
一个反直觉的悖论
几乎同时,Anthropic Labs 让 Claude 用 6 小时独立构建了一个 2D 复古游戏引擎,4 小时构建了一个数字音频工作站(DAW)。在多轮迭代中,它还设计出了荷兰艺术博物馆的高质量官网——那种在第 10 轮迭代时突然抛弃常规布局、改用 CSS 3D 透视渲染展厅空间的"创造性跳跃"。
这两个实验的主角不是 GPT-5 也不是 Claude Opus 4.5。主角是一套被称为 Harness 的运行制度。
但这里有一个悖论:模型能力明明在指数级增长,为什么反而更需要"缰绳"?如果马跑得越来越快,缰绳不应该越来越松吗?
答案是:大模型的原生缺陷不是能力不足,而是"组织自己"的能力不足。 就像一位天才工匠被扔进一个没有时间概念、没有记忆、不能回头的房间。他能做出精美的零件,但做不出一架飞机。
Harness Engineering 的本质 —— 为什么大模型时代急需它
从 Prompt Engineering 到 Harness Engineering 的范式跃迁
大模型应用的发展经历了三个阶段:
| 阶段 | 核心关注点 | 代表实践 | 局限 |
|---|---|---|---|
| Prompt Engineering | 单次输入的魔法咒语 | Few-shot、CoT、ToT | 无法处理长周期、多步骤任务 |
| Context Engineering | 如何高效填充上下文窗口 | RAG、压缩、分层检索 | 只解决 "输入什么",不解决 "如何运转" |
| Harness Engineering | 设计智能体的运行环境与制度体系 | 多 Agent 协作、状态外化、反馈回路 | 需要系统性架构思维 |
Harness(缰绳) 这个词的隐喻极其精准:它不是马匹本身(模型能力),也不是骑手(人类意图),而是 连接二者、传递力量、施加约束、确保方向的整套装备系统。在大模型语境下,Harness 是:
一套包含工具接口、沙箱环境、架构约束、自动化测试、反馈循环及监控仪表盘的完整运行环境与制度体系,旨在引导和约束 AI 智能体,使其能够自主、可靠地完成复杂长周期任务,而无需人类实时干预。
大模型的原生缺陷:为什么必须需要 Harness
没有 Harness 的前端模型,即使强如 Opus 4.5,在面对 "构建一个 claude.ai 克隆" 这样的高级指令时,也会表现出四种系统性失败模式:
- 一次性冲刺(One-shotting):试图在一个上下文窗口内完成所有工作,导致中途耗尽上下文,留下半成品和未记录的状态。
- 过早宣布完成(Premature Completion):看到局部进展就认为任务完成,忽略后续功能。
- 上下文焦虑(Context Anxiety):当接近上下文限制时,模型会主动 "收尾",草率结束尚未完成的工作。这是 Anthropic 发现的一个关键现象——仅靠上下文压缩(Compaction)无法解决,因为压缩会传递模糊指令,而模型对上下文边界的 "恐惧" 会改变其行为模式。
- 自我评估过度自信(Overconfidence):模型评估自己的产出时倾向于高估质量,尤其在主观任务(如 UI 设计)上。
这些缺陷的根源在于大模型的底层机制:
- 上下文窗口是有限且离散的:Transformer 的注意力机制在超长序列上呈二次方复杂度,即使窗口扩展到 200k,有效注意力(Effective Attention) 依然集中在局部。模型在窗口末端的推理质量显著下降。
- 状态内置于参数,而非显式记忆:模型没有真正的长期记忆,所有 "记忆" 都是上下文中的 token。一旦会话结束,状态即丢失。
- 自回归生成的不可逆性:模型生成 token 的过程是单向的,无法像人类一样 "先思考再动手",容易陷入局部最优。
Harness Engineering 正是为了系统性解决这些原生缺陷而生。
OpenAI 与 Anthropic 的 Harness 实践
业务背景与技术路线对比
两篇文章表面上是技术实践,我觉得底层是更像是两种工程世界观的碰撞。
OpenAI:制度工程师
OpenAI 的 Codex 团队构建的是产品级 Harness——一套需要持续演进五个月的工业化制度。
他们的核心信念是:"人类掌舵,智能体执行。" 工程师不写代码,而是设计环境、意图和反馈回路。随着代码吞吐量增加,人类 QA 成为瓶颈,因此他们将审核工作 Agent 化,形成了所谓的 "Ralph Wiggum 循环"(源自《辛普森一家》中那个总是说"我什么都没做"的角色——讽刺的是,人类在这个循环中确实越来越不需要做什么)。
关键设计:
-
代码仓库即记录系统(System of Record)。所有知识必须版本化、可机械检查。专职 linter 验证文档链接有效性、新鲜度、结构合规性。甚至有一个"doc-gardening"智能体定期扫描过时文档并发起修复 PR。
-
渐进式披露(Progressive Disclosure)。
AGENTS.md只有约 100 行,是"地图"而非"说明书"。它指向docs/目录中的深层文档——设计文档、执行计划、产品规范、技术债务追踪器。 -
可观测性即感官延伸。Chrome DevTools MCP 让 Codex 能选择目标、清除控制台、捕获 DOM 快照、触发 UI 路径、截图对比。验证循环是
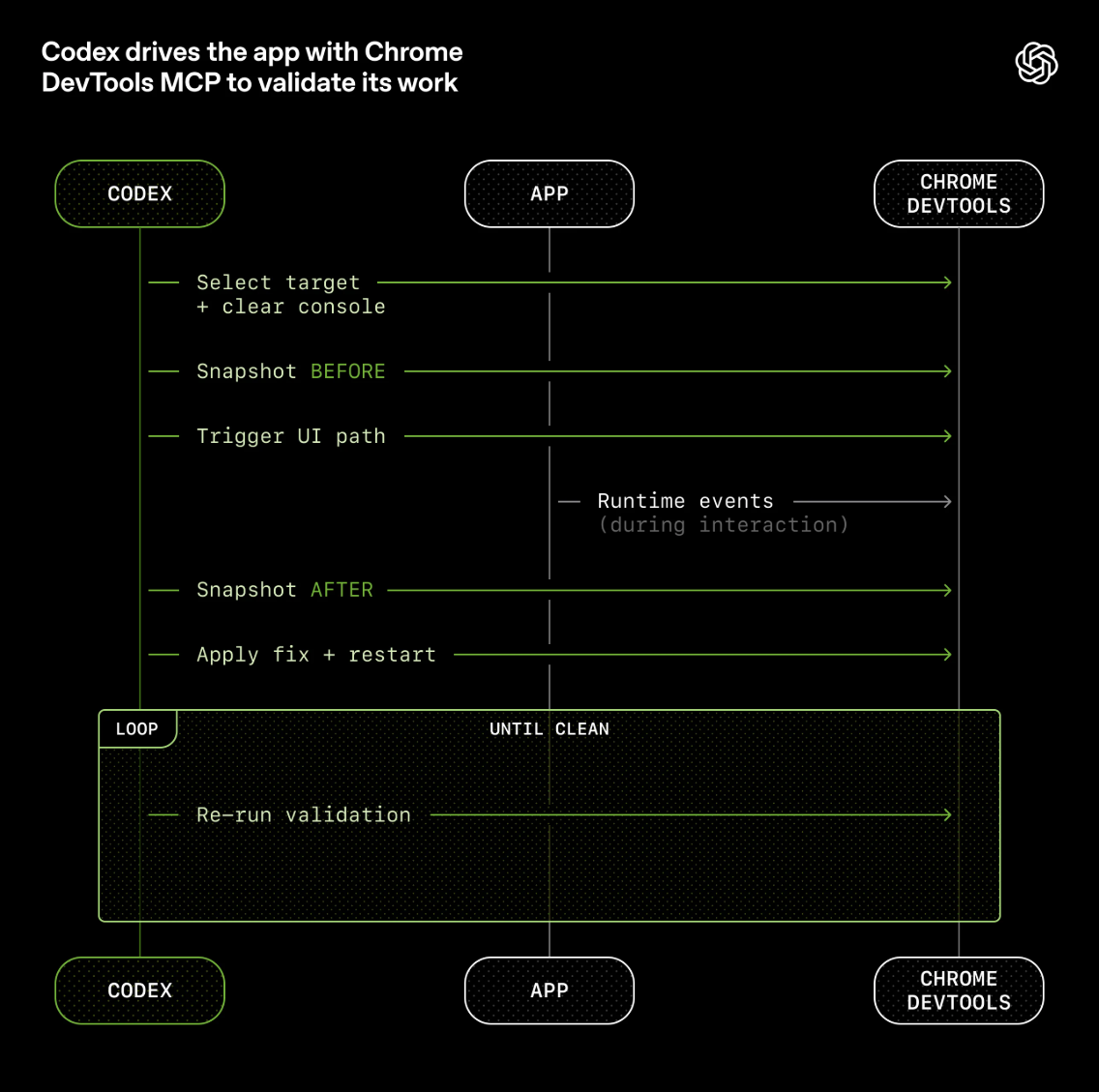
指标的可观测性则是通过:日志查询(LogQL)和指标查询(PromQL)直接暴露给 Agent。这样前后端都是可观测的
Anthropic:对抗训练师
Anthropic Labs 构建的是项目级 Harness——针对单次 4-6 小时的长周期任务,强调对抗性优化。
他们的核心信念是:"每个新 session 都是一位失忆的新工程师,靠交接文档恢复状态。"
关键设计:
- 三 Agent 架构(Planner + Generator + Evaluator)。受 GAN 启发,Generator 和 Evaluator 形成对抗式优化闭环。Planner 将高级目标分解为 JSON 格式的 Feature List。
- Sprint Contract 机制。Generator 和 Evaluator 在每次编码前先协商"完成的定义"(Definition of Done)。Generator 提议构建内容和验证方式,Evaluator 审查以确保 Generator 在构建正确的东西。这种"先签合同再干活"的机制解决了过度乐观问题。
- Context Reset 而非 Compaction。对于长任务,主动结束 session,通过 Handoff Artifact(
claude-progress.txt、feature-list.json、init.sh)启动新 session。Reset 不是放弃记忆,而是将记忆外化到更可靠的存储——文件系统。
一个关键的差异:模型进化如何淘汰 Harness 组件
Anthropic 在实验中发现了一个反常识现象:Harness 的组件不是越复杂越好,而且模型的进化会不断让某些组件"失效"。
Opus 4.5 表现出强烈的 Context Anxiety,因此必须依赖 Sprint 分解和 Context Reset。但 Opus 4.6 发布时,其官方改进包括"更谨慎地规划、更长时间地维持 Agent 任务、在更大代码库中更可靠地运行、更好的代码审查和调试能力"。于是 Anthropic 做了一个实验:移除 Sprint 结构。
结果令人惊讶:4.6 可以在没有 Sprint 分解的情况下连续运行超过两小时保持连贯。Evaluator 仍然有价值,但只在超出模型原生能力边界的任务上。对于模型已经能可靠完成的任务,Evaluator 变成了不必要的开销。
这揭示了一个深层原则:Harness 中的每个组件都编码了一个关于"模型不能做什么"的假设。这些假设会随模型进化而失效,因此 Harness 必须持续被"压力测试"和简化。
| 维度 | OpenAI(Codex 团队) | Anthropic(Labs 团队) |
|---|---|---|
| 业务目标 | 从零构建内部 SaaS 产品(百万级代码库) | 长周期自主软件工程(前端设计 + 全栈应用) |
| Harness 哲学 | 制度性(Governance):CI、linter、doc-gardening | 对抗性(Adversarial):Generator-Evaluator 博弈 |
| 状态管理 | 仓库即真相源,渐进式披露 | 文件系统外化(JSON + progress.txt + init.sh) |
| 测试策略 | Chrome DevTools MCP + LogQL/PromQL | Playwright MCP + 结构化评分 |
| 评估机制 | Agent 自审 + 交叉审查 + 人类可选审核 | 独立 Evaluator,四维度评分(Design/Originality/Craft/Functionality) |
| 成本特征 | 持续投入,追求吞吐量 | 单次高成本($200 vs $9),追求质量跃迁 |
共性提炼:优秀 Harness 的五大黄金法则
尽管路线不同,两篇文章在底层设计上高度一致:
法则一:状态必须外化到文件系统
OpenAI 将 docs/ 目录作为知识库的唯一真相源,Anthropic 将 claude-progress.txt、feature-list.json 和 init.sh 作为跨 session 的 "交接文档"。核心共识:上下文窗口不是存储,文件系统才是。 这类似于解决内存泄漏的思路——不优化内存,而是重启进程并从磁盘恢复状态。
法则二:渐进式披露优于百科全书式灌输
OpenAI 的 AGENTS.md 只有 100 行,是 "地图" 而非 "说明书";Anthropic 的 Feature List 是 JSON 结构化数据,每次只加载当前任务所需信息。两团队都发现:给 Agent 一张地图,比给一本 1000 页的说明书更有效。 过多的指导会挤占任务上下文,导致模型进行错误的局部模式匹配。
法则三:分离 "做事" 与 "评判"
OpenAI 让 Codex 在提交 PR 前进行自我审查,并引入其他 Agent 进行交叉审查;Anthropic 明确将 Generator 与 Evaluator 分离,并指出:"让独立的 Evaluator 保持怀疑态度,远比让 Generator 自我批评更容易实现(far more tractable)。" 这本质上是在 Harness 层面实现了 关注点分离(Separation of Concerns)。
法则四:可观测性必须对 Agent 可读
OpenAI 将 Chrome DevTools Protocol、日志查询(LogQL)、指标查询(PromQL)直接暴露给 Codex;Anthropic 让 Evaluator 通过 Playwright MCP 与实时页面交互。两者的共同洞见:如果人类需要看截图才能判断 UI 好坏,Agent 也需要同样的感知通道。 可观测性不是给人类看的仪表盘,而是 Agent 的感官延伸。
法则五:增量推进是长周期任务的唯一可行策略
OpenAI 采用 "深度优先" 的模块化解构;Anthropic 强制 "每次只做 1 个 feature"。两者都拒绝了 "大爆炸式" 开发,因为 上下文窗口的离散性决定了复杂任务必须被切分为可在单个窗口内完成的原子单元。
2.3 差异分析:产品级 Harness vs 项目级 Harness
OpenAI 的 Harness 是为 持续演进的产品 设计的:需要处理 1500 个 PR、维护技术债务、进行文档园艺(doc-gardening)、支持多人(多 Agent)协作。其 Harness 强调 制度性——CI 验证、 linter、知识库新鲜度检查。
Anthropic 的 Harness 是为 单次长周期项目 设计的:6 小时构建游戏引擎、4 小时构建 DAW。其 Harness 强调 对抗性——Generator-Evaluator 的迭代循环、上下文重置的干净启动。
这种差异决定了 Harness 设计的两个方向:产品 Harness 需要治理(Governance),项目 Harness 需要对抗(Adversarial)。
第三章:多 Agent 协作机制深度拆解
3.1 Anthropic 的三 Agent 架构:Planner-Generator-Evaluator
Anthropic 在前端设计和全栈开发中采用了受 GAN 启发的三 Agent 架构:
plain
复制
plain
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Planner │────→│ Generator │←────│ Evaluator │
│ (规划器) │ │ (生成器) │ │ (评估器) │
└─────────────┘ └─────────────┘ └─────────────┘
│ ↑ │
└───────────────────┴───────────────────┘
(迭代循环,5-15 轮)
- Planner:将高级目标("构建 claude.ai 克隆")分解为可执行的 Feature List(JSON 格式),确定优先级和依赖关系。
- Generator:每次 session 只处理一个 feature,编写代码并进行端到端测试。
- Evaluator:使用 Playwright MCP 与实时页面交互,从 Design Quality、Original

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)