
2026年开发者的必备指南, Codex、Claude Code、CodeWhale怎么选?
讲完了大模型的工作逻辑、Token、上下文和 API 参数。到这里,已经不能只停留在“会调接口”了。真正做项目时,问题会很快变成另一组:
- 代码应该让 AI 在 IDE 里补,还是交给终端 Agent 改?
- 一个功能要不要让 Codex 或 Claude Code 自己开分支、跑测试、提 PR?
- DeepSeek 便宜,但工具链怎么接?有没有 Claude Code 之外的选择?
- Prompt 改了以后,怎么知道不是“感觉变好了”?
- Agent 能跑命令、改文件、连 MCP,权限边界怎么收住?
这就是工具链的价值。
2024 年以前,很多人说“AI 编程工具”,其实是在说补全插件。2025 年以后,重点明显变了:Coding Agent 开始进入真实工程流程。它不只是补一行代码,而是能读仓库、改文件、跑命令、看测试、解释 diff,甚至在云端并行处理多个任务。
所以这篇不再按“工具排行榜”写。更实用的方式,是按一条大模型应用开发流水线来拆:模型底座、编码 Agent、Agent 应用框架、本地调试、评测观测、Go 生态,以及上线前的权限和成本控制。
本文按 2026-06-19 可查到的公开资料整理。AI 工具更新很快,具体模型名、价格、可用地区和安装方式,以官方文档为准。
一、模型 API 平台:先把底座选稳
大模型应用的底座还是 API。工具再花哨,最后都要回到三件事:能力、成本、稳定性。
1. DeepSeek:低成本长上下文,适合大量工程试错
DeepSeek[1] 当前官方模型表里,主模型是 deepseek-v4-flash 和 deepseek-v4-pro。官方文档显示二者都支持 1M context、JSON Output、Tool Calls 和 Thinking Mode,OpenAI 格式 base URL 是 https://api.deepseek.com,同时也提供 Anthropic 格式入口。
这对开发者很重要。大量工具本来就是按 OpenAI Chat Completions 形状设计的,DeepSeek 的兼容性降低了接入成本。客服摘要、文档问答、代码解释、批量抽取这类任务,用 deepseek-v4-flash 先跑起来,通常比一上来接最贵模型更务实。
但 DeepSeek 不是“无脑默认”。它适合高性价比和长上下文场景;如果要做极复杂代码规划、跨仓库迁移、强工具调用 Agent,仍然要拿真实任务和 Codex、Claude Code 对比。
2. OpenAI:Codex 已经不只是模型,而是工程闭环入口
OpenAI 现在不能只看 API 模型,还要看 Codex[2] 这条线。底层模型已经从 codex-1 迭代到 GPT-5.5,又推出了 GPT-5.3-Codex[3]。但更值得关注的不是模型本身,而是 Codex 把入口铺到了桌面 App、IDE 插件、CLI、Web 和云端沙箱——它在变成一个完整的工程 Agent 平台。具体怎么用,后面 Coding Agent 那节会展开。
如果团队已经在用 ChatGPT、GitHub、OpenAI API,Codex 的优势不是”补全更聪明”,而是更容易进入工程闭环:开任务、隔离环境、跑测试、产出 diff、做 review。
3. Claude:Claude Code 的工程深度在拉开差距
Anthropic 的 Claude Code[4] 仍然是终端 Agent 的重要参照物。官方文档把它定义成”住在终端里的 agentic coding tool”,支持从自然语言描述构建功能、修 bug、理解代码库、自动化琐碎任务。它能编辑文件、运行命令、创建 commit,也能通过 MCP 连接外部数据源。
2026 年 Claude Code 迭代很快,但我觉得真正拉开差距的不是功能多,而是工程深度。子 Agent 现在支持 5 层嵌套——大型仓库可以把任务层层拆解,每一层专注一个范围。Auto Mode(研究预览)让安全操作自动批准、高风险操作自动阻止,减少了反复确认的中断感。Computer Use via CLI(也是研究预览)甚至能从终端操作原生应用和 UI,不限于文件和命令。
更有意思的是 Dreaming 机制:Agent 在空闲时会回顾历史 session、提炼模式、维护记忆。这意味着同一个仓库用得越久,它对项目的理解越准。Claude Design 和 Claude Code 之间也打通了双向协作,设计稿可以直接变成工程任务。
如果说 Cursor、Windsurf 代表”AI IDE”,Claude Code 更像”把一个能动手的工程助手放进终端”。它对大型代码库理解、命令行工作流、MCP 生态和企业权限配置的重视,是很多后续工具模仿的方向。
4. 国内云平台:百炼、火山、腾讯云更适合企业落地
企业项目通常还会看阿里云百炼、火山引擎、腾讯云这类平台。它们的优势不只是模型,而是账号体系、审计、知识库、工作流、私有化、合规和售后。
个人项目可以先用 DeepSeek 或 OpenAI 快速验证;企业项目如果涉及数据合规、私有知识库、部门权限和预算审批,云平台的工程配套会比单独调 API 省很多沟通成本。
二、Coding Agent:现在的主战场在终端和云端
AI IDE 还重要,但 2026 年的开发者工具不能只讲 Cursor、Windsurf、Trae。真正变化更大的,是 Codex、Claude Code、CodeWhale(deepseek-tui)这类能读写仓库、执行命令、跑测试的 Agent 工具。
1. Codex:从补全工具变成工程平台
Codex 的定位已经不是旧时代的”代码补全模型”。2026 年的 Codex 覆盖了桌面 App(macOS/Windows)、VS Code/Cursor/Windsurf 插件、CLI、Web 和云端执行环境,底层也迭代到了 GPT-5.5 和 GPT-5.3-Codex。
我觉得 Codex 2026 年最值得关注的变化有三个:
第一是子 Agent 模型 GA。一个 manager 可以协调多个并行 worker,各自有独立上下文和云端沙箱。我后来用它同时跑三个 lint 修复任务,每个 Agent 在自己的 worktree 里改,互不影响,最后分别提 PR。这种”多 issue 并行”的工作方式,手动很难做到。
第二是 AGENTS.md。仓库可以用这个文件告诉 Agent 如何理解项目、运行哪些测试、遵守哪些代码规范。这很像团队的 onboarding 文档,只是读者从新人变成了 Agent。仓库里如果没有清楚的 README、测试命令、lint 命令、数据库启动方式,Agent 再强也容易原地打转。
第三是 Codex Security(2026 年 3 月推出),专门扫描和修复应用层漏洞。这让安全审查也能变成 Agent 任务。
Codex 的周活已经超过 400 万开发者,也被 Gartner 评为企业编码 Agent 领导者[5]。
适合 Codex 的任务:
- 中等规模功能开发:有清晰需求、可跑测试、改动边界明确。
- 代码审查:让 Agent 从 diff、测试和兼容性角度找问题。
- 迁移和重构:例如改 API 调用方式、升级依赖、批量修 lint。
- 后台并行任务:多个 issue 分给多个 Agent,各自在隔离环境里跑。
不适合一上来交给 Codex 的任务:
- 需求还很模糊,需要大量产品判断。
- 本地环境极难复现,测试也跑不起来。
- 改动涉及密钥、生产数据、支付、权限策略,且没有人工 review。
2. Claude Code:终端里的工程助手,强在交互和上下文
Claude Code 的入口很简单:官方文档给的标准安装方式是 npm install -g @anthropic-ai/claude-code,进入项目目录后运行 claude。它不是另一个聊天窗口,而是直接进入你已经工作的终端。
它适合这几类场景:
- 在陌生仓库里快速建立理解:让它解释模块、调用链、配置和测试入口。
- 带着它排 bug:贴错误日志,让它搜代码、改文件、跑命令。
- 小到中等规模的功能开发:先计划,再改代码,再运行验证。
- 自动化开发琐事:修 lint、写 release notes、处理重复性改动。
Claude Code 的另一个重点是配置和权限。官方文档里有 CLAUDE.md、.claude/settings.json、MCP servers、subagents、hooks、permissions 等机制。这说明它不是“玩具 CLI”,而是在往团队工程工具方向走。
用 Claude Code 时,比较稳的习惯是:
- 在仓库根目录写清
CLAUDE.md:项目结构、测试命令、代码风格、禁止事项。 - 不要默认放开所有命令执行权限,尤其是删除文件、数据库操作、部署命令。
- 让它每完成一个小功能就跑验证,而不是一次性改一大片。
- 最终 diff 仍然要人工 review。
3. CodeWhale(原 deepseek-tui):DeepSeek 阵营的终端 Agent 选择
如果想用 DeepSeek 模型做 Claude Code / Codex CLI 类似的终端 Agent,CodeWhale[6](原名 deepseek-tui,GitHub[7])值得关注。项目已于 2026 年中改名为 CodeWhale,但旧名、旧安装命令和环境变量仍然可用。
它的官方站点把自己描述为基于 DeepSeek V4 系列的开源命令行 Agent,能编辑文件、运行 shell、调用 MCP server,并尊重 sandbox。架构上是两个 Rust binary:deepseek dispatcher CLI 负责认证、配置和模型选择,deepseek-tui 负责实际 Agent 执行。没有 Electron、没有 Python 运行时,空闲内存占用约 12MB。
安装方式有两种:
# npm 方式(便捷下载器,实际是预编译 Rust binary)npm install -g deepseek-tui# Cargo 方式(需要 Rust 1.88+)cargo install deepseek-tui-cli --locked
它有几个值得注意的点:
- 成本友好:底层接 DeepSeek V4,
deepseek-v4-flash输入 $0.14/M tokens,同等工作量成本约为 Claude Code 的十分之一。 - 终端原生:不是 IDE 插件,适合习惯命令行的开发者。
- 工具能力完整:读文件、改文件、grep、apply_patch、exec_shell、MCP 都在它的设计范围内。
- 有 sandbox 和 approval:Agent 能动手,但不是默认无边界乱跑。
- 支持 auto mode:可在
deepseek-v4-flash/deepseek-v4-pro、thinking off/high/max 之间做本地路由。
需要注意的是,CodeWhale 还在快速变化(截至 2026 年 6 月已达 v0.8.8,37 个 release)。它很适合愿意折腾、愿意跟开源项目一起迭代的开发者;如果是企业稳定生产环境,仍然要看版本锁定、权限策略、日志审计和安全评估。
4. Cursor、Windsurf、Trae:AI IDE 的角色和格局都在变
AI IDE 没过时,但 2026 年格局变化不小。
- Cursor[8]:VS Code 的 AI 分支,估值 $9B,ARR $5 亿,$20/月。强项是代码库语义理解和
.cursorrules配置(团队实测 PR review 评论减少 70%、TypeScript 报错减少 35%)。适合日常编码、补全、局部重构、和代码库对话。 - Windsurf[9]:2025 年被 Cognition 以 $3B 收购,推出了自研模型 SWE-1.5(比 Sonnet 4.5 快 13x),$15/月。新增 Arena Mode 允许在 IDE 内对比不同模型。除 VS Code 外还支持 JetBrains、Neovim、Sublime 等。适合在 IDE 内完成多文件修改和运行验证。
- Trae[10]:对国内开发者友好,免费策略最激进,对比测试中响应速度最快(平均 1.2 秒)。适合预算敏感、刚入门或 5 万行以下的新项目。
它们更像”前台工作台”。写业务代码、看上下文、做小改动很舒服。但一旦任务变成”后台跑一个迁移””并行处理多个 issue””自动 review PR”,Codex、Claude Code、CodeWhale 这类 Agent 工具会更自然。
三、Agent 应用开发:不要只会让 Agent 写代码
Coding Agent 是帮你开发软件的 Agent;而大模型应用里,还需要你自己构建面向用户的 Agent。
1. Dify:开源 LLM 应用平台,已进入多 Agent 阶段
Dify[11] 的定位是开源 LLM 应用开发平台,2026 年已经不只是"拖拽式工作流"了。几个重要更新:
- MCP 支持:Agent 现在可以连接任意 MCP server(文件系统、GitHub、Slack、数据库、浏览器),在设置里添加即可。
- Supervisor Agent 模式:支持多个子 Agent 协调,处理复杂多步骤任务。
- RAG 增强:混合检索(dense + sparse vector)、chunk 重排序、父文档检索、Q&A 自动提取。
- 模型生态扩展:原生支持 Gemini 2.0、Claude 3.5、GPT-4o mini、DeepSeek V3/R1、Mistral Large,也支持 Ollama 本地模型。
- 社区规模:GitHub stars 已超 50K,商业云版本也在运营。
适合 Dify 的场景:
- 快速做客服机器人、知识库问答、表单处理、内容生成工作流。
- 产品、运营、业务同学也要参与配置。
- 团队想先验证流程,再决定是否沉淀成代码。
局限也很明显:复杂业务逻辑、严格类型约束、深度工程化测试,最后还是要回到代码。
2. Coze:适合插件生态和低代码 Bot
Coze[12] 适合快速搭 Bot、接插件、做多轮对话和工作流。它的优势是上手快、生态现成、适合做偏产品化的 Agent 原型。
如果目标是在企业微信、飞书、网页或某个业务入口里快速放一个助手,Coze 这类平台能省掉大量样板工作。代价是可控性、版本管理和深度定制要提前评估。另外,Coze 由字节跳动运营,如果涉及欧盟数据合规(NIS2/DORA),需要额外评估数据驻留问题。
3. n8n:工作流自动化的开源替代
如果团队的核心需求不是"构建 AI 对话 Bot",而是"把多个系统串起来跑自动化流程",n8n[13] 值得关注。它是一个开源的工作流自动化平台,2026 年在 AI Agent 场景也有大量应用。
和 Dify/Coze 的区别在于,n8n 更偏通用自动化:它有 400+ 集成节点(Slack、GitHub、数据库、HTTP、邮件等),AI 是其中一环而不是全部。适合用来做"AI 分析结果 → 触发审批 → 写入数据库 → 发通知"这类跨系统工作流。
如果你的 AI 应用不只是对话,还需要对接企业内部的多个系统,n8n 和 Dify 的组合会比单独用其中一个更灵活。
4. Eino:Go 开发者要重点看
如果你用 Go 写后端,Eino[14] 值得认真看。CloudWeGo 官方把 Eino 定位为 Go 语言的 LLM/AI 应用开发框架,覆盖模型、工具、链路编排、Agent、图编排等能力。它是字节跳动内部在豆包、TikTok 等产品上打磨半年后开源的,不是实验室项目。
2026 年 Eino 的重要更新是 ADK(Agent Development Kit),补齐了几块关键能力:
- 工具调用、多 Agent 协调、上下文管理。
- 中断/恢复(human-in-the-loop):Agent 可以暂停等人工输入,恢复后从 checkpoint 继续。
- 流式处理自动编排:组件只实现自己需要的流式范式,框架自动做拼接、装箱、合并和复制。
- 模型支持:OpenAI、Claude、Gemini、Ark、Ollama 等都有官方实现。
这类框架的价值不是”帮你少写几行 API 调用”,而是把复杂 Agent 应用里的组件边界明确下来:
- LLM 调用怎么封装。
- Tool 怎么声明、调用、校验。
- RAG 检索怎么接。
- 多步骤流程怎么编排。
- 失败、重试、超时、观测怎么统一处理。
简单项目用 go-openai 或直接 HTTP 调用就够了;一旦进入多工具、多步骤、多模型、多租户,Eino 这种框架会比手写胶水代码更稳。
四、本地模型与调试:不是为了炫,是为了降低试错成本
本地模型最大的价值,不是替代云端最强模型,而是让开发者低成本试错。
1. Ollama / LM Studio:本地跑模型,适合原型和隐私场景
Ollama[15] 和 LM Studio[16] 都适合在本机跑开源模型。它们常见用途是:
- 离线试 Prompt 结构。
- 做简单分类、抽取、摘要原型。
- 处理不方便传到外部 API 的样例数据。
- 给开发环境提供一个 OpenAI-compatible endpoint。
但不要误会:本地模型能跑,不等于线上效果就够。真正上线前,仍然要用目标模型、目标数据、目标延迟跑评测。
2. vLLM:团队自托管推理的常见选择
如果团队有 GPU 资源,或者需要自己托管开源模型,vLLM[17] 这类推理框架会进入选型范围。它更偏平台工程,不是每个业务开发者都要亲自维护。
判断是否需要自托管,可以看三个问题:
- 调云 API 的成本是否已经明显不可控。
- 数据是否不能出内网。
- 团队是否有能力维护 GPU、模型版本、并发、监控和故障恢复。
如果这三个问题没有清晰答案,先别急着自托管。
五、调试、评测和观测:这是 AI 应用的刹车系统
AI 应用最怕“看起来能跑”。Prompt 改了一句、模型换了一个、温度调了一点,输出可能就变了。没有评测和观测,工具链再全也只是加速踩坑。
1. curl / Postman / Bruno:API 调试基本功
先用 curl 或 Postman 把请求打通,再写代码。这个习惯不过时。
要确认的不是“接口能返回”,而是:
- Header、鉴权、base URL、model 名是否正确。
stream和非stream的响应结构是否一致。- JSON 模式、工具调用、错误码、超时是否按预期工作。
- usage 字段能不能拿到,是否能进日志。
Bruno[18] 这类 Git-friendly API client 也值得看,团队可以把接口样例直接放进仓库,方便 code review。
2. promptfoo:Prompt 和模型评测要自动化
promptfoo[19] 官方文档把它定位为开源 CLI 和库,用于评估、红队测试 LLM 应用。它适合做矩阵测试:同一批用例,跑不同 Prompt、不同模型、不同参数,然后比较结果。
客服摘要接口就可以这样测:
- 50 条真实脱敏工单。
- 固定期望字段:
summary、category、risk_level、next_action。 - 检查 JSON 是否可解析。
- 检查分类是否落在枚举里。
- 抽样人工评估摘要质量。
- 记录 token、延迟、失败率。
这比“我感觉这个 Prompt 更好”可靠得多。
3. Langfuse / Phoenix / OpenTelemetry:把链路看见
上线后要看三类数据:
- 成本:prompt token、completion token、reasoning token、cache hit/miss。
- 质量:解析成功率、校验失败率、人工复核通过率、用户反馈。
- 链路:每一步 Prompt、检索结果、工具调用、模型响应、异常堆栈。
Langfuse[20]、Phoenix[21]、OpenTelemetry 这类工具各有侧重,核心目标一样:让一次大模型调用从黑盒变成可追踪链路。没有这个能力,线上问题很难复盘。
六、Go 生态:简单调用别上框架,复杂 Agent 别硬手写
Go 开发者可以按复杂度选工具。
1. 简单 API 调用:HTTP 或 go-openai 足够
如果只是调用 OpenAI-compatible Chat Completions,直接 HTTP 或 sashabaranov/go-openai[22] 就够了。重点不是 SDK 多高级,而是把下面几件事写扎实:
- timeout 和 retry。
- stream 解析。
- usage 记录。
- JSON parse 和业务校验。
- 错误码分类。
- 日志脱敏。
2. Token 和成本:tiktoken-go 仍然有用
Token 估算不是摆设。长文档、RAG、多轮对话、批处理任务,成本经常不是输出贵,而是输入和缓存策略没设计好。
pkoukk/tiktoken-go[23] 这类库可以帮你在请求前估算 token,避免超上下文,也方便做成本预估。注意不同模型 tokenizer 不完全一样,估算结果要和实际 usage 对照校准。
3. 复杂 Agent:看 Eino,不要全靠胶水代码
一旦应用里有多个工具、多个模型、RAG、工作流分支、重试和回滚,手写胶水代码很快会乱。Eino 的价值就在这里:把组件抽象和编排方式固定下来,让复杂 Agent 应用有结构可维护。
七、一条更现实的开发工作流
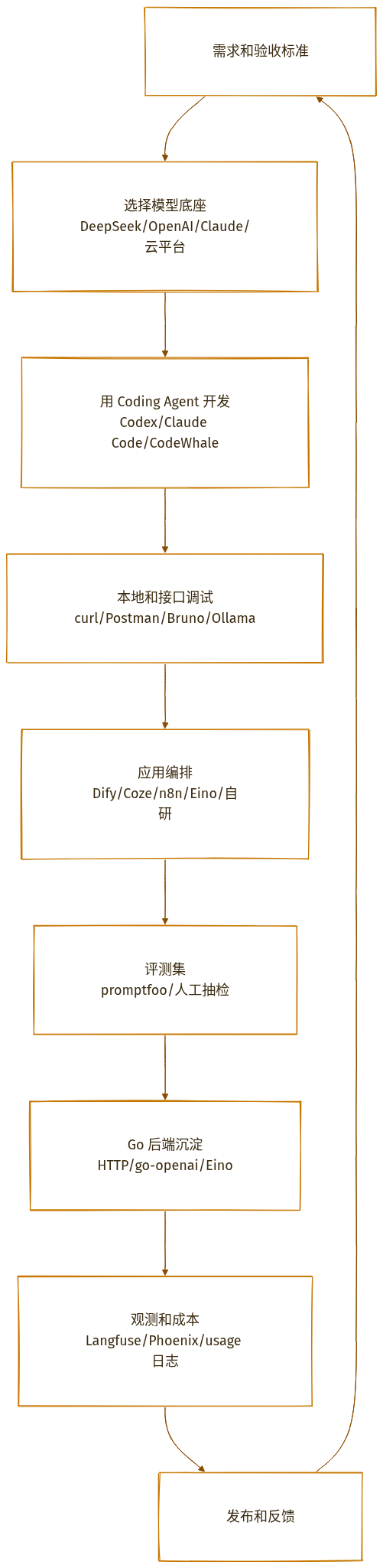
这条线的关键不是工具多,而是每一步都有明确产物:
- 需求阶段:有验收标准,不只是一句“做个 AI 助手”。
- Agent 开发阶段:有 diff、有测试输出、有 review。
- 调试阶段:有可复现请求样例。
- 编排阶段:知道哪些逻辑放平台,哪些逻辑进代码。
- 评测阶段:有固定用例,不凭感觉换 Prompt。
- 上线阶段:能看到成本、失败率、工具调用和用户反馈。
八、不同开发者怎么选
| 场景 | 推荐组合 | 说明 |
|---|---|---|
| 个人学习和练手 | DeepSeek + CodeWhale + Ollama + promptfoo | 成本低,能完整体验 Agent 修改代码和评测流程 |
| 日常业务开发 | Claude Code 或 Codex + Cursor/Windsurf + curl/Postman | 终端 Agent 负责中等任务,IDE 负责日常编辑 |
| Go 后端 AI 应用 | DeepSeek/OpenAI + go-openai + Eino + promptfoo | 简单调用先轻量,复杂编排再引入 Eino |
| 企业知识库 / 工作流 | 百炼/火山/腾讯云 + Dify/Coze/n8n + 观测平台 | 优先考虑权限、审计、知识库和交付效率 |
| 多人协作的大仓库 | Codex + Claude Code + AGENTS.md/CLAUDE.md + CI | 关键是把测试、规范、权限写进仓库,而不是只买工具 |
结语:抓住大模型时代的职业机遇
AI大模型的发展不是“替代人类”,而是“重塑职业价值”——它淘汰的是重复性、低附加值的工作,却催生了更多需要“技术+业务”交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为“懂技术、懂业务”的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)