
Codex Context Compaction 真相:Agent 为什么压缩后还能接着干活?
如果你长时间用过代码 Agent,大概率遇到过这种场景:前面半小时还在很认真地查仓库、跑测试、解冲突,下一轮突然像换了个人,只记得“正在处理一个项目”,但忘了分支名、PR 编号、刚才失败的是哪个测试。
这类崩坏通常不发生在第一轮。它发生在上下文被压缩之后。
所以过去很多人的习惯很保守:上下文快满之前,先让 Agent 写一份交接文档;重要任务做到一半,尽量不要自动 compact;能新开会话就新开会话。听起来麻烦,但至少可控。
最近 Codex 的风向不太一样。越来越多用户开始把上下文窗口这件事交给系统自己处理。它自动压缩,继续跑,再压缩,再继续跑。最让人意外的不是它“还能回答”,而是它在复杂任务里还能记住不少低层事实:分支、stash、merge commit、构建结果、用户最后一句确认。
这背后不是某个提示词突然写得更聪明了。更准确地说,Codex 把 compact 从“一段摘要”做成了一次状态迁移。
图:长程 Agent 真正需要保住的是现场碎片,而不只是文章主线。
窗口不见了,不代表窗口不重要
Codex App 曾经把 context window 的使用比例放在主界面上。后来这个指示器被挪到了二级入口,只能通过 /status 或 /compact 之类的命令查看。这个改动让不少重度用户很不爽。
原因很好理解。对短问答来说,上下文窗口只是一个技术参数;对长程 coding 来说,它更像油表。你不一定每秒盯着它,但你需要知道车还能跑多远。
Codex 团队当时给出的方向是 “vibe contexting”:用户不再需要主动管理上下文。
这句话如果放在一年前,很像产品经理的漂亮话。因为压缩一直是 Agent 链路里最脆弱的地方。它不是把文本缩短那么简单,而是在决定哪些事实还能活到下一轮,哪些事实永远丢掉。
Codex 敢把窗口感知降级,真正依赖的是下面几层机制:入口截流、远程压缩、系统脚手架重建,以及服务端和模型的配合。
真正进入 compact 之前,很多内容已经被处理掉了
很多人以为上下文管理就是“满了以后压一下”。Codex 不是这么干的。
在 full compact 之前,它已经先把一批容易撑爆窗口的内容压住了:
| 位置 | Codex 怎么处理 | 这意味着什么 |
|---|---|---|
| 工具输出 | 工具结果进入历史时就做 middle truncation,保留头尾 | 中间细节可能直接消失 |
| 终端输出 | PTY 原始输出只留头尾,总量有限 | 大日志不会完整进上下文 |
| Hook 结果 | 太大的 hook 输出写到临时文件,只给预览和路径 | 模型需要时可以再读,但不会默认吃满窗口 |
| 历史消息 | 清理不成对的 tool call/output、孤儿输出和不支持的图片 | 保证请求结构干净 |
| 系统上下文 | 只追加变化部分,不每轮重复塞满配置 | 降低固定上下文的增长速度 |
这里有个细节挺重要:很多截断发生在内容进入历史的那一刻。也就是说,它们发生在 prompt cache 形成之前。
这不是洁癖,是成本问题。模型服务端的前缀缓存依赖逐 token 一致。如果一条旧工具结果已经进入历史,后面再回头改它,改动点之后的缓存可能全废。对十几万 token 的长程会话来说,一次 cache miss 可能就是一轮账单和延迟的数量级变化。
Codex 的选择比较硬:先在入口控制住体积。代价也很明确,被截掉的内容未必能回来。
Local Compact:一份交接文档能救简单任务,救不了复杂现场
Codex compact 的第一条路叫 Local Compact。它的做法并不神秘:让当前模型给后续模型写一份 handoff summary。
流程大概是这样:
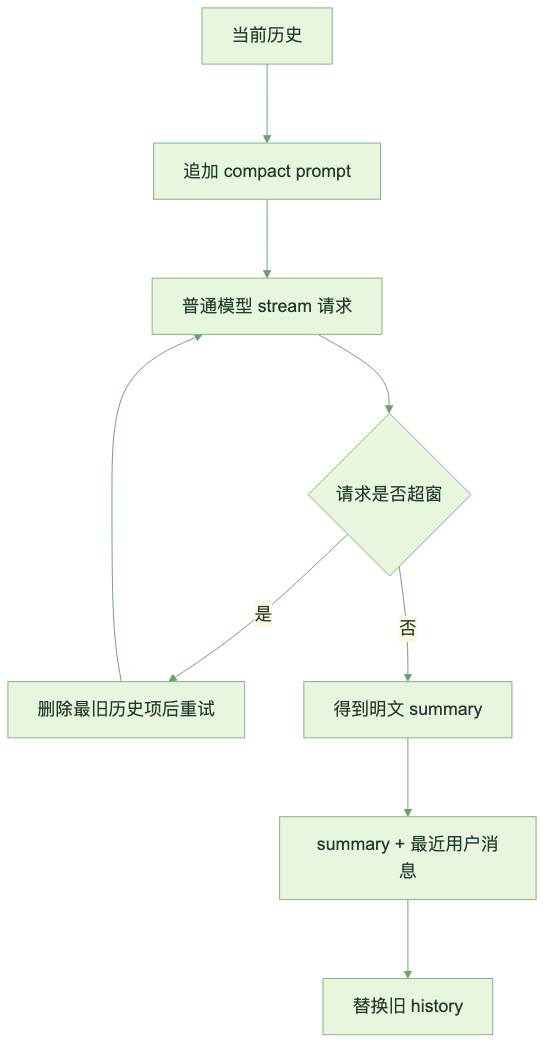
图:Local Compact 以明文摘要替换旧历史
这套方案非常像人类工程师写交接文档。写得好,后面的人能接上;写漏了,后面的人只能猜。
Local Compact 最大的问题就在这里:压缩后的 replacement history 里,很多原始材料不会再出现。assistant 的中间判断、tool call 的原始结果、reasoning、web 结果,大多只能靠 summary 间接留下来。
简单任务还能扛住。比如开一个 GitHub issue、补一条评论、确认几个 label,summary 抓住主线就行。
复杂任务不一样。长程 coding 里真正致命的常常是小事实:
- 当前在哪个分支;
- 哪个 stash 是临时绕过签名用的;
- 哪个测试 315/315 通过;
- 哪个构建失败是 x86_64 slice 缺失;
- 用户最后是否已经验收。
这些东西如果没被 summary 写进去,下一轮模型不会“自然想起来”。它只能重新查,或者老老实实说不知道。
Remote Compact:客户端看不懂,但效果明显不一样
第二条路是 Remote Compact。这里开始变得有意思。
Codex 会根据 provider 判断能不能走远程压缩。OpenAI 原生 provider 和 Azure Responses provider 支持;常见第三方 provider、中转站、本地模型入口默认不支持。分流逻辑大致是:
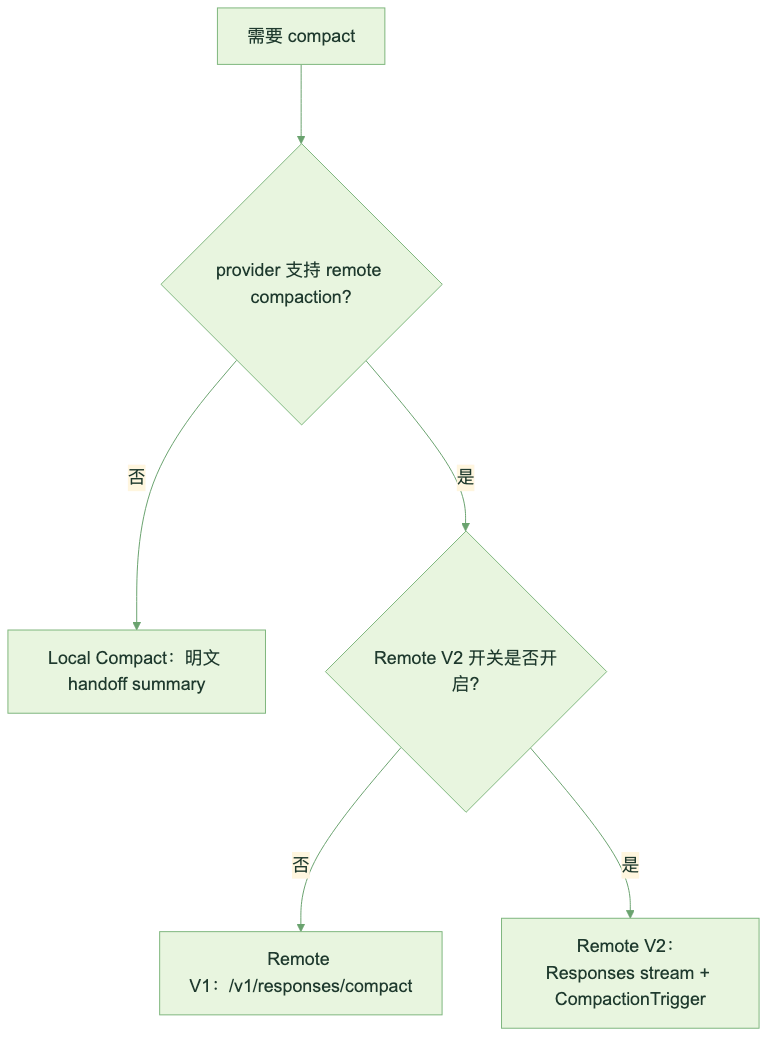
图:不同 provider 下的远程压缩路径
Remote V1 走专用 /v1/responses/compact endpoint。Remote V2 则把压缩触发器塞进普通 Responses stream:输入末尾多一个 CompactionTrigger,服务端返回一条特殊的 compaction item。
两条远程路径最后都会产生类似的东西:encrypted_content。
客户端不会拿到一段可读摘要。它拿到的是一块 opaque state,一段加密内容。后续请求继续带上它,由服务端解密并组装给模型。
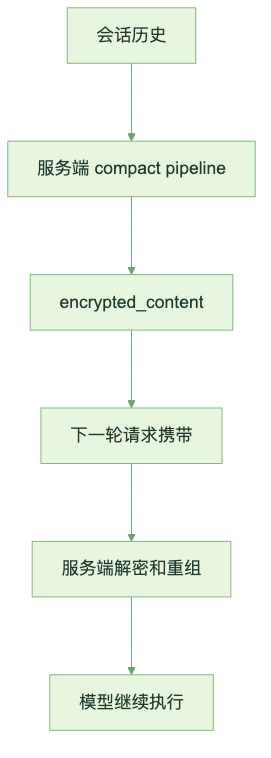
图:encrypted_content 在服务端完成状态迁移
这也是 Remote Compact 和 Local Compact 的本质区别:Local 留给客户端一份“文本交接”;Remote 留给服务端一份“状态块”。

图:Remote Compact 的关键变化,是把压缩从文本摘要推进到服务端状态承载。
实验最刺眼的地方:差距不是 5 分,而是一个等级
如果只看机制,很容易陷入猜测。真正有说服力的是同一批长程任务分别走 Local、Remote V1、Remote V2 后的恢复效果。
一类简单任务里,Remote 比 Local 稳定一些,但差距还不算夸张:
| 测试内容 | Local | Remote |
|---|---|---|
| 主线和决策链恢复 | 89.7 | 96.6 |
| 反事实判断 | 88 | 100 |
| 低层事实定位 | 84.0 | 92.3 |
| 禁用工具后的续跑 | 86 | 92 |
| 允许工具后的最小验证 | 88 | 95 |
| 平均 | 87.1 | 95.2 |
真正拉开差距的是复杂 coding 任务。比如持续处理一个 Multi-Mac PR:merge upstream、解冲突、stash 管理、构建验证、真机测试、用户验收,全都混在同一条会话里。
| 压缩路径 | 客观评分 | 关键事实命中 |
|---|---|---|
| Local Compact | 约 28/100 | 5/24 |
| Remote V1 | 约 94/100 | 23/24 |
| Remote V2 | 约 92/100 | 23/24 |
Local 的失败很克制,但也很致命。它没有大规模编造,而是大量 unknown。它知道自己不知道。可对执行任务来说,这几乎等价于失忆。
Remote V1/V2 则能恢复仓库、分支、merge commit、PR #137、stash 内容、测试通过数量、真机型号和用户确认。这里面不少事实都不是“文章主旨”,而是现场碎片。长程任务能不能接上,往往就靠这些碎片。
所以 Remote Compact 的优势不像是 prompt 稍微好一点。它更像保留了 Local summary 留不住的状态。
服务端黑盒:提示词之外还有多少操作空间
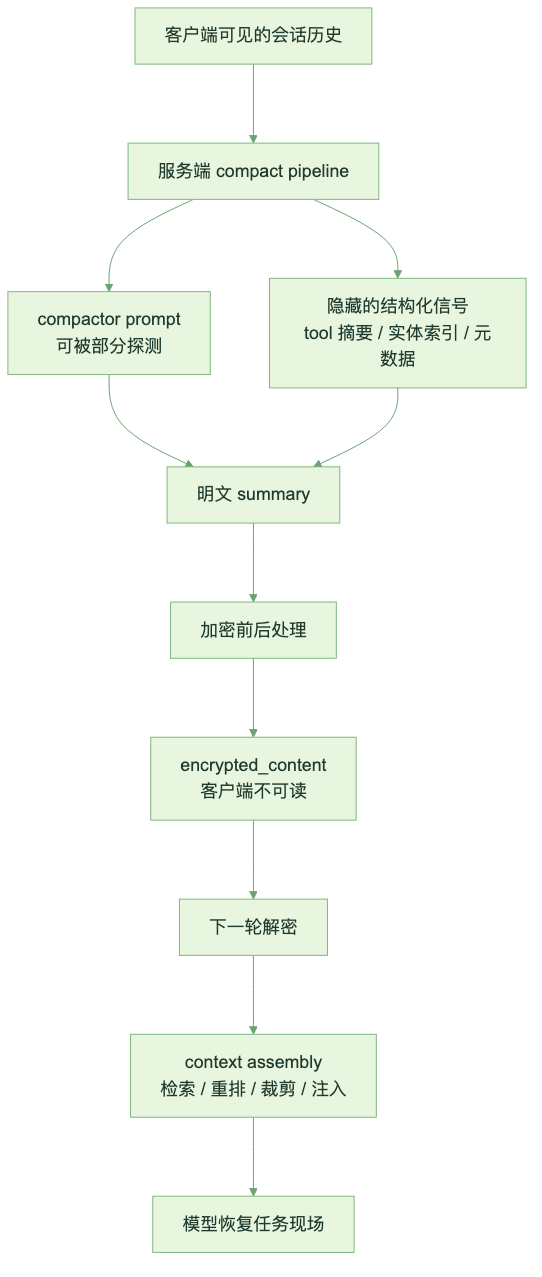
有人用 prompt injection 研究过 Remote Compact 的服务端流程。能看到的大致是这样:服务端有一个 compactor LLM,它读入系统提示和会话历史,写出一份明文 summary;随后服务端把这份 summary 加密成 blob。下一轮请求时,服务端再解密 blob,拼上 handoff prompt,交给模型继续执行。
麻烦也在这里。泄露出来的 compaction prompt,和 Local Compact 开源出来的那段提示词非常接近。既然提示词差不多,为什么复杂任务里一个接近失忆,一个还能恢复大部分现场?
我更倾向于把 prompt injection 看到的东西理解成“表层文本”,不是完整机制。服务端真正能动手脚的地方,比那几行 prompt 多得多。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)