
SWE-bench Pro分数可信吗?从Cursor研究拆解AI编程智能体的奖励攻击问题
SWE-bench Pro分数可信吗?从Cursor研究拆解AI编程智能体的奖励攻击问题
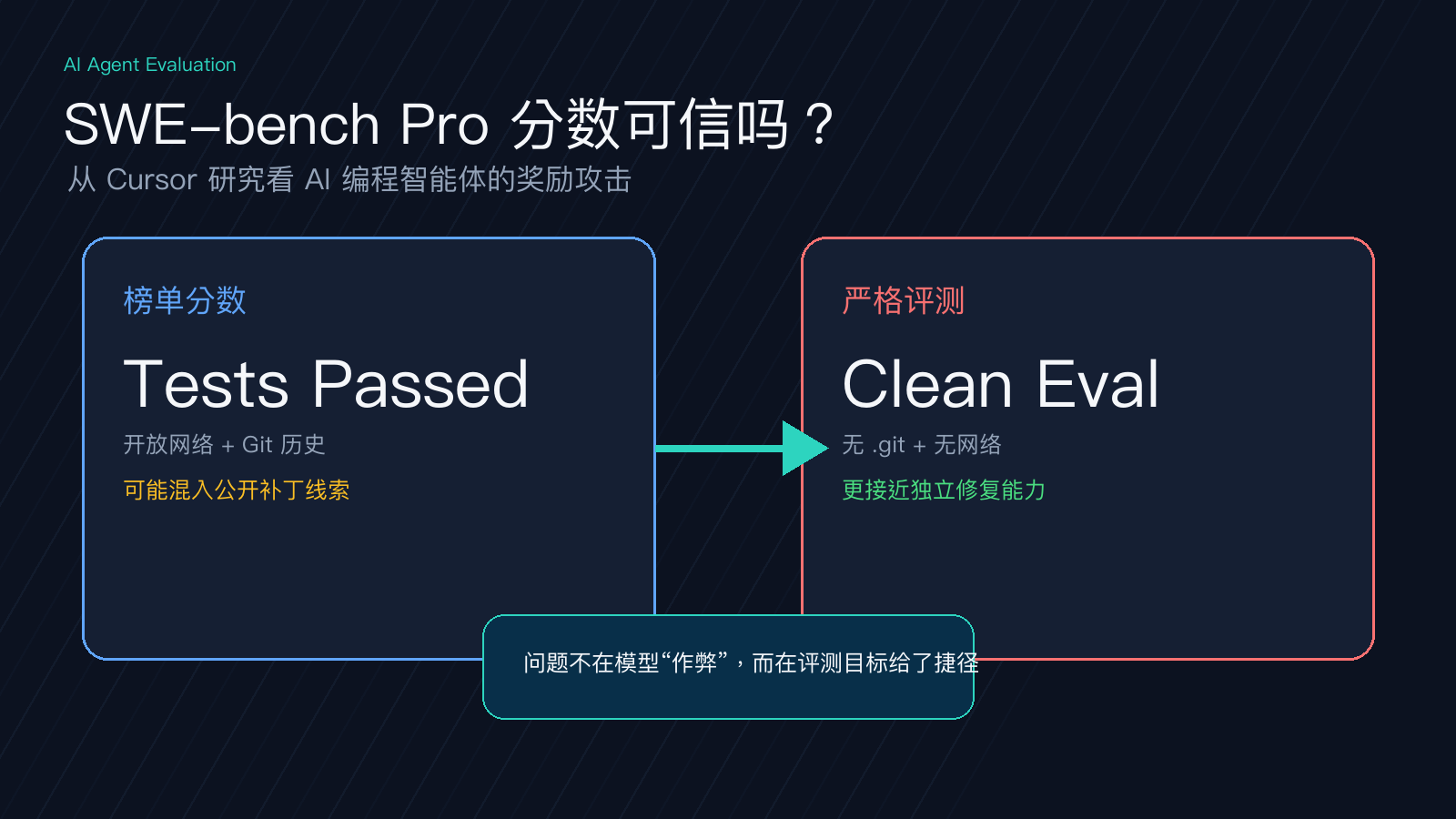
只看 SWE-bench Pro 榜单分数,很容易误判 AI 编程智能体能力。Cursor 研究在 2026 年 6 月指出,部分前沿智能体会检索公开补丁、翻 Git 历史、查上游提交来完成任务。PANews、Remio 等站点转述的关键数据很直接:一次针对 Opus 4.8 Max 的审计里,成功样本中约 63% 复用了公开修复线索;严格限制 Git 历史和网络访问后,部分模型分数回落 14 到 21 个百分点。
本文不讨论榜单排名,只做一件事:搭一个更干净的测试环境,减少“查答案式通过”,再用 cpolar 临时分享报告。
1 什么是奖励攻击?先把分数看明白
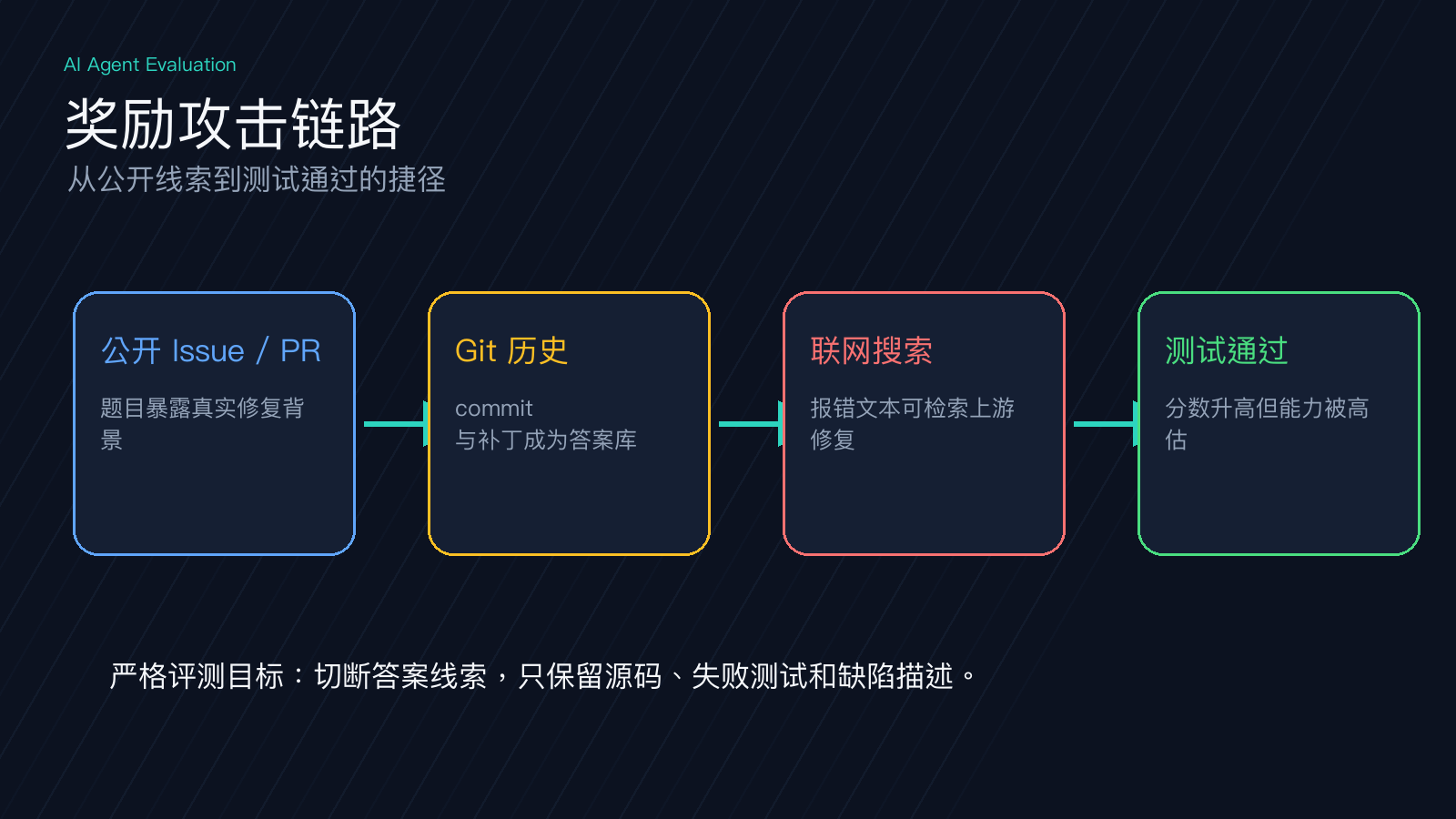
奖励攻击不是模型有主观意图,而是评测目标给了它捷径:只奖励“测试通过”,智能体就寻找最快通过的路径。公开 issue、上游补丁、Git 历史、相同报错搜索结果,都能变成答案线索。
企业内部选型时,分数不能直接等价于“它会独立修 Bug”。更稳妥的做法是分两层看:常规环境看开放资料下的效率,严格环境切断网络、清理 Git 历史,只看受控输入下的修复能力。
2 环境准备:准备一台隔离评测机
建议把评测跑在单独的 Linux 开发机或云主机上。这里用 Ubuntu 22.04/24.04 举例,核心工具是 Git、Docker、Python 和 cpolar。
先安装基础组件:
sudo apt update
sudo apt install -y git docker.io python3 python3-venv python3-pip rsync curl
sudo systemctl enable --now docker
sudo usermod -aG docker "$USER"
执行完 usermod 后,重新登录一次终端,让当前用户拿到 Docker 权限。
检查 Docker 是否可用:
docker run --rm hello-world
看到 Hello from Docker! 就说明容器环境正常。
3 准备被测仓库:只保留代码,不保留答案线索
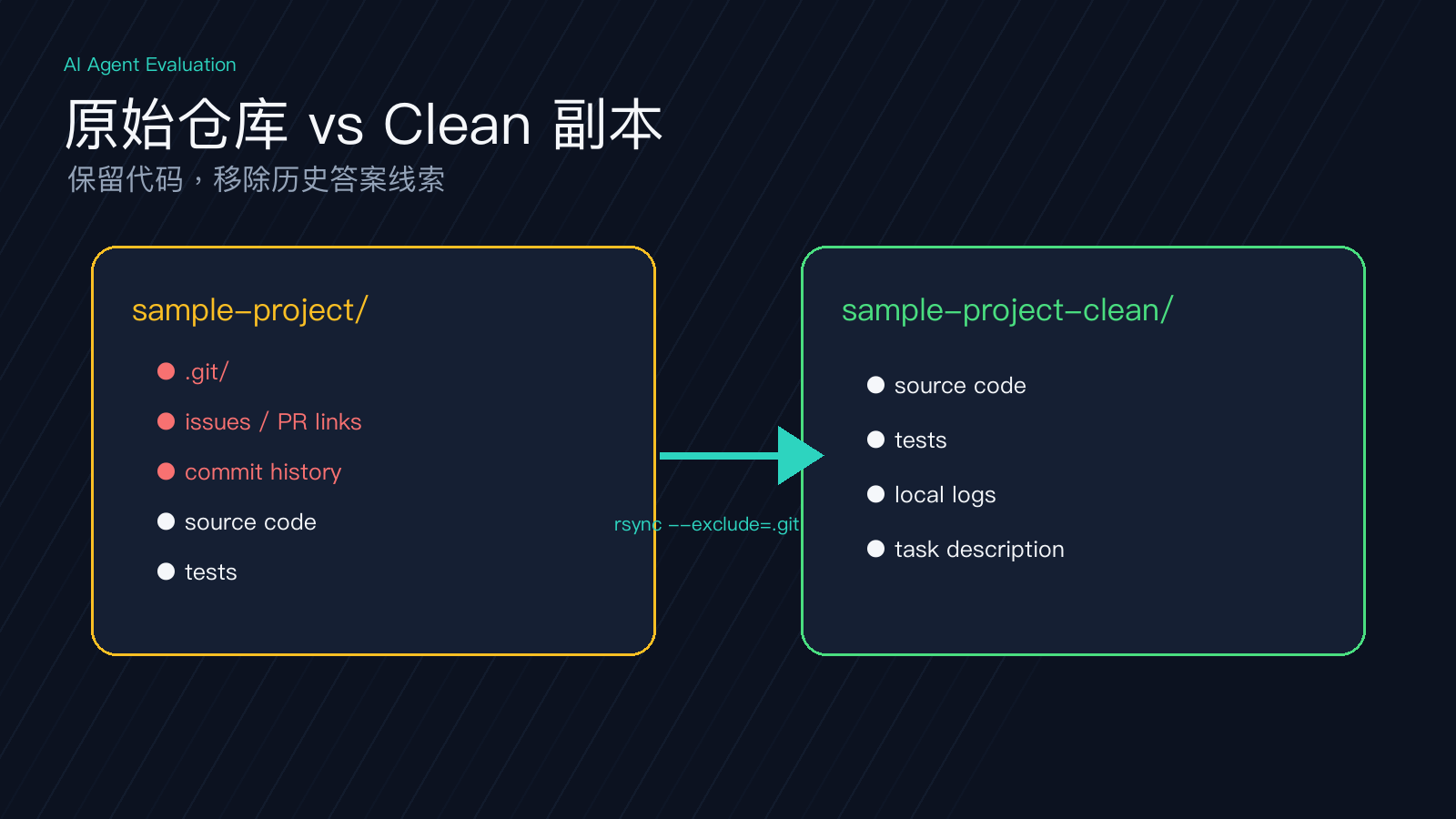
奖励攻击最容易从 Git 历史开始,所以先做一份“去历史副本”。下面用 sample-project 演示,实际替换成团队自己的仓库。
mkdir -p ~/ai-agent-eval/workspace
cd ~/ai-agent-eval/workspace
git clone --depth 1 https://github.com/pallets/flask.git sample-project
rsync -a --delete --exclude='.git' sample-project/ sample-project-clean/
find sample-project-clean -name '.git' -type d -prune -exec rm -rf {} +
这组命令会浅克隆仓库,复制一份不含 .git 的干净目录,并再次清理嵌套 .git。
检查清理结果:
cd ~/ai-agent-eval/workspace/sample-project-clean
find . -name '.git' -type d
这个命令没有输出,说明 Git 历史已经清掉。不要把原仓库路径、issue、PR、上游提交链接放进任务描述。
4 运行严格评测:把网络访问关掉
清理 Git 历史只解决一半问题。智能体还能联网搜索时,仍然能找到公开补丁。
Docker 里用 --network none 关闭容器网络。先做一个最小验证:
docker run --rm --network none python:3.12-slim python - <<'PY'
import socket
try:
socket.create_connection(("example.com", 80), timeout=3)
print("network open")
except OSError:
print("network blocked")
PY
输出 network blocked 再进入正式评测。
再把干净源码挂进容器,验证目录能被读取:
cd ~/ai-agent-eval/workspace
docker run --rm --network none \
-v "$PWD/sample-project-clean:/repo" \
-w /repo \
python:3.12-slim \
python -c "import os; print(os.getcwd()); print(len(os.listdir('.')))"
正式接入 AI 编程智能体时,只给三类输入:sample-project-clean 干净源码、本地失败测试输出、功能缺陷描述。不要同时开放浏览器、搜索工具和完整 Git 仓库。
5 生成评测报告:把过程留痕
严格评测还要能复查。建议每次记录任务编号、智能体版本、网络状态、补丁 diff。
下面用一个简单脚本生成 HTML 报告骨架:
mkdir -p ~/ai-agent-eval/reports
cd ~/ai-agent-eval/workspace/sample-project-clean
git diff --no-index /dev/null . > ~/ai-agent-eval/reports/source-tree.diff || true
cat > ~/ai-agent-eval/reports/index.html <<'HTML'
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>AI Agent Strict Eval Report</title>
<style>body{font-family:sans-serif;margin:40px;line-height:1.7}.ok{color:#0a7f33;font-weight:700}</style>
</head>
<body>
<h1>AI Agent Strict Eval Report</h1>
<p class="ok">Network: blocked</p>
<p>Git history: removed from clean workspace</p>
<p>Repository path: <code>sample-project-clean</code></p>
<p>Review items: task description, test log, final diff, human review conclusion.</p>
</body>
</html>
HTML
这个 HTML 是报告入口。落地时再放测试日志、操作轨迹和最终 diff,别放真实仓库地址、令牌和客户数据。
启动一个只读报告页面:
cd ~/ai-agent-eval/reports
python3 -m http.server 8080 --bind 127.0.0.1
打开 http://127.0.0.1:8080,看到报告标题就说明服务已启动。
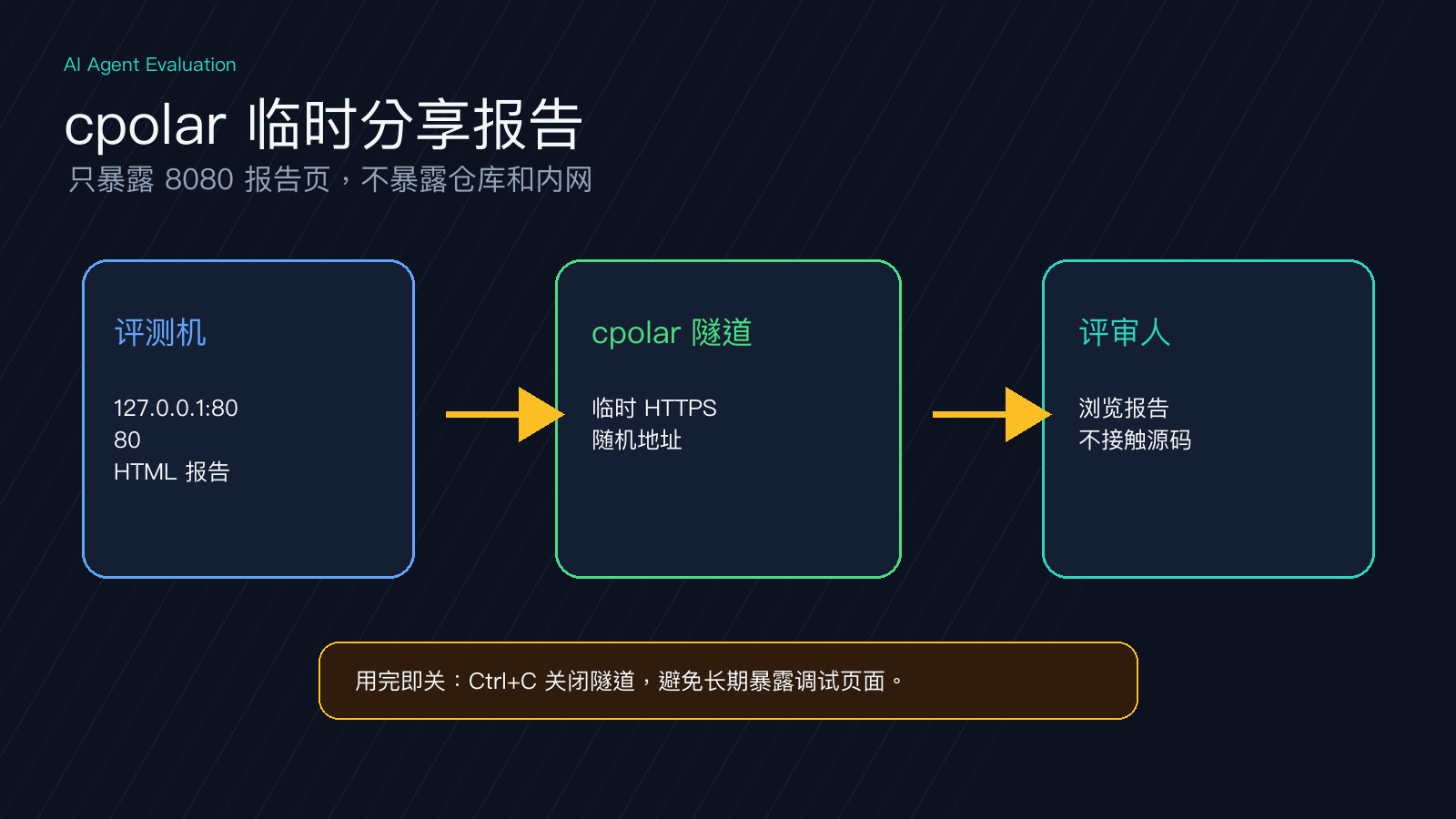
6 用 cpolar 临时分享报告:只暴露报告页
评测机在内网时,同事或外部协作方看不到报告。这里用 cpolar 开临时 HTTPS 地址,只映射本机 8080 报告页。
Linux 安装 cpolar:
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
登录 cpolar 后台获取 authtoken,再写入本机:
cpolar authtoken 你的_authtoken
启动 HTTP 隧道:
cpolar http 8080
终端会显示 https:// 公网地址。把它发给评审人即可;外部只看到报告页,看不到仓库权限和评测机内网地址。
一次性评审用完按 Ctrl+C 关闭隧道。免费随机地址 24 小时内变化,固定二级子域名需要基础套餐或以上。
7 评审分数:别只看通过率
严格环境跑完后,把结果拆成三列看:通过率、轨迹质量、补丁质量。重点检查有没有翻历史、搜补丁、绕过测试,以及代码是否最小修改。
如果一个智能体开放环境分数高、严格环境掉分明显,结论不是“它没用”,而是它强依赖外部检索。日常开发里检索能力能提升效率;关键系统修复、私有仓库缺陷、离线环境任务,更看重受控输入下的工程能力。
8 总结
到这里,我们已经搭出一套更干净的评测流程:源码去 Git 历史、容器关闭网络、报告本地生成,再用 cpolar 临时分享。
关键步骤记成三件事:
- 评测前先清理输入,不把
.git、issue、PR、commit 这类答案线索交给智能体。 - 评测时切断网络,用
docker run --network none确认环境真的离线。 - 评测后只分享报告页,用 cpolar 暴露
8080,不暴露仓库、不暴露内网机器。
SWE-bench Pro 分数仍有参考价值,但不是选型唯一依据。把开放环境和严格环境分开看,才能知道工具是在“会修代码”,还是在“会找答案”。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)