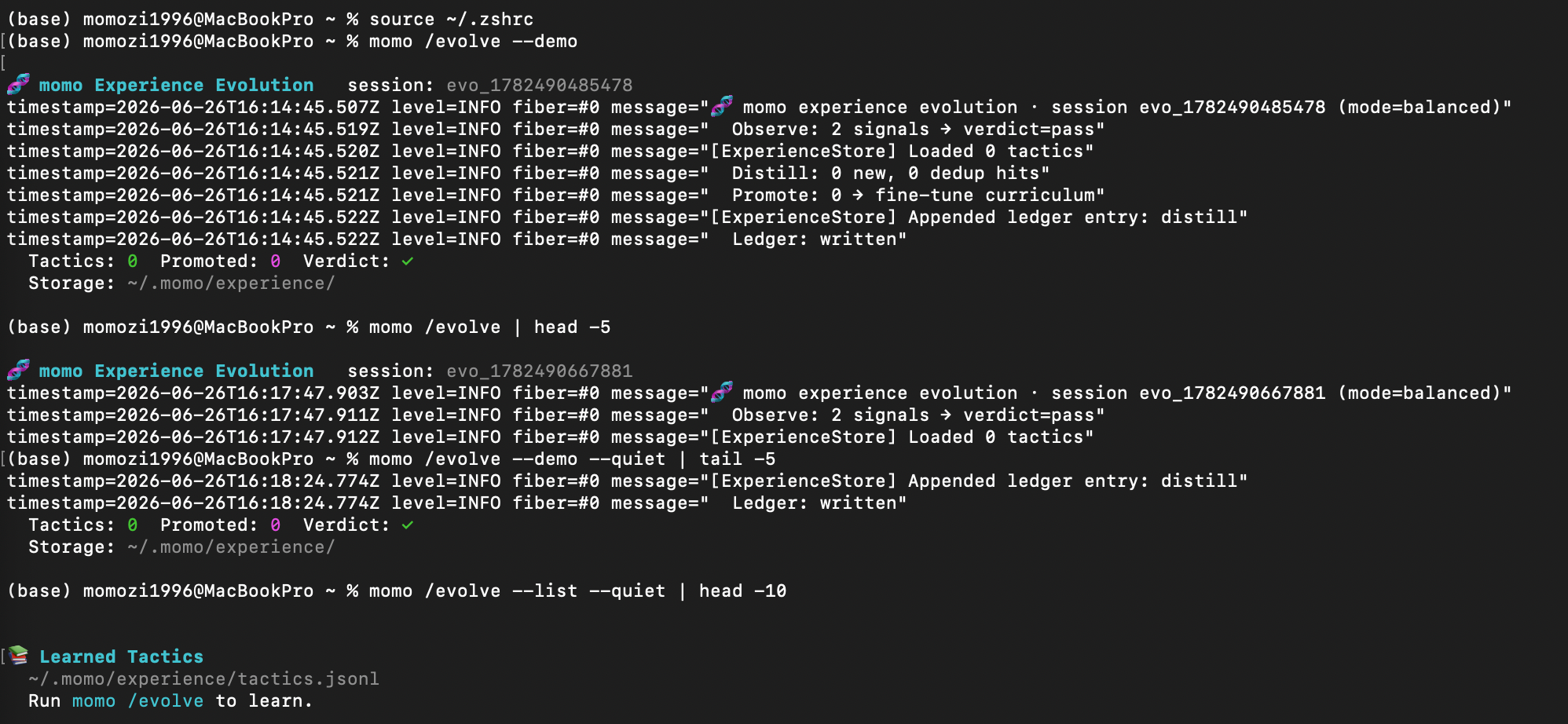
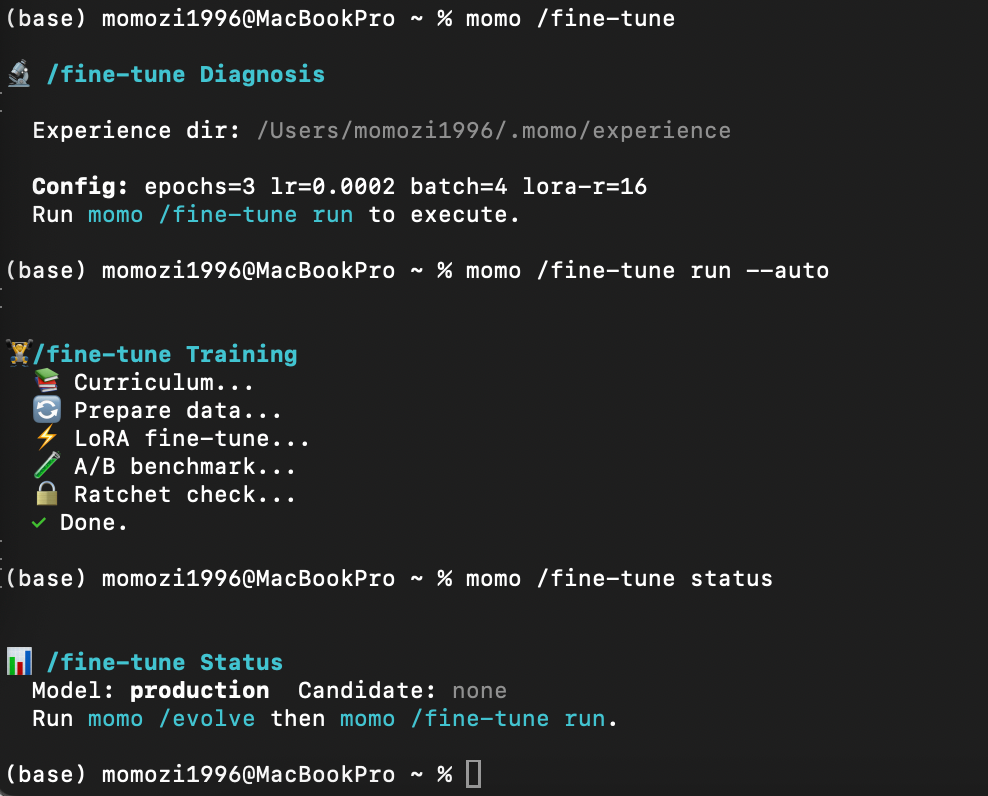
(3)🧬 慢环 /fine-tune ——【自微调】 周期性能力跃迁
% momo /fine-tune
七、为什么是"首个"?
实际上,MOMO CODE 不是世界上第一个 Code Agent。
但它是:
首个将"经验快环(KEP)+ 训练慢环(MCGS)"作为核心架构内置的开源 Code Agent。
其他工具的进化要么是手动 prompt engineering(人力),要么是端到端微调(贵且慢)。
我做的是 两速并行 ——秒级的经验注入 + 周期性的能力跃迁,且默认完全免费。
写在最后
如果你在用它,遇到 bug 或有想法,欢迎来 GitHub 开 Issue。
我们一起把它做得更强。
作者:MOMOZI
架构图、算法详解、完整文档见 GitHub 仓库

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)